
최종모의고사 1회
문제1
빅데이터 플랫폼은 원천 데이터에서 정형, 반정형, 비정형 데이터를 수집하고 저장한다. 다음 중 수집 기술로 가장 부적절한 기법은 무엇인가?
① NoSQL
② ETL
③ EAI
④ Crawler
정답 ①
해설
NoSQL은 정형 데이터, 반정형 데이터, 비정형 데이터 저장 기술이다.
문제2
다음 중 분석 가치 에스컬레이터에 대한 설명으로 가장 올바르지 않은 것은?
① 묘사 분석은 과거에 어떤 일이 일어났고, 현재는 무슨 일이 일어나고 있는지 확인하는 분석이다.
② 진단 분석은 데이터를 기반으로 왜 발생했는지 이유를 확인하는 분석이다.
③ 예측 분석은 무엇을 해야 할 것인지를 확인하는 분석이다,
④ 분석 가치 에스컬레이터에서 높은 난도를 수반하는 데이터 분석은 더 많은 가치를 창출한다.
정답 ③
해설
분석 가치 에스컬레이터의 구성 요소는 묘사 분석, 진단 분석, 예측 분석, 처방 분석이 있다.
- 묘사 분석
- 분석의 가장 기본적인 지표
- 과거에 어떤 일이 일어났고, 현재는 무슨 일이 일어나고 있는지 확인(묘사)
- 진단 분석
- 묘사 단계에서 찾아낸 분석의 원인을 이해하는 과정
- 데이터를 기반으로 왜 발생했는지 이유를 확인(진단)
- 예측 분석
- 데이터를 통해 기업 혹은 조직의 미래, 고객의 행동 등을 예측하는 과정
- 무슨 일이 일어날 것인지를 예측
- 처방 분석
- 예측을 바탕으로 최적화하는 과정
- 무엇을 해야 할 것인지를 확인(처방)
따라서 올바르지 않은 것은 ③이다.
문제3
다음 중 기업의 데이터 분석 수준을 파악하기 위한 조직 평가 성숙도 단계에 대한 설명으로 적절하지 않은 것은?
① 도입 단계는 분석을 시작하는 단계로 환경과 시스템을 구축하고, 전문 담당 부서에서 분석을 수행하는 단계이다.
② 활용 단계는 분석 결과를 실제 업무에 적용하는 단계로 분석 기법을 도입하는 단계이다.
③ 확산 단계는 전사 차원에서 분석을 관리하고 공유하는 단계이다.
④ 최적화 단계는 분석을 진화시켜서 혁신 및 성과 향상에 기여하는 단계이다.
정답 ①
해설
- 도입 단계
- 분석을 시작해 환경과 시스템을 구축(도입)하는 단계
- 활용 단계
- 분석 결과를 실제 업무에 적용(활용)하는 단계
- 확산 단게
- 전사 차원에서 분석을 관리하고 공유(확산)하는 단계
- 최적화 단계
- 분석을 진화(최적화)시켜 혁신 및 성과 향상에 기여하는 단계
① : 전문 담당 부서에서 분석을 수행하는 단계는 활용 단계이다.
문제4
다음 중 개인정보 비식별 조치 방법으로 가장 올바르게 설명한 것은 무엇인가?
① 데이터 마스킹 : 정약용, 21세 박 씨, 20~30세
② 데이터 범주화 : 정약용, 21세 정 씨, 평균 20세
③ 가명처리 : 정약용, 21세 장길산, 20대
④ 총계처리 : 장길산 160cm, 정약용 180cm 학생 키 150~200cm
정답 ③
해설
- 데이터 마스킹
- 개인 식별 정보에 대하여 전체 또는 부분적으로 대체 값(공백, '*', 노이즈 등)으로 변환하는 것
- 데이터 범주화
- 단일 식별 정보를 해당 그룹의 대푯값으로 변환(범주화)하거나 구간 값으로 변환(범주화)하여 고유 정보 추적 및 식별을 방지하는 것
- 가명처리
- 개인 식별이 가능한 데이터를 직접적으로 식별할 수 없는 다른 값으로 대체하는 것
- 휴리스틱 가명화, 암호화, 교환 방법이 있다.
- 총계처리
- 개인정보에 대하여 통곗값을 적용하여 특정 개인을 판단할 수 없도록 하는 것
문제5
다음 중 개인정보를 목적 외의 용도로 이용하거나 제3자에게 제공이 가능한 경우로 옳지 않은 것은?
