
이번 시간에는 고급 주제들에 대해 살펴 볼 것이다.
다룰려는 주제들은 아래와 같다.
- 예외 처리
- 엔티티 비교
- 프록시 심화 주제
- 성능 최적화
4.1 N+1 문제
4.2 읽기 전용 쿼리 성능 최적화
4.3 배치 처리
4.4 SQL 쿼리 힌트 사용
4.5 트랜잭션을 지원하는 쓰지 지연을 통한 성능 최적화
그럼 차근 차근 시작해보겠다.
면접 단골 주제인 N+1 문제가 궁금하신 분들은 4 인덱스로 바로 넘어가시면 될 것 같다.
1. 예외 처리
1.1 JPA 표준 예외
JPA 표준 예외들은 모두 RuntimeException의 자식인 javax.persistence.PersistenceException의 자식 클래스이다.
따라서 JPA 예외는 모두 언체크 예외이다.
JPA 표준 예외는 크게 트랜잭션 롤백을 표시하는 예외와 트랜잭션 롤백을 표시하지 않는 예외 로 나뉜다.
트랜잭션 롤백을 표시하는 예외는 심각한 예외이기 때문에 복구해서는 안 된다.
만약 이 예외가 발생할 때 강제로 커밋하면 트랜잭션이 커밋되지 않고, javax.persistence.RollbackException이 발생한다.
다만 트랜잭션 롤백을 표시하지 않는 예외는 심각한 예외가 아니기에 개발자가 트랜잭션을 커밋할지 롤백할지 판단하면 된다.
예외들은 아래 표에 정리하였으니 개발에 참고하면 된다.
트랜잭션 롤백을 표시하는 예외
| 예외 클래스 | 설명 |
|---|---|
javax.persistence.RollbackException | EntityTransction.commit() 실패 시 발생. 롤백이 표시되어 있는 트랜잭션 커밋 시에도 발생 |
javax.persistence.OptimisticLockException | 낙관적 락 충돌 발생 시 롤백 |
javax.persistence.PessimisticLockException | 비관적 락 충돌 발생 시 롤백 |
org.springframework.transaction.TransactionRequriedException | 트랜잭션이 필요할 때 트랜잭션이 없으면 발생 |
javax.persistence.EntityExistsException | entityManager.persist() 호출 시 이미 같은 엔티티가 존재할 때 발생 |
javax.persistence.EntityNotFoundException | EntityManager.getReference(..)를 호출했는데 실제 사용 시 엔티티가 존재하지 않으면 발생 |
트랜잭션 롤백을 표시하지 않는 예외
| 예외 클래스 | 설명 |
|---|---|
javax.persistence.NoResultException | Query.getSingleResult() 조회 결과가 없을 때 발생 |
javax.persistence.NonUniqueResultException | 단일 결과가 예상되었지만 여러 개가 반환될 때 발생 |
javax.persistence.LockTimeoutException | 비관적 락에서 시간 초과 시 발생 |
javax.persistence.QueryTimeoutException | 쿼리 실행 시간 초과 시 발생 |
1.2 스프링 프레임워크의 JPA 예외 변환
서비스 계층에서 데이터 접근 계층의 구현 기술에 직접 의존하는 것은 좋은 설계라고 할 수 없다.
예외도 마찬가지로, 서비스 계층에서 JPA의 예외를 직접 사용하여 JPA에 의존하는 것은 좋지 못하다.
스프링은 이 문제를 해결하기 위해 데이터 접근 계층에 대한 예외를 추상화하여 개발자에게 제공한다.
이 기능 (=스프링 프레임워크가 제공하는 JPA 예외 변환기) 을 적용하려면
PersistenceExceptionTranslationPostProcessor 를 스프링 빈으로 등록하면 된다.
이것을 등록하면 @Repository 어노테이션을 사용한 곳에 예외 변환 AOP를 적용해서 JPA 예외를 스프링 프레임워크가 추상화한 예외로 변환해준다.
<bean class="org.springframework.dao.annotation.PersistenceExceptionTranslationPostProcessor"/> 혹은 JavaConfig를 사용한다면
@Bean
public PersistenceExceptionTranslationPostProcessor exceptionTranslation(){
return new PersistenceExceptionTranslationPostProcessor();
}이렇게 등록하면 된다.
이렇게 예외 변환을 적용한 상태에서 변환 되지 않는 예외를 반환하고 싶다면 ,
변환 되지 않는 예외를 반환하고 싶은 메소드의 throws 절에 그대로 반환할 JPA 예외를 명시하면 된다.
public member findMember () throws javax.persistence.NoResultException{
.....
}1.3 트랜잭션 롤백 시 주의사항
트랜잭션 롤백을 하면 데이터베이스만 롤백되는 것이지 수정한 자바 객체까지 원상태가 되지는 않는다.
따라서 객체는 수정된 상태로 영속성 컨텍스트에 그대로 남아있게 된다.
그래서 트랜잭션이 롤백된 영속성 컨텍스트를 그대로 사용하는 것은 위험하고,
새로운 영속성 컨텍스트를 생성하거나 EntityManager.clear() 를 호출해서 영속성 컨텍스트를 초기화 한 후 사용해야 한다.
