웹 서버
웹 서버는 매일 수 십억개의 웹페이지를 쏟아 낸다. 이 장에서는 WWW의 일꾼인 웹 서버에 대해서 알아본다.
다채로운 웹 서버
웹 서버는 HTTP 요청을 처리하고 응답을 제공한다. 10 줄짜리 작은 웹 서버가 존재하기도 하고 50MB짜리 안전한 상용 엔진같은 서버도 있다. 기능은 달라도 모든 웹 서버는 리소스에 대한 HTTP 요청을 받아 콘텐츠를 클라이언트에게 보내준다.
구현
- HTTP, TCP 처리 구현
TCP 처리는 운영체제와 책임을 나눠 갖는다.
- 웹 리소스 관리
- 웹 서버 관리 기능 제공
웹서버가 하는 일
- 커넥션을 맺는다.
- 요청을 받는다.
- 요청을 처리한다.
- 리소스에 접근한다.
- 응답을 만든다.
- 응답을 보낸다.
- 트랜잭션을 로그로 남긴다.
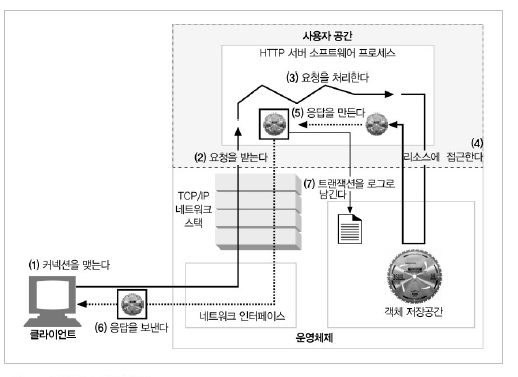
상용 웹 서버는 매우 복잡하지만 공통적으로 위와같은 일을 수행한다.
커넥션 수락
클라이언트가 이미 서버에 지속적 커넥션을 갖고 있다면 해당 커넥션을 사용한다. 그렇지 클라이언트는 새 커넥션을 열 필요가 있다.
클라이언트가 웹 서버에 TCP 커넥션을 요청하면, 웹 서버는 커넥션을 맺고 TCP 커넥션에서 IP 주소를 추출하여 클라이언트를 확인한다. 이때 웹 클라이언트의 IP 주소를 리버스 DNS 를 이용하여 호스트 명으로 바꾸는 작업을 한다. 이를 Hostname lookup 이라고 한다. 이 과정은 트랜잭션을 느리게 만들 수 있다.
웹 서버는 언제든 커넥션을 닫을 수 있다. 클라이언트의 호스트명이 인가되지 않았거나 악의적이라고 알려진 것인 경우 커넥션을 닫는다.
indent를 통해 클라이언트 사용자 알아내기
몇몇 웹서버는 IETF indent 프로토콜을 지원한다. 이 프로토콜은 서버에게 어떤 사용자 이름이 HTTP 커넥션을 초기화했는지 찾아낼 수 있게 해준다.
이 정보는 로깅에 유용하기 때문에, 널리 쓰이는 일반 로그 포맷(Common Log Format)의 두 번째 필드는 각 HTTP 요청의 indent 사용자 이름을 담고 있다.
클라이언트가 indent 프로토콜을 지원한다면, 클라이언트는 indent 결과를 위해 TCP 포트 113번을 listen 한다.
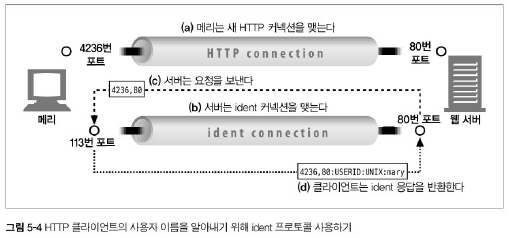
이런 indent는 조직 내부에서는 잘 사용할 수 있지만, 공공 인터넷에서는 여러 이유로 잘 동작하지 않는다.
- 많은 클라이언트 PC가 indentd 신원확인 프로토콜 데몬 SW를 실행하지 않는다.
- indent 프로토콜이 HTTP 트랜잭션을 지연시킬 수 있다.
- 방화벽이 indent 트래픽이 들어오는 것을 막는 경우가 많다.
- indent 프로토콜은 안전하지 않고 조작하기 쉽다.
- indent 프로토콜은 가상 IP주소를 잘 지원하지 않는다.
- 클라이언트 사용자 이름의 노출로 인한 프라이버시 침애의 우려가 있다.
