임의의 길이 데이터 전체 암호화하는데 조금 어려움이 있다.
그래서 128bit단위로 데이터를 암호화하는 AES가지고 Modes of operation.
임의의 길이 데이터를 암호화 복호화 해주기 위해 여러개를 반복해서 사용해야되는데 어떻게 여러번 반복해서 사용하냐에 대한 정의가 Modes of operation임.
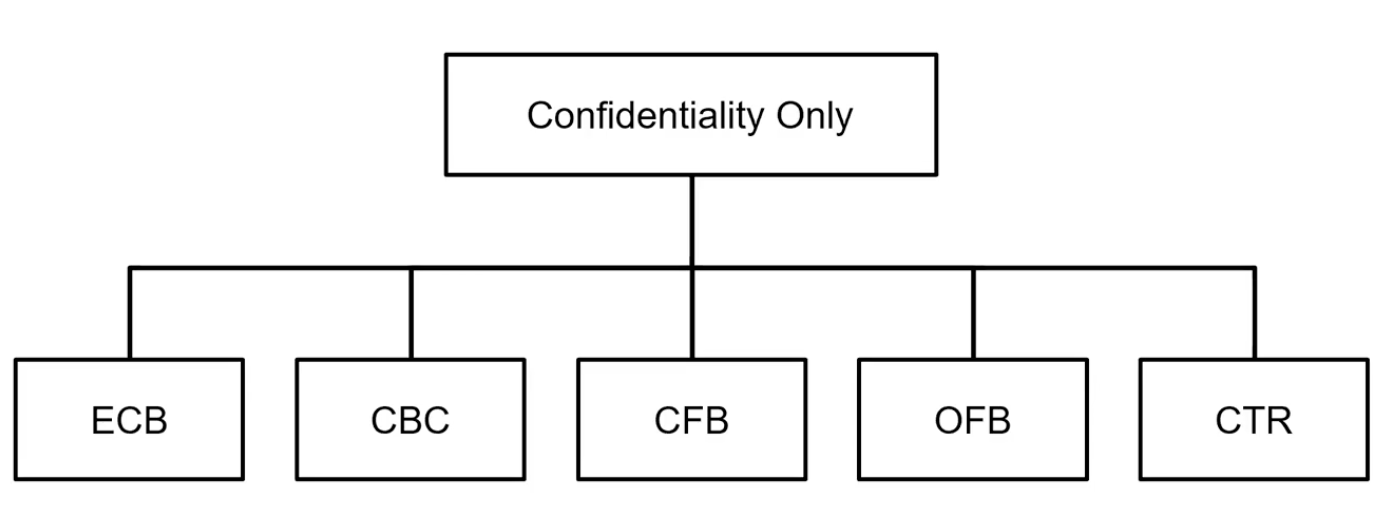
Block Cipher을 가지고 기밀성은 만족 시킬 수 있지만 무결성은 만족시킬 수 없다.(=Confidentiality Only) Cipher text를 잘 만들어내기는 하지만, 네트워크를 통해서 전달되는 과정에서 Cipher text에서 문제, 변형이 생겼을때 이것을 잡아낼 수 없음.
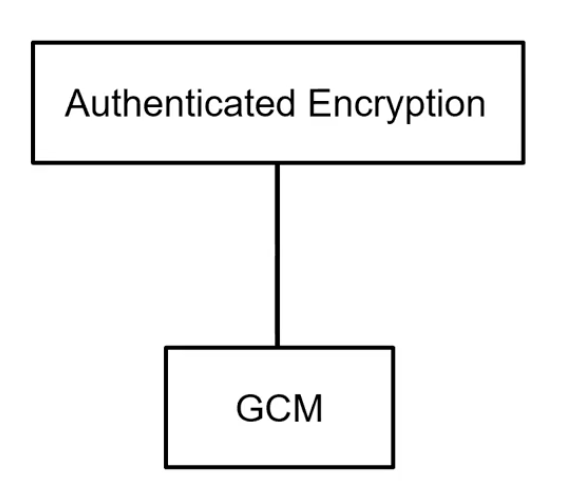
"Confidentiality Only가 아닌 데이터의 무결성도 체크를 해보자" 라는 운영 모드이다. GCM(갈로아 counter mode)
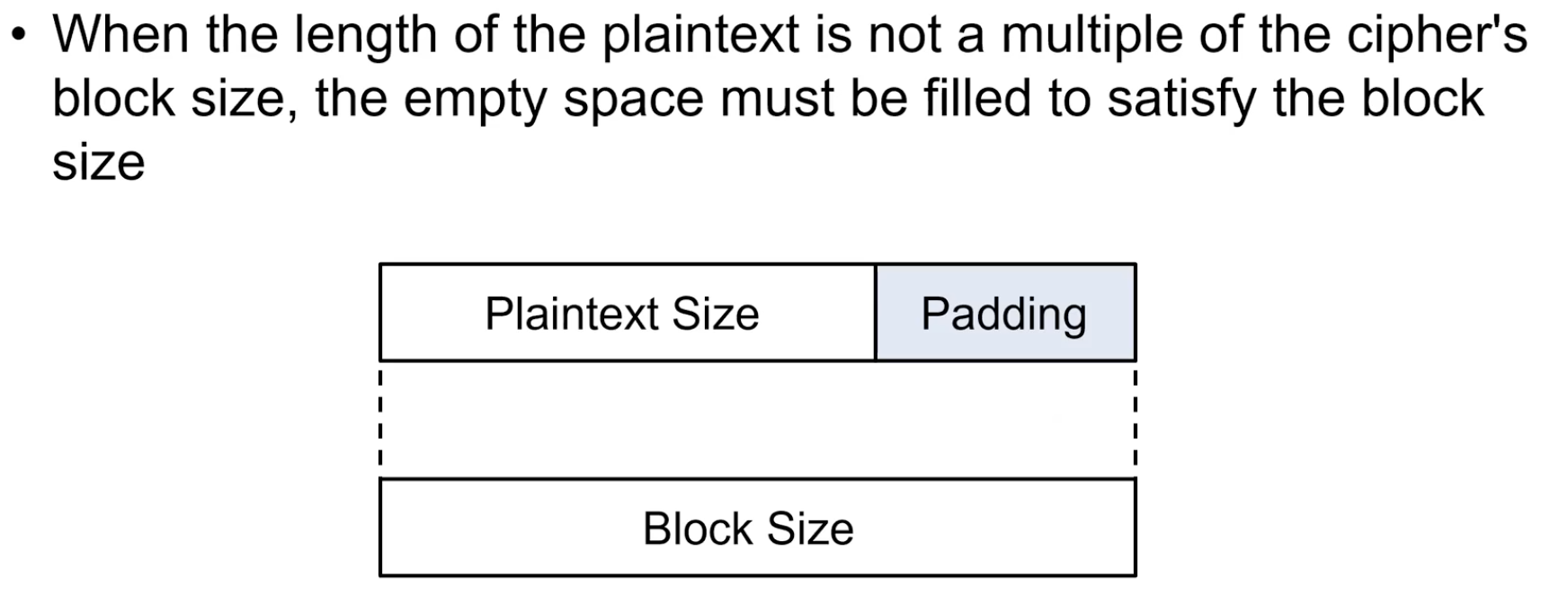
Padding
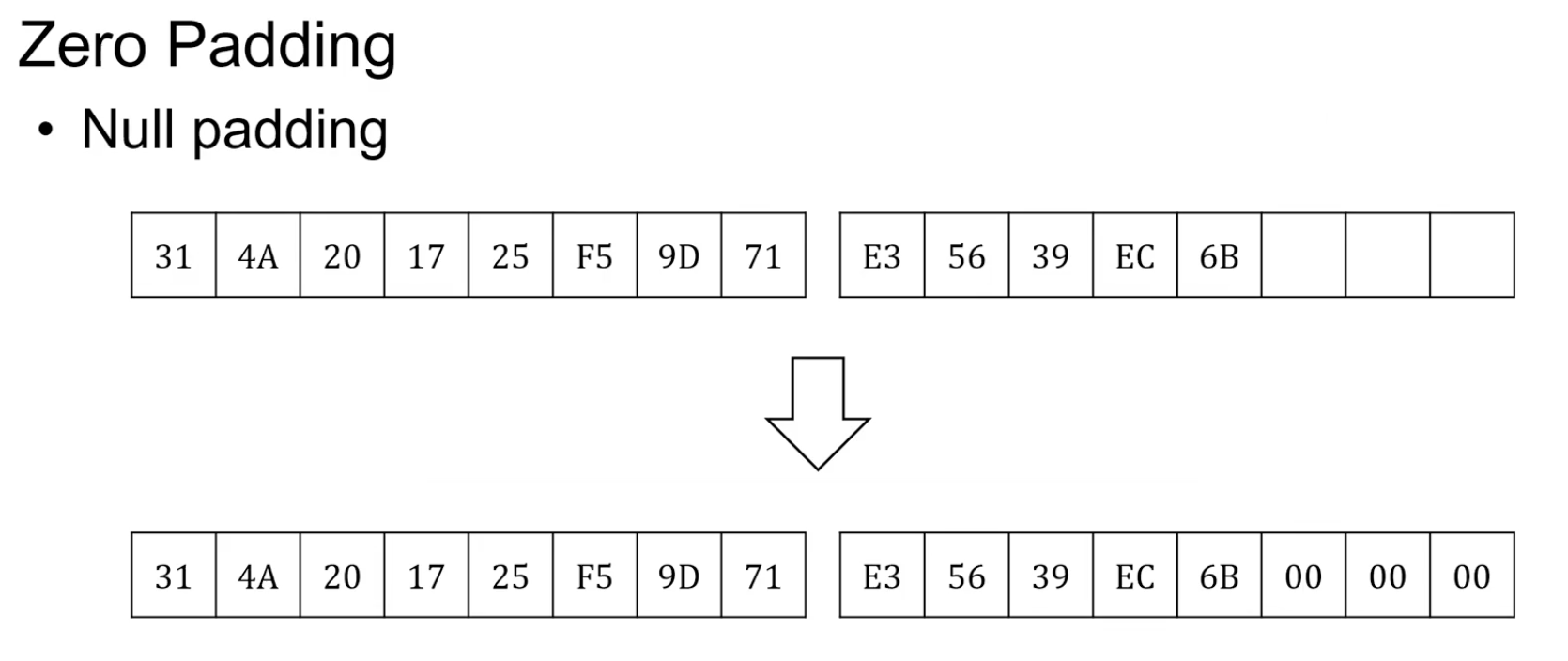
데이터를 암호화 할 때 항상 전송해야되는 데이터가 16byte의 배수가 아닌경우 block size를 맞춰주기 위해 padding이 필요하다.Zero Padding
뒤에 3byte가 부족한 경우 3byte를 모두 0으로 채워 넣음.
