3. Airflow 프로젝트 생성 및 DAG 개발
ML 파이프라인은 하나의 워크플로우로 이루어지며, 데이터 추출, 데이터 유효성 검사, 데이터 전처리, 모델 학습, 모델 평가 및 검증 그리고 예측과 같은 단계를 작업(Task)으로 구현하고 실행할 수 있음
3.1 Apache Airflow
Airflow는 데이터 파이프라인을 구축, 스케일링 관리하는 오픈 소스 플랫폼
DAG를 사용해 작업을 정의하고, 각 작업은 하나 이상의 Task로 구성됨
Task는 노드로 표현되며, 노드는 서로 연결되어 작업 흐름을 나타냄
DAG를 사용하여 데이터 처리에 대한 작업 흐름을 정의하면 Airflow는 작업을 스케줄링하고 자동 실행
MLOps에서는 모델의 학습, 평가, 배포 등의 다양한 작업을 자동화하는 파이프라인을 구성할 때 DAG를 자주 사용함
💡- DAG(Directed Acycilc Graph) Airflow에서 작업 흐름은 DAG로 정의됨. DAG는 방향성이 있고 사이클이 없는 그래프로 Airflow에서 작업 실행 순서를 결정함.
- 작업 순서를 명확히: 체계적인 관리
- 의존성 관리: 어떤 작업이 먼저 완료되어야 다음 작업을 진행할 수 있는지
- 작업(Task) DAG는 하나 이상의 작업(Task)로 구성되며, DAG에서 실행하는 작업 단위를 나타냄.
Airflow Architecture
Airflow의 아키텍처는 크게 세 가지 요소로 구성됨
- 웹 서버(Web Server) Airflow의 웹 서버는 DAG, 작업 및 작업 상태를 표시하는 웹 인터페이스를 제공함 웹 서버에서 사용자가 DAG를 보거나 실행할 수 있는 인터페이스를 제공하며, 실행된 작업의 상태, 로그 등의 정보를 확인할 수 있음
- 스케줄러(Scheduler) Airflow의 스케줄러는 DAG를 기반으로 작업을 스케줄링하고 실행함 스케줄러는 DAG 실행될 때마다 실행할 작업을 정의하며, 작업은 실행지에 따라 다른 방식으로 진행됨
- 실행자(Execultor) Airflow는 DAG에 Task를 정의해 작업을 실행하는데, 이러한 작업 실행 방법을 정의하는 것이 바로 Executor이다.
Airflow는 다양한 플러그인과 연동할 수 있다. 예를 들어 BigQuery, Amazon S3, Spark, Hive, Presto, MySQL 등과 연동할 수 있으며, 사용자 정의 플러그인을 작성하여 다른 서비스와 연결이 가능함
Airflow 장점
- 코드 기반의 작업 정의를 통해 유연성과 재사용성을 높일 수 있음
- Web UI내에서 DAG를 통해 작업 흐름을 시각적으로 파악할 수 있으며, 스케줄링으로 작업 실행이 자동 처리됨
- 다양한 실행자를 지원하여 작업 실행 방식을 선택할 수 있음
- SequentialExecultor: 순차적으로 작업
- LocalExecutor: 로컬에서 작업
- 다양한 플러그인과 연동이 가능하여, 데이터 처리 파이프라인을 구성하는 서비스와 연결 쉬움
- 오픈 소스라서 무료로 사용이 가능하며 커뮤니티 기반으로 개발되어 빠른 업데이트가 가능함
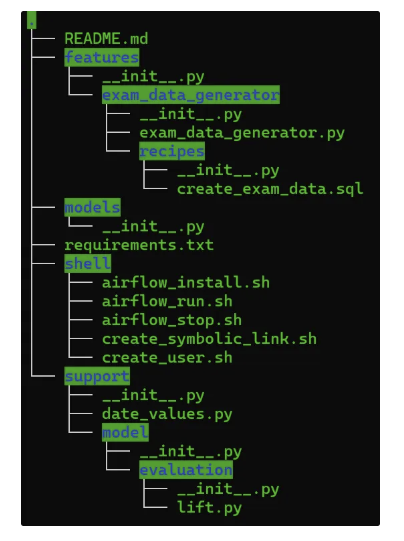
features
- exam_data_generator
- Airflow DAG로 개발되었으며, ML 파이프라인을 개발하기 위해 필요한 데이터를 생성해 주는 실습용 데이터 생성기
- 2023.06.01 ~ 2025.12.31의 실습용 데이터가 적재되어 있음. 해당 기간이 지나면 실습에 필요한 데이터를 생성해야 한다.
