컬렉션 프레임워크(Collection Framework)
많은 데이터를 쉽고 효과적으로 관리 할 수 있는 표준화된 방법을 제공하는 클래스의 집합
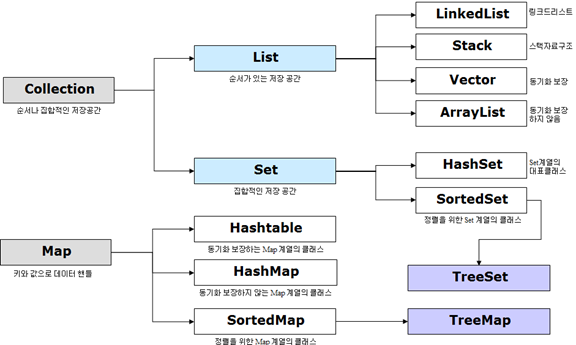
컬렉션 프레임워크의 주요 인터페이스
컬렉션의 사용 이유는?
-
일괄된 API : Collection의 일관된 API를 사용하여 Collection 밑에 있는 모든 클래스(ArrayList, Vector, LinkedList 등) Collection에서 상속받아 통일된 메서드를 사용하게 됩니다.
-
프로그래밍 노력 감소 : 객체 지향 프로그래밍의 추상화의 기본 개념이 성공적으로 구현되어있습니다.
-