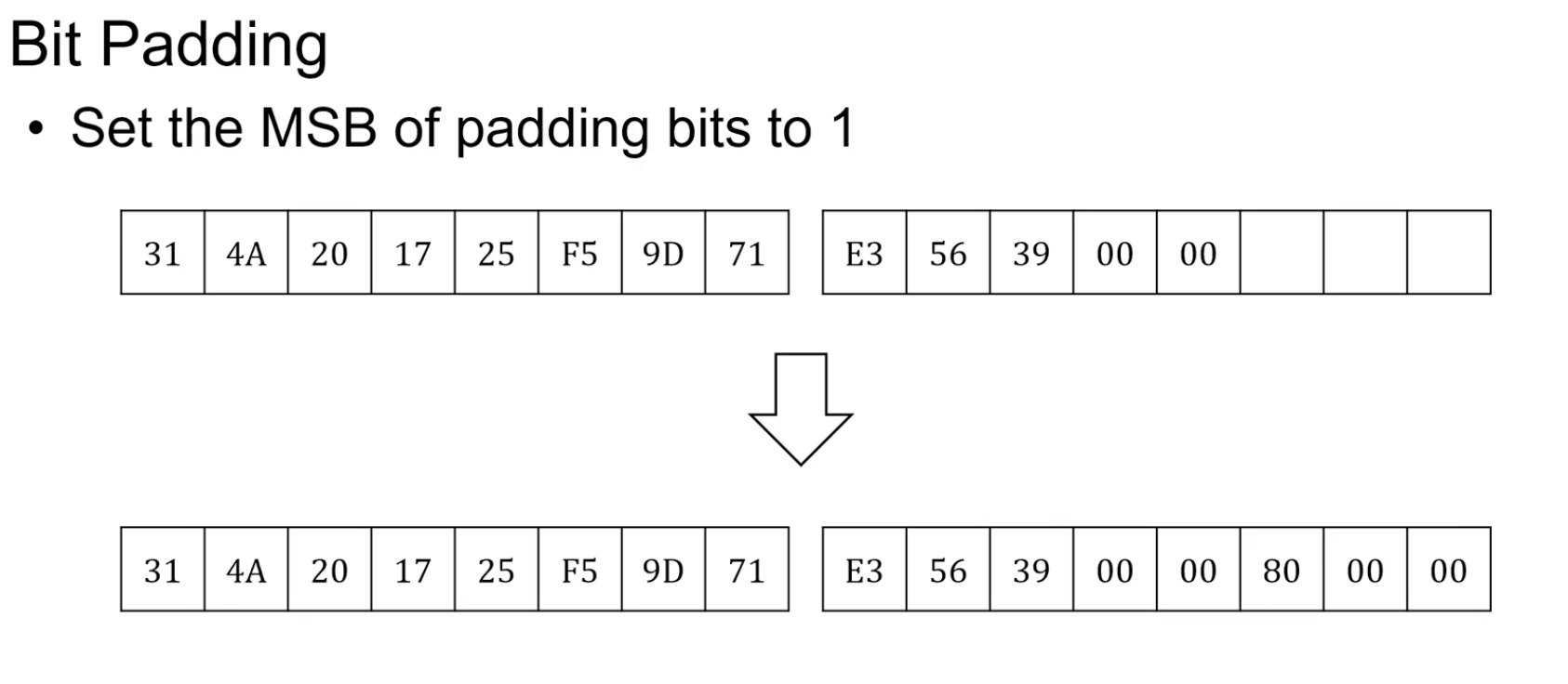
문제: 원래 데이터 마지막 바이트가 0으로 끝나는 경우 Decryption하는 경우 패딩을 제거 시켜야하는데 어디까지 Padding인지 모름.Bit Padding
Padding넣을때 Byte단위로 넣는데 첫 비트를 1넣는다. 80(=1000 0000)
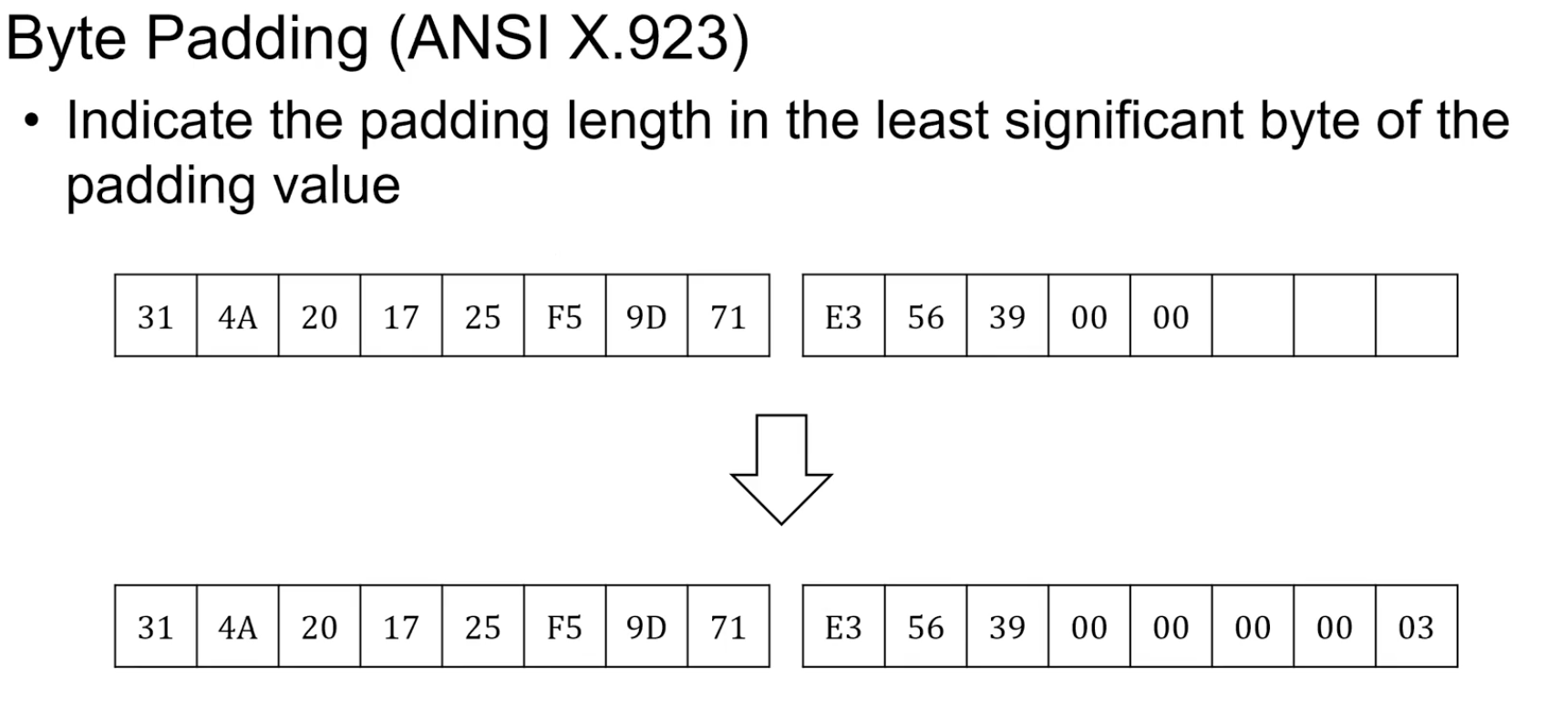
문제: 마지막 바이트가 80으로 오는 경우. 그래서 무조건 패딩을 하게 한다. 그렇게 할 경우 마지막 바이트가 80이여도 패딩이 필수이기에 80 80 이런식으로 결국엔 동일하게 80 byte block을 만나기 전까지 모두 지우면 된다.Byte Padding(ANSI X.923)
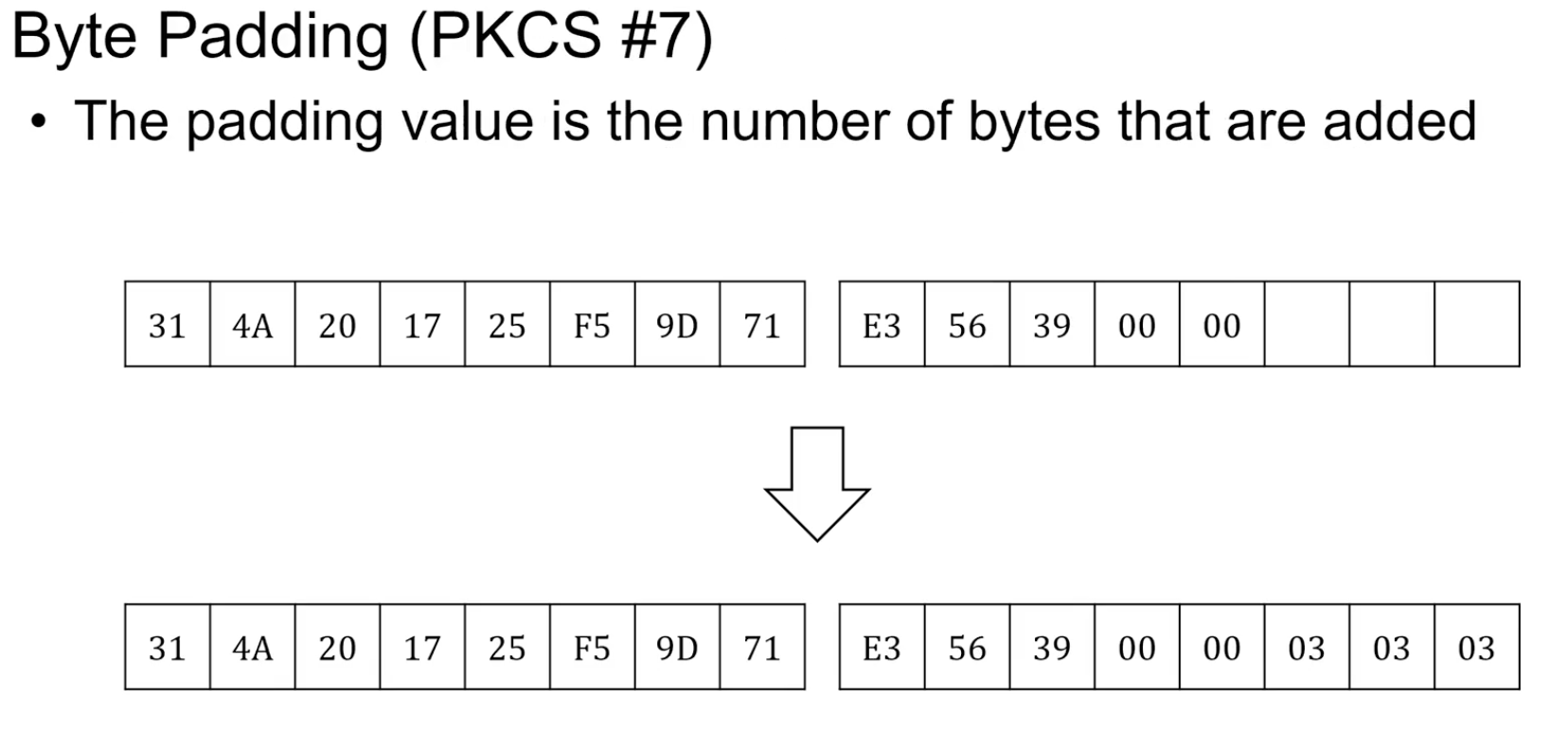