- 파일 설명
- examdata_generator.py: Airflow DAG 파일로 ‘DATE_PARAMS’ → ‘실습데이터_생성’ Task로 이루어져 있다.
- recipes > create_exam_data.sql: MariaDB 테이블에 적재할 데이터를 생성하는 SQL이 작성되어 있다.
models
- 책에서 실습하는 ML 모델 파이프라인을 Airflow의 DAG로 개발하는 곳
shell
- Airflow를 설치하고, 서비스를 실행 or 종료하는 등의 작업을 실행하는 셀 스크립트 관리
- airflow_install.sh
- airflow_run.sh
- Airflow의 scheduler, triggerer, webserver 서비스 실행
- 실습을 다시 시작할 때, 쉽게 Airflow 사용할 수 있음
- airflow_stop.sh
- Airflow의 scheduler, triggerer, webserver 서비스 중지
- PC를 끄고 다시 시작하게 되어도 Airflow 서비스를 다시 시작하는 데에 문제 없음
- create_user.sh
- 실습에서 사용하는 MLops 사용자를 간단히 추가
- create_symbolic_link.sh
- ML 파이프라인 프로젝트 내에 개발한 DAG와 공통 모듈을 Airflow에 바로 반영하기 위해 심볼릭 링크 사용
support
- ML 파이프라인을 개발하면서, 공통으로 사용되는 모듈을 개발하고 관리함
- data_values.py 모듈은 Date와 관련된 기능을 사전에 개발해 놓았으며, 실습 과정에서 사용함
requirements.txt
- ML 파이프라인 프로젝트에 필요한 외부 패키지 및 라이브러리의 목록을 포함하는 텍스트 파일
- pip를 사용하여 의존성 패키지를 설치하는 데 사용함
파일 권한 오류
터미널에서는 mlops 폴더 아래에 pipeline 폴더가 있는 것이 확인되었지만 PyCharm 접속 시 pipeline 폴더가 확인되지 않음
- /home/ubuntu 위치에서 /home/mlops에 접근하고자 하여 확인되지 않았다.
- sudo chmod 755로 해결 - 외부에서도 볼 수 있도록 권한 부여
PyCharm 인터프리터 설정 오류
인터프리터 create를 누르면 권한이 없다는 오류가 발생하였다.
아직도 PyCharm이 /home/ubuntu/.pycharm_helpers 경로(옛날 사용자 ubuntu 홈 디렉터리)에 있는 스크립트를 실행하려다 권한 문제가 발생하는 전형적인 상황이었다.
- PyCharm이 자동으로 생성.관리하는 폴더가 이전 경로에 남아 있으므로, 루트 권한으로 삭제했더니 해결되었다.
- sudo rm -rf /home/ubuntu/.pycharm_helpers
- 어차피 PyCharm이 새 Interpreter를 설정할 때 다시 만들어 주기 때문에 삭제해도 됨
- SequentialExecutor는 Airflow의 실행 엔진 중 하나로, 작업을 순차적으로 실행함
- 단일 머신 또는 개발 및 테스트 환경에서 사용하기에 적합하지만, 프로덕션 환경에서는 병렬 처리 or 확장성이 요구될 수도 있음
# Airflow needs a home. ~/airflow is the default, but you can put it
# somewhere else if you prefer (optional)
export AIRFLOW_HOME=~/airflow
# Install Airflow using the constraints file
AIRFLOW_VERSION=2.7.2
PYTHON_VERSION="$(python --version | cut -d " " -f 2 | cut -d "." -f 1-2)"
# For example: 3.10
CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt"
# For example: https://raw.githubusercontent.com/apache/airflow/constraints-2.5.2/constraints-3.7.txt
pip install "apache-airflow==${AIRFLOW_VERSION}" --constraint "${CONSTRAINT_URL}"
# The Standalone command will initialise the database, make a user,
# and start all components for you.
airflow standalone- export AIRFLOW_HOME=~/airflow는 AIRFLOW_HOME 디렉토리를 환경 변수로 설정하며 Apache Airflow의 Home을 지정함
- PYTHON_VERSION에는 현재 사용 중인 Python 버전을 조회하는 shell 명령어를 이용하여 버전을 설정함
- CONSTRAINT_URL은 Apache Airflow에서 조건에 맞는 파일을 다운로드할 수 있는 URL을 설정함
- airflow standalone 명령어를 실행하면, 데이터베이스 초기화, 사용자 생성 및 Airflow 구성 요소의 시작을 수행함
- 명령어 하나로 웹 서버, 스케줄러 등 Airflow에 필요한 모든 구성 요소가 한 번에 시작됨
기타 설정
- Airflow User 생성 추가
- Web UI에서 사용자 추가 or shell > create_user.sh 파일을 실행하여 추가
- Airflow Variables 추가
- 심볼릭 링크를 사용하지 않고 실제 위치를 사용하는 이유는?
