kubernetes CKA study (8) - Imperative vs Declarative, kubectl apply command
kubernetes CKA study

Imperative vs Declarative
지금까지 우리는 Kubernetes에서 오브젝트를 생성하고 관리하는 다양한 방법을 보았습니다. 우리는 커맨드를 사용해서 직접 오브젝트를 생성하기도 했고, configuration file을 사용하기도 했습니다. 인프라 관리에 있어서 이 방법들은 imperative(명령형) 접근 방식과 declarative(선언적) 접근 방식으로 분류됩니다.
비유를 들어 이해해보겠습니다. Street D에 있는 친구집에 놀러가고 싶습니다.
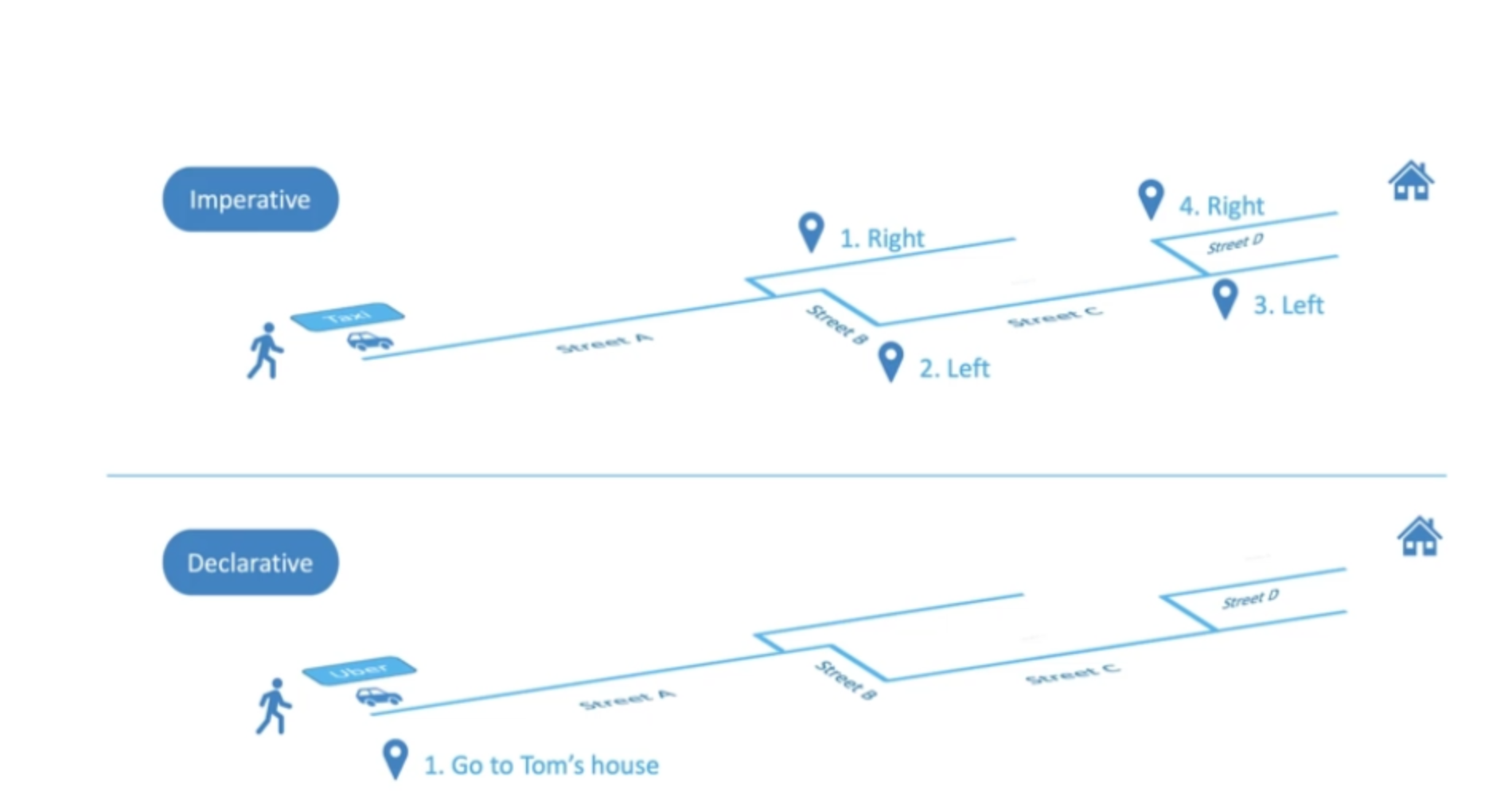
Imperative
과거에는 택시를 타면 목적지에 도달하는 방법에 대해 step-by-step으로 기사님께 말씀드려야 했습니다.