마지막 byte에 padding 개수를 표시. (03)
문제:다음과 같이 01이 패딩의 개수 1개란 것인지 원본 데이터의 마지막이 01인지 구분하기 힘들다. 그렇기에 이것또한 무조건 패딩이 존재한다는 정책을 만들면 해당 문제를 해결 가능하다.
Byte Padding(PKCS #7)
패딩 전체 다 패딩 개수를 byte에 작성하는 방법이다.
동일하게 무조건 패딩을 넣는 정책을 만들어야 함.
Cofidential Only
패딩이 필요한 경우
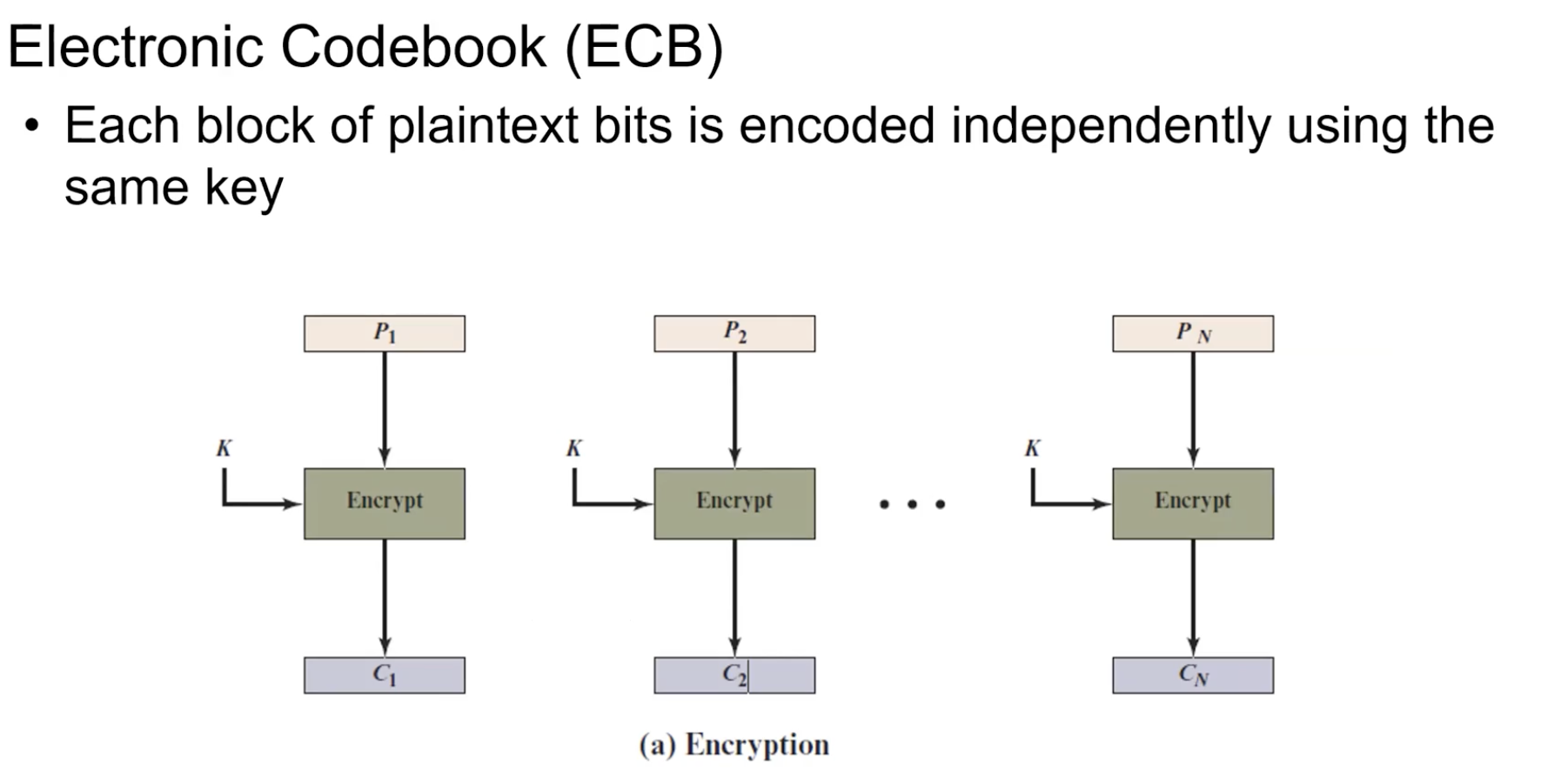
Electronic Codebook (ECB)
block 단위(1word = 4byte = 32bit)로 128bit를 나누어 각각 독립적으로 병렬적으로 데이터를 암호화 하고 나온 결과들을 이어 합친 것. 무조건 128bit단위로 넣어줘야 하기에 패딩이 필요하다.
