
2023/07/24 우리조의 이번 과제는 ELK스택의 발표 & 강의 를 하는것이었고 내가 맡은 부분인 Elastic search 와 고가용성 테스트 의 발표를 하기 위해 아래의 목차를 준비하였다.
Elastic Search - 고가용성 테스트
Elastic Search - 기본 CRUD 실습
Elastic Search - CRUD Quiz
Elastic Search - Batch Process 실습
Elastic Search - 검색 API 실습
Elastic Search - Query DSL 실습
Elastic Search - URL Request 실습
Elastic Search - Query Quiz
Elastic Search - 한국어 형태소 분석기 노리 적용 실습
Elastic Search - 노리 스피치 분석기 (음성삭제)
Elastic Search - 노리 한자 분석기
Elastic Search - 동의어 사전 정의 추가
Elastic Search - 롤오버 테스트
Elastic Search - 실제 국민 청원데이터로 실습
Kibana - DevTools 사용 및 차트 그려보기
Kibana - Dashboard 배치하기
# elastic search 실습
설치
https://www.elastic.co/kr/downloads/past-releases/elasticsearch-7-2-0
https://www.elastic.co/kr/downloads/past-releases/logstash-7-2-0
https://www.elastic.co/kr/downloads/past-releases/kibana-7-2-0
https://www.elastic.co/kr/downloads/past-releases/filebeat-7-2-0
클러스터 탐색
es 는 매우 포괄적이고 강력한 REST API 를 제공 한다.
그 API로 할 수 있는 몇가지 작업
-
클러스터 , 노드 및 색인상태, 상태 및 통계확인
-
CRUD 및 인덱스에 대한 검색 작업 수행
-
페이징, 정렬, 필터링, 스크립팅 집계 및 기타 여러가지 고급 검색 작업도 가능
curl 혹은 postman 혹은 kibana devtools 로 가능..
구성요소는 3가지가 있음. 리소스, 메서드, 메시지
RESTful 답게 요청..
자원(RESOURCE) - URI
행위(Verb) - HTTP METHOD
표현(Representations)
POST http://localhost:9200/users/_doc
{
"name": "TEST"
}클러스터 상태
-
클러스터가 어떻게 진행되고 있는 지 기본적인 확인
-
HTTP/REST 호출을 수행할 수 있는 모든 도구 사용이 가능함
-
/_cat/health?v 명령어 로 사용가능 -
녹색 : 모든것이좋음
-
노란색 : 모든 데이터를 사용할 수는 있지만 일부 복제본은 아직 할당되지 않음. ( 클러스터는 완전히 작동함, 샤딩작업이 아직 끝나지않음. 완벽하게 백업작업이 이루어지지 않았다.)
-
빨간색 : 어떤 이유로든 사용할 수 없음
-
여기 나와 있는 언더바가 있는 것들은 API 이지만 REST API와는 다르다.
가진 데이터 확인하기
-
갖고 있는 모든 인덱스 조회
-
_cat/indices?v
데이터 입력/ 조회 /삭제 / 업데이트 요약
-
입력 : PUT -> http:/localhost9200/index1/_doc/1 -d '{"num" : 1, "name" : "test"}'
-
-d 는 메세지 부분
-
업데이트 : POST http:/localhost9200/index1/type1/1/_update -d '{"num" : 1}'
인덱스 만들기
인덱스를 한번 만들어보자
- PUT /customer
그리고 잘 들어왔는지 확인해보자
- GET _cat/indices
간단한 데이터를 넣어보자
인덱스/타입/식별자
POST customer/type1/1
{
"name" : "test"
}수정하면 "_version" : 1, 이 올라감
만들었으니 조회해보자, ("_source") 안에 데이터 있음
- GET customer/type1/1
삭제해보자
- DELETE customer/type1/1
실행하면 "_version" : 3, 이 올라감..이걸 만약 초기화 하고싶다 하면
DELETE /customer 를 해서 새로 설정해줘야 함.
또한 굳이 인덱스만들고 타입만들지않아도 바로 쿼리넣어도 들어간다.
POST customer/type1/1
{
"name" : "test"
}업데이트는 아래것은 테이블을 아예 갈아 끼는것
POST customer/type1/1
{
"name" : "test1",
"age" : 12
}아래건 수정
POST customer/type1/1/_update
{
"doc" : {
"name" : "test2"
}
}업데이트는 수정 식으로 스크립트도 넣을 수 있음 (ctx = 현재 구문컨텍스트 에서 라는뜻)
POST customer/type1/1/_update
{
"script" : {
"inline" : "if(ctx._source.age < 100) {ctx._source.age++}"
}
}데이터 베이스 이다 보니 왠만한 건 다 가능하다.