① 정보주체로부터 별도의 동의를 받은 경우
② 데이터 이용 활성화를 위한 통계작성에 이용해야 할 경우
③ 다른 법률에 의한 특별한 규젇이 있는 경우
④ 범죄의 수사와 공소의 제기 및 유지를 위하여 필요한 경우
정답 ②
해설
개인정보를 목적 외의 용도로 이용하거나 제3자에게 제공이 가능한 경우는 다음과 같다. (개인정보보호법 18조 2항)1. 정보주체로부터 별도의 동의를 받은 경우 2. 다른 법률에 특별한 규정이 있는 경우 3. 정보주체 또는 그 법정대리인이 의사표시를 할 수 없는 상태에 있거나 주소불명 등으로 사전 동의를 받을 수 없는 경우로서 명백히 정보주체 또는 제3자의 급박한 생명, 신체, 재산의 이익을 위하여 필요하다고 인정되는 경우 4. 삭제 5. 개인정보를 목적 외의 용도로 이용하거나 이를 제3자에게 제공하지 아니하면 다른 법률에서 정하는 소관 업무를 수행할 수 없는 경우로서 보호위원회의 심의, 의결을 거친 경우 6. 조약, 그 밖에 국제협정의 이행을 위하여 외국정부 또는 구제기구에 제공하기 위하여 필요한 경우 7. 범죄의 수사와 공소의 제기 및 유지를 위하여 필요한 경우 8. 법원의 재판업무 수행을 위하여 필요한 경우 9. 형 및 감호, 보호처분의 집행을 위하여 필요한 경우
최종모의고사 2회
문제1
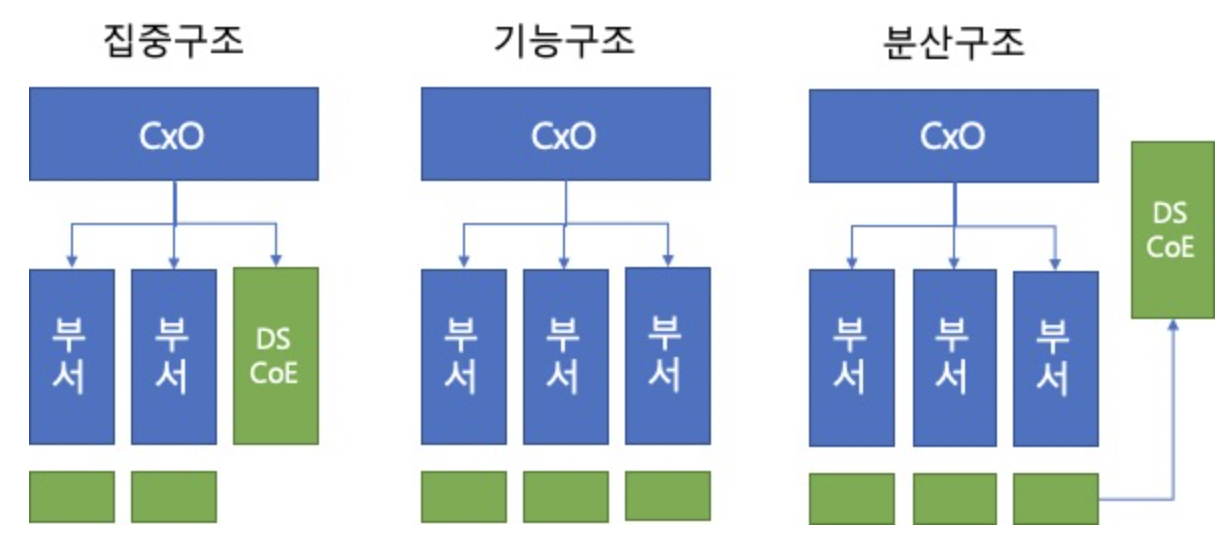
다음 중 다음 그림과 같은 빅데이터 조직 구조로 가장 적절한 것은 무엇인가?
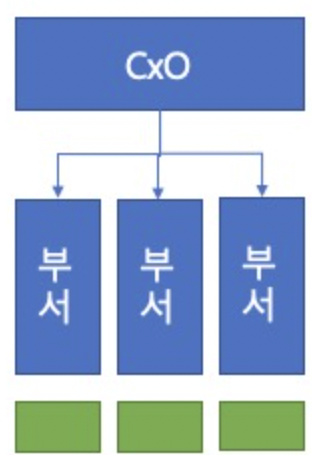
① 집중 구조
② 기능 구조
③ 분산 구조
④ 협업 구조
정답 ②
해설
기능 구조는 일반적인 형태로 별도 분석 조직이 없고, 해당 부서에서 분석을 수행한다.
문제2
다음 중 개인정보 비식별 조치 방법으로 가장 적절한 것은 무엇인가?
- 조치 전 : 주민등록번호 901212-1234567
- 조치 후 : 90년대 생, 남자
① 가명처리
② 총계처리
③ 데이터 삭제
④ 데이터 마스킹
정답 ③
해설
출생년도, 성별 외에 개인식별에 중요한 나머지 값을 삭제하여씅므로 데이터 삭제에 해당한다.
