
1.8 HashSet
HashSet은 Set인터페이스를 구현한 가장 대표적인 컬렉션이며, Set인터페이스의 특징대로 HashSet은 중복된 요소를 저장하지 않는다.
ArrayList와 같이 List인터페이스를 구현한 컬렉션과 달리 HashSet은 저장순서를 유지하지 않으므로 저장순서를 유지하고자 한다면 LinkedHashSet을 사용해야한다.
<표 11-15, HashSet의 메서드>
| 생성자 또는 메서드 | 설명 |
|---|---|
| HashSet() | HashSet 객체를 생성한다. |
| HashSet(Collection c) | 주어진 컬렉션을 포함하는 HashSet 객체를 생성한다. |
| HashSet(int initialCapacity) | 주어진 값을 초기용량으로 하는 HashSet 객체를 생성한다. |
| HashSet(int initialCapacity, float loadFactor) | 초기용량과 load factor를 지정하는 생성자. |
| boolean add(Object o) | 새로운 객체를 저장한다. |
| boolean addAll(Collection c) | 주어진 컬렉션에 저장된 모든 객체들을 추가한다.(합집합) |
| void clear() | 저장된 모든 객체를 삭제한다. |
| Object clone() | HashSet을 복제해서 반환한다. (얕은 복사) |
| boolean contains(Object o) | 지정된 객체를 포함하고 있는지 알려준다. |
| boolean containsAll(Collection c) | 주어진 컬렉션에 저장된 모든 객체들을 포함하고 있는지 알려준다. |
| boolean isEmpty() | Iterator를 반환한다. |
| boolean remove(Object o) | 지정된 객체를 HashSet에서 삭제한다. (성공하면 ture, 실패하면 false) |
| boolean removeAll(Collection c) | 주어진 컬렉션에 저장된 모든 객체와 동일한 것들을 HashSet에서 모두 삭제한다. (차집합) |
| boolean retainAll(Collection c) | 주어진 컬렉션에 저장된 객체와 동일한 것만 남기고 삭제한다.(교집합) |
| int size() | 저장된 객체의 개수를 반환한다. |
| Object[] toArray | 저장된 객체들을 객체배열의 형태로 반환한다. |
| Object[] toArray(Object[] a) | 저장된 객체들을 주어진 객체배열(a)에 담는다. |
사용예시)
import java.util.HashSet;
import java.util.Set;
public class HashSetEx1 {
public static void main(String[] args) {
Object[] objArr = {"1", new Integer(1),"2","2","3","3","4","4","4"};
Set set = new HashSet();
for(int i=0; i<objArr.length;i++){
set.add(objArr[i]); // HashSet에 objArr의 요소들을 저장한다.
}
// HashSet에 저장된 요소들을 출력한다.
System.out.println(set);
}
}
/* 실행결과
[1, 1, 2, 3, 4]
*/예시+) 1~50 사이의 숫자 중에서 25개를 골라서 '5X5'크기의 빙고판을 만드는 예제
import java.util.*;
public class Bingo {
public static void main(String[] args) {
Set set = new HashSet();
//Set set = new LinkedHashSet();
int[][] board = new int[5][5];
for (int i = 0; set.size() < 25; i++) {
set.add((int) (Math.random() * 50) + 1 + "");
}
Iterator it = set.iterator();
for (int i = 0; i < board.length; i++) {
for (int j = 0; j < board[i].length; j++) {
board[i][j] = Integer.parseInt((String) it.next());
System.out.print((board[i][j] < 10 ? " " : " ") + board[i][j]);
}
System.out.println();
}
}
}
/* 실행결과
23 45 24 46 25
48 28 50 10 33
34 35 13 37 16
38 39 17 3 6
8 9 41 42 21
*/next()는 반환값이 Object타입이므로 형변환해서 원래의 타입으로 되돌려 놓아야 한다.
HashSet은 저장된 순서를 보장하지 않고 자체적인 저장방식에 따라 순서가 결정되기 때문에, 몇번 실행해보면 같은 숫자가 비슷한 위치에 나온다는 사실을 발견할 수 있다.
1.9 TreeSet
TreeSet은 이진 검색 트리(binary search tree)라는 자료구조의 형태로 데이터를 저장하는 컬렉션 클래스이다.
이진 검색 트리는 정렬, 검색, 범위검색(range search)에 높은 성능을 보이는 자료구조이며 TreeSet은 이진 검색 트리의 성능을 향상시킨 '레드-블랙 트리(Red Black tree)'로 구현되어 있다.
- Set 인터페이스를 구현했으므로 중복된 데이터의 저장을 허용하지 않으며 정렬된 위치에 저장하므로 저장순서를 유지하지도 않는다.
