머신러닝 프로세스 과정
- 데이터 수집
- 데이터 정리
- test 데이터셋 - train 데이터셋
3-1. train 데이터셋을 활용하여 모델을 학습 - 학습된 모델을 test 데이터셋을 활용하여 성능을 측정
- 모델 배포
📌 머신러닝의 기본 개념
과거 : 사람이 직접 알고리즘을 코딩하거나 패턴을 만들어 결과를 얻음.
AI/머신러닝 : 데이터와 결과를 기반으로 스스로 패턴 학습하고 이를 이용해서 예측
⭐️Linear Regression
"직선을 그려 예측한다."
y = wx
출처:https://ko.wikipedia.org/wiki/%EC%84%A0%ED%98%95_%ED%9A%8C%EA%B7%80
y = wx에서 w(가중치)의 값을 정하는 것이 가장 중요하다. w 값에 따라 다양한 예측값이 나오게 되고, 모델의 정확도에 있어 굉장히 중요하다.
w(가중치)가 최적인지 어떻게 알 수 있을까?
✅ Loss Function ( Cost Function )
⭐️Loss Function(MSE)
Loss Function = (실제값 - 예측값)^2 / N
출처:https://vitalflux.com/mean-square-error-r-squared-which-one-to-use/
예측값과 실제 값의 차이를 error, cost, Residual Error 등으로 표기한다.
🔥 MSE(Mean Squared Error)
이러한 에러들의 차이를 Squared(제곱) 하고 N으로 나눈 값들을 평균제곱오차라고 한다
Loss Function을 어떻게 최적화 할 수 있을까?
✅ Gradient Descent Algorithm
⭐️ Gradient Descent Algorithm
W - ⍺(학습률)W'
출처: https://vitalflux.com/gradient-descent-explained-simply-with-examples/
우리는 최적의 W(가중치)를 구하는 것이 목표이기에 Loss Function(손실함수)의 값이 0에 가까워야 한다.
🔥 Gradient Descent Algorithm
W := W - ⍺(학습률)W'
🚨 ⍺(학습률)의 크기를 너무 크게 설정하게 된다면 Cost가 가장 낮아지는 순간을 넘어가 다시 Cost가 증가하는 값들을 갖게 되기에, 너무 크지 않는 학습률을 설정하여 진행하여야 한다.
📌 머신러닝 기술 원리
지도학습 (Supervised Learning)
- 정답을 알려주면서 진행하는 학습
- 데이터와 레이블(정답)이 함께 제공
- Label = 정답, 실제값 , 타깃, y
- 예측된 값 = 예측값, 분류값, y hat
비지도학습 (Un-Supervised Learning)
- 레이블(정답)이 없이 진행되는 학습
- 데이터 자체에서 패턴을 찾아내야 할 때 사용
지도학습 (Supervised Learning)
vs 비지도학습 (Un-Supervised Learning)
지도학습의 예시 출처:https://blogs.nvidia.com/blog/2018/08/02/supervised-unsupervised-learning/
비지도학습 예시
출처:https://blogs.nvidia.com/blog/2018/08/02/supervised-unsupervised-learning/
지도학습 모델 종류
우리가 사용하는 데이터는 이산적인(Discrete) 값을 갖는 데이터이거나 연속적인(Continuous) 값을 갖는 데이터 입니다. 어떤 데이터가 이산적인 값을 갖는다고 하는 것은 값이 연속적으로 분포하지 않는다는 것이고, 그 외의 경우는 연속적인 값을 갖는다.
분류모델 (Classification)
- 레이블의 값들이 이산적으로 나눠질 수 있는 문제에 사용
ex) 주차게이트에서 번호판 인식, 얼굴 인식, 음성 인식
예측모델 (Regression, 회귀모델)
- 레이블의 값들이 연속적인 문제에 사용
ex) 어떤 사람의 키와 몸무게를 데이터로 얻어 그 사람의 허리 둘레를 예측
과적합 (Overfitting) vs 과소적합 (Underfitting)
출처: https://vitalflux.com/overfitting-underfitting-concepts-interview-questions/
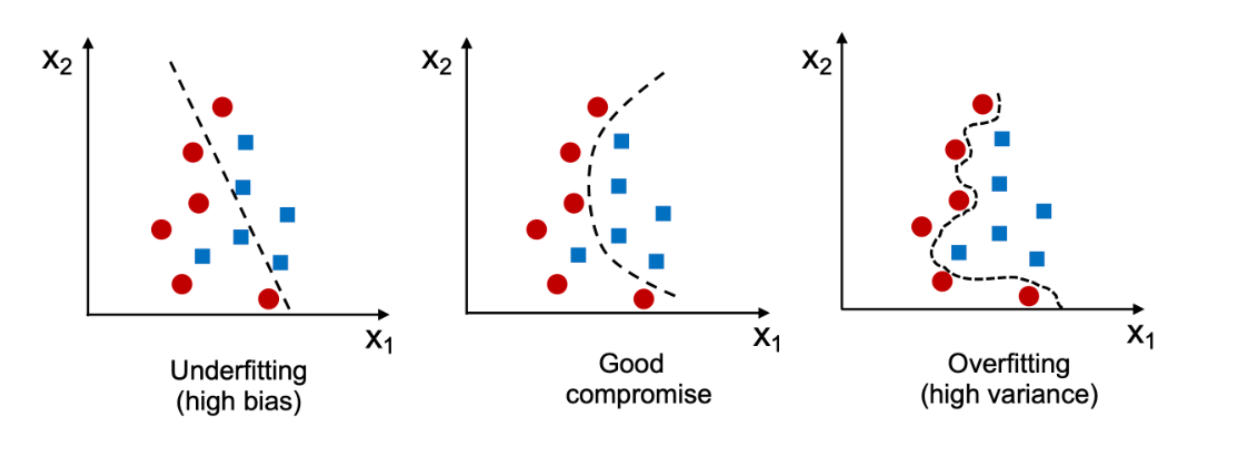
Overfitting은 학습 데이터에 대해 과하게 학습된 상황이다. 따라서, 학습 데이터 이외의 Test data와 같은 다른 데이터에 대해선 모델이 잘 작동하지 못한다. 학습 데이터가 부족하거나, 데이터의 특성에 비해 모델이 복잡한 경우 발생한다. 또한, Training의 loss는 계속 떨어지고, Test의 loss는 감소하다가 다시 증가한다.
Underfitting은 이미 있는 Train set도 학습을 하지 못한 상태를 의미한다. Overfitting과 반대되는 상태이다.
⭐️ Test Accuracy가 증가하다가 감소하면 학습 데이터가 부족한 경우로 볼 수 있다.
⭐️ Train Accuracy가 100%에 가깝지만 Test Accuracy가 상당히 낮은 경우가 있다. 학습 데이터가 편향되어 있지 않은지를 확인해야한다.
🔥 Overfitting 발생
- training dataset의 크기가 매우 큰 경우 (데이터셋에 tarin dataset밖에 없을 경우)
- 학습 데이터에 적합한 Model Capacity를 사용하지않고 큰 Model Capacity를 사용하였을 때
✅ Overfitting 해결법
- Model Capacity 낮추기: 모델이 학습 데이터에 비해 과하게 복잡하지 않도록, hidden layer 크기를 줄이거나 layer 개수를 줄이는 등 모델을 간단하게 만듬.
- Dropout: 학습을 할 때 일부 뉴런을 끄고 학습
- L1/L2 정규화
- 학습 데이터 늘리기
🔥 Underfitting 발생
- 학습 반복 횟수가 너무 적음
- train dataset의 크기가 매우 작음