Street B로 우회전 하시고, 좌회전해서 Street C로 가주세요. 그다음 다시 좌회전 하고 우회전하면 Street D에요. 거기서 직진하면 됩니다.
이처럼 '어떻게'를 중요하게 두는 방식이 Imperative 방식입니다.
Declarative
반면에, 오늘날 택시를 타면 최종 목적지만 지정하면 친구 집으로 운전해주십니다. 이것이 Declarative 방식입니다. 여기서는 단계별 지침을 말할 필요가 없습니다. 대신 최종 목적지만 지정하면 됩니다. 우리가 최종 목적지를 지정하면 시스템이 올바른 경로를 파악합니다. 이렇게 '무엇을' 할 것인지를 중요하게 두는 방식이 Declarative방식입니다.
Infrastructure as Code
이러한 접근 방식이 우리가 배우는 것과 무슨 상관이 있을까요? infrastructure-as-code(코드형 인프라) 세계에서 provisioning infrastructure의 imperative 접근 방식의 예로는 단계별로 쓰여진 instructions 세트가 될 수 있습니다.
-
provisioning a VM named a web server
-
installing the NGINX software on it
-
editing configuration file to use port 8080
-
setting the path to web files
-
downloading source code of repositories from Git
-
starting the NGINX server
여기서 우리는 무엇이 필요한지 말하고, 그것을 완료하려면 어떻게 해야 하는지 말합니다.
반면 declarative 접근방식에서 우리는 우리의 요구를 선언합니다. 예를 들어 nginx 소프트웨어가 있는 "web server"라는 이름으로 VM이 필요하고 포트는 8080으로 설정하고 싶다면, 단계별 지침을 제공할 필요 없이시스템 또는 소프트웨어에 의해 수행됩니다. Ansible, Puppet, Chef, Terraform과 같은 오케스트레이션 툴이 범주에 속합니다.
imperative 접근 방식에서 첫 단계의 반만 실행되면 어떻게 될까요? 나머지를 완료하기 위해 같은 지침을 또 제공해야 할까요? 이런 상황을 다루기 위해, 관련된 많은 추가적인 단계들이 있을 것입니다. 예를 들어 이미 존재하는지 체크하는 것이라던가, 체크한 결과에 따라 조치를 취하는 것 같은 것들 말입니다.
예를 들어 VM을 프로비저닝하는 동안 "web server"라는 VM이 이미 존재한다면 어떻게 될까요? 데이터베이스를 만들거나 데이터를 가져올 때도 마찬가지입니다. VM이 이미 존재한다면, 해당 instruction은 실패한걸까요 아니면 계속해야 하는 것일까요? 소프트웨어 버전을 예를 들어 NGINX 1.18로 업그레이드하기로 결정한 경우, configuration file에서 nginx 버전을 업그레이드하는 것 만큼 간단해야 할 것입니다. 그리고 나머지는 시스템이 처리해야 할 것입니다. 이상적으로, 시스템이 충분히 지능적이어서 이미 벌어진 일을 알고 필요한 변경 사항만 적용합니다. 이것이 declarative 방식입니다.
Kubernetes
쿠버네티스 세계에서는 인프라 관리를 imperative 방식으로 한다는 것은 파드를 생성할 때 kubectl run커맨드를 사용하는 것과 같습니다. deployment를 생성할 때에는 kubectl create deployment 를, service를 생성할때는 kubectl expose 를 사용합니다.그리고 kubectl edit커맨드는 이미 존재하는 오브젝트를 수정하는데 쓰입니다. Deployment나 ReplicaSet을 확장하기 위해서는 kubectl scale커맨드를 사용합니다. deployment에서 image를 업데이트하려면 kubectl set image 커맨드를 사용하면 됩니다.