이진 검색 트리(binary search tree)는
- 모든 노드는 최대 두 개의 자식노드를 가질 수 있다.
- 왼쪽 자식노드의 값은 부모노드의 값보다 작고 오른쪽 자식노드의 값은 부모노드의 값보다 커야한다.
- 노드의 추가 삭제에 시간이 걸린다.(순차적으로 저장하지 않으므로)
- 검색(범위검색)과 정렬에 유리하다.
- 중복된 값을 저장하지 못한다.<표 11-16, TreeSet의 생성자와 메서드>
| 생성자 또는 메서드 | 설명 |
|---|---|
| TreeSet() | 기본 생성자 |
| TreeSet(Collection c) | 주어진 컬렉션을 저장하는 TreeSet을 생성 |
| TreeSet(Comparator comp) | 주어진 정렬조건으로 정렬하는 TreeSet을 생성 |
| TreeSet(SortedSet c) | 주어진 SortedSet을 구현한 컬렉션을 저장하는 TreeSet을 생성 |
| boolean add(Object o) boolean addAll(Collection c) | 지정된 객체(o) 또는 Collection(c)의 객체들을 Colelction에 추가 |
| Object ceiling(Objcet o) | 지정된 객체와 같은 객체를 반환. 없으면 큰 값을 가진 객체 중 제일 가까운 값의 객체를 반환. 없으면 null |
| void clear() | 저장된 모든 객체를 삭제한다. |
| Object clone() | TreeSet을 복제하여 반환한다. |
| Comparator comparator() | TreeSet의 정렬기준(Comparator)를 반환한다. |
| boolean contains(Object o) boolean containsAll(Collection c) | 지정된 객체(o) 또는 Collection의 객체들이 포함되어 있는지 확인한다. |
| NavigableSet descendingSet() | TreeSet에 저장된 요소들을 역순으로 정렬해서 반환 |
| Object first() | 정렬된 순서에서 첫 번째 객체를 반환한다. |
| Object floor(Object o) | 지정된 객체와 같은 객체를 반환. 없으면 작은 값을 가진 객체 중 제일 가까운 값의 객체를 반환. 없으면 null |
| SortedSet headSet(Object toElememt) | 지정된 객체보다 작은 값의 객체들을 반환한다. |
| NavigableSet headSet(Object toElement, boolean inclusive) | 지정된 객체보다 작은 값의 객체들을 반환, inclusive가 true이면, 같은 값의 객체도 포함 |
| Object higher(Object o) | 지정된 객체보다 큰 값을 가진 객체 중 제일 가까운 값의 객체를 반환. 없으면 null |
| boolean isEmpty() | TreeSet이 비어있는지 확인한다. |
| Iterator iterator() | TreeSet의 Iterator를 반환한다. |
| Object last() | 정렬된 순서에서 마지막 객체를 반환한다. |
| Object lower(Object o) | 지정된 객체보다 작은 값을 가진 객체 중 제일 가까운 값의 객체를 반환. 없으면 null |
| Object pollFirst() | TreeSet의 첫번째 요소(제일 작은 값의 객체)를 반환. |
| Object pollLast() | TreeSet의 마지막번째 요소(제일 큰 값의 객체)를 반환. |
| boolean remove(Object o) | 지정된 객체를 삭제한다. |
| boolean retainAll(Colelction c) | 주어진 컬렉션과 공통된 요소만을 남기고 삭제한다.(교집합) |
| int size() | 저장된 객체의 개수를 반환한다. |
| Spliterator spliterator() | TreeSet의 spliterator를 반환 |
| SortedSet subSet(Object fromElement, Object toElement) | 범위 검색(fromElement와 toElement 사이)의 결과를 반환한다.(끝 범위인 toElement는 범위에 포함되지 않음) |
| NavigableSet<E> subSet (E fromElement, boolean fromInclusive, E toElement, boolean toInclusive) | 범위검색(fromElement와 toElement사이)의 결과를 반환한다.(fromInclusize가 true면 시작값이 포함되고, toInclusive가 true면 끝값이 포함된다.) |
| SortedSet tailSet(Object fromElement) | 지정된 객체보다 큰 값의 객체들을 반환한다. |
| Object[] toArray() | 저장된 객체를 객체배열로 반환한다. |
| Object[] toArray(Object[] a) | 저장된 객체를 주어진 객체배열에 저장하여 반환한다. |
좀 많기도 하고 가독성도 떨어지지만... 적어두는 편이 낫겠다.(내 손목이 누군가에겐 도움이 됐으면 하는 바램이랄까)
로또번호 생성 예제)
import java.util.Set;
import java.util.TreeSet;
public class TreeSetLotto {
public static void main(String[] args) {
Set set = new TreeSet();
for (int i = 0; set.size() < 6; i++) {
int num = (int) (Math.random() * 45) + 1;
set.add(num); // set.add(new Integer(num));
}
System.out.println(set);
}
}
/* 실행결과
[8, 16, 18, 23, 26, 32]
*/TreeSet은 저장할 때 이미 정렬하기 때문에 읽어올 때 따로 정렬할 필요가 없다
1.10 HashMap과 Hashtable(얘는 생략)
HashMap은 Map을 구현했으므로 앞에서 살펴본 Map의 특징, 키(key)와 값(value)을 묶어서 하나의 데이터(entry)로 저장한다는 특징을 갖는다. 그리고 해싱(hashing)을 사용하기 때문에 많은 양의 데이터를 검색하는데 있어서 뛰어난 성능을 보인다.