프로그램 속도 및 품질 향상 : 유용한 데이터 구조 및 알고리즘은 성능을 향상시킬 수 있습니다 Collection을 사용하여 최상의 구현을 생각할 필요없이 간단하게 Collection API를 사용하여 구현을 하면 됩니다.
• 널리 알려진 여러가지 자료구조를 자바에서 미리 구현하여 제공하는 패키지
• 요소를 수집해서 저장하는 것을 의미하며 객체를 수집해서 저장하는 역할을 함
• 프레임워크(Framework): 사용 방법을 미리 정해 놓은 라이브러리
• 크게 Collection계열과 Map계열로 나뉨
1. List implements Collection
구현 클래스
- Vector
- ArrayList
ArrayList
컬렉션 클래스 중 가장 많이 사용되는 클래스.
배열을 이용해서 값을 저장한다.
인덱스를 이용해서 배열 오소에 빠르게 접근 가능하지만
크기를 늘리기 위해서는 새로운 배열을 생성하고 기존의 값들을 옮겨야 하므로 느리다.
정적배열 : 크기가 고정되었다
동적배열 : 크기가 고정되어 있지 않다.
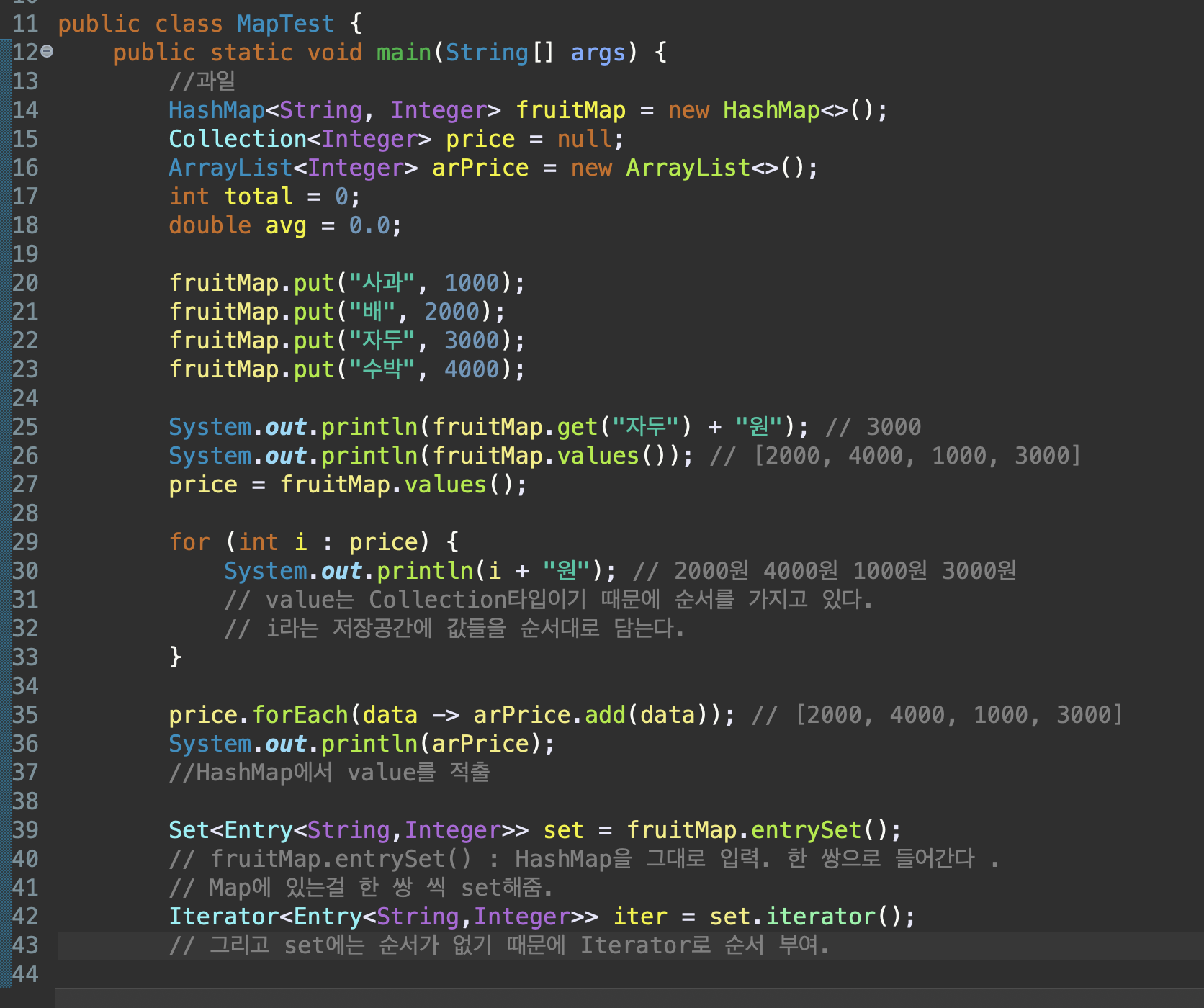
배열 : 속도가 빠르지만 고정된 메모리 양으로 인해 나중에 늘릴 수 없다.
ArrayList : 메모리 양은 맘대로 늘리고 줄일 수 있으나, 배열보다 느리다.
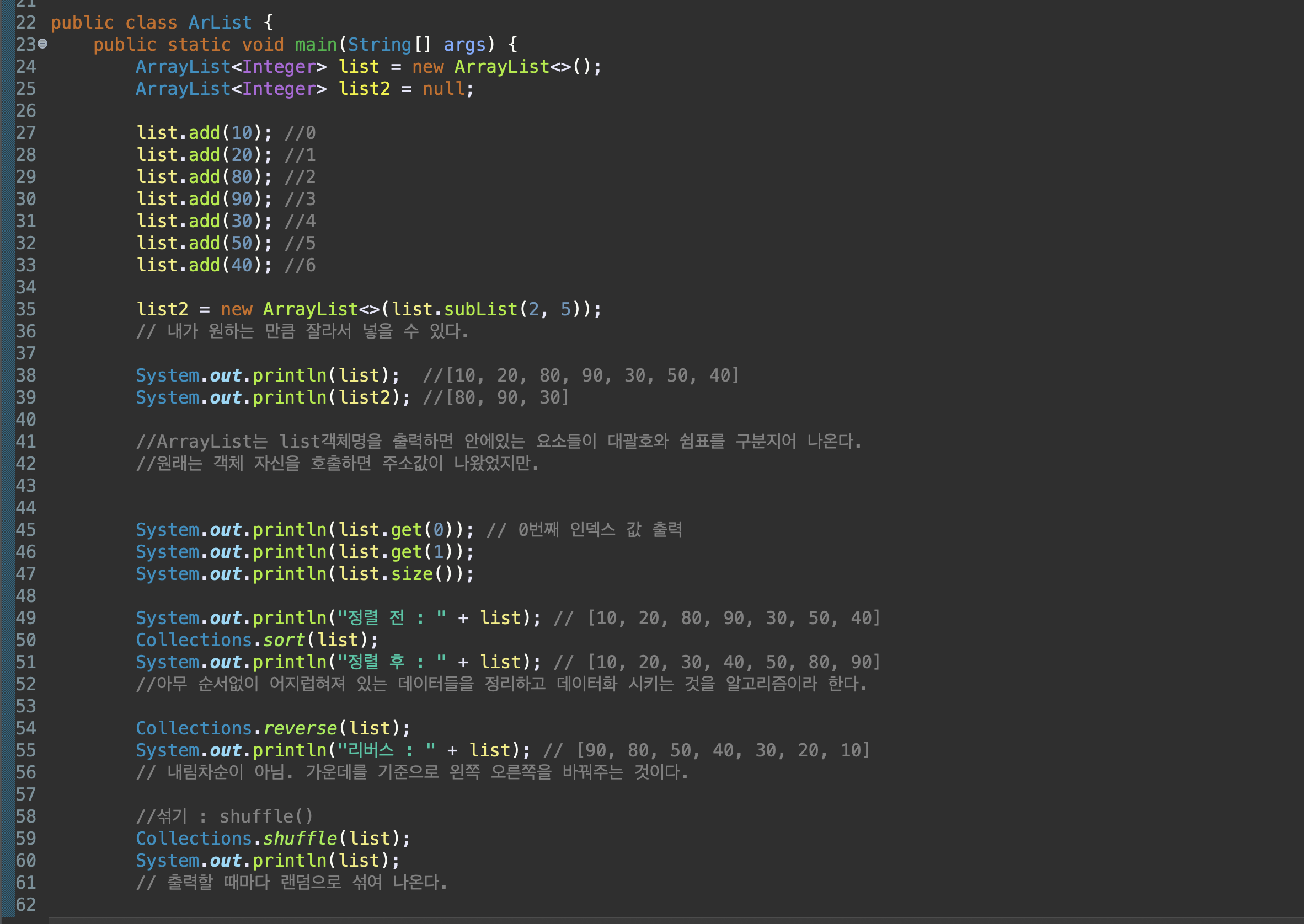
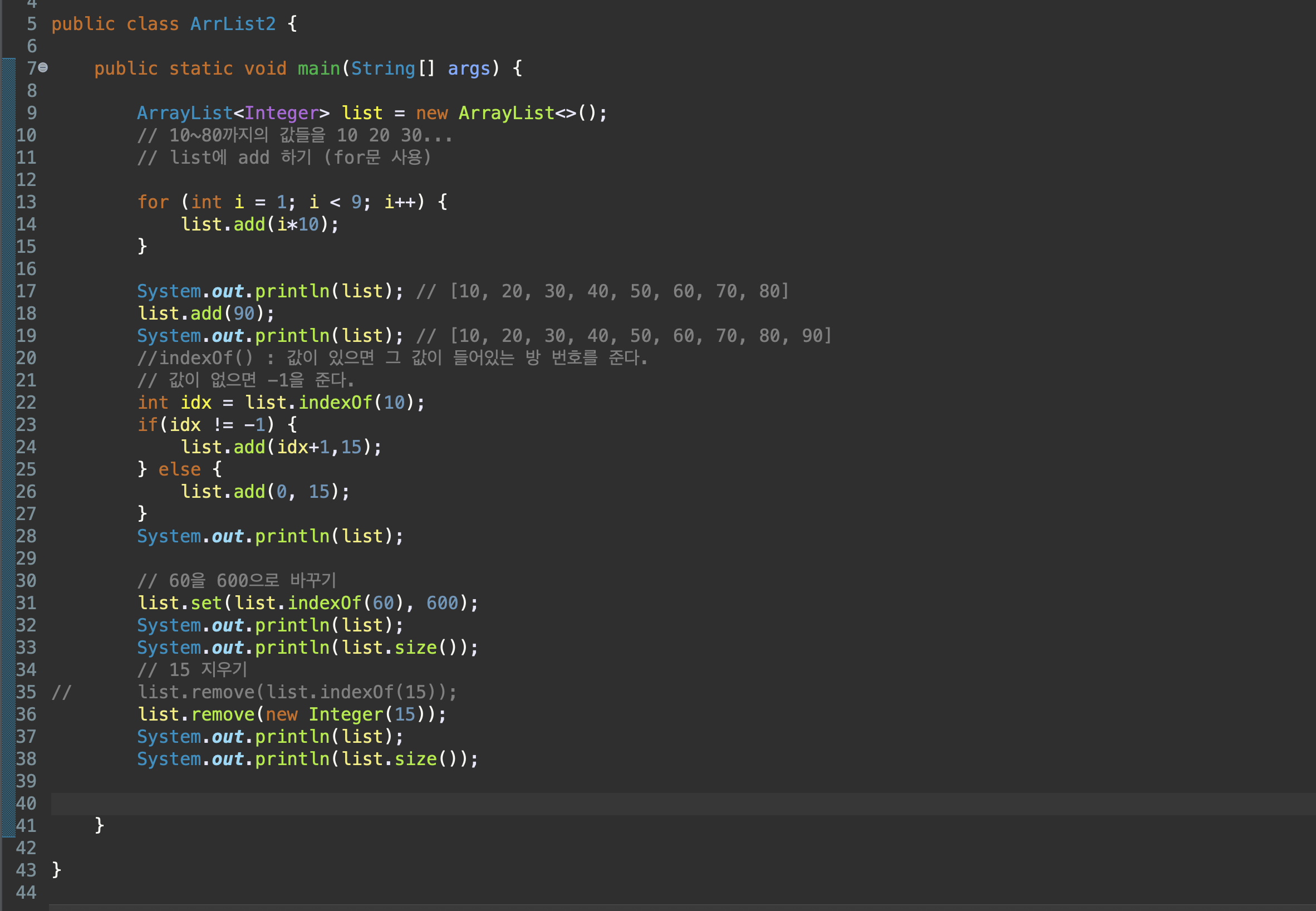
list.add();
list.subList(0, 0);
list.get(0);