우리는 오브젝트를 생성하고 관리하기 위해 configuration file들도 사용했습니다. kubectl create -f커맨드를 사용해서 configuration file을 지정했습니다. 또한 오브젝트를 수정하기 위해 kubectl replace커맨드를 사용하고 오브젝트를 삭제하기 위해 kubectl delete커맨드를 사용했습니다. 이 모든 것들은 Kubernetes에서 오브젝트를 관리하는 imperative 접근 방식입니다. 우리는 오브젝트를 만들고, 업데이트하고, 삭제하는 니즈를 위해 어떻게해야 하는지 인프라에게 정확하게 말하고 있습니다. declarative 접근 방식은 다음과 같습니다. Kubernetes 클러스터의 애플리케이션 및 서비스의예상되는 상태를 정의하는 file 세트를 만드는 것입니다. 그리고 단 하나의 커맨드 kubectl apply커맨드로 Kubernetes는 configuration file을 읽을 수 있어야 합니다. 그리고 인프라를 예상되는 상태로 만들기 위해 해야 할 일을 스스로 결정합니다. 따라서 declarative 접근 방식에서는 오브젝트를 만들고, 업데이트하고, 삭제하기 위해 kubectl apply커맨드를 실행합니다. apply 커맨드는 기존 구성을 확인하고 시스템에 어떤 변경이 필요한지 파악할 것입니다.
Imperative Commands
imperative 접근 방식에는 두 가지 방법이 있습니다. 첫 번째는 imperative(명령형) 커맨드를 사용하는 것입니다. 오브젝트를 생성하기 위한 run, create, expose 커맨드와 기존에 존재하는 오브젝트를 업데이트하기 위한 edit, scale, set 커맨드가 imperative 커맨드입니다. 이러한 커맨드는 yaml파일을 다룰 필요가 없기 때문에 빠르게 오브젝트를 만들고 수정하는데 도움이 됩니다. 그리고 자격증 시험에도 도움이 됩니다.
그러나, 기능이 제한적이고 multi-container 파드나 deployment을 생성하는 것과 같이 advanced use case의 경우 길고 복잡한 커맨드를 작성해야 합니다. 또한 이러한 커맨드는 한 번 실행되고 잊혀집니다. 해당 커맨드를 실행했던 사람의 세션 기록에서만 볼 수 있습니다. 따라서 다른사람이 이 오브젝트가 어떻게 만들어졌는지 알기 어렵고 트래킹하기가 어렵습니다. 따라서 크고 복잡한 환경에서는 이러한 커맨드로 작업하기가 어렵습니다. 이 점이 오브젝트 configuration file로 오브젝트를 관리할 때 도움을 받을 수 있는 점입니다.
Imperative Object Configuration Files
Definition file (=configuration file, manifest file)을 만드는 것은 우리가 원하는 것을 yaml 형식으로 정확히 기록하고 kubectl create커맨드로 오브젝트를 만드는데 도움을 줍니다. yaml파일이 있으면 git과 같은 코드 레포지토리에 저장할 수도 있습니다. 프로덕션에 반영되기 전에 변경사항을 검토하고 승인 프로세스를 넣을 수도 있겠지요.
향후 변경사항이 있으면, 예를 들어 이미지 이름을 다른 버전으로 고칠 때, 이를 처리하는 여러 방법이 있습니다. 한 가지 방법은 kubectl edit커맨드를 사용하는 것입니다. 따라서 이 커맨드가 실행되면 오브젝트를 만드는 것과 유사하게 yaml definition file이 열립니다. 이것은 오브젝트를 만들 때 사용한 파일이 아닙니다. Kubernetes 메모리에 있는 유사한 Pod definition file입니다. 우리는 이 파일을 변경하고 저장하고 종료할 수 있습니다. 그러면 이 변경사항은 live object에 적용됩니다. 그러나 live object 와 로컬에 있는 definition file 사이에 차이가 있으니 주의해주세요.
kubectl edit커맨드를 사용해 만든 변경사항은 실제로 어디에도 기록되지 않습니다. 변경이 적용되면 로컬 definition file만 남는데, 이 definiton file에는 변경사항이 적용되지 않은 예전 버전입니다. 향후 당신이나 팀원이 kubectl edit커맨드를 사용해서 오브젝트가 변경된 사실을 모르고 오브젝트를 변경했다고 합시다. 변경사항이 적용될 때 이전 버전의 image는 손실됩니다. 따라서 kubectl edit 커맨드는 내가 더이상 configuration file을 의존하지 않을 것이라고 확신할 때 사용할 수 있습니다.
그러나 더 나은 방법은 먼저 로컬 버전 configuration file을 수정하는 것입니다. 즉, image 이름을 configuration file에서 먼저 수정하고, kubectl replace커맨드를 실행하여 오브젝트를 업데이트하는 방식입니다. 이렇게 하면 변경 사항이 기록되고, 변경 검토 프로세스의 일부로 추적할 수 있습니다. 때때로 오브젝트를 완전히 삭제하고 다시 만들어야 할 때가 있습니다. 이 경우에는 force 옵션과 함께 동일한 커맨드를 실행합니다.
