
최종모의고사 1회
문제1
교차 검증은 모델의 일반화 오차에 대해 신뢰한 추정치를 구하기 위해 훈련, 평가 데이터를 기반으로 하는 검증 기법이다. 다음 중 홀드 아웃 교차 검증을 설명한 것으로 가장 적합한 것은 무엇인가?
① 전체 데이터에서 평가 데이터를 학습에도 사용하므로 데이터 손실이 발생하지 않는다.
② 전체 데이터를 비복원추출 방식을 이용하여 렌덤하게 훈련 데이터와 평가 데이터로 나눠 검증하는 방법이다.
③ 검증 데이터는 최적화된 분류기의 성능을 평가할 때 사용되는 데이터이다.
④ 데이터 집합을 무작위로 동일 크기를 갖는 K개의 부분 집합으로 나누고, 그중 1개를 평가 데이터로, 나머지 (K-1)개를 훈련 데이터로 선정하여 분석 모형을 평가하는 기법이다.
정답 ②
해설
- 계산량이 많지 않아 모형을 쉽게 평가할 수 있으나 전체 데이터에서 평가 데이터만은 학습에 사용할 수 없으므로 데이터 손실이 발생한다.
- 검증 데이터는 분류기들의 매개변수를 최적화하기 위해 사용되는 데이터이다.
- 데이터 집합을 무작위로 동일 크기를 갖는 K개의 부분 집합으로 나누고, 그중 1개를 평가 데이터로, 나머지 (K-1)개를 훈련 데이터로 선정하여 분석 모형을 평가하는 기법은 K-fold 교차 검증이다.
- 홀드 아웃 교차 검증은 전체 데이터를 비복원추출 방식을 이용하여 랜덤하게 훈련 데이터와 평가 데이터로 나눠 검증하는 기법이다.
문제2
다음 중 두 개 이상의 집단 간 비교를 수행하고자 할 때 집단 내의 분산, 총 평균과 각 집단의 평균 차이에 의해 생긴 집단 간 분산 비교로 얻은 F-분포를 이용하여 가설검정을 수행하는 방법은 무엇인가?
① Z-검정
② T-검정
③ 분산 분석
④ 카이제곱 검정
정답 ③
해설
분산 분석(ANOVA)은 두 개 이상의 집단 간 비교를 수행하고자 할 때 집단 내의 분산, 총 평균과 각 집단의 평균 차이에 의해 생긴 집단 간 분산 비교로 얻은 F-분포를 이용하여 가설검정을 수행하는 방법이다.
문제3
다음 중 과대 적합을 방지하기 위한 드롭아웃을 설명한 것으로 가장 부적절한 것은 무엇인가?
① 개별 가중치 값을 제한하여 복잡한 모델을 좀 더 간단하게 하는 방법이다.
② 드롭아웃은 신경망 학습 시에만 사용하고, 예측 시에는 사용하지 않는다.
③ 학습 시에 인공신경망이 특정 뉴런 또는 특정 조합에 너무 의존적이게 되는 것을 방지해준다.
④ 드롭아웃은 학습 과정에서 신경망의 일부를 사용하지 않는 방법이다.
정답 ①
해설
개별 가중치 값을 제한하여 복잡한 모델을 좀 더 간단하게 하는 방법은 가중치 규제이다.
문제4
다음 중 주어진 데이터로부터 학습을 통해 내부에서 결정되는 매개변수를 최적화하는 기법으로 가장 부적절한 것은 무엇인가?
① 확률적 경사 하강법
② 모멘텀
③ AdaGrad
④ 드롭아웃
정답 ④
해설
드롭아웃은 매개변수를 최적화 하는 기법이 아닌 과대 적합을 방지하기 위한 기법이다.
문제5
다음 중 데이터 시각화 기법을 설명한 것으로 가장 적합한 것은 무엇인가?
① 시간의 변화에 따른 경향(트렌드)을 파악하기 위해 산점도를 사용한다.
② 집단 간의 상관관계를 확인하여 다른 수치의 변화를 예측하기 위해 히트맵을 사용한다.
③ 지도를 통해 시점에 따른 경향, 차이 등을 확인하기 위해 카토그램을 사용한다.
④ 전체에서 부분 간 관계를 설명하기 위해 막대그래프를 사용한다.
정답 ③
해설
데이터 시각화 기법은 다음과 같다.