- 주민등록번호에서 연도 정보와 성별(남자) 정보만 남기고 주민등록번호는 삭제처리한다.
문제3
다음 중 분석과제 우선순위 선정 매트릭스에서 분석 과제의 적용 우선순위를 '난이도'에 둘 때 가장 올바른 우선 순위는?
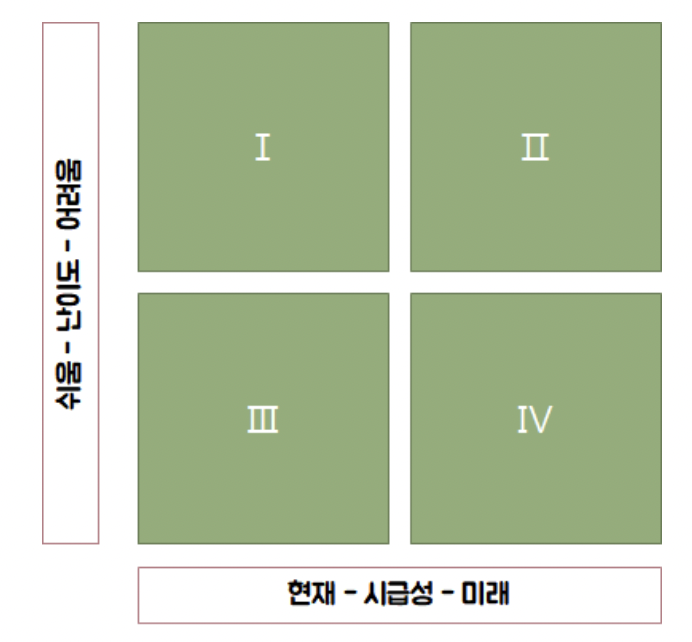
① 3 1 2
② 3 4 2
③ 3 2 4
④ 3 2 1
정답 ①
해설
시급성 : 3 4 2
난이도 : 3 1 2
문제4
다음 중 데이터로부터 잡음을 제거하기 위해 데이터 추세에 벗어나는 값들을 변환하는 기법으로 구간과, 군집화 등의 기법을 적용하는 데이터 변환 기술은 무엇인가?
① 정규화
② 평활화
③ 집계
④ 일반화
정답 ②
해설
평활화는 데이터 집합에 존재하는 잡음으로 인해 거칠게 분포된 데이터를 매끄럽게 만들기 위해 구간화, 군집화 등의 기법을 적용한다.
문제5
다음 중 빅데이터 위기 요인의 통제 방안에 대한 설명으로 가장 옳지 않은 것은?
① 개인정보 유출 및 사용으로 발생하는 피해에 대해 사용자가 책임을 지게 한다.
② 예측 알고리즘을 통해 범죄를 일으킬 가능성이 있는 사람에 대하여 사전에 구속, 접근 금지 등의 조치를 취한다.
③ 예측 알고리즘의 부당함을 반증할 수 있도록 알고리즘에 대한 접근권을 제공한다.
④ 알고리즈미스트를 통하여 불이익을 당한 사람들을 대변한다.
정답 ②
해설
예측 알고리즘을 통한 판단을 근거로 사전에 불이익을 줄 수는 없다.
문제6
상향식 접근 방식으로서 시행 착오를 통한 문제 해결을 위해 사용되며 가설의 생성, 디자인에 대한 실험, 실제 환경에서의 테스트, 테스트 결과에서의 통찰 도출 및 가설 확인의 프로세스로 구성되는 접근법은 다음 중 무엇인가?
① 프로토타이핑
② 최적화
③ 디자인 사고
④ 지도 학습
정답 ①
해설
시행 착오를 통한 문제 해결을 위해 사용되는 상향식 접근법은 프로토타이핑 접근법이다.
최종모의고사 3회
문제1
다음 중 빅데이터의 특징에 대한 설명으로 올바르지 않은 것은?
① 휘발성(Volatility) : 데이터가 얼마나 오래 저장될 수 있고, 타당하여 오랫동안 쓰일 수 있을지에 관한 특징
② 규모(Volume) : 정형 데이터뿐만 아니라 비정형, 반정형 데이터를 포함하는 특징
③ 속도(Velocity) : 사물 정보(센서, 모니터링), 스트리밍 정보 등 실시간 성 정보의 생성 속도 증가에 따라 처리 속도의 가속화가 요구되는 특징
④ 정확성(Validity) : 데이터의 규모가 아무리 크더라도 질 높은 데이터를 활용한 정확한 분석 수행이 없다면 의미가 없다는 특징
정답 ②
해설
정형 데이터뿐만 아니라 비정형, 반정형 데이터를 포함하는 특징은 다양성(Variety)에 대한 특징이다.