지금까지도 이것은 imperative 접근 방식입니다. 어떻게 오브젝트를 생성하고 업데이트하는지 여전히 kubernetes에게 지시하고 있기 때문입니다. 먼저, 오브젝트를 생성하기 위해 kubectl create커맨드를 실행합니다. 그리고 kubectl replace커맨드를 오브젝트를 교체하기 위해 사용하거나 오브젝트를 삭제하기 위해 kubectl delete커맨드를 실행합니다. 그리고 이제 create 커맨드를 입력하면 어떻게 되나요? 오브젝트가 이미 존재하는데 create 커맨드를 실행하면 어떻게 될까요? 파드가 이미 존재한다는 에러가 뜹니다. 오브젝트를 업데이트할 때, replace커맨드를 실행하기 전에 오브젝트가 먼저 존재하는지 항상 확인해야 합니다. 오브젝트가 존재하지 않으면 replace 커맨드가 에러 메세지와 함께 실패합니다. 따라서 imperative 접근 방식은 항상 현재 구성을 알고 있어야 하고, 변경 전에 모든 것이 제자리에 있는지 체크를 해야 하므로 관리자에게 매우 부담이 됩니다.
Declarative
declarative 접근 방식은 우리가 작업해 온 오브젝트 configuration file을 동일하게 사용합니다. 대신 create나 replace커맨드가 아닌, kubectl apply커맨드를 사용합니다. kubectl apply커맨드는 아직 존재하지 않는 객체를 생성할 정도로 지능적입니다. 만약 configuration file이 여러 개 있는 경우, 단일 파일이 아니라 폴더 단위로 지정하면 여러 오브젝트를 한번에 생성할 수 있습니다. 오브젝트의 변경이 필요한 경우에는, 우리는 단순히 오브젝트의 configuration file을 업데이트하고 kubectl apply커맨드를 실행해주면 됩니다. 이번에는 오브젝트가 이미 존재한다는 것을 커맨드는 알고 있으며, 새로운 변경사항만 객체에 업데이트하게 됩니다. 따라서 객체가 이미 존재한다는 에러나 업데이트를 적용할 수 없다는 에러는 발생하지 않습니다. 이 방식은 항상 오브젝트를 업데이트하는 옳은 방법을 알아낼 것입니다. 앞으로 애플리케이션의 어떤 변경사항이든, 이미지 업데이트, configuration file의 필드 업데이트, 새로운 configuration file추가, 완전히 새로운 오브젝트간에, 우리가 해야할 일은 단순히 로컬 디렉토리를 업데이트하고, kubectl apply커맨드를 실행하는 것입니다.
Exam Tips
지금은 시험을 위한 몇 가지 팁을 알려드리겠습니다. 시험 관점에서, 시간을 최대한 아끼기 위해 imperative 방식을 사용할 수 있습니다. 예를 들어 질문이 파드를 생성하는 것이거나 주어진 이미지를 사용해 deployment를 생성하는 것이라면, imperative 커맨드는 빠르게 풀 수 있게 도와줄 것입니다. 따라서 imperative 커맨드를 연습하는 것이 중요합니다. 기존 오브젝트의 속성을 편집해야 한다면 kubectl edit커맨드가 가장 빠른 방법이겠지요? 만약에 예를 들어 여러 컨테이너가 필요한 경우나 환경 변수, 커맨드, 초기화 컨테이너 등 복잡한 요구사항이 있는 경우라면 configuration file을 사용하여 오브젝트를 만드는 것이 좋습니다. 이렇게 하면 혹시 실수를 했을 때 빨리 알아차리고 쉽게 고칠 수 있습니다. 이러한 경우에는 kubectl apply커맨드가 더 나은 선택이 될 것입니다. 접근 방식에 대한 더 자세한 내용은 kubernetes 공식 문서 페이지에서 익숙해질 수 있습니다.
imperative-command 에 대한 테스트 이다. 명령형 커맨드는 낯설기 때문에 테스트 본 내역을 정리해보고자 한다.