간단한 CRUD 쿼리 퀴즈
QUIZ 시나리오
TourCompany에 오신걸 환영합니다 ! 이 여행사는 열분이 고객명단을 잘 관리해주리라 믿고 의뢰합니다. 다음 시나이로에 따라 여러분들의 작업을 진행하시면 됩니다.
이 회사에는 엘라스틱서치가 새로 도입되서 아무런 데이터도 없습니다. 고객관리를 위해 다음 데이터를 입력 하십시오. (index: tourcompany, Type: customerlist)
다음 임무를 수행하기 위해 쿼리문을 작성하고 데이터베이스 적용 하십시오.
-
- BoraBora 여행은 공항테러 사태로 취소되었습니다. BoraBora 여행자의 명단을 삭제 해주십시오.
-
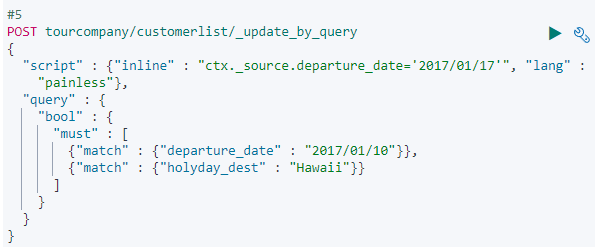
- Hawaii 단체 관람객의 요청으로 출발일이 조정 되었습니다. 2017/01/10 에 출발하는 Hawaii 의 출발일을 2017/01/17일로 수정해주세요.
-
- 휴일 여행을 디즈니랜드로 떠나는 사람들의 핸드폰 번호를 조회 하세요.
if 문이나 핸드폰번호 만 뽑아오는 부분은 제외하고 단순 CRUD만 실행해보기
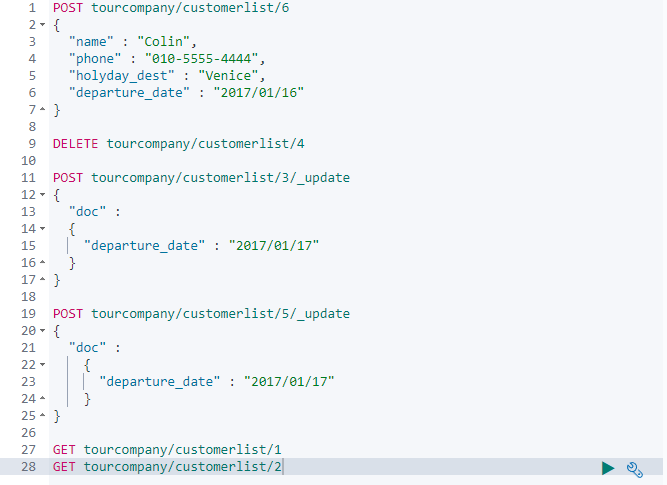
배치 프로세스
여태까지의 작업들을 한꺼번에 집어넣을수 있는 기능
-
bulk 라는 api 로 위의 작업들을 일괄적으로 수행할 수 있는 기능임
-
최대한 적은 네트워크 왕복으로 가능한 한 빨리 여러작업을 수행할 수 있는 매우 효율 적인 메커니즘
-
다음 예제로 알아보자
한꺼 번에 넣기
PUT /customer/type1/_bulk?pretty
{"index" : {"_id" : "1"}}
{"name" : "test1"}
{"index" : {"_id" : "2"}}
{"name" : "test2"}
{"index" : {"_id" : "3"}}
{"name" : "test3"}
{"index" : {"_id" : "4"}}
{"name" : "test4"}
일부러 실패
PUT /customer/type1/_bulk
{"index" : {"_id" : "1"}}
{"name" : "test1",}
{"index" : {"_id" : "2"}}
{"name" : "test2"}
{"index" : {"_id" : "3"}}
{"name" : "test3"}
{"index" : {"_id" : "4"}}
{"name" : "test4"}이렇게 넣어도 되고 수정도 가능, 합칠수도있음
POST /customer/type1/_bulk?pretty
{"update" : {"_id" : "1"}}
{"doc" : {"name" : "ttttt"}}
{"delete" : {"_id" : "4"}}- 행 하나가 실패되도 계속 진행함.
대충 이런식으로 진행함
검색 API
이제 조금 사용법이 갈라지게 되었다.