요청 메시지 수신
커넥션에 데이터가 도착하면, 웹 서버는 네트워크 커넥션에서 데이터를 읽어 들이고 파싱하여 요청메시지를 구성한다.
요청 메시지 파싱할 때, 다음과 같은 일을 한다.
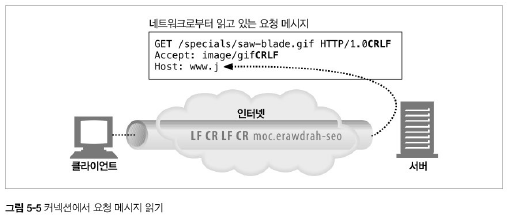
- 요청줄을 파싱하여
요청 메서드,URI,버전 번호를 찾는다. - 메시지 헤더들을 읽는다.
- 헤더의 끝을 의미하는 CRLF로 끝나는 빈 줄을 찾는다.
- 요청 본문이 있다면 읽어 들인다.
웹 서버는 입력 데이터를 네트워크로부터 불규칙적으로 받는다. 파싱해서 이해할 수 있는 수준의 분량을 확보할 때까지 메모리에 임시로 저장해 둘 필요가 있다.
커넥션 입력/출력 처리 아키텍쳐
고성능 웹 서버는 수천 개의 커넥션을 동시에 열 수 있도록 지원한다. 항상 언제 들어올지 모르는 새 요청을 주시하고 있으며, 요청을 처리하는 방식에는 여러가지가 있다.
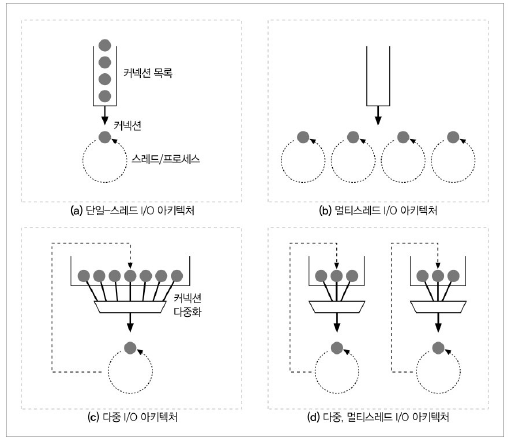
단일 스레드 웹 서버
한 번에 하나의 요청을 처리한다.
구현이 간단하지만, 처리 동중에 다른 커넥션을 모두 무시하여 심각한 성능 문제가 발생한다.
멀티프로세스와 멀티스레드 웹 서버
여러개의 프로세스 혹은 고효율 스레드를 할당한다.
프로세스와 스레드는 서버의 시스템 리소스를 소비하기 때문에 최대 개수에 제한을 둔다.
프로세스/스레드는 미리 만들어 두고 할당하여 사용할 수도 있고, 매 커넥션에 필요할 때마다 만들어 할당할 수도 있다.
다중 I/O 서버
대량의 커넥션을 지원하기 위해 많은 웹 서버가 채택한 아키텍쳐이다.
모든 커넥션은 동시에 그 활동을 감시당한다.
어떤 커넥션이 상태가 바뀌면, 그 커넥션에 대해서 작은 양의 처리가 수행된다. 처리가 완료되면, 커넥션은 다음번 상태 변경을 위해 열린 커넥션 목록으로 돌아간다.
이 말은 어떤 커넥션에 대해 작업을 수행하는 것은 그 커넥션에 실제로 해야 할 일이 있을 때 뿐이라는 것이다.
즉, 프로세스와 스레드가 유휴 상태의 커넥션에 매여 리소스를 낭비하지 않는다.
다중 멀티스레드 웹 서버
몇몇 서버는 여러 개의 CPU를 활용하기 위해 멀티스레딩과 멀티플렉싱을 결합한다. 여러개의 스레드는 각각 열려있는 커넥션을 감시하고 각 커넥션에 대해 조금씩 작업을 수행한다.
요청 처리
요청 처리는 메서드, 리소스, 헤더, 본문을 얻어내어 처리한다.
POST를 비롯한 몇몇 메서드는 본문을 요구한다.
GET은 본문을 금지한다.
그 외 OPTIONS와 같은 메서드는 본문을 허용하되 요구하지는 않는다.