스프링 프레임워크는 이 문제를 예방하기 위해 기본적으로 트랜잭션 AOP 종료 시점에 트랜잭션을 롤백하면서 영속성 컨텍스트도 함께 종료하기 때문에 문제가 발생하지 않는다.
또한 OSIV 처럼 영속성 컨텍스트의 범위를 트랜잭션 범위보다 넓게 사용하는 경우에는, 트랜잭션 롤백이 일어나면 영속성 컨텍스트를 초기화해서 다른 트랜잭션에서 잘못된 영속성 컨텍스트를 사용하는 문제를 예방한다.
2. 엔티티 비교
2.1 영속성 컨텍스트가 같을 때 엔티티 비교
앞선 장에서 설명했던 내용이지만 영속성 컨텍스트가 같을 때
동일한 엔티티를 조회하면 반환된 엔티티는 항상 같다.
단순히 내부 값만 같은 것이 아니라 참조 주소도 같다.
@Transational
public class Test {
@Autowired MemberRepository memberRepository;
@Test
public void test(){
Member member = new Member("member1");
Long savedId = member.getId();
memberRepository.save(member);
Member findMember = memberRepository.findOne(saveId);
System.out.println(member == findMember);
}
}
//결과 true위의 예시 코드에서 콘솔에는 true가 출력된다.
당연한 말이지만 JPA는 영속성 컨텍스트를 지원한다.
그리고 위의 예시는 같은 트랜잭션 범위에 있어 같은 영속성 컨텍스트를 사용하게 되고, 따라서 같은 회원을 조회할 때 DB에서 직접 조회하여 회원 엔티티를 반환하는 것이 아닌 영속성 컨텍스트에 있는 엔티티를 반환해주기 때문에 주소값이 같을 수 밖에 없다.
정리하자면 같은 영속성 컨텍스트를 사용할 때 엔티티를 비교하면
동일성 , 동등성, 데이터 베이스 동등성 을 모두 만족하게 된다.
2.2 영속성 컨텍스트가 다를 때 엔티티 비교
2.1과 코드는 유사하지만 테스트 클래스에 @Transaction이 없고 Repository에만 @Transation이 있다면 트랜잭션은 Repository 에만 존재하게 된다. 기본적으로 Transation과 영속성 컨텍스트의 생명주기는 같으므로 영속성 컨텍스트의 범위 또한 Repository에만 있다.
이 경우 Test 코드를 실행하면 member == findMember 는 false가 나오게 된다.
왜냐하면 memberRepository.save(member)를 할 때, repository에서 트랜잭션이 시작되어 영속성 컨텍스트에 member가 저장되지만 트랜잭션이 커밋이 되면서 member는 준영속 상태가 된다.
그래서 memberRepository.find(saveId)를 실행할 때, 다시 트랜잭션이 일어나고 영속성 컨텍스트가 생성되는데 당연히 해당 엔티티는 영속성 컨텍스트에 없기 때문에 데이터베이스에 직접 조회한 후 영속성 컨텍스트에 저장하고 이를 반환한다.
따라서 member와 findMember은 같은 데이터베이스 로우를 가르키고 있지만 주소값이 다른 엔티티가 된다.
결론적으로 동일성 비교는 실패하고, equals()를 구현했다면 동등성은 만족, 데이터베이스 동등성도 만족하게 된다.
이 내용을 보건데, 같은 영속성 컨텍스트를 보장하지 못한다면 동일성 비교말고 동등성 비교나 데이터베이스 동등성을 활용해야 한다.
데이터베이스 동등성 비교는
member.getId().equals(findMember.getId());
와 같이 할 수 있을 것이다.
다만, 식별자 값을 직접 부여한다면 가능하겠지만, 그렇지 않다면 엔티티가 영속화 되기 전까지는 식별자 값이 null 이기에 이 방법을 사용하지 않을 것이다.
그렇다면 남은 방법은 동등성 비교이다.
엔티티를 비교할 때는 기본적으로 비즈니스 키를 활용한 동등성 비교를 권장한다.
자세히 말하자면 equals()를 오버라이딩 할 때 비즈니스 키가 되는 필드들을 선택을 하면 된다는 말인데, 특히나 기본 키 후보들이 좋은 대상이다.
예를 들어 주민등록번호와 같은 키는 중복이 되지 않고 거의 변경되지 않기에 equals()에 선택하기 좋은 키이다.
3. 프록시 심화 주제
프록시를 사용하는 방식의 기술적 한계로 예상하지 못한 문제들이 발생하기도 한다.
어떤 문제가 발생하고 어떻게 해결해야 하는지 살펴보자.
3.1 영속성 컨텍스트와 프록시
영속성 컨텍스트는 자신이 관리하는 영속 엔티티의 동일성 뿐만 아니라 프록시로 조회한 엔티티의 동일성도 보장한다.
어떻게 보장하는지 코드로 보겠다.
@Test
public void test(){
Member newMember = new Member("member1");
em.persist(member);
em.flush();
em.clear();
Member refMember = em.getReference(Member.class , "member1");
Member findMember = em.find(Member.class , "member1");
Assert.asserTrue(refMember == findMember); //성공
}위의 코드를 보면 먼저 회원 객체를 getReference를 사용해서 프록시로 조회했다. 그런다음 find로 같은 엔티티를 조회하면 프록시를 반환한다.