HashMap은 키와 값을 각각 Object타입으로 저장한다. 즉, (Object, Object)의 형태로 저장하기 때문에 어떠한 객체도 저장할 수 있지만 키는 주로 String을 대문자 또는 소문자로 통일해서 사용하곤 한다.
-> 알고리즘을 풀 때는 Integer를 주로 사용하기도 한다.
키(key) - 컬렉션 내의 키(key) 중에서 유일해야 한다.
값(value) - 키(key)와 달리 데이터의 중복을 허용한다.
<표 11-18, HashMap의 생성자와 메서드>
| 생성자/메서드 | 설명 |
|---|---|
| HashMap() | HashMap객체를 생성 |
| HashMap(int initialCapacity) | 지정된 값을 초기용량으로 하는 HashMap객체를 생성 |
| HashMap(int initialCapacity, float loadFactor) | 지정된 초기용량과 load factor의 HashMap객체를 생성 |
| HashMap(Map m) | 지정된 Map의 모든 요소를 포함하는 HashMap을 생성 |
| void clear() | HashMap에 저장된 모든 객체를 제거 |
| Object clone() | 현재 HashMap을 복제해서 반환 |
| boolean containsKey(Object key) | HashMap에 지정된 키(key)가 포함되어있는지 알려준다.(포함되어 있으면 true) |
| boolean containsValue(Object value) | HashMap에 지정된 값(value)가 포함되어있는지 알려준다.(포함되어 있으면 true) |
| Set entrySet() | HashMap에 저장된 키와 값을 엔트리(키와 값의 결합)의 형태로 Set에 저장해서 반환 |
| Object get(Object key) | 지정된 키(key)의 값(객체)을 반환. 못찾으면 null 반환 |
| Object getOrDefault(Object key, Object defaultValue) | 지정된 키(key)의 값(객체)을 반환한다. 키를 못찾으면, 기본값(defaultValue)로 지정된 객체를 반환 |
| boolean isEmpty() | HashMap이 비어있는지 알려준다. |
| Set keySet() | HashMap에 저장된 모든 키가 저장된 Set을 반환 |
| Object put(Object key, Object value) | 지정된 키와 값을 HashMap에 저장 |
| void putAll(Map m) | Map에 저장된 모든 요소를 HashMap에 저장 |
| Object remove(Object key) | HashMap에서 지정된 키로 저장된 값(객체)을 제거 |
| Object replace(Object key, Object value) | 지정된 키의 값을 지정된 객체(value)로 대체 |
| boolean replace(Object key, Object oldValue, Object newValue) | 지정된 키와 객체(oldValue)가 모두 일치하는 경우에만 새로운 객체(newValue)로 대체 |
| int size() | HashMap에 저장된 요소의 개수를 반환 |
| Collection values() | HashMap에 저장된 모든 값을 컬렉션의 형태로 반환 |
간단한 id, password 예제)
import java.util.HashMap;
import java.util.Scanner;
public class HashMapEx1 {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("myId", "1234");
map.put("asdf", "1111");
map.put("asdf", "1234");
Scanner s = new Scanner(System.in); // 화면으로부터 라인단위로 입력받는다.
while (true) {
System.out.println("id와 password를 입력해주세요.");
System.out.print("id :");
String id = s.nextLine().trim();
System.out.print("password :");
String password = s.nextLine().trim();
System.out.println();
if (!map.containsKey(id)) {
System.out.println("입력하신 id는 존재하지 않습니다. 다시 입력해주세요.");
continue;
}
if (!(map.get(id)).equals(password)) {
System.out.println("비밀번호가 일치하지 않습니다. 다시 입력해주세요");
} else {
System.out.println("id와 비밀번호가 일치합니다.");
break;
}
}
}
}
/* 실행결과
id와 password를 입력해주세요.
id :asdf
password :1111
비밀번호가 일치하지 않습니다. 다시 입력해주세요
id와 password를 입력해주세요.
id :asdf
password :1234
id와 비밀번호가 일치합니다.