- 실제 위치와 심볼릭으로 생성한 위치에서 동일한 파일과 디렉토리를 관리하다 보면, realpath와 같은 명령어를 실행할 때, 문제가 발생함. 도커 빌드 시 디렉터리 확인 절차에서 오류
- 링크를 연결하여 원본 파일을 직접 사용하는 것과 같은 효과를 내는 링크 ⇒ 윈도우의 바로가기와 유사한 개념이다.
프로젝트 패키지 심볼릭 링크 생성
mlops-study-ml-pipeline 프로젝트 내에서 Airflow DAG를 개발하면, Airflow Web UI에서 즉시 확인해 볼 수 있도록 심볼릭 링크(바로가기)를 생성하고자 함
Airflow에서 DAG 파일을 관리하는 경로는 Airflow Home 디렉터리의 airflow.cfg 파일에 정의되어 있음
# The folder where your airflow pipelines live, most likely a
# subfolder in a code repository. This path must be absolute.
#
# Variable: AIRFLOW__CORE__DAGS_FOLDER
#
dags_folder = /home/mlops/airflow/dags
# Hostname by providing a path to a callable, which will resolve the hostname.
# The format is "package.function".
#
# For example, default value "airflow.utils.net.getfqdn" means that result from patched
# version of socket.getfqdn() - see https://github.com/python/cpython/issues/49254.
#
# No argument should be required in the function specified.
# If using IP address as hostname is preferred, use value ``airflow.utils.net.get_host_ip_address``
#
# Variable: AIRFLOW__CORE__HOSTNAME_CALLABLE
#
hostname_callable = airflow.utils.net.getfqdn
# A callable to check if a python file has airflow dags defined or not
PyCharm IDE에서 패키지내 DAG를 정의하거나, 참조해야 하는 Python 모듈을 추가로 개발할 수 있다. 이렇게 개발된 코드는 Airflow Home의 dags 디렉터리 안에 바로 반영될 수 있도록 심볼릭 링크를 생성할 것이다.
⇒ PyCharm에서 mlops-study-ml-pipeline 프로젝트의 features, models 그리고 support 패키지를 Terminal 내의 ~/airflow/dags 하위에 심볼릭 링크 파일을 생성해 두면 PyCharm의 코드와 바로 연결됨
심볼릭 링크 생성 명령어
mkdir -p ~/airflow/dags
ln -snf ~/Study/mlops-study-ml-pipeline/features ~/airflow/dags/features
ln -snf ~/Study/mlops-study-ml-pipeline/features ~/airflow/dags/models
ln -snf ~/Study/mlops-study-ml-pipeline/support ~/airflow/dags/support
ls -al ~/airflow/dags 
-
mkdir -p ~/airflow/dags
- ~ 홈 디렉터리 아래에 airflow/dags 디렉터리를 생성
- -p: 상위 폴더가 없을 경우에도 자동으로 만들어주기 때문에 오류 없이 전체 경로 생성 가능
- 중간 디렉터리 = 부모 디렉터리
-
ln -snf ~/Study/mlops-study-ml-pipeline/features ~/airflow/dags/features
- 해당 디렉터리에 대한 심볼릭 링크를 ~ 홈 디렉터리 아래의 airflow/dags/features 경로에 생성함
- -snf
- -s, —symbolic 심볼릭 링크를 생성
- -n 대상 경로가 심볼릭 링크일 때, 그 심볼릭 링크가 가리키는 실제 디렉터리를 따라가지 않고, 링크 자체를 대상으로 취급하도록 함 = 잘못된 참조를 방지하고 올바르게 삭제 후 덮어쓰게 해줌
- -f, —force 대상 파일이 이미 존재할 경우, 해당 파일을 강제로 삭제하고 링크를 생성
Broken DAG Error Solution
1. DAG 파일 캐시 삭제 - Airflow가 DAG 파일 파싱할 때 사용하는 pycache 삭제하여 변경 사항 반영find ~/airflow/dags -type d -name "__pycache__" -exec rm -r {} +
- Airflow DB Upgrade
- Airflow scheduler와 webserver 재시작
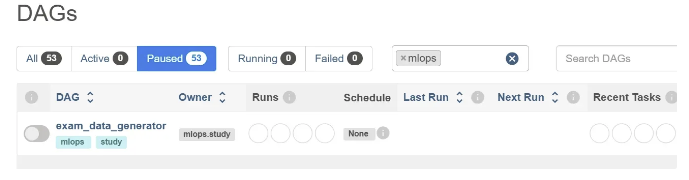
airflow db upgrade airflow webserver airflow scheduler오류 해결 이후 심볼릭 링크가 잘 반영되어 DAGs에 mlops가 조회되는 것을 확인할 수 있다.