순서를 바꾸어도 핵심은 같다.
find로 원본 엔티티를 먼저 조회하면 em.getReference()를 호출해도 프록시가 아닌 원본을 반환한다.
이와 같은 과정으로 프록시로 조회한 엔티티의 동일성도 보장해준다.
3.2 프록시 비교
3.2.1 프록시 타입 비교
프록시는 원본 엔티티를 상속 받아서 만들어지므로 프록시로 조회한 엔티티의 타입을 비교할 때는 ==를 사용하면 안 되고 instanceOf를 사용해야 한다.
따라서 3.1의 코드에서 Member.class == refMember.getClass() 는 false가 나오고 refMember instanceOf Member 은 true가 나온다.
3.2.2 프록시 동등성 비교
엔티티의 동등성을 비교하려면 비즈니스 키를 사용해 equals() 메소드를 오버라이딩 하면 된다고 하였다. 그런데 IDE나 외부 라이브러리르 사용해서 구현한 equals() 메소드로 엔티티를 비교할 때, 비교 대상이 원본 엔티티면 문제가 없지만 프록시면 문제가 발생할 수 있다. 😱
@Entity
@Getter
@Setter
public class Member {
@Id
private String id;
private String name;
@Override
public boolean equals(Object obj){
if (this == obj ) return true;
if (obj == null) return false;
if (this.getClass() != obj.getClass()) return false; //(1)
Member member = (Member) obj;
if(name != null ? !name.equals(member.name) :
member.name != null) return false //(2)
return true;
}
@Override
public int HashCode(){
/../
}
}위와 같이 equals 메소드를 오버라이딩 하고
Member member = new Member("member1", "회원1");
Member refMember = em.getReference(Member.class , "member1");위의 member와 refMember를 동등성 비교하면 일치할 것 같지만 일치하지 않는다.
그런데 em.find로 원본 엔티티를 사용하면 동등성 비교가 일치하다고 나온다.
이 문제가 발생한 이유는 다음과 같다.
(1) : 클래스 타입 비교를 == 를 사용해서 하였다. 앞서 설명한 대로 프록시는 원본을 상속받은 자식 타입이기 때문에 instaceof를 사용해야 한다.
(2) : member.name으로 프록시의 멤버변수에 직접 접근하게 코드를 작성하기 때문이다. memger.getName() 과 같이 접근자를 사용해야 한다.
자세한 설명 **
프록시는 실제 데이터를 가지고 있지 않는다.
따라서 프록시 멤버변수에 직접 접근하면 아무값도 조회할 수 없기 때문에 접근자(getter)를 사용해야 한다.
`member.getName()`으로 수정한다면 프록시 객체의 초기화 (=실제 사용될 때 데이터베이스를 조회해 실제 엔티티 객체를 생성하는 것)
가 일어나고, 프록시 객체는 실제 엔티티 객체의 getName()을 호출하여 결과를 반환하게 된다.3.3 상속관계와 프록시
이번에는 상속관계를 프록시로 조회할 때 발생할 수 있는 문제점과 해결방안을 살펴보겠다.
예제에서 사용할 클래스 모델은 아래와 같다.
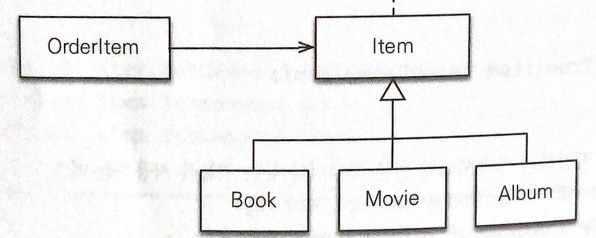
결론적으로 말하자면 프록시를 부모 타입으로 조회하면 문제가 발생한다.
Item proxyItem = em.getReference(Item.class , saveBook.getId());
proxyItem.getClass() == Book.class //false
proxyItem instanceOf Book //false
proxyItem instanceOf Item //true
Book book = (Book) proxyItem; // java.lang.ClassCastException 발생
em.getReference()를 통해 조회할 때 Item 엔티티를 대상으로 조회했기 때문에 proxyItem 은 Item 타입을 기반으로 만들어진다.
따라서 proxyItem 은 Item$Proxy 타입이고 Book과 관계가 없기 때문에 instanceof Book은 false가 된다.
또한 직접 Book 타입으로 다운케스팅을 하려고하면 마찬가지로 proxyItem은 Book이 아닌 Item 타입을 기반으로 한 ItemProxy 타입이기 때문에 ClassCastException이 발생하게 된다.
이러한 상속 관계에 발생하는 프록시 문제 해결 방안은 여러 가지가 있다.
JPQL로 대상을 직접 조회하여 처음부터 자식 타입을 직접 조회할 수도 있지만
Book book = em.createQuery("select b from Book b where b.id = :bookId" ,Book.class)
.setParameter("bookId", item.getId())
.getSingleResult();이렇게 하면 다형성을 활용할 수 없다.