list.size();
Collections.sort(list);
Collections.reverse(list);
Collections.shuffle(list);
list.indexOf(0);
list.remove(0);
설계
로그인
회원가입(비밀번호 암호화)
검색
삽입
수정
삭제
2. Set implements Collection
구현 클래스
- HashSet
Set
Set은 집합이다.
집합은 중복 집합이 아니라면 중복되는 원소를 포함할 수 없다.
A A 두개를 Set에 넣으면 두개가 아닌 하나가 된다는 것.
값(객체, 데이터)을 중복해서 저장할 수 없다.
저장된 값들은 인덱스가 없기 때문에 저장 순서가 고정되어 있지 않다.
결론 : 중복이 안되고 순서가 없다
size() : 저장된 값의 수
add() : 값 추가
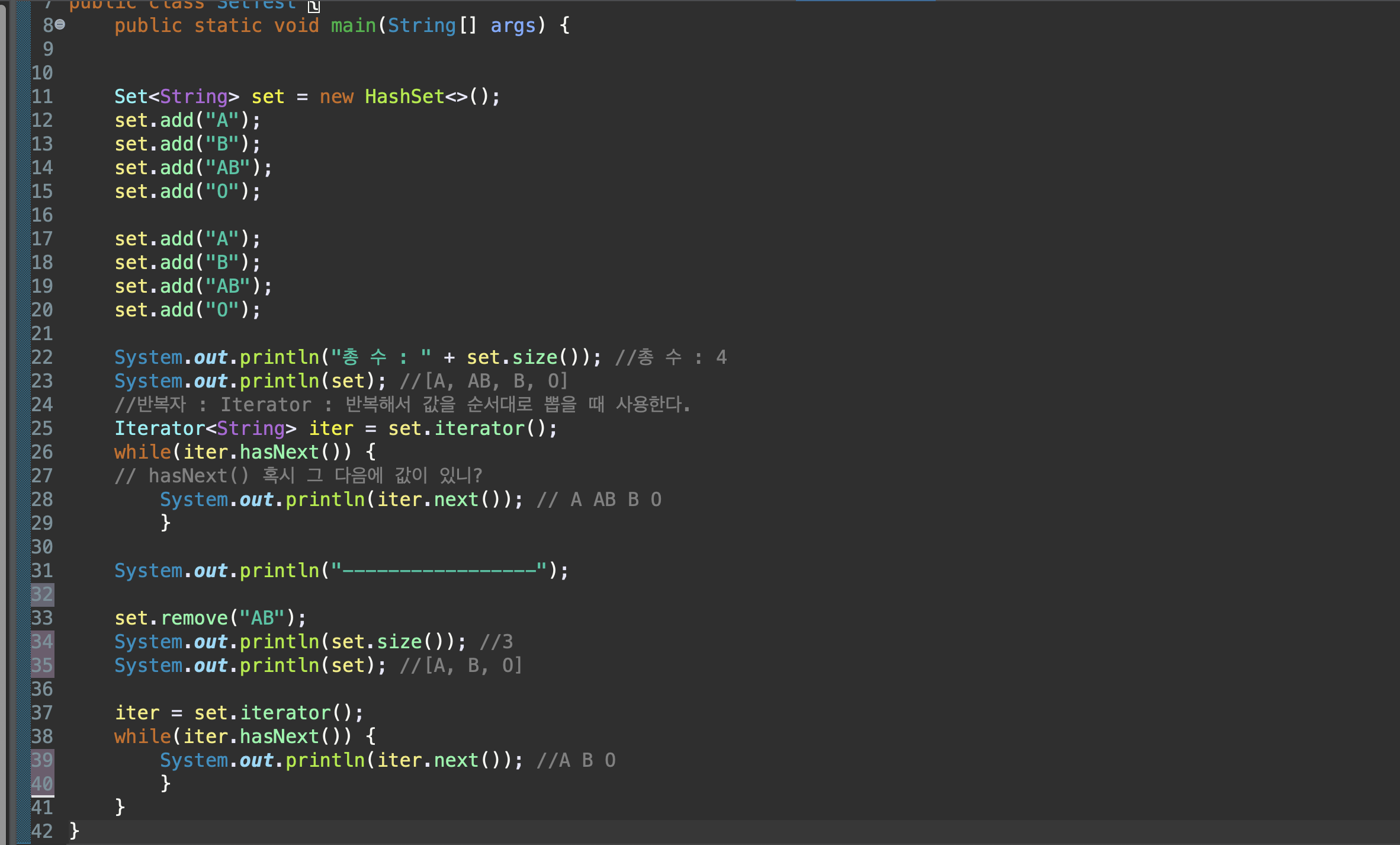
iterator() : 검색
remove(Object o) : 값 삭제
HashSet : Set 컬렉션을 구현하는 대표적인 클래스
Set 객체명 = new HashSet()
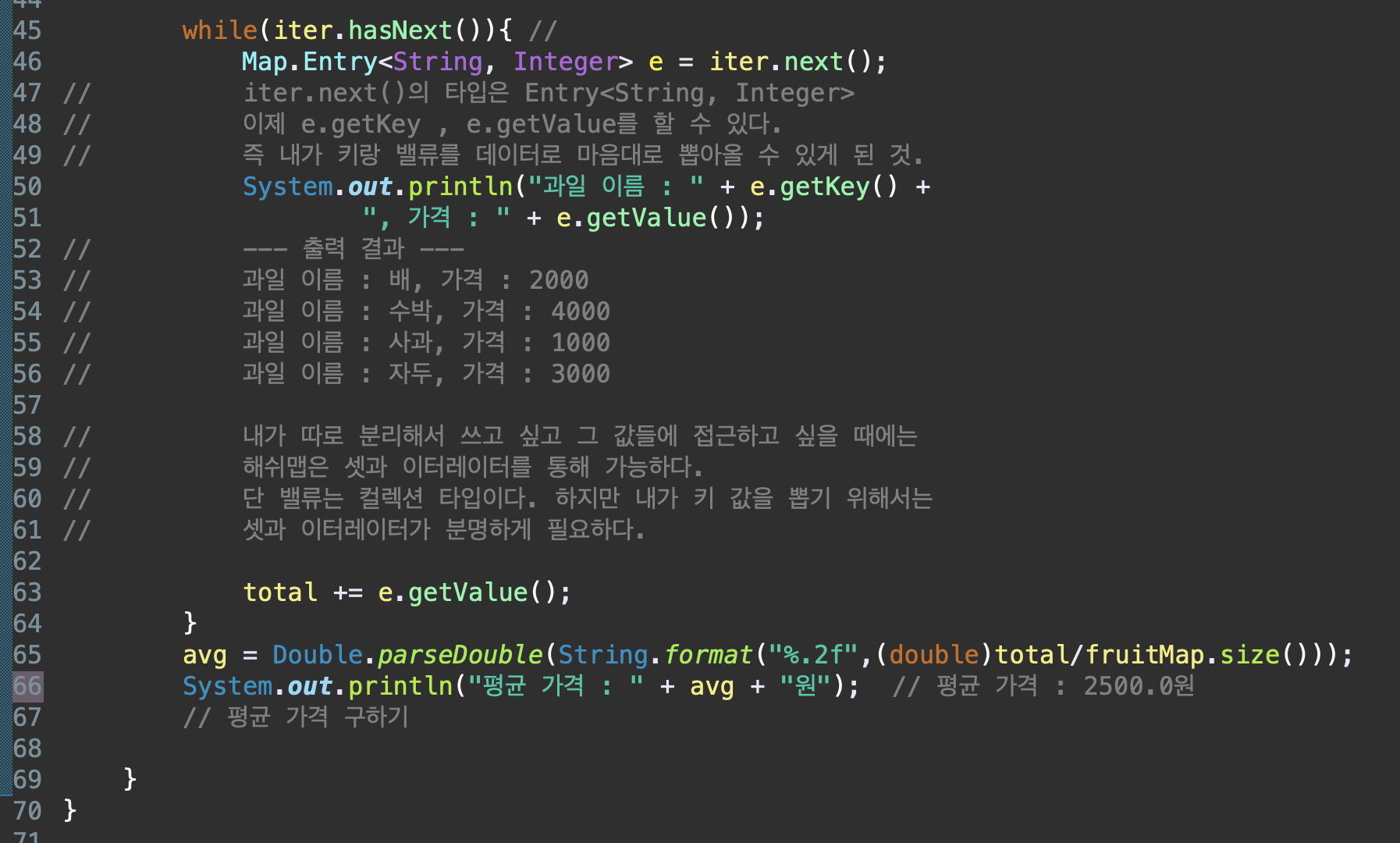
순서를 부여해서 값을 하나씩 차례로 뽑고 싶다면 Iterator라는 반복자를 사용해서 Set에 Iterator 메소드를 호출해주고. hasNext()메소드를 통해 값이 다 끝날 때까지 반복해준 다음, 그 내부적으로는 반복문 안에서 next라는 메소드를 이용해 값을 순서대로 사용해주면 된다.