구분 내용 기법 시간 시각화 - 시간 흐름에 따른 변화를 통해 경향(트렌드 파악) - 막대그래프
- 점그래프분포 시각화 - 분류에 따른 변화를 최대, 최소, 전체 분포 등으로 구분
- 전체에서 부분 간 관계를 설명- 파이 차트
- 도넛 차트
- 트리맵관계 시각화 - 집단 간의 상관관계를 확인하여 다른 수치의 변화 예측 - 산점도
- 버블 차트
- 히스토그램비교 시각화 - 각각의 데이터 간의 차이점과 유사성 관계도 확인 가능 - 히트맵
- 평행 좌표 그래프
- 체르노프 페이스
- 스타차트공간 시각화 - 지도를 통해 시점에 따른 경향, 차이 등을 확인 가능 - 등치선도
- 도트맵
- 카토그램따라서 가장 적합한 것은 ③이다.
문제6
다음 중 버블 차트의 시각화 유형과 같은 것은 무엇인가?
① 체르노프 페이스
② 산점도
③ 트리맵
④ 히트맵
정답 ②
해설
버블 차트는 관계 시각화 기법이므로 같은 유형인 것은 산점도이다.
최종모의고사 2회
문제1
다음 중 범주에 따라 분류된 변수가 정규 분포되어 있다면 빈도가 실제 기대되는 값으로부터 유의미한 차이가 관찰되는가를 보기 위한 검증으로 가장 알맞은 것은?
① Z-검정
② 카이제곱 검정
③ 분산 분석
④ T-검정
정답 ②
해설
- Z-검정은 귀무가설에서 검정 통계량의 분포를 정규분포로 근사할 수 있는 통계 검정이다.
- 카이제곱 검정은 범주에 따라 분류된 변수가 정규 분포되어 있다면 빈도가 실제 기대되는 값으로부터 유의미한 차이가 관찰되는가를 보기 위한 검증 방법이다.
- 분산 분석(ANOVA)은 두 개이 상의 집단 간 비교를 수행하고자 할 때 집단 내의 분산, 총평균과 각 집단의 평군 차이에 의해 생긴 집단 간 분산 비교로 얻은 F-분포를 이용하여 가설검정을 수행하는 방법이다.
- T-검정은 두 집단 간의 평균을 비교하는 모수적 총계 방법으로써 표본이 정규성, 등분산성, 독립성 등을 만족할 경우 적용한다.
문제2
다음 중 훈련 데이터를 중복하여 사용하지 않고 훈련 데이터 세트를 나누는 기법으로 가장 알맞은 것은?
① 직접 투표
② 배깅
③ 페이스팅
④ 랜덤 서브스페이스
정답 ③
해설
- 직접 투표는 단순 투표 방식으로 개별 모형의 결과 기준이다.
- 배깅은 훈련 데이터의 중복을 허용하며 훈련 데이터 세트를 나누는 기법으로 복원추출 방식이다.
- 페이스팅은 훈련 데이터를 중복하여 사용하지 않고 훈련 데이터 세트를 나누는 기법으로 비복원추출 방식이다.
- 랜덤 서브스페이스는 훈련 데이터를 모두 사용하고 특성은 샘플링하는 방식이다.
문제3
다음 중 하나의 자산을 획득하려 할 때 주어진 기간 동안 모든 연관 비용을 고려할 수 있도록 확인하기 위해 사용되는 평가 기법으로 가장 알맞은 것은?
① TCO
② ROI
③ NPV
④ IRR
정답 ①
해설
- TCO(Total Coas of Ownership)는 총 소유 비용이다.
- TCO는 하나의 자산을 획득하려 할 때 주어진 기간 동안 모든 연관 비용을 고려할 수 있도록 확인하기 위해 사용되는 평가 기법이다.
문제4
다음 중 관계 시각화에 대한 설명으로 가장 알맞지 않은 것은?
① 다변량 데이터 사이에 존재하는 변수 사이의 연관성, 분포와 패턴을 찾는 시각화 방법이다.
② 변수 사이의 연관성인 상관관계는 한 가지 요소의 변화가 다른 요소의 변화와 관련이 있는지를 표현하는 시각화 기법이다.
③ 산점도 행렬은 산점도에서 데이터값을 나타내는 점 또는 마크에 여러 가지 의미를 부여하여 확장된 차트이다.
④ 관계 시각화의 유형으로 산점도, 산점도 행렬, 버블 차트, 히스토그램 등이 있다.
정답 ③
해설
- 산점도 행령은 다변량 변수를 갖는 데이터에서 가능한 모든 변수 쌍에 대한 산점도를 행렬 형태로 표현한 그래프이다.
- 버블 차트는 산점도에서 데이터값을 나타내는 점 또는 마크에 여러 가지 의미를 부여하여 확장된 차트이다.
문제5
다음 중 초매개변수로 설정이 가능하지 않은 것은?