이외에 프록시 벗기기 , 별도의 인터페이스 제공 , 비지터 패턴 사용과 같은 방법이 있는데 하나씩 살펴보겠다.
3.3.1 상속관계와 프록시 문제 해결 - 프록시 벗기기
하이버네이트가 제공하는 기능을 사용하면 프록시에서 원본 엔티티를 가져올 수 있다.
...
Item item = orderItem.getItem();
Item unProxyItem = unProxy(item);
if(unProxyItem instanceof Book) {
System.out.println("proxyItem instanceof Book");
Book book = (Book) unProxyItem;
System.out.println("책 저자 = " + book.getAuthor());
}
Assert.assetTrue(item != unProxyItem);
}
//하이버네이트가 제공하는 프록시에서 원본 엔티티를 찾는 기능을 사용하는 메소드
public static <T> T unProxy(Object entity) {
if (entity instanceof HibernateProxy) {
entity = ((HibernateProxy) entity)
.getHibernateLazyInitializer();
.getImplementation();
}
return (T) entity;
}
///출력 결과
proxyItem instanceOf Book
책 저자 = shj그런데 이 방법을 사용하면 프록시와 원본 엔티티의 동일성 비교가 실패하게 된다.
왜냐하면 앞서 설명했듯이 영속성 컨텍스트는 한 번 프록시로 노출한 엔티티는 계속 프록시로 노출했는데, 이 방법은 프록시에서 원본 엔티티를 직접 꺼내버리기 때문이다.
따라서 원본 엔티티가 꼭 필요한 곳에서 잠깐 사용하고 다른 곳에서 사용되지 않도록 하는 것이 중요하다.
3.3.2 상속관계와 프록시 문제 해결 - 기능을 위한 별도의 인터페이스 제공
public interface TitleView {
String getTitle();
}
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "DTYPE")
public abstract class Item implements TitleView {
@Id @GeneratedValue
@Column(name = "ITEM_ID")
private Long id;
private String name;
private int price;
private int stockQuantity;
//Getter, Setter
...
}
@Entity
@DiscriminatorValue("B")
public class Book extends Item {
private String author;
private String isbn;
@Override
public String getTitle() {
return "[제목:" + getName() + " 저자:" + author + "]";
}
}
@Entity
@DiscriminatorValue("M")
public class Movie extends Item {
private String director;
private String actor;
@Override
public String getTitle() {
return "[제목:" + getName() + " 감독:" + director + " 배우 :" + actor + "]";
}
}이 방법은 TitleView라는 공통 인터페이스를 만들고 자식 클래스들은 인터페이스의 getTitle() 메소드를 각각 구현하게 한다.
그런다음 OrderItem에서 Item의 getTitle()을 호출하게 하고 이를 사용하면 된다.
@Entity
public class OrderItem {
@Id @GeneratedValue
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "ITEM_ID")
private Item item;
/.../
public void printItem() {
System.out.println("TITLE=" + item.getTitle());
}
}
....
OrderItem orderItem = em.find(OrderItem.class, saveOrderItem.getId());
orderItem.printItem();이렇게 한다면 다형성을 활용할 수 있고 클라이언트 입장에서 대상 객체가 프록시인지 아닌지를 고민하지 않아도 된다.