문제: 동일한 입력인 경우. Plain text와 Key가 같다면 반드시 Cipher text도 반드시 같다. (Block Chipher은 Deterministic 결정론적)
이미지를 암호화하는 과정에 이미지에서 비슷한 부분이 계속 있을 수 있다. 똑같은 block은 똑같은 형태로 암호화가 된다. 패턴을 노출시킬 수 있다.

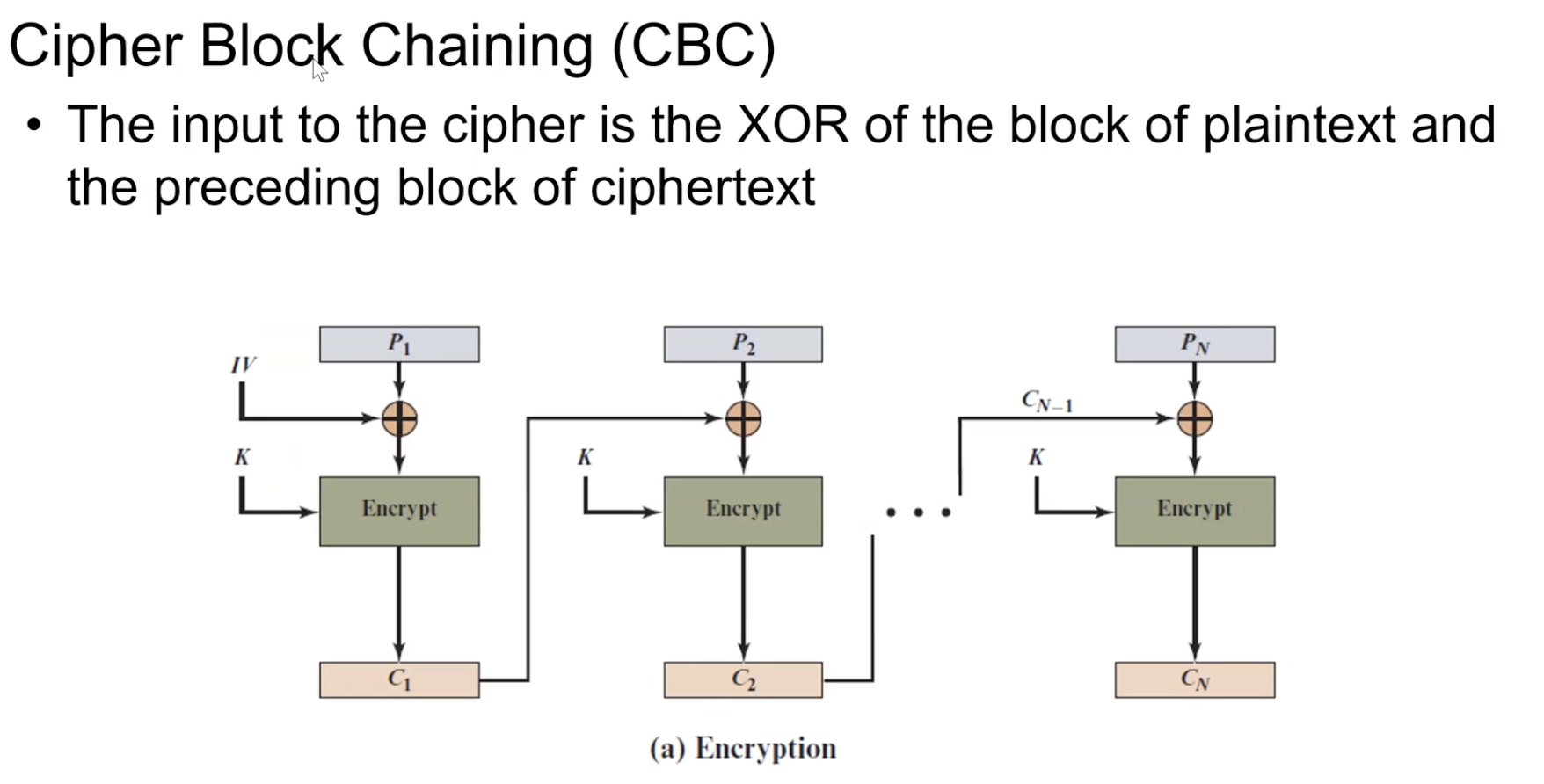
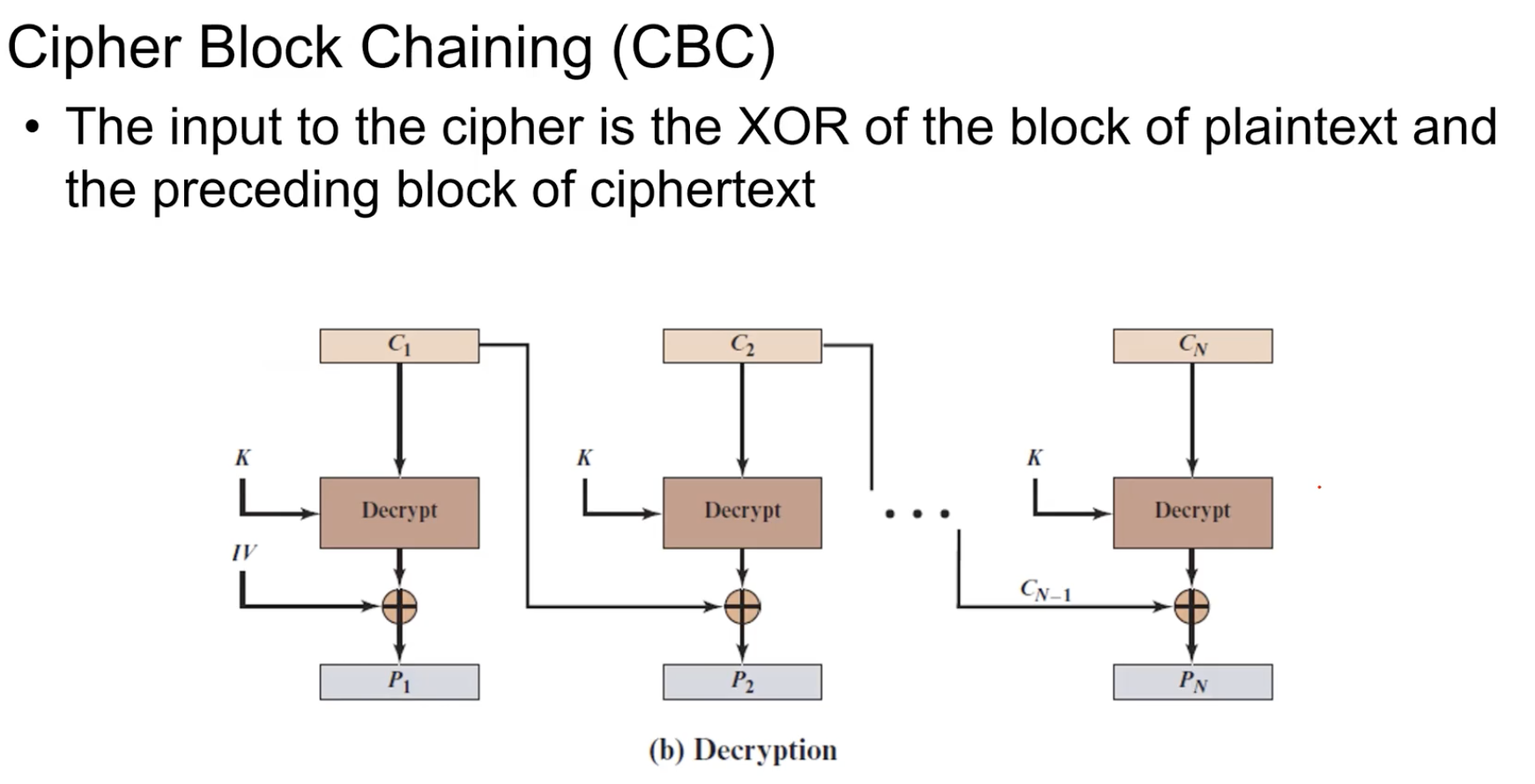
Cipher Block Chaining (CBC)
앞에서의 연산결과가 지금 연산에서의 영향을 주고 지금 연산에서의 결과가 다음 연산에서의 결과에 영향을 준다.