Set은 검색에 목적이 있다.
HashSet 과 arrayList 중 누가 더 빠를까?
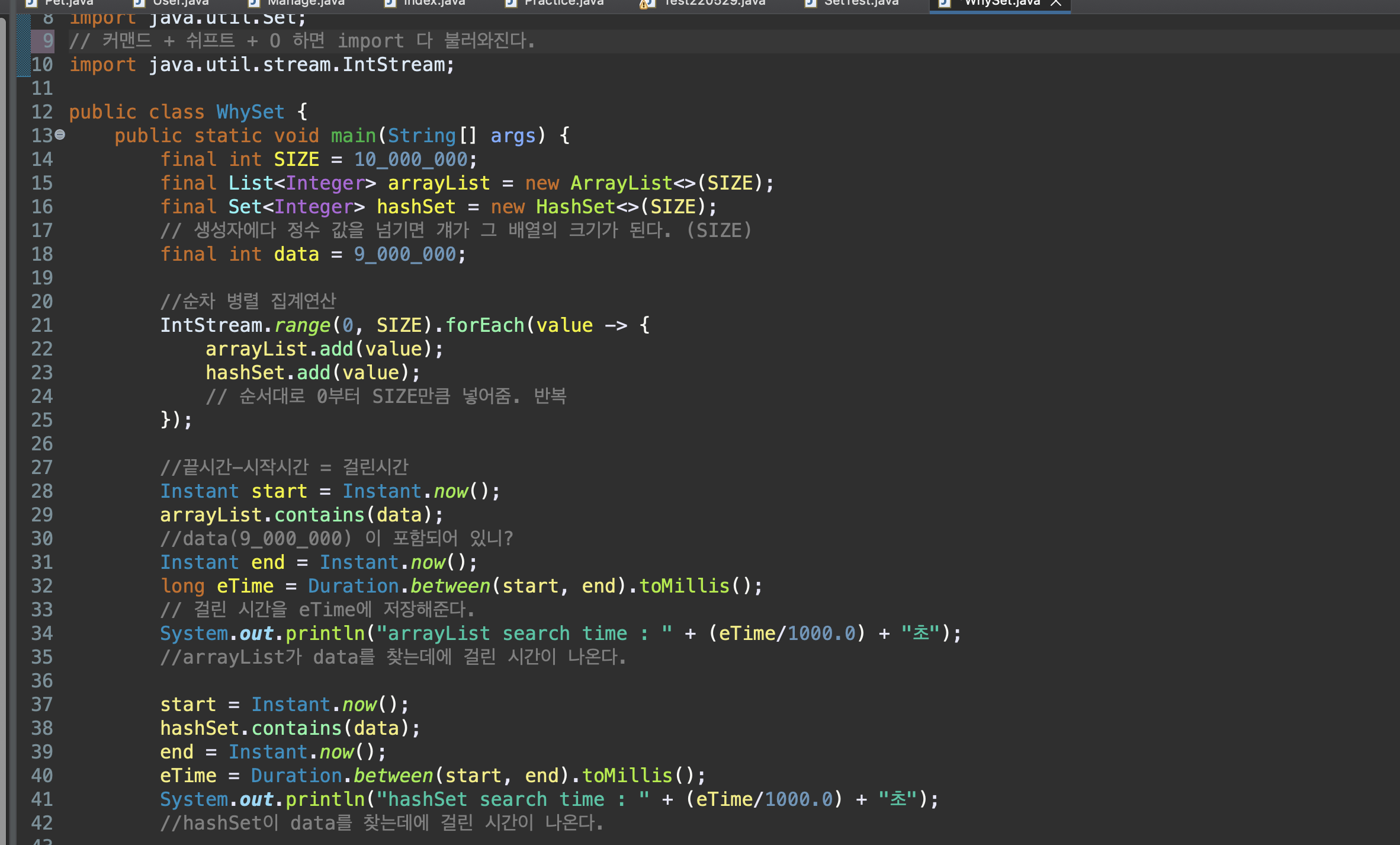
// --- 출력 결과 ---
// arrayList search time : 0.017초
// 순서를 부여하기 때문에 더 오래걸린다.
// hashSet search time : 0.0초
// 훨씬 빠르다. 시간 복잡도
: 속도의 효율성
공간 복잡도
: 메모리 사용의 효율성
hashSet이 시간 복잡도에서 그래프가 훨씬 더 효율적이다
검색하기 위한 목적으로 만들 때에는 arrayList보다 hashSet이 훨씬 더 빠르다는 걸 알 수 있다.
Set은 검색의 목적이 있기 때문에 순서 정보를 관리할 필요가 없어서 데이터 크기에 상관없이 검색에 걸리는 시간이 매우 짧다.
반면 List는 index를 관리해야 하기 때문에 상대적으로 시간이 오래 걸린다.
그러므로 기능적 차이가 없다면 HashSet을 써야한다.
List와 Set인터페이스의 공통요소를 Collection 인터페이스에서 정의하고, 두 인터페이스는 그것을 상속받는다.Map은 별개이다.
3. Map
구현 클래스
HashMap
TreeMap
HashMap
Key와 Value 한쌍(pair, entry)으로 저장된다.
그러므로 검색에 용이하다.
[Key, value] 한 쌍
Map 자료구조는 순서를 따지지 않기 때문에
Set으로 묶은 후 Iterator를 통해 순서를 부여받아서 나와야 한다.
