- 테스트용 USER/ TABLE 생성
tbsql sys/tibero
create tablespace TEST01 datafile '/home/tibero/tibero_data/tibero/data/test01.dtf' size 100m autoextend on next 10m maxsize 10G
create user eun1 identified by 'tibero' default tablespace TEST01;
grant resource, connect to eun1;create table eun1.T1
(c1 number,
c2 number,
c3 varchar2(10)
)
nologging;
- DATA 50만건 insert
BEGIN
FOR i IN 1..500000 LOOP
INSERT INTO eun1.T1 (c1, c2, c3)
VALUES (
i, -- c1: 반복문 번호
TRUNC(DBMS_RANDOM.VALUE(1, 10000000)), -- c2: 1 ~ 10,000,000 사이의 랜덤 숫자
DBMS_RANDOM.STRING('X', 10) -- c3: 랜덤한 10자리 문자
);
-- 1000건마다 커밋하여 성능 최적화
IF MOD(i, 1000) = 0 THEN
COMMIT;
END IF;
END LOOP;
COMMIT; -- 나머지 데이터 커밋
END;
/
--지피티가 짜줌..
2.1 플랜확인
set autot
select c3 from eun1.T1
where c1=1100
and c2=11003844574;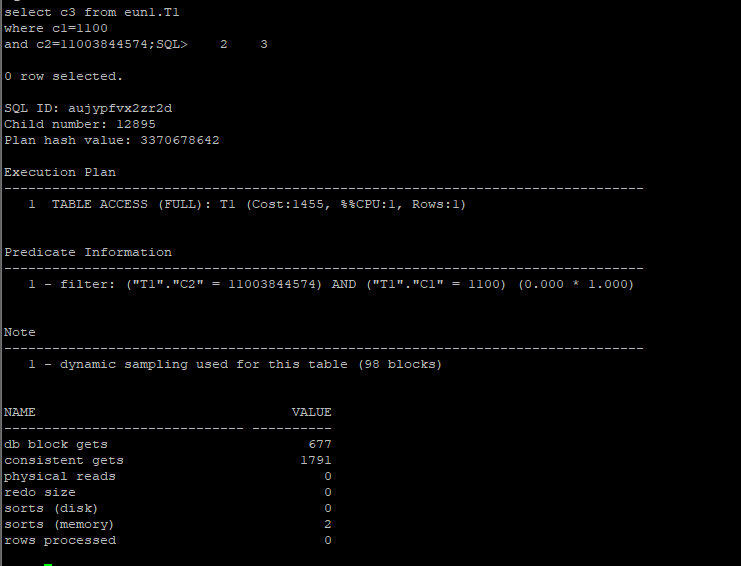
- 인덱스 생성
create index eun1.idx01 on eun1.T1(c1, c2);3.1 플랜 확인
set autot on
select c3 from eun1.T1
where c1=1100
and c2=11003844574;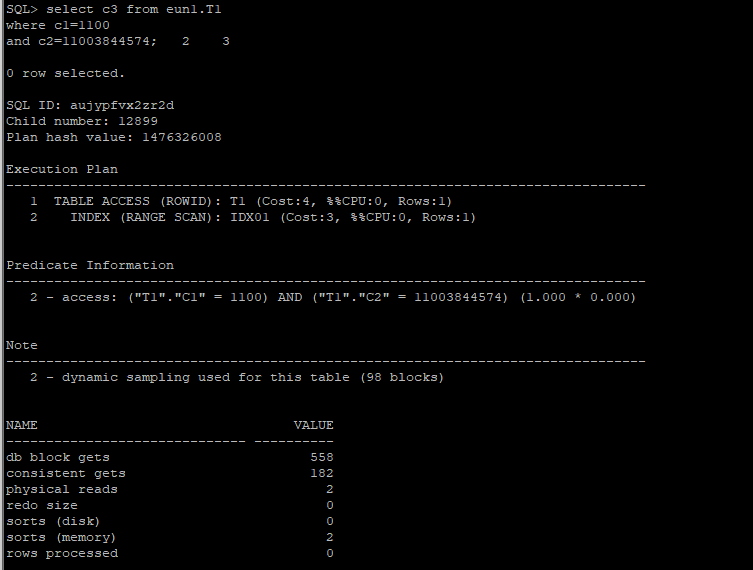
- C3 컬럼의 인덱스 추가
create index eun1.idx02 on eun1.T1(c3);4.1 플랜 확인
select c3 from eun1.T1
where c1=1100
and c2=11003844574;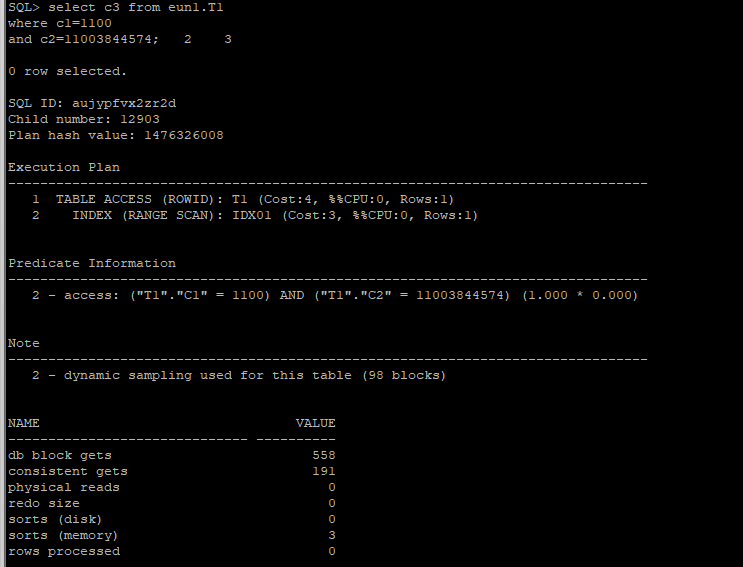
- 실행통계
db block gets : 현재의 블록이 요구된 횟수
consistent gets : consistent mode에서 읽은 논리 블록 수를 누적한 시스템 통계정보
physical reads : 디스크로부터 읽은 데이터 블록의 총 개수
redo size : redo log가 만들어진 크기 (size)
sorts (disk) : disk에서 일어난 sort 수
sorts (memory) : memory에서 일어난 sort 수
rows processed : 연산을 하는 동안 처리한 row 수