① 학습률
② 가중치
③ 은닉층의 수
④ 의사결정나무의 깊이
정답 ②
해설
초매개변수로 설정 가능한 예시로는 학습률, 은닉층의 개수, 의사결정나무의 깊이 등이 있다.
문제6
다음 중 혼동 행렬에 대한 설명으로 적절하지 않은 것은?
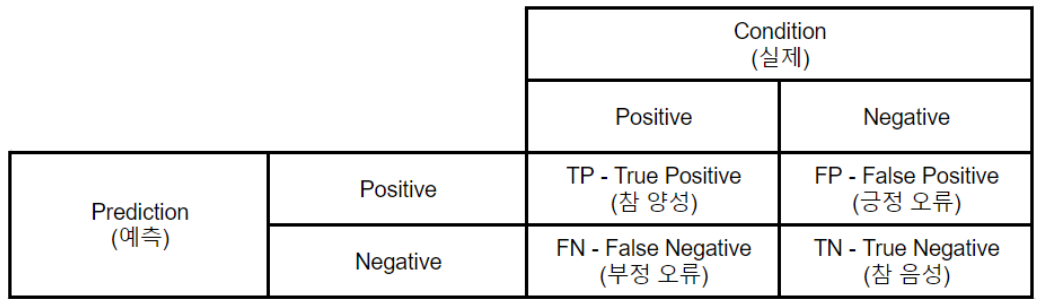
① 실제로 부정인 범주 중 부정으로 올바르게 예측한 비율을 정확도라고 하며, (TP+TN)/(TP+TN+FP+FN)라고 표기한다.
② 카파 값은 0~1 사이의 값을 가지며, 1에 가까울수록 예측값과 실제값이 일치하지 않는 것을 의미한다.
③ 정밀도는 '긍정'으로 예측한 비율 중에서 실제로 긍정인 비율로 TP/(TP+FP)라고 표기한다.
④ 머신러닝 성능 평가지표 중 오차 비율을 표기하는 식은 (FP+FN)/(TP+TN+FP+FN)이다.
정답 ①, ②
해설
정확도는 전체 예측에서 실제로 긍정 또는 부정으로 올바르게 예측한 것이 차지하는 비율이다.혼동행렬 관련 주요 평가지표는 다음과 같다.
평가지표 계산식 내용 특이도
(Specificity)실제로 부정인 범주 중에서 부정으로 올바르게 예측(TN)한 비율 민감도
(Sensitivity)실제로 긍정인 범주(TP+FN) 중에서 긍정으로 올바르게 예측(TP)한 비율 거짓 긍정률
(FP Rate)실제로 부정인 범주(TN+FP) 중에서 긍정으로 잘못 예측(FP)한 비율 정밀도
(Precision)긍정으로 예측한 비율(TP+FP) 중에서 실제로 긍정(TP)인 비율 정확도
(Accuracy)전체 예측(TP+TN+FP+FN)에서 실제로 긍정 또는 부정으로 올바르게 예측한 것(TP+TN)이 차지하는 비율 오차비율
(Error Rate)전체 예측(TP+TN+FP+FN)에서 잘못 예측한 것(FP+FN)이 차지하는 비율 ② 카파 값은 0~1 사이의 값을 가지며, 1에 가까울수록 예측값과 실제값이 일치하는 것을 의미한다.
- ②번 했는데 틀렸다고 해서 놀랐다.
최종모의고사 3회
문제1
다음 중 관계 시각화에 대한 설명으로 옳지 않은 것은?
① 다변량 데이터 사이에 존재하는 변수 사이의 연관성, 분포와 패턴을 찾는 시각화 방법이다.
② 관계 시각화의 주요 유형으로 히트맵, 체르노프 페이스, 스타 차트 등이 있다.
③ 변수 사이의 연관성인 상관관계는 한 가지 요소의 변화가 다른 요소의 변화와 관련이 있는지를 표현하는 시각화 기법이다.
④ 정보를 SNS상에 쉽고 빠르게 전달할 수 있다.
정답 ②
해설
관계 시각화의 유형으로는 산점도, 산점도 행렬, 버블차트, 히스토그램, 네트워크 그래프 등이 있다.
- 그런데 ③에서 상관관계가 시각화 기법인가?(산점도를 말하는 건가?)
문제2
다음 중 적합도 검정에 대한 설명으로 가장 올바르지 않은 것은?
① 적합도 검정은 표본 집단의 분포가 주어진 특정 이론을 따르고 있는지를 검정하는 기법이다.
② 적합도 검정 기법으로는 카이제곱 검정, 샤피로-윌크 검정, K-S 검정, Q-Q Plot이 있다.