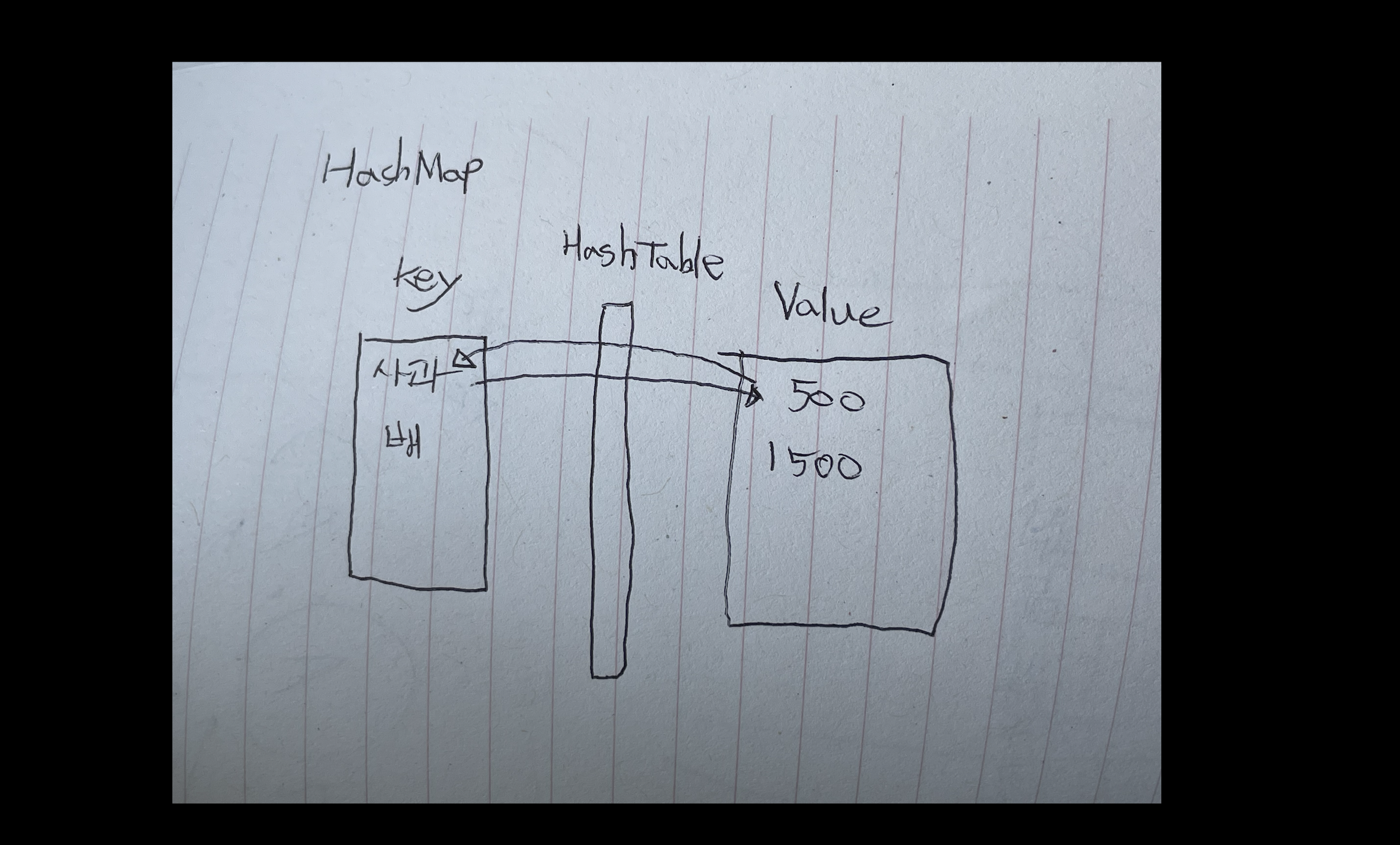
HashTable을 통해 Key와 Value가 통신할 수 있는 것. 한 쌍이 되어있다.
Key는 중복이 불가능하다.(Set 타입)
Value는 중복이 가능하다.(Collection 타입)
Value는 ArrayList나 List로도 받을 수 있다.
두 개의 배열(Key와Value)이 한 쌍이 되어 있기에.
면접 질문-
HashMap에서 Key 값을 주면 어떻게 Value 값을 활용할 수 있나요?
Key와 Value사이에 HashTable이란게 존재하고 그 HashTable을 통해 Key와 Value가 통신합니다!
키 <-> |해시테이블| <-> 값 HashMap<K,V> 객체명 = new HashMap<K,V>();혹은
HashMap<K,V> 객체명 = new HashMap<>(용량); clear() : 모든 값(데이터, 객체) 제거
containsKey(Object Key) : 키가 있는지 검사
containsValue(Object value) : 값이 있는지 검사
get(Object key) : 키 값을 주고 그 짝꿍인 값을 가져온다.
isEmpty() : 비어있는지 확인
keySet() : HashMap에 저장된 모든 키가 저장된 형태 (Set타입) -> HashMap 객체. keySet() = 셋 타입의 키 배열
values() : HashMap에 저장된 모든 값이 저장된 형태 (Collection타입)