앞에서의 Cipher text와 현재의 Plain text을 XOR.
이렇게 하는경우 P1과 P2가 같은 Plain text라고 하더라도 P1의 암호문과 XOR되고 암호화 되기에 C1, C2가 달라짐. (Probabilistic 확률적특성: 같은 입력 + 같은 키여도, 매번 다른 암호문이 나올 수 있음)
첫번째 연산의 경우 IV(Initialization Vector or nonce)을 사용해 전체 암호문에 대한 Probabilistic한 특성을 부여.
Palintext와 Key가 동일하더라도 IV가 다르면 Cipher text는 항상 다름.
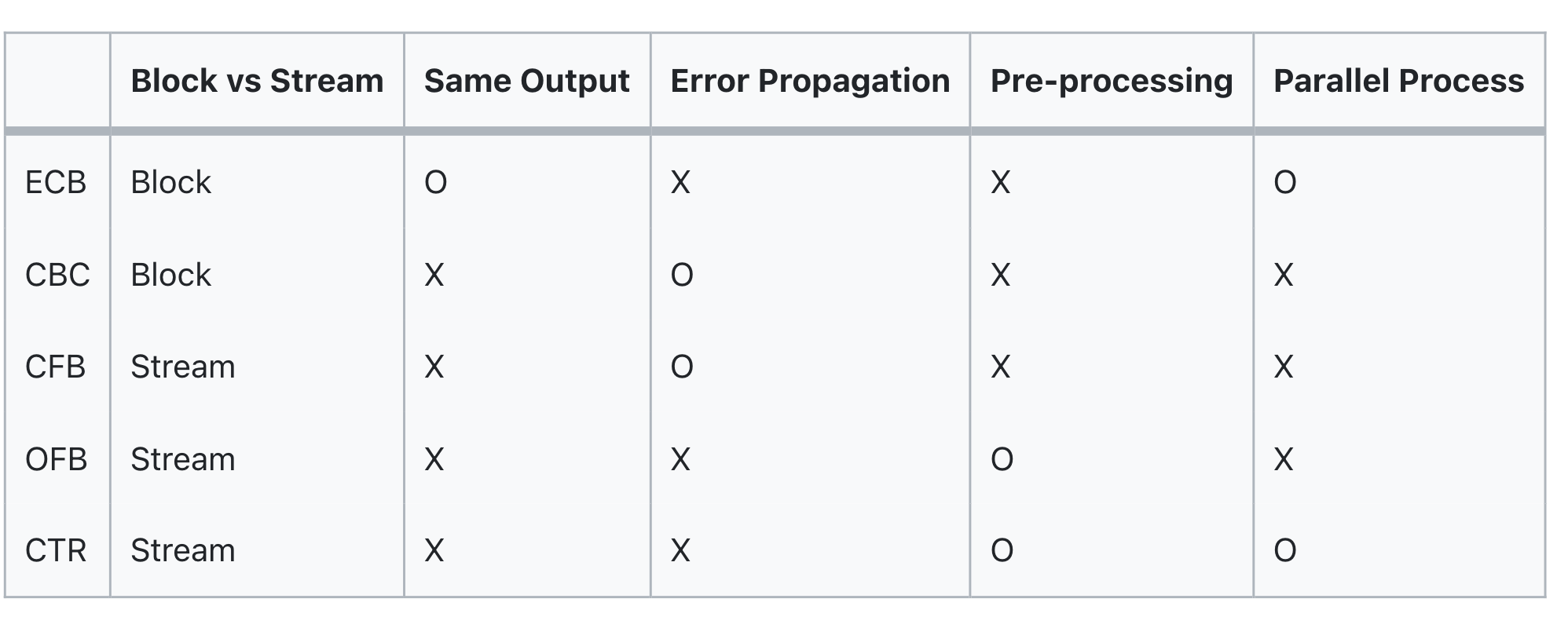
단점: ECB같은 경우 전체 평문에 대해 병렬처리가 가능하다. 하지만 CBC의 경우 앞 Chiper text가 필요하다. 암호화할 때는 병렬처리가 불가능하다. 복호화 경우에는 Chiper text의 값들을 모두 알기에 병렬처리가 가능하다.
Error Propagation(오류 전파)
암호문을 전송하다가 암호문에서의 어떤 비트(byte)에 문제가 생겼을 때. 위처럼 4번째 byte에서 문제가 생겼을 때, Decryption할때 전체 Block 모두 영향을 받음.(Diffusion효과: AES에서 평문과 암호문 연관관계를 섞기위해 평문에 한비트라도 문제가 생기면 암호문에서 여러개의 비트에 영향을 받음)
뒤에 있는 ci+1에 XOR연산이 진행되는데 달라진 byte 부분에만 영향을 준다. (4번째 byte)
✅ (Pi, Pi+1)까지만 오류가 전파된다.