-
- REST 요청 "URI"를 통해 검색 매개변수 보내기
-
- REST 요청 본문을 통해 검색 매개변수 보내기
/bank/_search?q=*&sort=account_number:asc&pretty
q=* -> 모든 문서와 일치하도록
검색결과 확인
-
took : 검색하는데 걸린 시간
-
timed out : 검색 시간이 초과되었는지 여부
-
shards : 검색된 파편의 수와 성공 실패 파편의 수
-
hit : 검색결과
-
hits.hits : 검색결과의 실제 배열
Query DSL(Domain Specific Language)
- 쿼리를 실행하는데 사용할수있는 JSON 스타일 도메인 관련언어 제공함
이런식으로 사용하긴하는데 sample data를 넣고 실습을 진행해보자
POST /customer/_search
{
"query": {"match_all": {}}
}greater than or equal to
샘플데이터 넣자
샘플데이터 넣고 난 후.. 조회해보자
- GET kibana_sample_data_flights/_search?q=*
개수조절 가능
GET kibana_sample_data_flights/_search
{
"size": 1000
}티켓 프라이스 정렬
- GET kibana_sample_data_flights/_search?q=*&sort=AvgTicketPrice:desc
body 방식 (데이터는 10개만나옴)
POST kibana_sample_data_flights/_search
{
"query": {"match_all": {}},
"sort" : {"AvgTicketPrice" : "desc"}
}AvgTicketPrice 결과만 보기
POST kibana_sample_data_flights/_search
{
"query": {"match_all": {}},
"sort" : {"AvgTicketPrice" : "desc"},
"_source": "AvgTicketPrice"
}조건넣기
POST kibana_sample_data_flights/_search
{
"query": {"match": {"DestCountry" : "US"}},
"sort" : {"AvgTicketPrice" : "desc"}
}조건 2개
POST kibana_sample_data_flights/_search
{
"query": {
"bool": {
"must": {"match" : {"DestCountry" : "US"}},
"must_not": {"match" : {"FlightNum" : "R43CELD"}}
}
}
}URL로 요청
인덱스랑 타입 설정안하면 다 나옴
- GET _search
써니 검색어결과
- GET kibana_sample_data_flights/_search?q=Sunny
다중검색어
- GET kibana_sample_data_flights/_search?q=OriginWeather:Sunny AND DestCountry:AU
티켓 가격 정렬
- kibana_sample_data_flights/_search?q=OriginWeather:Sunny AND DestCountry:AU&sort=AvgTicketPrice:desc
QUIZ
이전에 등록해놓은 tourcompany 를 그대로쓰고..
tourcompany 인덱스에서 010-3333-5555 를 검색하십시오
휴일 여행을 디즈니랜드로 떠나는 사람들의 핸드폰 번호를 조회하십시오 (Phone필드만 출력)
departure date 가 2017/01/10 과 2017/01/11 인 사람을 조회하고, 이름순으로 출력하십시오. (name과 departure date 필드만 출력)
BoraBora 여행은 공항 테러 사태로 취소 되었습니다. BoraBora 여행자의 명단을 삭제 해주십시오.
Hawaii 단체 관람객의 요청으로 출발일이 조정 되었습니다. 2017/01/10 에 출발하는 Hawaii의 출발일을 2017/01/17 로 수정 해주십시오.
POST tourcompany/customerlist/_bulk
{"index" : {"_id" : "1"}}
{"name" : "Alfred", "phone" : "010-1234-5678", "holyday_dest" : "Disneyland", "departure_date" : "2017/01/20"}
{"index" : {"_id" : "2"}}
{"name" : "Huey", "phone" : "010-2222-4444", "holyday_dest" : "Disneyland", "departure_date" : "2017/01/20"}
{"index" : {"_id" : "3"}}
{"name" : "Naomi", "phone" : "010-3333-5555", "holyday_dest" : "Hawaii", "departure_date" : "2017/01/10"}
{"index" : {"_id" : "4"}}
{"name" : "Andra", "phone" : "010-6666-7777", "holyday_dest" : "Bora Bora", "departure_date" : "2017/01/11"}
{"index" : {"_id" : "5"}}
{"name" : "Paul", "phone" : "010-9999-8888", "holyday_dest" : "Hawaii", "departure_date" : "2017/01/10"}
{"index" : {"_id" : "6"}}
{"name" : "Clin", "phone" : "010-5555-4444", "holyday_dest" : "Venice", "departure_date" : "2017/01/16"}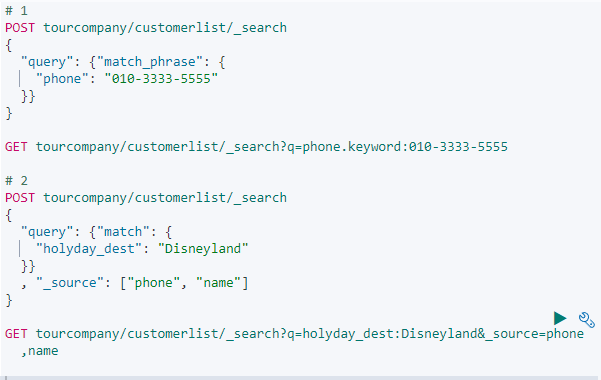


lang = 언어상관없이 한다는 뜻인데 별 의미는없고 항상 들어감
키바나에서 기능이 있기 때문에 집계기능은 넘어가자
# 노리 설치
-
한글에는 성능을 발휘하기 쉽지 않음
-
조사나 어미의 접미사가 명사, 동사등과 결합하기 때문에 기본 형태소 분석기로는 분석하기가 쉽지 않음. (띄어쓰기 조사 등등)
-
"은", "는", "이", "가", "을", "를"
-
동음이의어 예를 들어 "체리"라는 단어는 식재료인 "체리"와 사람 이름인 "체리"로 사용될 수 있음
-
한글을 분석해서 저장함
-
아버지가 -> 아버지, 가 로 나눠줌
-
Mecab 라는 라이브러리 사용
Mecab
- 언어에 존재하는 수많은 규칙과 예외사항으로 인해 개발이 어려운데, 한국어 형태소의 확률적 모델링을 수행한 분석기임.