- 규모
- 물리적인 크기와 개념적인 범위까지 대규모인 데이터의 양
문제2
빅데이터 분석 방법론의 계층 중에서 입력자료(Input), 처리 및 도구(Process & Tool), 출력자료(Output)로 구성된 단위 프로세스는 무엇인가?
① 단계
② 태스크
③ 스텝
④ 프로세스 그룹
정답 ③
해설
스텝은 빅데이터 분석 방법론 계층에서 입력자료, 처리 및 도구, 출력자료로 구성된 단위 프로세스이다.
문제3
다음 중 SEMMA 분석 방법론에 대한 설명으로 가장 올바르지 않은 것은?
① SEMMA 분석 방법론의 분석 절차는 샘플링, 탐색, 수정, 최적화, 검증의 5단계로 되어 있다.
② 분석 솔루션 업체 SAS사가 주도한 통계 중심의 5단계 방법론이다.
③ 탐색 단계에서는 기초통계, 그래프 탐색, 요인별 분할표, 클러스터링, 변수 유의성 및 상관분석을 통한 분석 데이터를 탐색한다.
④ 수정 단계에서는 수량화, 표준화, 각종 변환, 그룹화를 통한 분석 데이터 수정 및 변환을 한다.
정답 ①
해설
SEMMA 분석 방법론의 분석 절차는 샘플링, 탐색, 수정, 모델링, 검증의 5단계로 되어 있다.
문제4
다음 중 상향식 접근 방식 절차로 올바른 것은?
① 프로세스 흐름 분석 프로세스 분류 분석 요건 식별 분석 요건 정의
② 프로세스 흐름 분석 프로세스 분류 분석 요건 정의 분석 요건 식별
③ 프로세스 분류 프로세스 흐름 분석 분석 요건 식별 분석 요건 정의
④ 프로세스 분류 프로세스 흐름 분석 분석 요건 정의 분석 요건 식별
정답 ③
해설
상향식 접근 방식 절차는 다음과 같다.
절차 내용 프로세스 분류 전사 업무 프로세스를 가치사슬, 메가 프로세스, 메이저 프로세스, 프로세스 단계로 구조화해 업무 프로세스 정의 프로세스 흐름 분석 프로세스 맵을 통해 프로세스 별로 업무 흐름을 상세히 표현 분석 요건 식별 각 프로세스 맵상의 주요 의사결정 포인트 식별 분석 요건 정의 각 의사결정 시점에 무엇을 알아야만 의사결정을 할 수 있는지 정의
문제5
다음 중 개인정보의 파기에 관한 사항으로 올바르지 않은 것은
① 개인정보처리자는 보유 기간의 경과, 개인 정보의 처리 목적 달성 등 그 개인 정보가 불필요하게 되었을 때는 지체 없이 그 개인정보를 파기하여야 한다.
② 개인정보처리자가 개인정보를 파기하지 아니하고 보존하여야 하는 경우에는 해당 개인정보 파일을 다른 개인정보와 함께 저장할 수 있다. 함께 저장할 때는 반드시 개인정보 파일을 암호화하여 저장, 관리하여야 한다.
③ 개인정보처리자가 제1항에 따라 개인정보를 파기할 때에는 복구 또는 재생되지 아니하도록 조치하여야 한다.
④ 개인정보의 파기방법 및 절차 등에 필요한 사항은 대통령령으로 정한다.
정답 ②
해설
개인정보처리자가 개인정보를 파기하지 아니하고 보존하여야 하는 경우에는 해당 개인정보 파일을 다른 개인정보와 분리하여서 저장, 관리하여야 한다.
문제6
다음 중 HDFS에 대한 설명으로 올바르지 않은 것은?
① HDFS는 수십 테라바이트 또는 페타바이트 이상의 대용량 파일을 분산된 서버에 저장하고, 그 저장된 데이터를 빠르게 처리할 수 있게 하는 파일 시스템이다.
② HDFS는 블록 구조의 파일 시스템으로 파일을 특정 크기의 블록으로 나누어 분산된 서버에 저장되는데 블록 크기는 64MB에서 하둡 2.0부터는 128MB로 증가되었다.
③ HDFS의 유형에는 Key-Value Store, Column Family Data Store, Document Store, Graph Store가 있다.
④ HDFS는 하나의 네임 노드와 하나 이상의 보조 네임 노드, 다수의 데이터 노드로 구성된다.
정답 ③
해설
Key-Value Store, Column Family Data Store, Document Store, Graph Store는 NoSQL의 유형이다.
- NoSQL
- 전통적인 RDBMS와 다른 DBMS를 지칭하기 위한 용어로 데이터 저장에 고정된 테이블 스키마가 필요하지 않고 조인 연산을 사용할 수 없으며, 수평적으로 확장이 가능한 DBMS이다.