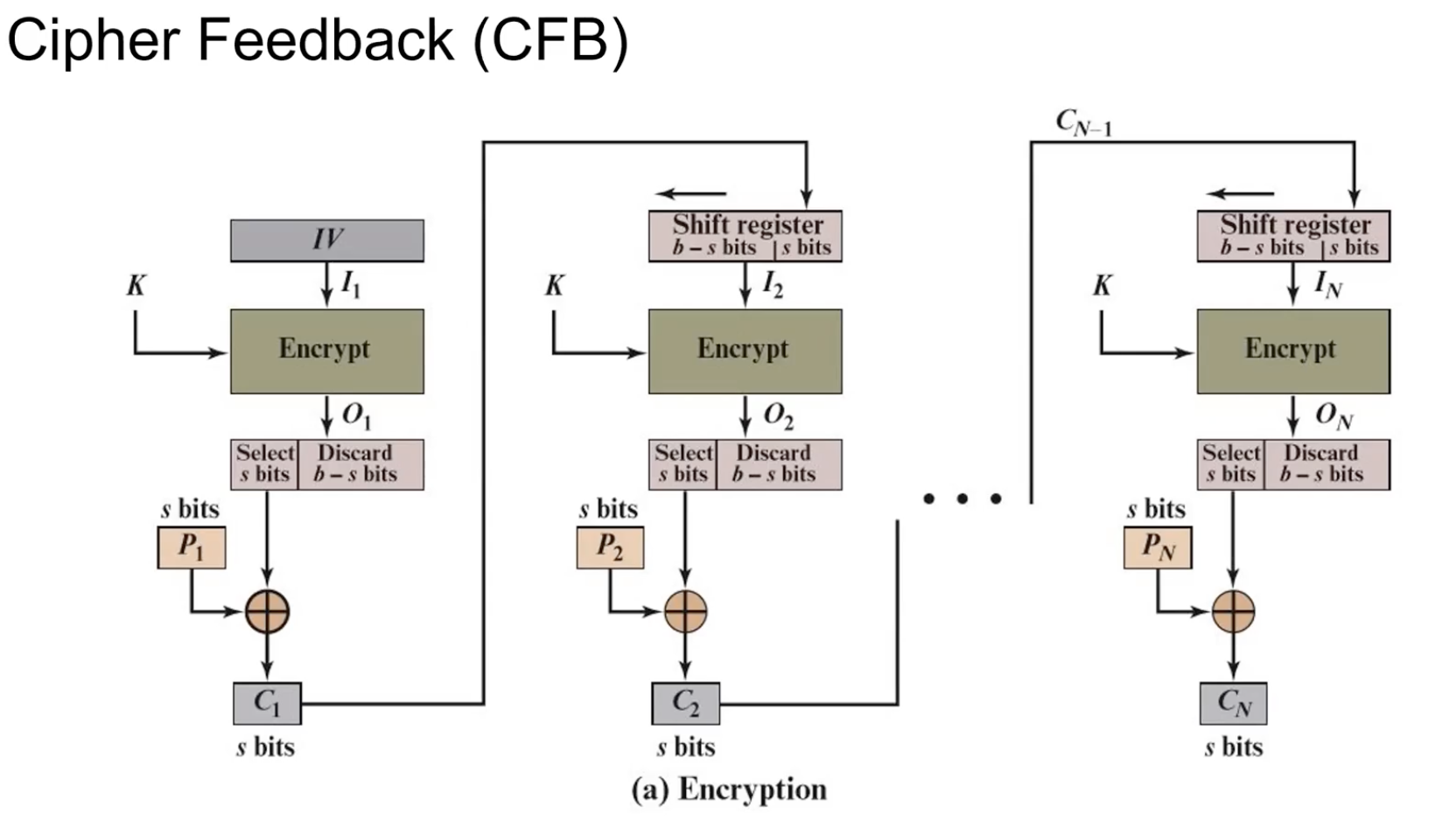
패딩 필요 없는 경우Cipher Feedback (CFB)
임의의 길이에 대해서 처리하는 운영모드. (Not Only 128bit).
첫 번째 보면 IV와 K를 사용해 IV를 암호화 한다. 그렇게 나온 결과 중 Plain text의 bit크기와 동일한 크기만큼만 사용하게 끔 Select, Discard를 통해 수정한다. 그렇기에 이제는 평문이 128bit단위로 들어오지 않아도 상관없다.
bit 별로 처리가 가능해서 패딩이 필요가 없음.
IV가 계속 같다면 똑같은 Plain text에 대해서 동일한 Chiper text가 나오니까 CFB에서는 이전 Chiper text 전체(size s)를 가져와 기존 IV뒤에 s만큼의 기존 Chiper text를 붙이고 IV를 Shift하여 새로운 IV를 만든다.
Decryption 과정에서는 병렬처리가 가능하다. 여기서는 이제 Decryption블럭이 없고 Encrypt블럭을 사용해 Decryption이 진행된다.
Error Propagation(오류 전파)
IV에 이전 Chiper text크기만큼 들어가 shift 연산이 이루어지고 해당 IV를 통해 Encryption이 진행되기에 전체값이 모두 영향을 받음.
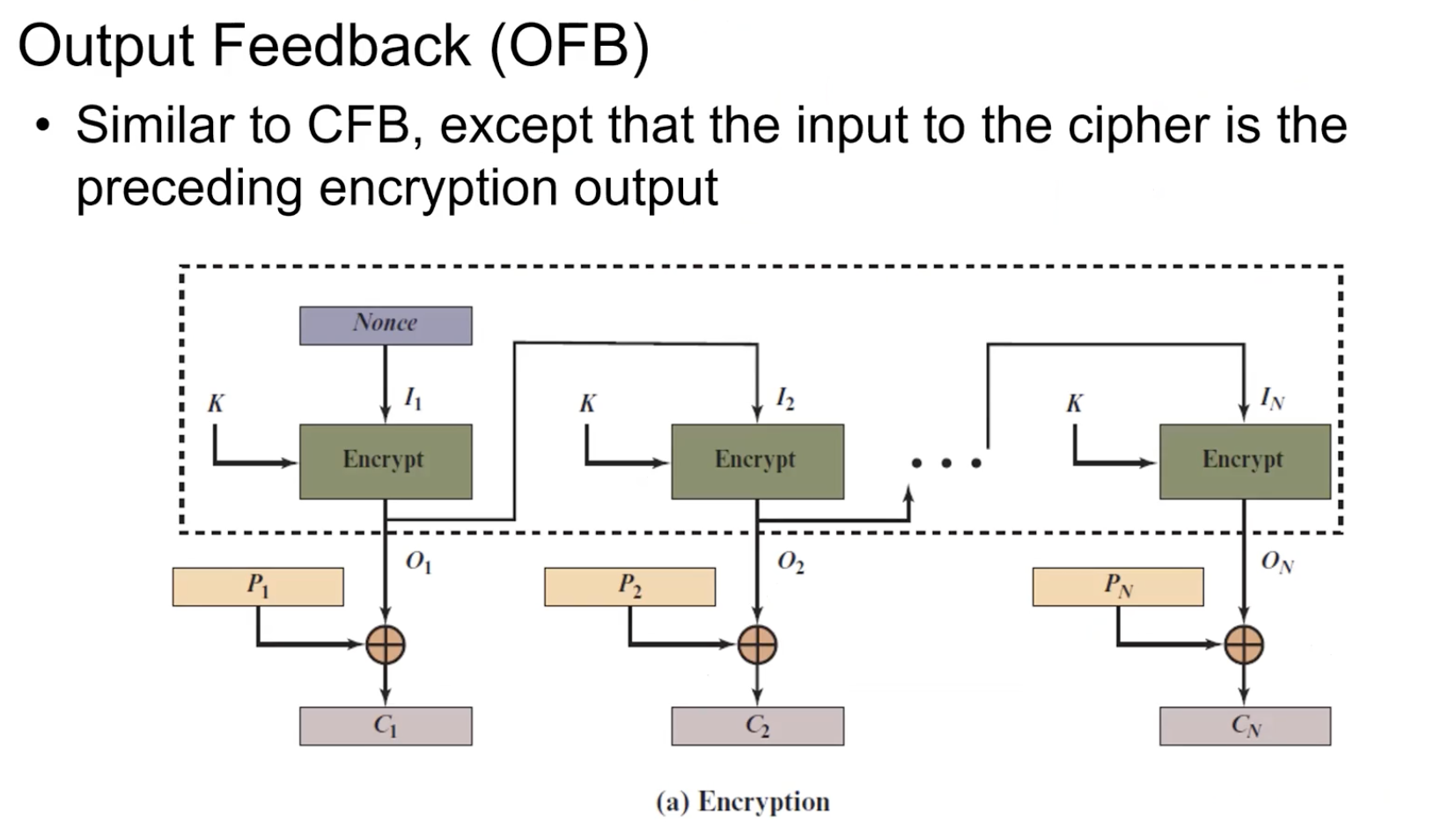
Output Feedback (OFB)
IV가 계속 달라지니까 Plain text가 같더라도 암호문은 계속 달라진다.
장점: 전처리 가능. Output을 평문과 상관없이 언제든지 다 만들어 둘 수 있다.