이 방법을 사용할 때는 프록시의 특징 때문에 프록시의 대상이 되는 타입에 인터페이스를 적용해야 한다. 여기서는 Item이 프록시의 대상이므로 Item이 이 인터페이스를 받게 하였다.
3.3.3 상속관계와 프록시 문제 해결 - 비지터 패턴 사용
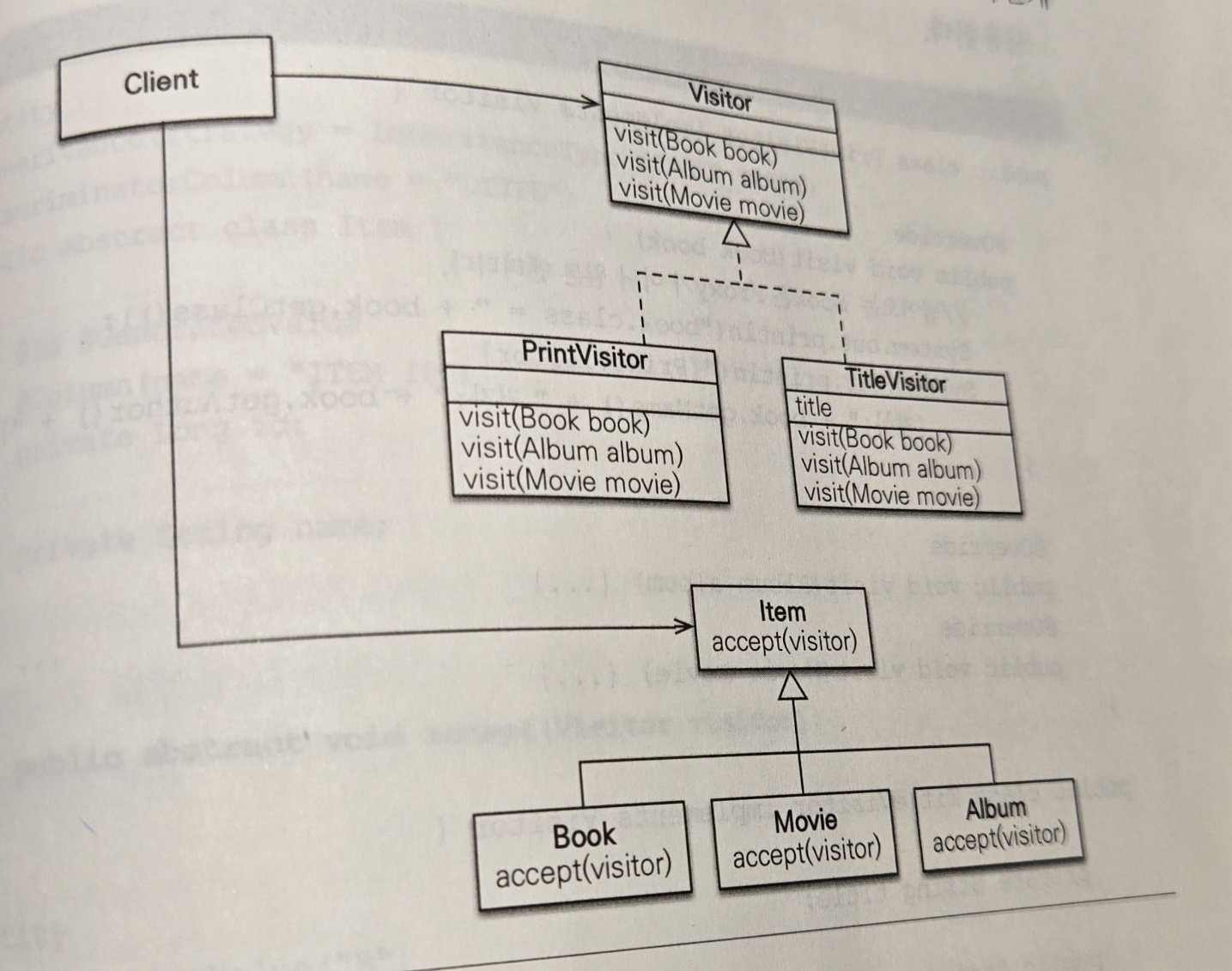
비지터 패턴은 Visitor 와 Visiter를 받아들이는 대상 클래스로 구성된다.
여기서는 Item이 accept(visitor) 메소드를 사용해서 Visitor를 받아들이고 Item은 단순히 Visitor를 받아들이기만 하고 실제 로직은 Visitor가 처리한다.
Visitor 정의와 구현
예제에서는 Visitor의 구현 클래스로 대상 클래스의 내용을 출력해주는 PrintVisitor 와 대상 클래스의 제목을 보관하는 TitleVisitor를 작성하였다.
//Visitor interface
public interface Visitor {
void visit(Book book);
void visit(Album album);
void visit(Movie movie);
}
//Visitor 구현
public class PrintVisitor implements Visitor {
@Override
public void visit(Book book) {
//넘어오는 book은 Proxy가 아닌 원본 엔티티
System.out.println("book.class = " + book.getClass());
System.out.println("[PrintVisitor] [제목: " + book.getName() +
"저자 :" + book.getAutor() + "]");
}
@Override
public void visit(Album album) {...}
@Override
public void visit(Movie album) {...}
}
public class TitleVisitor implements Visitor {
private String title;
public String getTitle() {
return title;
}
@Override
public void visit(Book book) {
title = "[제목:" + book.getName() + "저자:" + book.getAuthor() + "]";
}
@Override
public void visit(Album album) {...}
@Override
public void visit(Movie movie) {...}
}
//대상 클래스 작성
@Entity
@Inheritance(strategy = InheritanceType.Single_TABLE)
@DiscriminatorColumn(name = "DTYPE")
public abstract class Item {
@Id @GeneratedValue
@Column(name = "ITEM_ID")
private Long id;
private String name;
...
public abstract void accept(Visitor visitor);
}
@Entity
@DiscriminatorValue("B")
public class Book extends Item {
private String author;
private String isbn;
//Getter, Setter
@Override
public void accept(Visitor visitor) {
visitor.visit(this);
}
}
/... Movie , Album도../이렇게 하면 구현은 끝났다.
자식 클래스들 (Movie , Book 등) 은 부모에 정의한 accept (visitor) 메소드를 구현할 때 단순히 파라미터로 넘어온 Visitor의 visit(this) 메소드를 호출하여,실제 로직 처리를 visitor에게 위임하였다.
그런 다음 사용은 아래 처럼 하면 된다.
OrderItem orderItem = em.find(OrderItem.class, orderItemId);
Item item = orderItem.getItem();
item.accept(new PrintVisitor());Visit.visit() 에서 파라미터로 넘어오는 엔티티는 프록시가 아니라 실제 원본 엔티티이기 때문에 비지터 패턴을 사용하면 프록시에 대한 걱정 없이 안전하게 엔티티에 접근할 수 있고 instanceof나 타입캐스팅 없이 코드를 구현할 수 있다.
비지터 패턴은 새로운 기능이 필요할 때 visitor만 추가하면 된다.