Process finished with exit code 0
*/HashMap을 생성하고 데이터를 저장하는 부분에서 3개의 데이터 쌍을 저장했지만 실제로는 2개만 저장된다. 그 이유는 중복된 키가 있기 때문이다.
Map은 값의 중복을 허용하지만 키는 중복을 허용하지 않기 때문에 저장하려는 두 데이터 중에서 어느 쪽을 키로 할 것인지를 잘 결정해야한다.
해싱과 해시함수
해싱 이란 해시함수(hash function)를 이용해서 데이터를 해시테이블(hash table)에 저장하고 검색하는 기법을 말한다. 해시함수는 데이터가 저장되어 있는 곳을 알려 주기 때문에 다량의 데이터 중에서도 원하는 데이터를 빠르게 찾을 수 있다.
-> HashSet, HashMap, Hashtable 등
해싱에서 사용하는 자료구조는 배열 과 링크드 리스트 의 조합으로 되어 있다.
저장할 데이터의 키를 해시함수에 넣으면 배열의 한 요소를 얻게 되고, 다시 그 곳에 연결되어 있는 링크드 리스트에 저장하게 된다.
원하는 데이터를 검색하는 과정은 다음과 같다.
1. 검색하고자 하는 값의 키로 해시함수를 호출한다.
2. 해시함수의 계산결과(해시코드)로 해당 값이 저장되어 있는 링크드 리스트를 찾는다.
3. 링크드 리스트에서 검색한 키와 일치하는 데이터를 찾는다.이미 배운 바와 같이 링크드 리스트는 검색에 불리한 자료구조이기 때문에 링크드 리스트의 크기가 커질수록 검색속도가 떨어지게 된다.
반면에 배열은 배열의 크기가 커져도, 원하는 요소가 몇 번째에 있는 지만 알면 아래의 공식에 의해서 빠르게 원하는 값을 찾을 수 있다.
배열의 인덱스가 n인 요소의 주소 = 배열의 시작주소 + type의 size * n
1.11 TreeMap
TreeMap은 이름에서 알 수 있듯이 이진검색트리의 형태로 키와 값의 쌍으로 이루어진 데이터를 저장한다. 그래서 검색과 정렬에 적합한 컬렉션 클래스이다.
-
검색에 관한한 대부분의 경우에서 HashMap이 TreeMap보다 더 뛰어나다.
-
다만 범위검색이나 정렬이 필요한 경우에는 TreeMap 을 사용하자.
<표 11-19, TreeMap의 생성자와 메서드>
| 메서드 | 설명 |
|---|---|
| TreeMap() | TreeMap객체를 생성 |
| TreeMap(Comparator c) | 지정된 Comparator를 기준으로 정렬하는 TreeMap객체를 생성 |
| TreeMap(Map m) | 주어진 Map에 저장된 모든 요소를 포함하는 TreeMap을 생성 |
| TreeMap(SortedMap m) | 주어진 SortedMap에 저장된 모든 요소를 포함하는 TreeMap을 생성 |
| Map.Entry ceilingEntry(Object key) | 지정된 key와 일치하거나 큰 것중 제일 작은 것의 키와 값의 쌍 (Map.Entry) 을 반환. 없으면 null을 반환 |
| Object ceilingKey(Object key) | 지정된 key와 일치하거나 큰 것중 제일 작은 것의 키를 반환. 없으면 null을 반환 |
| void clear() | TreeMap에 저장된 모든 객체를 제거 |
| Object clone() | 현재 TreeMap을 복제해서 반환 |
| Comparator comparator() | TreeMap의 정렬기준이 되는 Comparator를 반환 Comparator가 지정되지 않았다면 null을 반환 |
| boolean containsKey(Object key) | TreeMap에 지정된 키(key)가 포함되어있는지 알려줌 (포함되어 있으면 true) |
| boolean containsValue(Object value) | TreeMap에 지정된 값(value)가 포함되어있는지 알려줌 (포함되어 있으면 true) |
| NavigableSet descendingKeySet() | TreeMap에 저장된 키를 역순으로 정렬해서 NavigableSet에 담아서 반환 |
| Set entrySet() | TreeMap에 저장된 키와 값을 엔트리 (키와 값의 결합) 의 형태로 Set에 저장해서 반환 |
| Map.Entry firstEntry() | TreeMap에 저장된 첫번째 (가장 작은) 키와 값의 쌍 (Map.Entry) 을 반환 |
| Object firstKey() | TreeMap에 저장된 첫번째 (가장 작은) 키를 반환 |
| Map.Entry floorEntry(Object key) | 지정된 key와 일치하거나 작은 것 중에서 제일 큰 키의 쌍 (Map.Entry) 을 반환. 없으면 null을 반환 |