오류전파 문제는 발생하지 않는다. Output의 값은 Cipher text와 독립적이기에
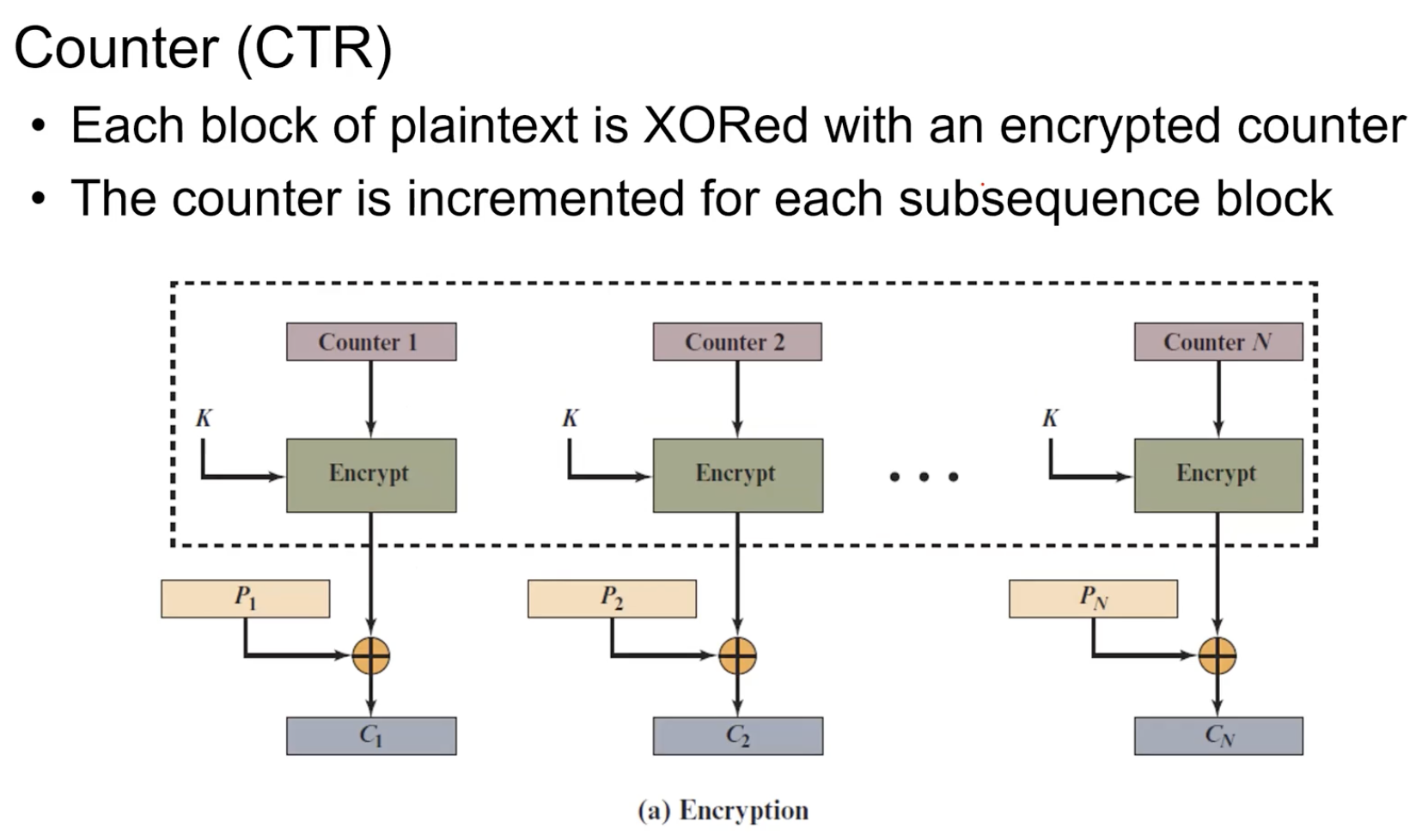
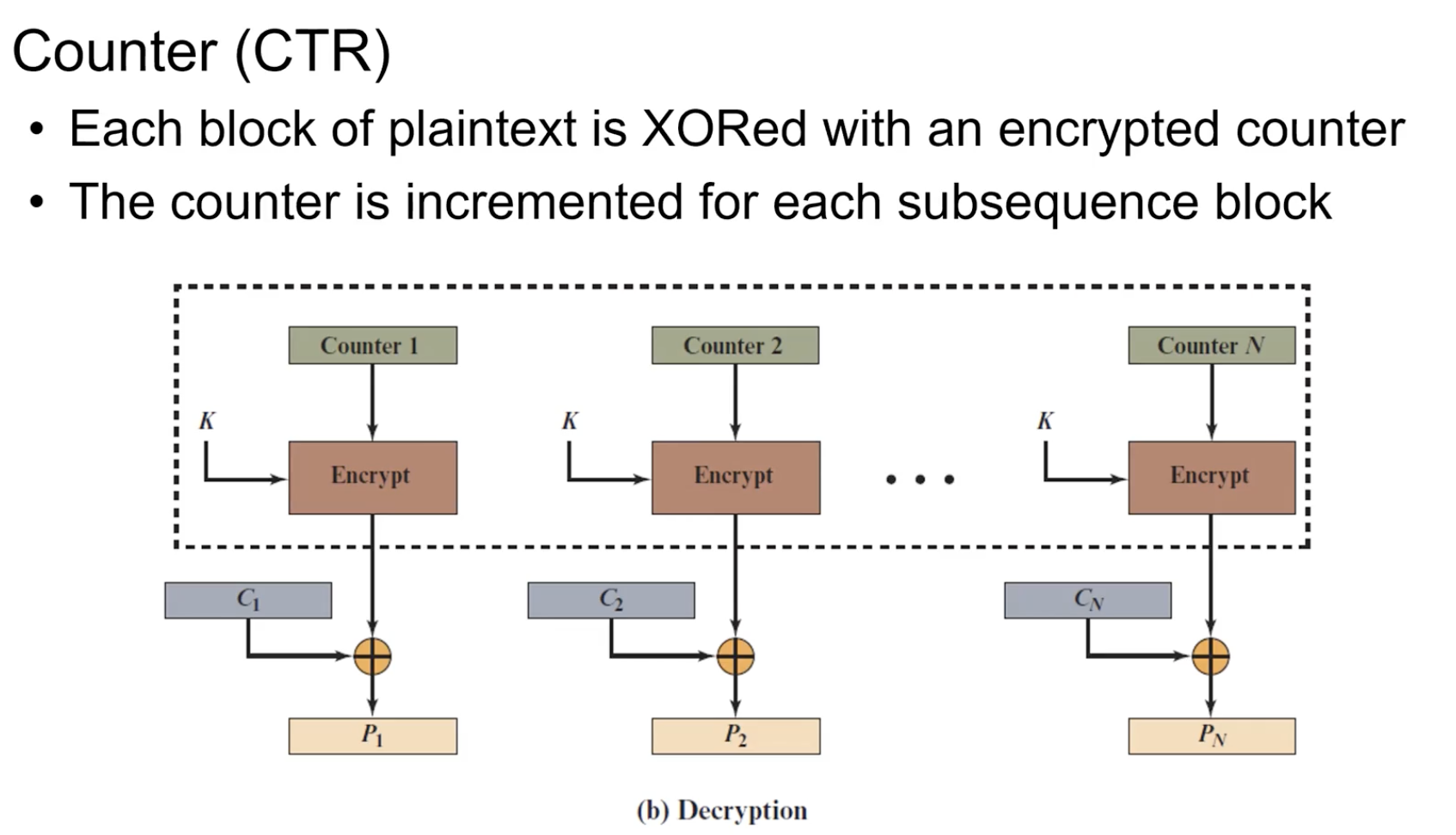
CTR(Counter)
IV를 앞에 있는 것보다 1 증가시켜서 계속 입력으로 사용하는 것.
전처리 가능. output도 다 다름. 128bit 아니여도 됨. Cipher text 문제가 발생해도 오류가 전파되는 일도 없다.
Encrypt만 사용해서 Decryption.
Authenticated Encryption
Chiper text만 가지고도 전체 암호문에 대한 무결성을 체크할 수 있는 Encryption모드가 필요해서 만든 개념.
Authenticated Encryption with Associated Data(AEAD):
Associated Data: 암호화하지는 않을 거지만 무결성은 보장시켜주려고 하는 데이터(무결성을 검증할 때 활용됨).
기존 운영모드는 기밀성만 체크했지만 이제는 무결성도 체크하자.