따라서 기존의 코드의 구조를 변경하지 않고 기능을 추가할 수 있지만
너무 복잡하고 더블 디스패치(메소드 호출 시 두 번의 다형적 결정이 일어나는 방식)를 사용하기 때문에 이해하기 어렵다.
그리고 객체 구조가 변경되면 모든 Visitor를 수정해야 한다.
4.성능 최적화
4.1 N+1 문제
JPA를 활용할 때 성능상 가장 주의해야 하는 문제이다.
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
@OneToMany(mappedBy = "member", fetch = FetchType.EAGER)
private List<Order> orders = new ArrayList<Order>();
/.../
}@Entity
@Table(name = "ORDERS")
public class Order {
@Id @GeneratedValue
private Long id;
@ManyToOne
private Member member;
...
}위처럼 Member와 Order이 1:N 관계를 가지고 있고 즉시 조회로 설정이 되었다고 가정하자.
이때 em.find()로 조회하면 즉시 로딩이 되어 join을 통해 한 번에 주문 정보를 조회한다. (select m from member m outer join orders o on m.id = o.member_id 와 같은 쿼리가 실행된다.)
여기까지는 성능상 문제가 없지만 JPQL을 사용할 때 문제가 발생한다.
List<Member> members =
em.createQuery("select m from Member m", Member.class)
.getResultList();
//실행 SQL
SELECT * FROM MEMBER위의 JPQL을 실행하면 JPQL은 즉시 로딩 ,지연 로딩은 신경 쓰지 않고 위와 같은 SQL을 실행하여 결과를 애플리케이션에 로딩한다.
그런데 회원 엔티티와 연관된 주문 컬렉션이 즉시 로딩으로 설정되어 있으므로 JPA는 주문 컬렉션을 즉시 로딩하려고
SELECT * FROM ORDERS WHERE MEMBER_ID = ?
와 같은 SQL을 추가로 실행한다. 조회된 회원이 10명이면 추가로 10번의 SQL을 실행할 것이다. 이 문제를 N+1 문제라고 한다.
N+1 문제는 지연로딩일 때도 발생할 수 있다.
JPQL에서는 발생하지 않겠지만 위의 JPQL로 조회한 members를 가지고
for(Member member : members) {
//지연 로딩 초기화
System.out.println("member = " + member.getOrders().size());
}위와 같이 모든 member에 대해 연관된 주문 컬렉션을 사용할 때 문제가 발생한다.
주문컬렉션을 초기화하는 수만큼 ORDERS를 조회하는 SQL이 실행되게 된다. 회원이 5명이면 회원에 따른 주문도 5번 조회될 것이다.
이렇게 N+1 문제가 발생하는 상황을 살펴보았다.
이제 해결방법을 살펴보겠다.
1. 페치 조인 사용
가장 일반적인 방법이다.
페치 조인은 SQL 조인을 사용해서 연관된 엔티티를 함께 조회하기 때문에 (다시 말하자면 페치 조인을 이용해 JPQL를 사용하면 연관된 엔티티도 함께 조회되게 된다) N+1 문제가 발생하지 않는다.
2. 하이버네이트의 @BatchSize
하이버네이트가 제공하는 org.hibernate.annotations.BatchSize 어노테이션을 사용하면 연관된 엔티티를 조회할 때 지정한 size만큼 SQL 의 IN 절을 사용해서 조회한다. 만약 조회한 회원이 10명인데 size = 5로 지정하면 2번의 SQL 만 추가로 실행한다.
@Entity
public class Member {
...
@org.hibernate.annotaions.BatchSize(size = 5)
@OneToMany(mappedBy = "member", fetch = FetchType.EAGER)
private List<Order> orders = new ArrayList<Order>();
...
}3. 하이버네이트의 @Fetch(FetchMode.SUBSELECT)
하이버네이트가 제공하는 org.hibernate.annotations.Fetch 어노테이션에 FetchMode를 SUBSELECT로 사용하면 연관된 데이터를 조회할 때 서브쿼리를 사용해서 N+1 문제를 해결한다.
@Entity
public class Member {
...
@org.hibernate.annotations.Fetch(FetchMode.SUBSELECT)
@OneToMany(mappedBy = "member", fetch = FetchType.EAGER)
private List<Order> orders = new ArrayList<Order>();
...
}JPQL로 회원 식별자 값이 10을 초과하는 회원을 모두 조회할 때,
즉시 로딩으로 설정하면 조회 시점에, 지연 로딩으로 설정하면 지연 로딩된 엔티티를 사용하는 시점에 다음 SQL이 실행된다.
SELECT O FROM ORDERS O
WHERE O.MEMBER_ID IN (
SELECT
M.ID
FROM
MEMBER M
WHERE M.ID > 10
)정리하자면 로딩 전략은 즉시 로딩은 사용하지 말고 지연 로딩만 사용하는 것을 추천한다. 즉시 로딩은 N+1 문제 뿐만 아니라 필요하지 않은 엔티티를 로딩하는 상황이 자주 발생하고, 성능 최적화가 어렵다. 따라서 모두 지연 로딩으로 설정하고 성능 최적화가 꼭 필요한 곳에는 JPQL 페치 조인을 사용하는 것이 좋다.