1.3 한국어 형태소가 없을 때 문제점 테스트
데이터 삽입
POST test/data
{
"제목":"안녕하세요.",
"내용":"안녕하세요. 이동명입니다.",
"날짜":"2019-12-28",
"비밀번호":"1234"
}첫번째 데이터 검색 요청
GET _search?q="안녕"데이터 검색 결과 - 실패
{
"took" : 11,
"timed_out" : false,
"_shards" : {
"total" : 6,
"successful" : 6,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}두 번째 데이터 검색 요청
GET /_search?q="안녕하세요"데이터 검색 결과 - 성공
{
"took" : 11,
"timed_out" : false,
"_shards" : {
"total" : 6,
"successful" : 6,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "test",
"_type" : "data",
"_id" : "lxNPSm8BB_pfiKR1HdID",
"_score" : 0.2876821,
"_source" : {
"제목" : "안녕하세요.",
"내용" : "안녕하세요. 이동명입니다.",
"날짜" : "2019-12-28",
"비밀번호" : "1234"
}
}
]
}
}결론: 풀 텍스트 검색 불가능...
해결 방법: 노리를 사용해서 분석한 데이터를 입력하면 검색하도록 만들 수 있음
설치
엘라스틱 서치 bin 폴더에서 명령어 이용..
.\elasticsearch-plugin.bat install analysis-nori
설치 후 재부팅
POST _analyze
{
"analyzer" : "nori",
"text" : "독산역 주변에 playdata 가 생겼어요."
}단어가 토큰별로 다 찢어지는 모습을 볼 수 있다.
노리 토크나이저와 토큰 필터
노리는 하나의 토크나이저와 두 개의 토큰 필터로 구성됨
- nori_tokenizer : 토크나이저 (공백, 문자, 구두점 등을 사용해서 잘게 나눌수있음)
- nori_part_of_speech : 토큰필터(음성삭제)
- nori_readingform : 토큰필터(한자필터)
토크나이저: 단어(term또는 token)를 분리
토큰 필터: 단어들을 검색 가능 하도록(searchable) 가공
토크나이저 + 토큰 필터 → 분석기(Analyzer) 한국어의 풀텍스트 서치 가능!
노리 토크나이저(단어를찢는 핵심 토크나이저)
decompound_mode: 토크 나이저가 복합 토큰을 처리하는 방법을 결정
none : 화합물 분해없음 -> 독산 역
discard : 화합물 분해 후 원래 형태버림 독산 역 -> 독산, 역 (가곡역 사라짐)
mixed : 분해하고 원래 형태 유지 -> 독산 역 -> 독산, 역 (둘다저장)
user_dictionary
- Nori 토크 나이 저는 기본적으로 mecab-ko-dic 사전을 사용
- 사용자 지정 명사 (NNG)가있는 user_dictionary가 기본 사전에 추가 가능
- 사전은 다음 형식이어야합니다. →<토큰> [<토큰 1> ... <토큰 n>]
$ES_HOME/config/userdict_ko.txt
세종시 세종 시- 첫 번째 토큰은 필수이며 사전에 추가해야하는 사용자 지정 명사를 나타냅니다. 복합 명사의 경우 사용자 정의 분할은 첫 번째 토큰 ([<토큰 1> ... <토큰 n>]) 후에 제공 될 수 있습니다. 사용자 정의 복합 명사의 분할은 decompound_mode 설정에 의해 제어
노리 기능을 커스터마이징해 사용
사전 파일 생성 - userdict_test.txt
안녕하세요 안녕 하세 요
이동명입니다 이동명 입니다사전 파일 배치 - config 폴더 에 넣기
가장 먼저 인덱스가 노리의 분석 기능을 사용할 수 있도록 설정이 필요
korean_analyzer1 라는 인덱스를 추가해준다. 옵션은 mixed 로 추가했으니 화학물 분해 후 전부다
저장할 것 임..
PUT korean_analyzer1
{
"settings":{
"analysis":{
"tokenizer":{
"korean_nori_tokenizer":{
"type":"nori_tokenizer",
"decompound_mode":"mixed",
"user_dictionary":"userdict_test.txt"
}
},
"analyzer":{
"nori_analyzer":{
"type":"custom",
"tokenizer":"korean_nori_tokenizer"
}
}
}
}
}POST korean_analyzer1/_analyze
{
"analyzer":"nori_analyzer",
"text":"안녕하세요 이동명입니다."