Deploy a pod named nginx-podusing the nginx:alpineimage.
kubectl run nginx-pod --image=nginx:alpine
Deploy a redispod using the redis:alpineimage with the labels set to tier=db.
kubectl run redis --image=redis:alpine -l=tier=db
Create a service redis-serviceto expose the redisapplication within the cluster on port 6379.
kubectl expose po redis --port=6379 --name=redis-service
Create a deployment named webappusing the image kodekloud/webapp-color with 3replicas.
kubectl create deployment webapp --image=kodekloud/webapp-color --replicas=3
Create a new pod called custom-nginxusing the nginximage and expose it on container port 8080.
kubectl run custom-nginx --image=nginx --port=8080
Create a new namespace called dev-ns. Use imperative commands.
kubectl create ns dev-ns
Create a new deployment called redis-deploy in the dev-nsnamespace with the redisimage. It should have 2replicas.
kubectl create deployment redis-deploy --image=redis --replicas=2 --namespace dev-ns
reate a pod called httpdusing the image httpd:alpine in the default namespace. Next, create a service of type ClusterIP by the same name (httpd). The target port for the service should be 80.
kubectl run httpd --image=httpd:alpine --port=80 --expose=true
kubectl apply command
Declarative
우리는 declarative한 방식으로 오브젝트를 관리하는데 kubectl apply커맨드가 어떻게 사용하는지 보았습니다. 이번 강의에서는 커맨드가 내부적으로 어떻게 작동하는지 조금 더 살펴보겠습니다.
Kubectl Apply
apply커맨드는 로컬 configuration file, kubernetes의 liev object definition, 마지막으로 적용된 구성을 변경사항을 결정하기 전에 고려합니다. 따라서 apply 커맨드를 실행할 때, 오브젝트가 아직 존재하지 않는 경우, 오브젝트가 생성됩니다. 오브젝트가 생성되면 오브젝트 configuration(우리가 로컬에서 만든 것과 유사)은 쿠버네티스 내에서 생성됩니다.
그러나 오브젝트의 상태를 저장하는 추가 필드가 있습니다. 이것이 Kubernetes 클러스터에 있는 오브젝트의 live configuration입니다.
우리가 작성한 로컬 오브젝트 configuration 파일의 YAML 버전은 json 형식으로 변환되고, 마지막으로 적용된 configuration으로 저장됩니다. 앞으로 오브젝트에 대한 모든 업데이트에 대해 어떤 변경이 live object에 적용되는지 세 가지 모두 비교하겠습니다.
-
Local file
-
Last applied Configuration
-
Kubernetes (Live object configuration)
예를 들어, nginx 이미지가 1.19로 업데이트되었을 때, kubectl apply 커맨드는 local file과 live configuration의 값을 비교합니다. 만약 차이점이 있다면 live configuration이 새 값으로 업데이트됩니다. 변경 후, 마지막으로 적용된 json 형식은 항상 최신 상태로 업데이트됩니다.
그렇다면 왜 우리는 last applied configuration이 필요할까요? type label과 같은 필드가 삭제되었다고 가정해 보겠습니다. 이제 kubectl apply 커맨드를 실행하면 마지막으로 적용된 configuration에는 레이블이 있었으나, 로컬 configuration에는 없다는 것을 알 수 있습니다. 이것은 그 필드를 live configuration에서 제거해야 함을 의미합니다. 따라서 live configuration에 필드가 있고 로컬이나 last applied configuration에 존재하지 않는다면, 필드는그대로 남게 됩니다. 그러나 로컬 파일에서 필드가 누락되고 마지막으로 적용된 configuration에 존재한다면, 이전 단계나 또는 kubectl apply 명령을 마지막으로 실행했을 때마다 해당 특정 필드가 있었고 현재 제거 중이라는 것을 의미합니다.
따라서 마지막으로 적용된 configuration은 로컬 파일에서 어떤 필드가 제거되었는지 파악하는 데 도움이 됩니다. 해당 필드는 실제 live configuration에서 제거된 것입니다. 방금 얘기한 내용을 Kubernetes 공식문서 페이지에서 자세히 설명합니다.
우리는 세 종류의 파일을 보았고, 로컬 파일이 로컬 시스템을 저장하고 있다는 것을 알았습니다. 라이브 오브젝트 configuration은 Kubernetes 메모리에 있습니다. 그런데 마지막으로 적용된 configuration이 저장되는 json file은 어디에 있을까요? Kubernetes 클러스터 자체의 live object configuration에 last applied configuration라는 주석으로 저장됩니다.
따라서 apply명령을 사용해야만 완료되고, kubectl create, replace 명령은 last applied configuration 을 저장하지 않는다는 것을 기억해주세요. 그러므로 imperative 방식과 declarative방식을 혼합하지 않도록 명심해야 합니다. 따라서 apply 커맨드를 사용할 때마다 live configuration내에서 변경사항을 결정하기 위해 local part definition file, live object configuration, last applied configuration stored within the live object configuration file 세가지 섹션을 모두 비교합니다.