| Object floorKey(Object key) | 지정된 key와 일치하거나 작은 것 중에서 제일 큰 키를 반환. 없으면 null을 반환 |
| Object get(Object key) | 지정된 키(key)의 값(객체)을 반환 |
| SortedMap headMap(Object toKey) | TreeMap에 저장된 첫번째 요소부터 지정된 범위에 속한 모든 요소가 담긴 SortedMap을 반환 (toKey는 미포함) |
| NavagableMap headMap(Object toKey, boolean inclusive) | TreeMap에 저장된 첫번째 요소부터 지정된 범위에 속한 모든 요소가 담긴 SortedMap을 반환. inclusive의 값이 true면 toKey도 포함 |
| Map.Entry higherEntry(Object key) | 지정된 key보다 큰 키 중에서 제일 작은 키의 쌍 (Map.Entry) 을 반환. 없으면 null을 반환 |
| Object higherKey(Object key) | 지정된 key보다 큰 키 중에서 제일 작은 키의 쌍 (Map.Entry) 을 반환. 없으면 null을 반환 |
| boolean isEmpty() | TreeMap이 비어있는지 알려준다. |
| Set keySet() | TreeMap에 저장된 모든 키가 저장된 Set을 반환 |
| Map.Entry lastEntry() | TreeMap에 저장된 마지막 키 (가장 큰 키) 의 쌍을 반환 |
| Object lastKey() | TreeMap에 저장된 마지막 키 (가장 큰 키) 를 반환 |
| Map.Entry lowerEntry(Object key) | 지정된 key보다 작은 키 중에서 제일 큰 키의 쌍 (Map.Entry) 을 반환. 없으면 null을 반환 |
| Object lowerKey(Object key) | 지정된 key보다 작은 키 중에서 제일 큰 키의 쌍 (Map.Entry) 을 반환. 없으면 null을 반환 |
| NavigableSet navigableKeySet() | TreeMap의 모든 키가 담긴 NavigableSet을 반환 |
| Map.Entry pollFirstEntry() | TreeMap의 제일 작은 키를 제거하면서 반환 |
| Map.Entry pollLastEntry() | TreeMap의 제일 큰 키를 제거하면서 반환 |
| Object put(Object key, Object value) | 지정된 키와 값을 TreeMap에 저장 |
| void putAll(Map map) | Map에 저장된 모든 요소를 TreeMap에 저장 |
| Object remove(Object key) | TreeMap에서 지정된 키로 저장된 값(객체)를 제거 |
| Object replace(Object k, Object v) | 기존의 키(k)의 값을 지정된 값(v)으로 변경 |
| boolean replace(Object key, Object oldValue, Object newValue) | 기존의 키(k)의 값(newValue)으로 변경. 단, 기존의 값과 지정된 값(oldValue)가 일치해야함 |
| int size() | TreeMap에 저장된 요소의 개수를 반환 |
| NavigableMap subMap(Object fromKey, boolean fromInclusive, Object toKey, boolean toInclusive) | 지정된 두개의 키 사이에 있는 모든 요소들이 담긴 NavigableMap을 반환, fromInclusive가 true면 범위에 fromKey포함. toInclusive가 true면 범위에 toKey포함 |
| SortedMap subMap(Object fromKey, Object toKey) | 지정된 두 개의 키 사이에 있는 모든 요소들이 담긴 SortedMap을 반환 (toKey는 포함되지 않는다.) |
| SortedMap tailMap(Object fromKey) | 지정된 키부터 마지막 요소의 범위에 속한 요소가 담긴 SortedMap을 반환 |
| NavigableMap tailMap(Object fromKey, boolean inclusive) | 지정된 키부터 마지막 요소의 범위에 속한 요소가 담긴 NavigableMap을 반환. inclusive가 true면 fromKey포함 |
| Collection values() | TreeMap에 저장된 모든 값을 컬렉션의 형태로 반환 |
이렇게 많은 메서드가 있어도 실제로 자주 쓰이는 메서드는 몇 개 없겠지만 이런게 있구나 하고 한 번씩 읽어보는 것도 좋을 것 같다.
