spark 3.x 버전은 JAVA 11 버전을 필요로 한다
1.설치
아래의 링크로 가서 원하는 버전을 골라서 설치하면 된다
나는 3버전 아무거나면 돼서 그냥 latest 로 설치했다
https://spark.apache.org/downloads.html

버전을 고른다음에 3번에 다운로드 스파크를 누르면 http 주소를 확인할 수 있다

# 다운로드
wget https://dlcdn.apache.org/spark/spark-3.4.1/spark-3.4.1-bin-hadoop3.tgz
# 압축해제
tar zxvf spark-3.4.1-bin-hadoop3.tgz
# pyspark 설치
brew install pyspark2.경로설정
vi ~/.zshrcexport SPARK_HOME= 본인 경로
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
#pyspark 환경변수, 아래부분을 넣어줘야 주피터로 실행된다
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS='notebook'source ~/.zshrc3.실행
Scala
spark-shell
Pyspark
pysaprk실행시에 자동으로 주피터가 켜진다
4.예제
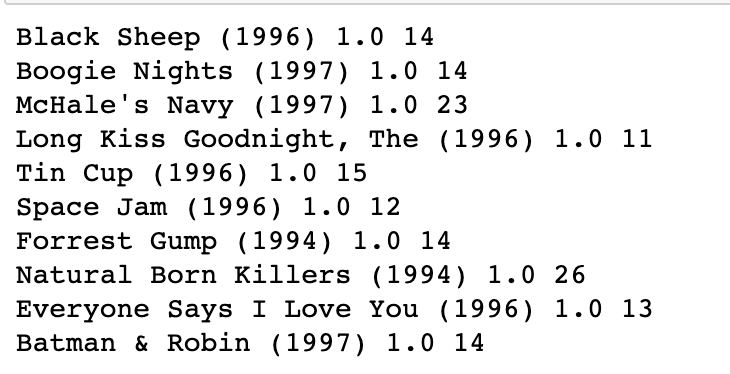
유데미 강의에서 준 샘플 코드에 문제로 내준 부분을 추가해서 실행시켜봤다
counts = movieDataset.groupBy("movieID", "rating").count()
badMovies = counts.filter("count>10").orderBy('rating').take(10)
for badMovie in badMovies:
print (movieNames[badMovie[0]], badMovie[1], badMovie[2])1점짜리 평점을 10개 이상 받은 영화를 랜덤으로 10개 뽑아낸 결과값은 아래와 같다