}nori_part_of_speech (음성삭제 테스트)
nori_part_of_speech 토큰 필터는 품사 태그 세트와 일치하는 토큰을 제거
지원되는 음성 태그 및 의미의 목록은 여기에서 확인
http://lucene.apache.org/core/7_4_0/analyzers-nori/org/apache/lucene/analysis/ko/POS.Tag.html
nori_sample 이라는 인덱스 추가 숫자에 해당하는 태그는 삭제하도록 설정
PUT nori_sample
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "nori_tokenizer",
"filter": [
"my_posfilter"
]
}
},
"filter": {
"my_posfilter": {
"type": "***nori_part_of_speech",
"stoptags": [
"NR"
]
}
}
}
}
}
}다음 질의를 하면 NR에 해당하는 내용은 삭제
NR = Numeral 숫자
무언가 우리의 검색을 방해하는 것들이있다. 그것이 만약 숫자면 제거..
GET nori_sample/_analyze
{
"analyzer": "my_analyzer",
"text": "일곱 강아지가"
}일곱이라는 데이터가 안나오는걸 볼수있다.
스탑 태그의 디폴트 세팅
"stoptags": [
"E",
"IC",
"J",
"MAG", "MAJ", "MM",
"SP", "SSC", "SSO", "SC", "SE",
"XPN", "XSA", "XSN", "XSV",
"UNA", "NA", "VSV"
]nori_readingform
nori_readingform 토큰 필터는 한자로 작성된 토큰을 한글 형식으로 다시 작성
한자 → 한글
PUT hanja
{
"settings": {
"index":{
"analysis":{
"analyzer" : {
"my_analyzer" : {
"tokenizer" : "nori_tokenizer",
"filter" : ["nori_readingform"]
}
}
}
}
}
}
GET hanja/_analyze
{
"analyzer": "my_analyzer",
"text": "李東明"
}
한자 해석 완료 ( 다 되는건 아님)동의어 추가
PUT test6
{
"settings": {
"analysis": {
"analyzer": {
"custom_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase", "custom_synonym_filter"]
}
},
"filter": {
"custom_synonym_filter": {
"type": "synonym",
"synonyms_path": "synonyms.txt"
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "custom_analyzer"
}
}
}
}
PUT test6/_doc/1
{
"name": "삼전"
}
PUT test6/_doc/2
{
"name": "삼성전자"
}
POST test6/_search
{
"query": {
"match": {
"name": "삼전"
}
}
}
인덱스에 적용
매핑 작업 (셋팅까진 같은데 매핑추가)
PUT article
{
"settings": {
"analysis": {
"analyzer": {
"nori": {
"tokenizer": "nori_tokenizer"
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"nori": {
"type": "text",
"analyzer": "nori"
}
}
}
}
}
}
PUT article/_bulk
{"index": {}}
{"title":"양산 삼호지구 뉴딜사업 규모 확 늘린다"}
{"index": {}}
{"title":"무궁화 프로젝트, ‘end’가 아닌 ‘and'인 이유"}
{"index": {}}
{"title":"인천시 서구, 가재울마을 도시재생뉴딜사업 본격추진"}
{"index": {}}
{"title":"도시재생으로 활력 키우는 춘천시…인구·관광객 유치 효과 기대"}
{"index": {}}
{"title":"임실군, 농촌맞춤형 도시재생 구현 ‘앞장’"}
{"index": {}}
{"title":"광명시, '소규모주택정비사업' 시민들 많은 관심"}
{"index": {}}
{"title":"금천구 독산동 우시장 일대 도시재생 ‘성과공유회’ 개최"}
{"index": {}}
{"title":"[기고] 지역 전통주, 도시재생사업으로 마을기업 이룬다면"}
{"index": {}}
{"title":"국토부 'LH에 도시재생 직렬 신설 검토 중'"}
{"index": {}}
{"title":"대전 중구, 내년까지 동서대로 1421번길 일원… 40개 건물·65개 업소 간판 개선"}대전 치면 나오는결과에 동서 쳐보자 또는 뉴딜
title.nori
POST article/_search
{
"query" : {
"match" : {
"title.nori": "대전"
}
}
}롤오버 테스트
롤오버에 앞서서
Elasticsearch의 Index Lifecycle Management (ILM)
Elasticsearch의 Index Lifecycle Management (ILM)은 색인의 생명주기를 관리하는 기능입니다. ILM을 사용하면 색인을 생성, 유지, 로테이션, 삭제하는 과정을 자동화하고 관리할 수 있습니다. 이를 통해 데이터의 보존 정책을 쉽게 적용하고, 용량을 효율적으로 관리하며, 클러스터 성능을 최적화할 수 있습니다.