import java.util.*;
public class TreeMapEx1 {
public static void main(String[] args) {
String[] data = {"A", "K", "A", "K", "D", "K", "A", "K", "K", "K", "Z", "D"};
TreeMap map = new TreeMap();
for (int i = 0; i < data.length; i++) {
if (map.containsKey(data[i])) {
Integer value = (Integer) map.get(data[i]);
map.put(data[i], new Integer(value.intValue() + 1));
} else {
map.put(data[i], new Integer(1));
}
}
Iterator it = map.entrySet().iterator();
System.out.println("= 기본정렬 =");
while (it.hasNext()) {
Map.Entry entry = (Map.Entry) it.next();
int value = ((Integer) entry.getValue()).intValue();
System.out.println(entry.getKey() + " : " + printBar('#', value) + " " + value);
}
System.out.println();
// map을 ArrayList로 변환한 다음에 Collections.sort()로 정렬
Set set = map.entrySet();
List list = new ArrayList(set); // ArrayList(Collection c)
// static void sort(List list, Comparator c)
Collections.sort(list, new ValueComparator());
it = list.iterator();
System.out.println("= 값의 크기가 큰 순서로 정렬 =");
while (it.hasNext()) {
Map.Entry entry = (Map.Entry) it.next();
int value = ((Integer) entry.getValue()).intValue();
System.out.println(entry.getKey() + " : " + printBar('#', value) + " " + value);
}
}
static class ValueComparator implements Comparator {
public int compare(Object o1, Object o2) {
if (o1 instanceof Map.Entry && o2 instanceof Map.Entry) {
Map.Entry e1 = (Map.Entry) o1;
Map.Entry e2 = (Map.Entry) o2;
int v1 = ((Integer) e1.getValue()).intValue();
int v2 = ((Integer) e2.getValue()).intValue();
return v2 - v1;
}
return -1;
}
}
public static String printBar(char ch, int value) {
char[] bar = new char[value];
for (int i = 0; i < bar.length; i++) {
bar[i] = ch;
}
return new String(bar);
}
}
/* 실행결과
= 기본정렬 =
A : ### 3
D : ## 2
K : ###### 6
Z : # 1
= 값의 크기가 큰 순서로 정렬 =
K : ###### 6
A : ### 3
D : ## 2
Z : # 1
Process finished with exit code 0
*/문자열 배열에 담긴 문자열을 하나씩 읽어서 TreeMap에 키로 저장하고 값으로 1을 저장한다. TreeMap에 같은 문자열이 키로 저장되어 있는지 containsKey()로 확인하여 이미 저장되어 있는 문자열이면 값을 1 증가시킨다.
TreeMap을 사용했기 때문에 HashMap과는 달리 키가 오름차순으로 정렬되어 있는 것을 알 수 있다. 키가 String인스턴스이기 때문에 String클래스에 정의된 정렬 기준에 의해서 정렬된 것이다.
그리고 Comparator를 구현한 클래스와 Collections.sort(List list, Comparator c)를 이용해서 값에 대한 내림차순으로 정렬하는 방법을 보여 준다.
1.12 Properties
Properties는 HashMap의 구버전인 hashtable을 상속받아 구현한 것으로, Hashtable은 키와 값을 (Object, Object)의 형태로 저장하는데 비해 Properties는 (String, String)의 형태로 저장하는 보다 단순화된 컬렉션클래스이다.
주로 애플리케이션의 환경설정과 관련된 속성(property)을 저장하는데 사용되며 데이터를 파일로부터 읽고 쓰는 편리한 기능을 제공한다. 그래서 간단한 입출력은 Properties를 활용하면 몇 줄의 코드로 쉽게 해결될 수 있다.
<표 11-20, Properties의 생성자와 메서드>
| 메서드 | 설명 |
|---|---|
| Properties() | Properties객체를 생성한다. |
| Properties(Properties defaults) | 지정된 Properties에 저장된 목록을 가진 Properties 객체를 생성한다. |
| String getProperty(String key) | 지정된 키(key)의 값(value)을 반환한다. |
| String getProperty(String key, String defaultValue) | 지정된 키(key)의 값(value)을 반환한다. 키를 못찾으면 defaultValue를 반환한다. |
| void list(PrintStream out) | 지정된 PrintStream에 저장된 목록을 출력한다. |
| void list(PrintWriter out) | 지정된 PrintWriter에 저장된 목록을 출력한다. |
| void load(InputStream inStream) | 지정된 InputStream으로부터 목록을 읽어서 저장한다. |
| void load(Reader reader) | 지정된 Reader으로부터 목록을 읽어서 저장한다. |
| void loadFromXML(InputStream in) | 지정된 InputStream으로부터 XML문서를 읽어서, XML문서에 저장된 목록을 읽어다 담는다. (load & store) |
| Enumeration propertyNames() | 목록의 모든 키(key)가 담긴 Enumeration을 반환한다. |
| void save(OutputStream out, String header) | deprecated되었으므로 store()를 사용하자. |
| Object setProperty(String key, String value) | 지정된 키와 값을 저장한다. 이미 존재하는 키(key)면 새로운 값(value)로 바뀐다. |
| void store(OutputStream out, String comments) | 저장된 목록을 지정된 Writer에 출력(저장)한다. comments는 목록에 대한 설명(주석)으로 저장된다. |
| void storeToXML(OutputStream os, String comment) | 저장된 목록을 지정된 출력스트림에 XML문서로 출력(저장)한다. comment는 목록에 대한 설명(주석)으로 저장된다. |
| void storeToXML(OutputStream os, String comment, String encoding) | 저장된 목록을 지정된 출력스트림에 해당 인코딩의 XML문서로 출력(저장)한다. comment는 목록에 대한 설명(주석)으로 저장된다. |
| Set stringPropertyNames() | Properties에 저장되어 있는 모든 키(key)를 Set에 담아서 반환한다. |
간단한 예제) Properties의 기본적인 메서드를 이용해서 저장하고 읽어오는 출력하는 방법을 보여주는
import java.util.Enumeration;
import java.util.Properties;
public class PropertiesEx1 {
public static void main(String[] args) {
Properties prop = new Properties();
// prop에 키와 값(key, value)을 저장한다.