리소스 매핑과 접근
웹 서버는 리소스 서버이다. 미리 HTML이나 JPEG와 같은 콘텐츠를 만들어 두고 제공한다. 웹 서버는 요청의 URI에 대응하는 컨텐츠나 컨텐츠 생성기를 찾아서 그 컨텐츠의 원천을 식별해야한다.
Docroot
매우 단순한 형태로 요청 URI를 웹 서버의 파일 시스템 안에 있는 파일 이름으로 사용하는 방식이다. 웹 서버의 파일 시스템의 특별한 폴더, docroot라는 폴더를 웹 컨텐츠를 위해 예약하여 사용한다.
요청 메시지에서 URI를 해당 문서 루트 뒤에 붙이면 웹 콘텐츠를 제공할 수 있다.
가상 호스팅된 docroot
한 서버에서 두 사이트를 호스팅한다고 했을 때, docroot 내에 joe, mary 폴더를 두어 웹 서버의 설정을 변경해주면 두 개의 사이트가 완전히 분리된 컨텐츠를 갖도록 호스팅할 수 있다.
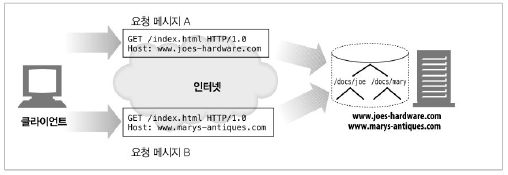
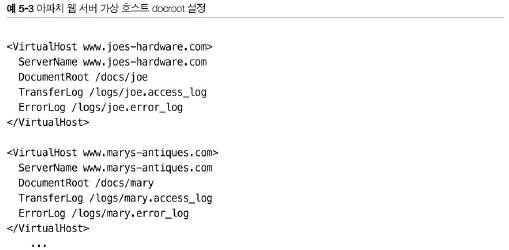
디렉터리 목록
웹 서버에 디렉터리 URL에 대한 요청을 했을 때, 웹 서버는 다음과 같은 응답을 할 수 있다.
- 에러를 반환
- 디렉터리 대신 index 파일 반환
- 디렉터리 탐색 후 디렉터리 구조를 담고 있는 HTML 페이지 반환
대부분은 디렉터리 안에서 index.html 혹은 index.htm 파일을 찾아 반환한다. 이러한 색인 파일이 없다면 웹 서버는 디렉터리 안의 파일 구조와 링크를 담은 HTML 파일을 반환한다.
편리하기는 하지만, 일반적으로 발견할 수 없는 파일도 드러나게 된다는 단점이 존재한다.
동적 컨텐츠
웹 서버는 URI를 동적 리소스에 매핑할 수도 있다. 어떤 리소스가 동적이라면 애플리케이션 서버는 그에 대한 동적 컨텐츠 생성 프로그램이 어디에 있느닞, 어떻게 프로그램을 실행할 수 있는지 알려줄 수 있어야 한다.
웹 초창기에는 CGI라는 서버사이드 애플리케이션 실행을 위한 간단한 인터페이스를 사용했지만, 오늘날의 애플리케이션 서버는 MS 액티브서버 페이지, 자바 서블릿과 같은 기능을 가지고 있다.
접근 제어
웹 서버는 클라이언트의 IP를 보고 접근을 제어할 수 있고, 리소스에 접근하기 위해 비밀번호를 물어볼 수도 있다.
응답 만들기
응답 엔티티
트랜잭션 응답이 본문을 생성한다면, 엔티티를 만들어 응답 메시지와 함께 톨려보낸다.
- Content-Type : 응답 본문의 MIME 타입을 서술
- Content-Length : 응답 본문의 길이를 서술
- 본문 내용
MIME 타입 결정하기
웹 서버에게는 응답 본문의 MIME 타임을 결정해야 하는 책임이 있다.
MIME 타입과 리소스를 연결하는 방법은 여러가지가 존재한다.
- mime.types
- 매직 타이핑
- 유형 명시
- 유형 협상
리다이렉션
웹 서버는 종종 성공 메시지 대신 다른 곳으로 가도록 리다이렉트를 할 수 있다. 응답 상태코드는 3XX로 지칭된다.
다음과 같은 곳에 유용하다.
- 영구히 리소스가 옮겨진 경우
- 임시로 리소스가 옮겨진 경우
- URL 증강
- 부하 균형
- 친밀한 다른 서버가 있을 때
- 디렉터리 이름 정규화
응답 보내기
로깅
트랜잭션이 완료되었을 때 웹 서버는 트랙잭션이 어떻게 수행되었는지에 대한 로그를 기록한다.