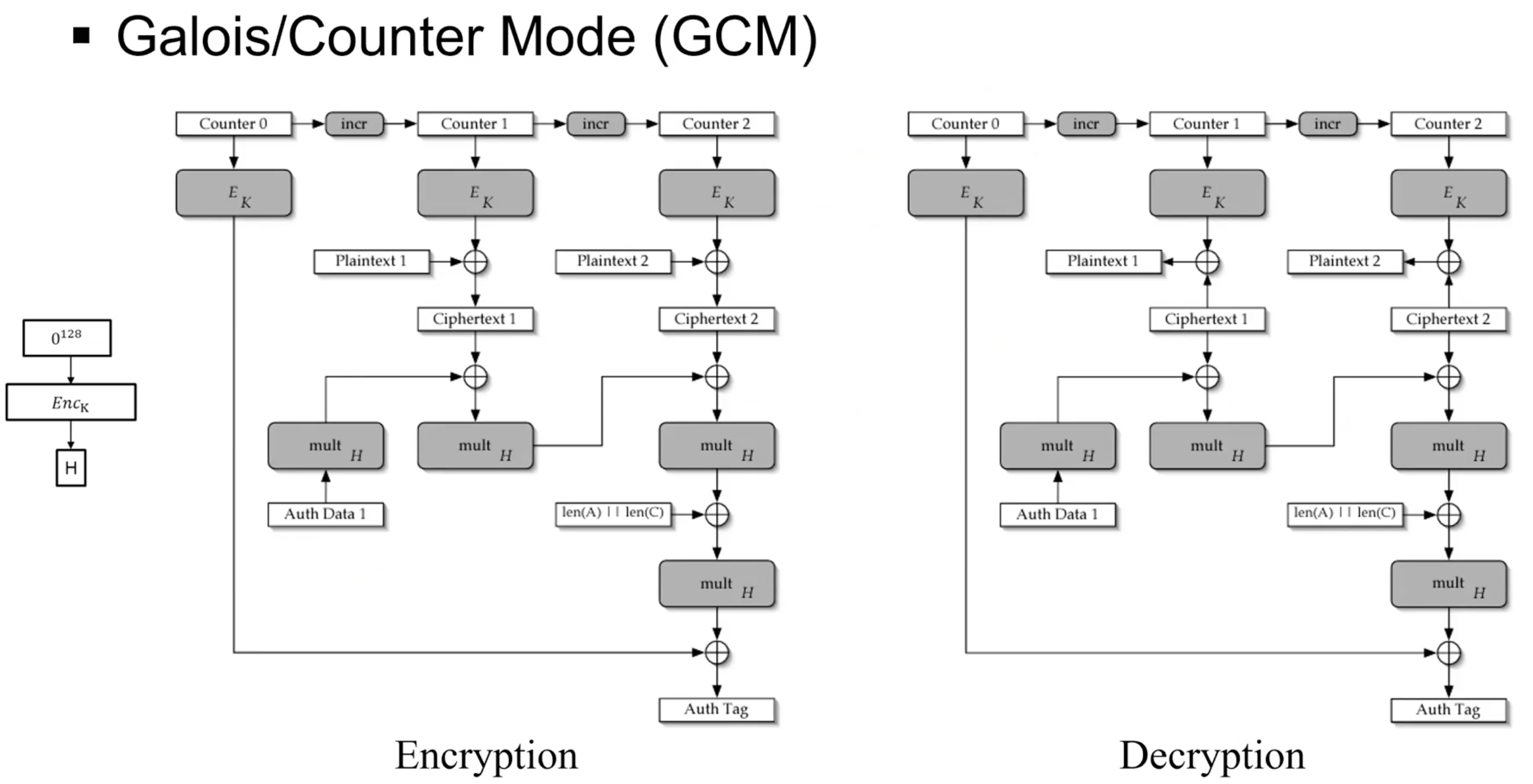
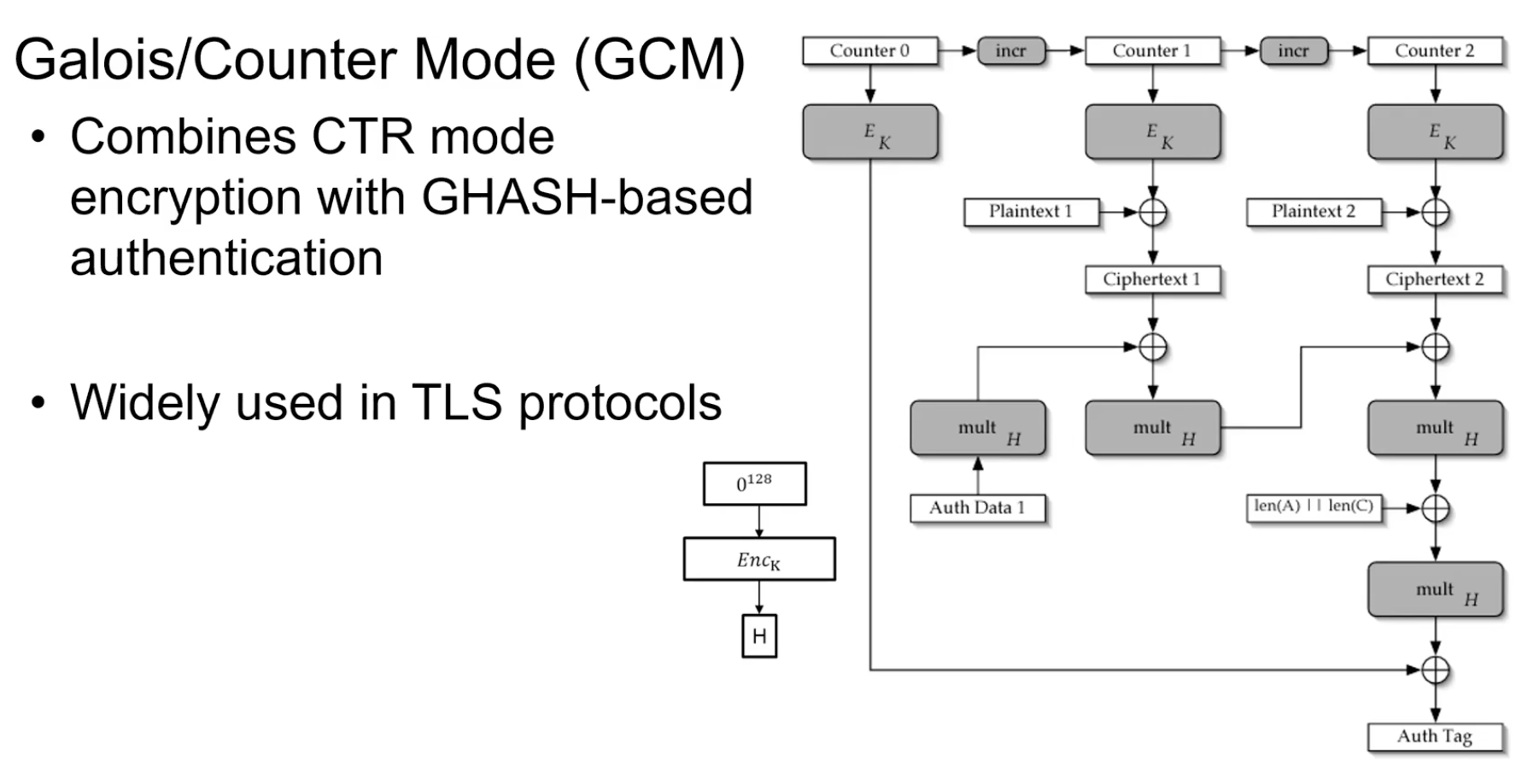
Galois/Counter Mode (GCM)
무결성 체크는 GF에서의 연산, 데이터를 암호화할 때는 Counter Mode 사용.
DES에서는 사용 불가능.
위에는 데이터를 암호화 하기 위해 Counter mode, 아래는 무결성 체크를 위한 Galois Message Authentication Code(GMAC)
gcm은 API호출을 통해 실행될 떄 IV의 매개변수로 넘겨주는데 보통 IV는 96bit로 설정되어 있음.
근데 이게 128bit가 되려면 32bit가 붙어야 됨.
즉 Counter은 앞 IV + 1 이니까 기존 96bit는 동일하고 나머지 32bit의 값이 계속 1씩 증가하는 형식이다.
Ex) 앞이 96 || 0^31 1 이면 뒤는 96 || 0^30 10 이다. -> 0 32개 + 1(1), 0 31개 + 10(2)
Ciphter text의 무결성 증거물 만들기.
Auth Data = Associated Data
H = Encryption의 입력으로 전체 0을 넣었을 때 나오는 Output
len(A) || len(C) = Associated Data의 길이 + Cipher text의 길이
Chipher text2가 128bit가 아니라면 패딩을 통해 맞춰야 됨.
결과적으로 Auth Tag에 Associated Data의 길이와 Cipher text길이의 정보를 넣는다.
첫 입력(X1): Associated Data
X2: Chiper text
병렬적으로 연산이 가능하다. 체인 때문에 앞 연산을 알아야 뒤 연산을 가능할 거 같지만 Galois Field에서의 곱셉 덧셈 연산으로 병렬적으로 연산이 가능하다는 것을 증명 가능함.