prop.setProperty("timeout", "30");
prop.setProperty("language", "kr");
prop.setProperty("size", "10");
prop.setProperty("capacity", "10");
// prop에 저장된 요소들을 Enumeration을 이용해서 출력한다.
Enumeration e = prop.propertyNames();
while (e.hasMoreElements()) {
String element = (String) e.nextElement();
System.out.println(element + "=" + prop.getProperty(element));
}
System.out.println();
prop.setProperty("size", "20"); // size의 값을 20으로 변경한다.
System.out.println("size=" + prop.getProperty("size"));
System.out.println("capacity=" + prop.getProperty("capacity", "20"));
System.out.println("loadfactor=" + prop.getProperty("loadfactor", "0.75"));
System.out.println(prop); // prop에 저장된 요소들을 출력한다.
prop.list(System.out); // prop에 저장된 요소들을 화면(System.out)에 출력한다.
}
}
/* 실행결과
capacity=10
size=10
timeout=30
language=kr
size=20
capacity=10
loadfactor=0.75
{size=20, language=kr, timeout=30, capacity=10}
-- listing properties --
size=20
language=kr
timeout=30
capacity=10
Process finished with exit code 0
*/데이터를 저장하는데 사용되는 setProperty()는 단순히 Hashtable의 put메서드를 호출할 뿐이다. 그리고 setProperty()는 기존에 같은 키로 저장된 값이 있는 경우 그 값을 Object타입으로 반환하며, 그렇지 않을 때는 null을 반환한다.
getProperty()는 Properties에 저장된 값을 읽어오는 일을 하는데, 만일 읽어오려는 키가 존재하지 않으면 지정된 기본값(defaultValue)을 반환한다.
String getProperty(String key)
String getProperty(String key, String defaultValue)또, Properties는 Hashtable을 상속받아 구현한 것이라 Map의 특성상 저장순서를 유지하지 않기 때문에 예제의 결과에 출력된 순서가 저장순서와는 무관하다는 것을 확인하자.
System.out은 화면과 연결된 표준출력으로 System클래스에 정의된 PrintStream타입의 static변수이다.
--> '15장 입출력(I/O)'에서..
1.13 Collections
Arrays가 배열과 관련된 메서드를 제공하는 것처럼, Collections는 컬렉션과 관련된 메서드를 제공한다.
fill(), copy(), sort(), binarySearch() 등의 메서드는 두 클래스에 모두 포함되어 있으며 같은 기능을 한다.
컬렉션의 동기화
멀티 쓰레드(multi-thread) 프로그래밍에서는 하나의 객체를 여러 쓰레드가 동시에 접근할 수 있기 때문에 데이터의 일관성(consistency)을 유지하기 위해서는 공유되는 객체에 동기화(synchronization) 가 필요하다.
Collections클래스에는 다음과 같은 동기화 메서드를 제공하고 있으므로, 동기화가 필요할 때 해당하는 것을 사용하면 된다.
static Collection synchronizedCollection (Collection c)
static List synchronizedList (List list)
static Set synchronizedSet (Set s)
static Map synchronizedMap (Map m)
static SortedSet synchronizedSortedSet (SortedSet s)
static SortedMap synchronizedSortedMap (SortedMap m)
// 이 들을 사용하는 방법은 다음과 같이
List syncList = Collections.synchronizedList(new ArrayList(...));- 멀티쓰레딩과 동기화에 대해서는 13장에서 자세히...
변경불가 컬렉션 만들기
컬렉션에 저장된 데이터를 보호하기 위해서 컬렉션을 변경할 수 없게, 즉 읽기전용으로 만들어야할 때가 있다.