참고로 JPA의 글로벌 페치 전략 기본값은
OneToOne , ManyToOne : 즉시로딩
OneToMany , ManyToMany : 지연 로딩
이다. 따라서 기본값이 즉시 로딩인 경우 fetch = FetchType.LAZY로 지연 로딩 전략을 사용하도록 변경하는 것을 추천한다.
4.2 읽기 전용 쿼리 성능 최적화
엔티티가 영속성 컨텍스트에 관리되면 얻는 이점은 많지만 스냅샷 인스턴스를 보관해야 하여 더 많은 메모리를 사용하는 단점이 있다.
만약 회원 100명을 조회하고 조회한 엔티티는 다시 조회할 일도 없고 수정할 일도 없이 딱 한 번만 읽어 화면에 출력하면 되는 경우 굳이 영속성 컨텍스트에 저장할 이유가 있을까?
이 경우 읽기 전용으로 엔티티를 조회하면 메모리 사용량을 최적화 할 수 있다.
최적화 방법
-
스칼라 타입으로 조회
: 엔티티가 아닌 스칼라 타입 (String , int 등) 으로 모든 필드를 조회하면 스칼라 타입은 영속성 컨텍스트가 결과를 관리하지 않기 때문에 최적화 할 수 있다. -
읽기 전용 쿼리 힌트
: 하이버네티이트에서는 org.hibernate.readOnly를 사용하면 엔티티를 읽기 전용으로 조회할 수 있다. 읽기 전용이기 때문에 영속성 컨텍스트는 스냅샷을 보관하지 않게 된다. -
읽기 전용 트랜잭션 사용
:스프링 프레임워크를 사용할 시@Transactional(readOnly =true)를 통해 손쉽게 최적화를 할 수 있다. 이 경우 하이버네이트 세션의 플러시 모드를 MANUAL로 설정하는데 이렇게 하면 강제로 플러시를 호출하지 않는 한 플러시가 일어나지 않는다. 따라서 트랜잭션을 커밋해도 영속성 컨텍스트를 플러시 하지 않기 때문에 플러시할 때 일어나는 스냅샷 비교와 같은 무거운 로직들이 수행되지 않아 성능이 향상된다. -
트랜잭션 밖에서 읽기
: 스프링의 경우@Transational (propagation = Progation.NOT_SUPPORTED)를 통해 트랜잭션 없이 엔티티를 조회하게 된다. 이렇게 하면 트랜잭션 자체가 없기 때문에 트랜잭션을 커밋할 일도 없고 자연적으로 플러시도 호출되지 않는다.
정리하자면 메모리를 최적화하고 싶으면 스칼라 타입으로 조회하거나 하이버네이트의 읽기 전용 쿼리 힌트를 사용하면 되고, 플러시 호출을 막아 속도를 최적화하려면 읽기 전용 트랜잭션이나 트랜잭션 밖에서 읽기를 사용하면 된다.
따라서 읽기 전용 트랜잭션과 읽기 전용 쿼리 힌트처럼 이 둘을 동시에 사용하여 속도와 메모리 모두를 최적화하는 것이 효과적이다.
4.3 배치 처리
수백만 건의 데이터를 배치 처리해야 하는 상황에서 일반적인 방식으로 엔티티를 계속 조회하면 영속성 컨텍스트에 아주 많은 엔티티가 쌓이면서 메모리 부족 오류가 발생한다.
오류 안 발생하게 하려면 어떻게 해야 할 지 알아보자.
4.3.1 JPA 등록 배치
영속성 컨텍스트에 엔티티가 계속 쌓이지 않도록 일정 단위마다 영속성 컨텍스트의 엔티티를 데이터베이스에 플러시하고 영속성 컨텍스트를 초기화 해 주면 된다.
EntityManager em = entityManagerFactory.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
for(int i = 0; i < 100000; i++) {
Product product = new Product("item" + i, 10000);
em.persist(product);
//100건마다 플러시와 영속성 컨텍스트 초기화
if (i % 100 == 0) {
em.flush();
em.clear();
}
}
tx.commit();
em.close();4.3.2 JPA 수정 배치
아주 많은 데이터를 조회해서 수정해야 하는데 한 번에 메모리에 올려둘 수는 없다.
그래서 2가지 방법 (페이징 처리 , 커서 ) 을 주로 사용한다.
- JPA 페이징 배치 처리
EntityManger em = entityManagerFactory.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
int pageSize = 100;
for(int i=0; i<10; i++) {
List<Product> resultList = em.createQuery("select p from Product p",
Product.class)
.setFirstResult(i * pageSize)
.setMaxResult(pageSize)
.getResultList();
for(Product product : resultList) {
product.setPrice(product.getPrice() + 100);
}
em.flush();
em.clear();
}
tx.commit();
em.close();페이지 단위마다 영속성 컨텍스트를 플러시하고 초기화하면 된다.
- 하이버네이트 scroll 사용
JPA는 커서를 지원하지 않는다. 그래서 커서를 사용하려면 하이버네이트의 세선을 사용해야 하는데, 하이버네이트는 scroll이라는 이름으로 JDBC 커서를 지원한다.