3.3 Airflow DAG
Airflow는 데이터 파이프라인을 관리하기 위한 플랫폼으로, 개발자와 데이터 엔지니어 데이터 처리, 변환 그리고 데이터 전송 등의 작업을 보다 쉽게 관리하고 자동화할 수 있도록 도와줌.
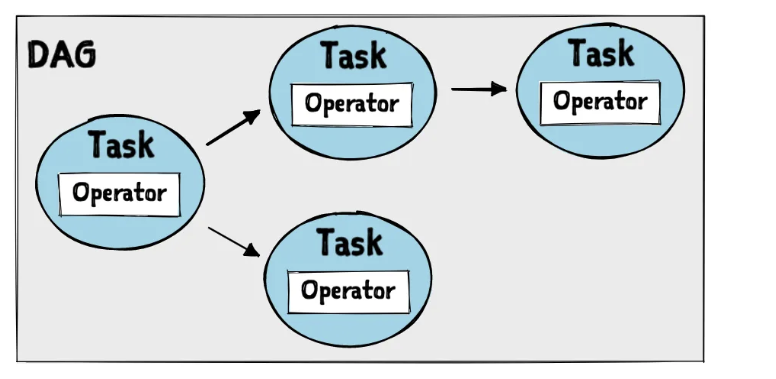
- Airflow의 핵심 기능은 DAG(Directed Acyclic Graph)라는 데이터 파이프라인의 흐름을 나타내는 그래프이다. DAG는 Operator를 통해 구현되는 Task 집합
- Task: DAG의 노드, DAG를 구성하는 작업 단위
- Operator: Task를 실행하기 위한 코드 블록, 데이터처리, 변환 등의 작업 수행함.
Airflow는 DAG를 스케줄링하고 실행하기 위한 다양한 기능 제공
DAG의 실행 스케줄을 설정하고, DAG의 실행 결과를 모니터링하며, 실패한 Task를 다시 실행하도록 스케줄을 조정할 수 있다.
3.3.1 DAG 정의
- DAG는 일반적으로 Context Manager로 관리하는 with 문 안에 DAG()를 선언하는 방법으로 사용
- Context Manager: 파일, 네트워크 연결, 데이터베이스 연결 또는 리소스 관리와 관련된 작업에서 자원의 할당 및 해제를 관리하는데 사용되는 객체
- 주요 역할은 작업을 시작할 때 리소스를 할당하고 작업이 완료되면 자동으로 해제
- Airflow에서 Context Manager는 DAG를 관리하기 위한 기능을 수행하게 되므로, DAG를 선언하고 사용할 때는 with문 사용
- with문을 사용하면 컨텍스트 매니저가 정의한 enter, exit 동작을 관리함
from airflow import DAG
with DAG(dag_id='my_first_airflow_dag',
default_args={
"owner": "mlops.study", # 소유권
"depends_on_past": False, # 과거 성공 여부와 상관없이 실행
# 생략
},
description='우리가 처음 만들어 보는 Airflow Dag입니다.',
schedule="0 8 * * *",
start_date=datetime(2023, 5, 1),
catchup=False,
tags=["mlops", study"],
) as dag:
# Context Manager---------------------------------
def __enter__(self):
DagContext.push_context_managed_dag(self)
return self
def __exit__(self, _type, _value, _tb):
DagContext.pop_context_managed_dag()
# /Context Manager--------------------------------with 문으로 DAG를 선언하면 Airflow가 DAG의 시작과 끝을 자동으로 관리해주기 때문에, 파이프라인 작성이 더 간편하고 안전함
-
Context Manager의 매직 메서드(언더스코어 2개로 시작;끝, 파이썬 클래스 내에 정의, 구현)
- enter
- 컨텍스트에 진입할 때 호출
- DagContext.push_context_managed_dag(self)는 컨텍스트를 관리하는 DAG 스택에 추가, 현재 실행 중인 DAG를 추적하고, 컨텍스트를 제어하는데 사용됨
- return self는 컨텍스트 관리되는 DAG 객체 자체를 반환. with 블록 내에서 변수에 할당되며, 작업 수행 중에 DAG를 참조할 수 있게 된다.