주로 멀티 쓰레드 프로그래밍에서 여러 쓰레드가 하나의 컬렉션을 공유하다보면 데이터가 손상될 수 있는데, 이를 방지하려면 아래의 메서드들을 이용하자.
static Collection unmodifableCollection (Collection c)
static List unmodifableList (List list)
static Set unmodifableSet (Set s)
static Map unmodifableMap (Map m)
static NavigableSet unmodifableNavigableSet (NavigableSet s)
static SortedSet unmodifableSortedSet (SortedSet s)
static NavigableMap unmodifableNavigableSet (NavigableMap m)
static SortedMap unmodifableSortedMap (SortedMap m)싱글톤 컬렉션 만들기
단 하나의 객체만을 저장하는 컬렉션을 만들고 싶을 경우가 있다. 이럴 때는 아래의 메서드를~
static List singletonList (Object o)
static Set singleton (Object o) // singletonSet이 아님
static Map singletonMap (Object key, Object value)매개변수로 저장할 요소를 지정하면, 해당 요소를 저장하는 컬렉션을 반환한다. 그리고 변환된 컬렉션은 변경할 수 없다.
한 종류의 객체만 저장하는 컬렉션 만들기
컬렉션에 모든 종류의 객체를 저장할 수 있다는 것은 장점이기도하고 단점이기도 하다.
대부분의 경우 한 종류의 객체를 저장하며, 컬렉션에 지정된 종류의 객체만 저장할 수 있도록 제한하고 싶을 때 아래의 메서드를 사용한다.
static Collection checkedCollection (Collection c, Class type)
static List checkedList (List list, Class type)
static Set checkedSet (Set s, Class type)
static Map checkedMap (Map m, Class keyType, Class valueType)
static Queue checkedQueue (Queue queue, Class type)
static NavigableSet checkedNavigableSet (NavigableSet s, Class type)
static SortedSet checkedSortedSet (SortedSet s, Class type)
static NavigableMap checkedNavigableMap (NavigableMap m, Class keyType, Class valueType)
static SortedMap checkedSortedMap (SortedMap m, Class keyType, Class valueType)
// 사용방법은 다음과 같이 두 번째 매개변수에 저장할 객체의 클래스에 지정하면 된다.
List list = new ArrayList();
List checkedList = checkedList(list, String.class); // String만 저장가능
checkedList.add("abc"); // OK.
checkedList.add(new Integer(3)); // 에러. ClassCastException 발생-> 컬렉션에 저장할 요소의 타입을 제한하는 것은 다음 장에서 배울 지네릭스(generics)로 간단히 처리할 수 있는데도 이런 메서드들을 제공하는 이유는 호환성 때문이다.
1.14 컬렉션 클래스 정리 & 요약
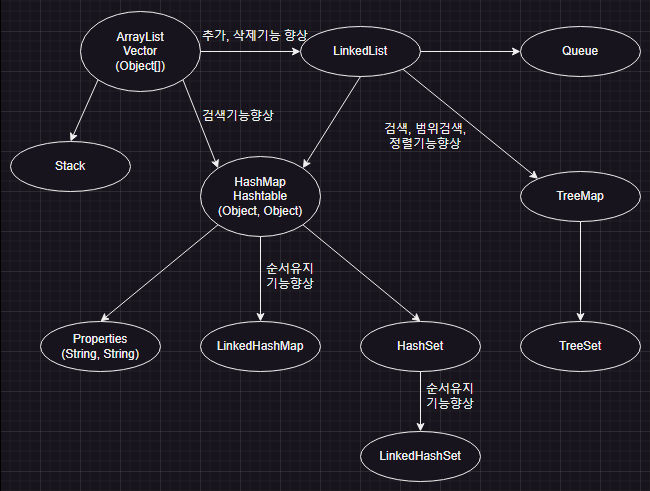
<표 11-21, 컬렉션 클래스의 특징>
| 컬렉션 | 특징 |
|---|---|
| ArrayList | 배열기반, 데이터의 추가와 삭제에 불리, 순차적인 추가삭제는 제일 빠름, 임의의 요소에 대한 접근성(accessibility)이 뛰어남 |
| LinkedList | 연결기반, 데이터의 추가와 삭제에 유리, 임의의 요소에 대한 접근성이 좋지 않다. |
| HashMap | 배열과 연결이 결합된 형태, 추가, 삭제, 검색, 접근성이 모두 뛰어남. 검색에는 최고성능을 보인다. |
| TreeMap | 연결기반, 정렬과 검색(특히 범위검색)에 적합. 검색성능은 HashMap보다 떨어짐. |
| Stack | Vector를 상속받아 구현 |
| Queue | LinkedList가 Queue인터페이스를 구현 |
| Properties | Hashtable을 상속받아 구현 |
| HashSet | HashMap을 이용해서 구현 |
| TreeSet | TreeMap을 이용해서 구현 |
| LinkedHashMap LinkedHashSet | HashMap과 HashSet에 저장순서유지기능을 추가 |