Hot Phase (핫 단계):
색인이 생성되고 활성화되어 있는 단계입니다.
데이터를 색인하고 새로운 문서를 추가하는 단계입니다.
이 단계에서는 검색과 색인 작업이 주로 이루어집니다.
일반적으로 성능이 중요한 시기이므로 높은 성능을 위해 빠른 디스크와 적절한 리소스를 할당하는 것이 일반적입니다.
Warm Phase (웜 단계):
웜 단계는 핫 단계 이후에 데이터가 더 이상 색인되지 않는 시기입니다.
여전히 검색이 가능하지만, 색인 작업은 더 이상 수행되지 않습니다.
이 단계에서는 디스크 공간을 절약하고 검색 성능을 향상시키기 위해 더 느린 디스크나 클라우드 스토리지 등을 사용할 수 있습니다.
Delete Phase (삭제 단계):
삭제 단계는 색인의 삭제를 처리하는 단계입니다.
정책에 따라 일정 시간이 지난 후 삭제되는 색인을 관리합니다.
삭제된 색인은 용량을 확보하고 클러스터 자원을 최적화합니다.
1. Index Lifecycle Management 정책 추가
PUT _ilm/policy/rolling
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_age": "1d",
"max_size": "1gb",
"max_docs": 4
},
"set_priority": {
"priority": 100
}
},
"min_age": "0ms"
}
}
}
}
rolling-test 이름으로 시작하는 모든 index에, rolling 라이프사이클을 적용! rollover대상의 alias는 rolling-write-index라는 alias이다.
"rolling-test"라는 이름으로 시작하는 모든 인덱스에 ILM 템플릿을 적용합니다. 이 템플릿은 "rolling"이라는 ILM 정책을 사용하며, 롤오버 대상의 별칭(alias)로 "rolling-write-index"를 설정합니다. 또한, 인덱스의 샤드 수를 1로, 복제본 수를 0으로 설정합니다.
PUT _template/rolling
{
"order": 1,
"version": 1,
"index_patterns": [
"rolling*"
],
"settings": {
"index": {
"lifecycle": {
"name": "rolling",
"rollover_alias": "rolling-write-index"
},
"number_of_shards" : "1",
"number_of_replicas" : "0"
}
}
}alias를 처음에는 template에 넣어뒀다가, 아래와같은 error와 함께 rolling이 제대로 안되서 index시점에 따로 alias를 생성해주었다.
rolling-test-000001"이라는 이름의 인덱스를 생성하고, 별칭 "rolling-write-index"를 사용하여 롤오버 대상 인덱스로 설정합니다. 이 때, "rolling-write-index"를 쓰기 인덱스로 설정합니다.
PUT rolling-test-000001
{
"aliases": {
"rolling-write-index": { "is_write_index": true }
}
}ILM poll 주기 10초로 변경 (default 10분)
rolling-test"라는 이름의 ILM 정책을 생성합니다. 이 정책은 "hot" 단계를 포함하한 액션이다.
"rollover" 액션: 인덱스의 최대 기간 1일, 최대 크기가 1KB, 최대 문서 수가 4개를 초과하면 롤오버(새로운 인덱스 생성)합니다.
"set_priority" 액션: 우선순위를 100으로 설정합니다.
또한"hot" 단계에 진입하는 최소 나이는 1분입니다.
PUT /_cluster/settings
{
"transient" : {
"indices.lifecycle.poll_interval" : "10s"
}
}3개의 doc 추가
POST rolling-write-index/_doc
{"id":1}
POST rolling-write-index/_doc
{"id":2}
POST rolling-write-index/_doc
{"id":3}아래의 명령어로 확인 가능
GET rolling-write-index/_ilm/explain
GET /_cat/aliases/rolling-write-index?v
index가 rolling, 굴러가는 모양이다.
롤링하는 순간
rolling-test-000001이
"rolling-write-index": {
"is_write_index": false
}가 되고
rolling-test-000002는
"rolling-write-index": {
"is_write_index": true
}가 된다.
즉 rolling-write-index로 검색하면 두 index모두에서 검색가능하지만, indexing하면 000002에만 인덱싱된다. 000001 인덱스의 크기는 더이상 늘지 않는 것이다.
장점
-
데이터의 지속적인 수집: 롤오버를 사용하면 계속해서 데이터를 수집하고 새로운 인덱스에 저장할 수 있습니다. 롤오버를 통해 새로운 인덱스가 자동으로 생성되고, 이전 인덱스에는 쓰기 작업이 중지되어 안정적인 데이터 수집이 가능해집니다.
-
검색 성능 향상: 롤오버를 통해 데이터가 여러 개의 작은 인덱스에 분산되어 저장됩니다. 이렇게 작은 인덱스를 사용하면 검색 작업의 성능이 향상될 수 있습니다. 작은 인덱스는 쿼리 처리 시간을 줄이고, 더 빠른 응답 시간을 제공할 수 있습니다.