③ 카이제곱 검정에서는 R 언어에서 chisq.test() 함수를 이용하여 나온 결과의 p-value 값이 0.05보다 클 경우 관측된 데이터가 가정된 확률을 따른다고 할 수 있다.
④ 정규성 검정은 R에서 sharpirowilk.test() 함수를 이용하여 검정할 수 있으며, 이때 귀무가설은 "표본은 정규 분포를 따른다."이다.
정답 ④
해설
- sharpirowilk.test() 함수를 이용하여 검정하는 것은 샤피로-윌크 검정이다.
문제3
다음 중 과대 적합에 대한 설명으로 가장 올바르지 않은 것은?
① 과대 적합은 제한된 훈련 데이터 세트에 너무 과하게 특화되어 새로운 데이터에 대한 오차가 매우 커지는 현상이다.
② 과대 적합을 방지하기 위해 데이터 세트 증가, 모델 복잡도 감소, 가중치 규제, 드롭아웃 방법을 적용한다.
③ 가중치 규제는 개별 가중치 값을 제한하여 복잡한 모델을 좀 더 간단하게 하는 방법으로 종류에는 P1 규제와 P2 규제가 있다.
④ 드롭아웃은 학습 과정에서 신경망 일부를 사용하지 않는 방법이다.
정답 ③
해설
가중치 규제는 개별 가중치 값을 제한하여 복잡한 모델을 좀 더 간단하게 하는 방법으로 종류에는 L1 규제(라쏘)와 L2 규제(릿지)가 있다.
문제4
다음 데이터 시각화 유형 중 가장 올바르지 않은 것은?
① 시간 시각화는 시간 흐름에 따른 변화를 통해 경향(트렌드)을 파악하는 방법으로 막대그래프 기법과 점그래프 기법이 있다.
② 분포 시각화는 전체에서 부분 간 관계를 설명하는 방법으로 파이 차트 기법, 도넛 차트 기법, 트리 차트 기법이 있다.
③ 관계 시각화는 집단 간의 상관관계를 확인하여 다른 수치의 변화를 예측하는 방법으로 산점도 기법, 버블 차트 기법, 히스토그램 기법이 있다.
④ 비교 시각화는 각각의 데이터 간의 차이점과 유사성 관계도 확인 가능한 방법으로 등치선도 기법, 도트맵 기법, 카토그램 기법이 있다.
정답 ④
해설
- 공간 시각화에는 등치선도 기법, 도트맵 기법, 카토그램 기법이 있다.
- 비교 시각화에는 히트맵 기법, 평행 좌표 그래프 기법, 체르노프 페이스 기법이 있다.
문제5
다음 빅데이터 시각화 도구 중 코딩 없이 스프레드시트, 데이터베이스 형태 데이터를 쉽게 가시화하는 시각화 도구는 무엇인가?
① 태블로(Tableau)
② 차트 블록(Chart Blocks)
③ 인포그램(Infogram)
④ 데이터 래퍼(Data Wrapper)
정답 ②
해설
- 빅데이터 시각화 도구 중 코딩 없이 스프레드시트, 데이터베이스 형태 데이터를 쉽게 가시화하는 시각화 도구는 차트 블록이다.
- 차트 블록은 웹 기반 차트 구현(트위터, 페이스북 등에 공유)이 가능하다.
문제6
다음 중 응용 프로그램 성능 측정 항목의 측정 주기에 대한 설명으로 가장 올바르지 않은 것은?
① 응답시간/트랜잭션 처리량은 실시간 측정을 한다.
② 메모리 사용은 정기적 측정을 한다.
③ 데이터베이스 처리는 실시간 측정을 한다.
④ 오류 및 예외 발생 여부는 정기적 측정을 한다.
정답 ④
해설
오류 및 예외 발생 여부는 실시간 측정을 한다.
문제7
다음 중 카파 통계량에 대한 설명으로 가장 올바르지 않은 것은?
① 두 관찰자가 측정한 범주 값에 대한 일치도를 측정하는 방법이다.
② 0~1의 값을 가지며 1에 가까울수록 모델의 예측값과 실젯값이 정확히 일치하며, 0에 가까울수록 모델의 예측값과 실젯값이 불일치한다.
③ 정확도 외에 카파 통계량을 통해 모형의 평가 결과가 우연히 나온 결과가 아니라는 것을 설명할 수 있다.
④ 카파 통계량의 계산식은 이다.
정답 ④
해설
- 카파 통계량의 계산식은 이다.
- : 카파 상관계수
- : 예측이 일치할 확률
- : 예측이 우연히(eventually) 일치할 확률
- 혼동 행렬에서 F1-Score의 계산식은 이다.