EntityTransaction tx = em.getTransaction();
Session session = em.unwrap(Session.class);
tx.begin();
ScrollableResults scroll = session.createQuery("select p from Product p")
.setCacheMode(CacheMode.IGNORE) //2차 캐시 기능을 끈다.
.scroll(ScrollMode.FORWARD_ONLY);
int count = 0;
while(scroll.next()) {
Product p = (Product) scroll.get(0);
p.setPrice(p.getPrice() + 100);
count++;
if(count % 100 == 0) {
session.flush(); //플러시
session.clear(); //영속성 컨텍스트 초기화
}
}
tx.commit();
session.close();scroll은 em.unwrap()을 이용해 하이버네이트 세션을 구하고, 쿼리를 조회하면서 scroll()로 ScrollabeResults 객체를 반환받아 next() 메소드를 통해 엔티티를 하나씩 조회할 수 있다.
- 하이버네이트 무상태 세션 사용
무상태 세션은 영속성 컨텍스트를 사용하지 않고 2차 캐시도 사용하지 않는다.
그래서 엔티티를 수정하려면 무상태 세션이 제공하는 update() 메소드를 직접 호출해야 한다.
SessionFactory sessionFactory =
entityManagerFactory.unwrap(SessionFactory.class);
StatelessSession session = sessionFactory.openStatelessSession();
Transaction tx = session.beginTransaction();
ScrollableResults scroll = session.createQuery("select p from Product p").scroll();
while(scroll.next()) {
Product p = (Product)scroll.get(0);
p.setPrice(p.getPrice() + 100);
session.update(p); //직접 update를 호출
}
tx.commit();
session.close();4.4 SQL 쿼리 힌트 사용
JPA는 데이터베이스 벤더에 제공하는 SQL 힌트를 제공하지 않는다.
SQL 힌트를 사용하려면 하이버네이트를 직접 사용해야 한다.
addQueryHint() 를 통해 SQL HINT를 추가할 수 있는데 하이버네이트 4.3.10 버전에서는 오라클 방언에만 힌트가 적용되어 있다.
다른 데이터베이스에서 SQL 힌트를 사용하려면 각 방언에서 org.hibernate.dialect.Dialect에 있는
public String getQueryHintString (String query, List<String> hints) 메소드를 오버라이딩해서 구현해야 한다.
4.5 트랜잭션을 지원하는 쓰기 지연과 성능 최적화
JPA가 아닌 JDBC로 직접 SQL을 다루는 경우 insert(member)를 5번 실행하면 5번의 INSERT SQL과 한 번의 커밋으로 총 6번 DB와 통신하게 된다.
네트워크 호출 한 번은 단순한 메소드 수만 번 호출하는 것보다 더 큰 비용이 들기 때문에 속도면에서 아주 좋지 않다.
JDBC가 제공하는 SQL 배치 기능을 사용하면 SQL을 모아서 데이터베이스 한 번에 보낼 수 있지만 적용하려면 코드의 많은 부분을 수정해야 한다.
JPA는 플러시 기능이 있으니 SQL 배치 기능을 효과적으로 사용할 수 있다.
SQL 배치 최적화 전략은 구현체마다 조금씩 다른데 하이버네이트에서는
<property name = "hibernate.jdbc.batch_size" value = "50"/>
과 같이 설정하면 SQL 배치 기능을 적용할 수 있다.
위와 같이 설정하면 최대 50건씩 모아서 SQL 배치를 실행하게 된다.
하지만 SQL 배치는 같은 SQL일 때만 유효하다. 중간에 다른 처리가 들어가면 SQL 배치를 다시 시작하게 된다.
트랜잭션을 지원하는 쓰기 지연과 변경 감지로 성능과 개발의 편의성이 향상된다.
하지만 진짜 장점은 데이터베이스 테이블 로우에 락이 걸리는 시간을 최소화한다는 것이다.
트랜잭션을 커밋해서 영속성 컨텍스트를 플러시하기 전까지는 데이터베이스에 등록, 수정, 삭제를 하지 않기 때문에 커밋 직전까지 데이터베이스 로우에 락을 걸지 않는다.
update (memberA); //UPDATE SQL A
비즈니스로직A() ; //UPDATE SQL..
비즈니스로직B() ; //INSERT SQL...
commit();JPA를 사용하지 않는다면 update(memberA)를 호출할 때 데이터베이스 테이블 로우에 락이 걸린다. 이 락은 비즈니스로직 A 와 B를 모두 수행하고 commit()이 호출되기 전까지 유지된다.
그런데 JPA는 커밋을 해야 플러시를 호출하고 데이터베이스에 수정 쿼리를 보내기 때문에 쿼리를 보내고 바로 트랜잭션을 커밋하므로 데이터베이스 락이 걸리는 시간을 최소화한다.
데이터베이스 락은 애플리케이션 서버 증설만으로는 해결할 수 없는 문제이다.
JPA 의 쓰기 지연 기능은 락이 걸리는 시간을 최소화해서 동시에 더 많은 트랜잭션을 처리할 수 있는 장점이 있다.
이렇게 오늘도 알차게 알아보았다.
다음 장에는 트랜잭션과 락, 2차 캐시에 대해 살펴보겠다.
참조 : 자바 ORM 표준 JPA 프로그래밍 - 김영한