-
용량 및 관리 효율성: 롤오버를 통해 인덱스 크기가 제어될 수 있습니다. 큰 인덱스 대신 작은 인덱스를 사용하면 디스크 공간을 효율적으로 활용할 수 있고, 관리 작업도 더 간단해집니다. 또한 롤오버된 인덱스는 삭제 또는 아카이빙 등의 관리 작업을 수행하기 용이합니다.
-
ILM (Index Lifecycle Management)의 효율적인 활용: 롤오버는 ILM 정책과 함께 사용될 수 있습니다. ILM을 통해 롤오버, 인덱스 크기 조정, 데이터 유지 기간 설정 등 다양한 자동화된 관리 작업을 수행할 수 있습니다. 롤오버를 활용하면 ILM을 통해 데이터의 수명 주기를 관리하고, 성능 및 용량 요구 사항에 맞게 데이터를 자동으로 이동하고 삭제할 수 있습니다.
-
가용성 및 복구: 롤오버를 사용하면 장애가 발생했을 때도 데이터의 일부만 손실할 수 있습니다. 롤오버된 인덱스는 다른 인덱스와 분리되어 있으므로 장애가 발생해도 다른 인덱스의 데이터에는 영향을 미치지 않습니다. 따라서 데이터의 가용성과 복구 가능성이 향상됩니다.
활용방도
-
데이터 분리 및 용량 제어
-
성능 및 확장성 향상
-
데이터 수명 주기 관리
-
백업 및 복구
-
시간에 따라 나눌수도 있고, 데이터 분류에 따라 나눌수도있고, 데이터 양이나 날짜 모든 조건 가능
국민청원 데이터 넣어서 실습해보기
-
ren petitions_201* *.json 으로 json 다 찍자..
-
ls petitions_201* | xargs -i mv {} {}.json
근데 관건은 여러개의 파일이 올라가지 않는다는 사실.. 다 올리려면 1시간도 넘게 걸리겠는데 누가 이렇게 할까? 그래서 한꺼번에 _bulk 로 올릴거임..
하지만 _bulk를 사용하려면 현재 데이터의 포맷을 _bulk 가능한 형태로 바꾸어야 한다.
앞서 간단히 살펴보았는데 위에는 첫줄에는 index와 id등 어떤 명령을 전달할 것인지가 먼저 명시돼야 하고 두번째 줄에는 전달하는 명령에 필요한 데이터를 넣어야 한다. 그러나 우리가 전달한 json 파일은 데이터만 입력돼 있으므로 이를 변경할 필요가 있다.
아래의 "{"category""을 "{"index":{"_index": "" + fileName + ""}}\n{"category""로 대체 하는 클래스를 만들어서 돌리자..
window
- for %F in (*.bat) do curl -H "Content-Type: application/x-ndjson" -XPOST "localhost:9200/bank/account/_bulk?pretty" --data-binary @%F
bash
- ls *.bat | xargs -i curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary @{}
데이터를 넣어보자..
-
만들어 놓은 JsonToEsBatchConverter.java 를 이용해서 .bat 파일을 추출해준다. (이 과정속에선 타입의 혼동을 줄이기 위해 "_type" : "_doc" 내용을 추가 하였음)
-
한글 형태소 분석기 nori 적용을 위해 자동으로 Mapping 을 해주는 ESIndexSettingsGenerator.java 파일을 이용해서 결과값을 txt 파일로 빼준다음에 모두 Kibana dev tools 에서 추가를 해준다. ( 이 과정속에서 한국어 형태소 분석기 적용을 위한 우리의 필드 중 한국어가 들어가는 content 필드와 title 필드를 Mapping 해준다.)
-
Mapping 이 다 완료되면 아래의 명령어를 통해 bulk로 밀어넣자
신변불안 , 정치 데이터 분석, 사회 문제 데이터 분석 등등 검색이 안될거임
그래서 노리 분석기 매핑을 해줘야 함.
자동 프로그램을 짜서 노리분석기를 content 필드와 title 필드에 맞게 끔 뽑아내자..
# Kibana 사용
시각화
- 총 게시글 수 표현
Mtric -> 총 게시글 수 저장
- 연도별 게시글 수
Vertical bar -> 연도 별 게시글 수 저장
- 상위 15개 데이터
Pie 차트 -> 상위 15개 데이터 저장
- 상위 15개 카테고리 2
tag cloud -> 상위 15개 카테고리 2 저장
- 시간에 따른 게시글 갯수
Visual Builder ->
EveryThing으로 풀고 갯수저장
- 동의수 top 10
data table ->
Kibana의 Uptime Monitors 기능은 시스템 또는 서비스의 가용성을 모니터링하는 기능입니다. 이 기능을 사용하여 여러 서버, 웹사이트, 애플리케이션 등의 상태를 실시간으로 추적하고, 장애 상황을 감지할 수 있습니다.
Uptime Monitors 기능을 활용하는 주요 상황과 사용 예시는 다음과 같습니다:
서비스 가용성 모니터링: 웹사이트, API, 마이크로서비스 등의 서비스의 가용성을 모니터링할 수 있습니다. Uptime Monitors는 정기적으로 서비스에 접근하여 응답을 확인하고, 서비스의 상태를 추적합니다. 이를 통해 서비스의 다운타임, 응답 지연 등의 문제를 식별하고 대응할 수 있습니다.
서버 상태 모니터링: 서버나 가상머신의 상태를 모니터링할 수 있습니다. 서버의 ping 또는 TCP 연결을 확인하여 서버의 동작 상태를 감시할 수 있습니다. 이를 통해 서버 다운 또는 네트워크 연결 문제 등의 상황을 파악하고 조치할 수 있습니다.
서비스 등록 확인: Uptime Monitors를 사용하여 서비스의 등록 여부를 확인할 수 있습니다. 예를 들어, 도메인이나 IP 주소가 변경되었을 때, 새로운 주소로 서비스가 등록되었는지 확인할 수 있습니다. 이를 통해 서비스 등록 문제를 조기에 파악하고 대응할 수 있습니다.
경고 및 알림: Uptime Monitors를 설정하여 서비스나 서버의 문제를 감지하고, 경고를 받을 수 있습니다. 예를 들어, 서비스의 응답이 지연되거나 실패할 경우, 설정한 경고 조건에 따라 알림을 받을 수 있습니다. 이를 통해 잠재적인 장애 상황을 신속하게 대응할 수 있습니다.
이러한 Uptime Monitors 기능을 활용하여 시스템의 가용성을 모니터링하면, 장애 상황을 신속하게 인지하고 대응할 수 있습니다. 시스템의 안정성을 유지하고 사용자 경험을 향상시키기 위해 Uptime Monitors를 사용할 수 있습니다.
Kibana APM (Application Performance Monitoring)은 애플리케이션의 성능을 모니터링하고 분석하는 기능을 제공하는 도구입니다. APM은 애플리케이션의 트랜잭션, 서비스 요청, 오류 등의 데이터를 수집하고 시각화하여 애플리케이션의 성능 트렌드와 문제를 파악할 수 있도록 도와줍니다.
Kibana APM의 주요 기능은 다음과 같습니다:
트랜잭션 모니터링: APM은 애플리케이션의 트랜잭션을 추적하고 모니터링합니다. 애플리케이션 내에서 발생하는 요청의 흐름과 성능을 시각화하여 확인할 수 있습니다. 트랜잭션의 지연 시간, 호출 스택, 데이터베이스 쿼리 등의 정보를 제공하므로 성능 문제의 원인을 식별할 수 있습니다.
오류 추적: APM은 애플리케이션에서 발생한 오류와 예외를 추적합니다. 오류 발생의 원인과 위치, 오류 발생 비율 등을 확인하여 애플리케이션의 안정성과 신뢰성을 개선할 수 있습니다.
성능 분석과 경고: APM은 애플리케이션의 성능 지표를 수집하고 분석하여 성능 문제를 파악합니다. 지연 시간, 처리량, 에러 비율 등의 지표를 실시간으로 모니터링하고, 설정한 경고 조건에 따라 알림을 받을 수 있습니다.
분산 추적과 서비스 맵: APM은 애플리케이션의 분산 환경에서 여러 서비스 및 컴포넌트 간의 상호 작용을 추적하고 시각화합니다. 이를 통해 서비스 간의 종속성과 성능 이슈를 파악할 수 있으며, 전체 시스템의 동작을 이해하는 데 도움을 줍니다.
후기
어느정도는 순조로웠지만 8시간의 시간이 주어진것에 대해서 처음엔 너무 시간이 여유로운 것 같아서 시간이 남을 것 같아서 걱정했지만.. 그건 걱정에 불과했다.. 시간이 조금 촉박해서 과정상 생략한 부분도 많아서 조금 아쉬운 부분도 있었고, 수업을 듣는 분들의 JDK 버전과 윈도우 환경변수 부분에서 막힌부분이 꽤 있었고, 하나하나 다 잡고 갈 수 없었기에 직접 실습을 못해본 부분도 있어서 아쉬웠다.
하지만 이번 과제를 준비하는 과정에 있어서 이때가 아니면 ELK 언제 공부해보나 싶기도하다. 강사님이 흥미롭고 재미있는 주제를 준 만큼 조원 끼리 열심히 공부하였고 의미있는 시간이 되었다. 다음 프로젝트나 파이널 프로젝트때 꼭 도입해보고 싶은 기술 중 하나이다. 유익하였다.