- 반환 값이 with as 구문에서 변수명에 할당 → dag 변수에는 DAG 객체 자체(self)가 할당됨
- exit
- 컨텍스트에서 빠져나올 때 호출
- enter
-
Dag를 선언하기 위해 입력한 매개변수
-
dag_id
- DAG를 식별할 수 있는 ID로 중복 불가
- 알파벳과 숫자, 대시, 점, 언더스코어만 사용 가능
-
default_args
- Task에게 인자를 전달하기 위해서 생성하는 기본 매개변수 집합
- 각 Task 생성자에게 명시적으로 인자를 전달하면 중복될 수 있기 때문에 선택한 방식
-
description
- Airflow 웹 서버에서 표시되는 DAG에 대한 설명
-
schedule
- DAG 실행이 예약되는 규칙을 정의함. cron문자열, timedelta객체, Timetable 또는 데이터셋 객체의 목록을 사용할 수 있음
- 매일 08:00에 실행하는 것을 의미

-
start_date
- DAG의 실행을 시작할 날짜를 지정하며, 스케줄러가 Catch up 수행 시 참조하는 타임스탬프로 사용됨
-
catchup
- 스케줄러가 Catch up을 수행할 것인지, 현재 날짜에 실행해야 할 최신 DAG인스턴스만 실행할 것인지를 결정하게 되며, 기본값은 True
- 과거에 놓친 스케줄들을 역으로 채워서 실행할지 여부
- catchup=True면 Start Date부터 Current Date까지 날짜별로 DAG 실행됨
- False면, Current Date부터 스케줄링되어 DAG 실행
- 스케줄러가 Catch up을 수행할 것인지, 현재 날짜에 실행해야 할 최신 DAG인스턴스만 실행할 것인지를 결정하게 되며, 기본값은 True
-
tags
- Airflow web UI에서 DAG를 필터링하는 데 도움이 되는 태그 목록
-
3.3.2 Task 정의
Task에서 사용할 Operator의 클래스를 import하는데, BashOpertator를 선택함
Task는 DAG를 선언한 with 절 안에 작성해야 하며 DAG는 3개의 Task를 가진다.
모두 BashOperator를 사용하여 작업을 수행하며 각 Task를 연결하여 하나의 DAG를 정의한다.
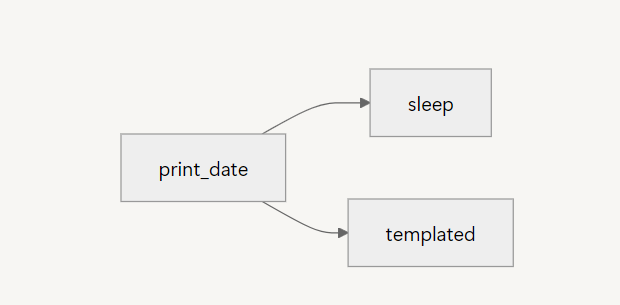
Task1
Task1은 date라는 명령어를 수행하고, 그 결과를 출력하는 기능 정의
task1= BashOperator(
task_id="print_date",
bash_command="date",
)- task_id도 Dag 내에서 고유한 ID 값을 갖는다.
- 중복되면 DulicateTaskIdFound 오류가 발생함
- bash_command: Airflow가 태스크를 실행할 때 터미널에서 date라는 명령어를 실행하도록 지시
Task2
Task2는 sleep 5 명령어를 실행하도록 정의하였으며, 명령어가 실행되면 5초간 대기하고 종료함
task2= BashOperator(
task_id="sleep",
depends_on_past=False,
bash_command="sleep 5",
retries=3,
)- depends_on_past=False: True로 설정하면, Task 인스턴스는 이전에 실패하지 않았을 경우에만 순차적으로 실행함. 기본값이 False이므로 이 코드에 없어도 동일하게 동작한다.
- retries=3: Task가 실패 시 재수행 작업을 3회 하도록 설정함. 기본값은 airflow.cfg 파일에 정의된 default_task_retries로 0이다. ‘
Task3
Task3는 Jinja 템플릿을 사용해, templated_command에 작성된 셸 코드를 실행하고, 그 결과를 출력함
{% %} 블록에 코드 논리가 포함되어 있고, {{ ds }}와 같은 매개변수를 참조하며, 함수를 호출한다.
templated_command = dedent(
"""
{% for i in range(5) %}
echo "ds = {{ ds }}"
echo "macros.ds_add(ds, {{ i }}) = {{ macros.ds_add(ds, i) }}"
{% endfor %}
"""
)
task3= BashOperator(
task_id="templated",
bash_command="templated_command",
)- templated_command = dedent(): Jinja 템플릿을 이용해 실행 명령어를 생성함
- dent(): text 변수의 각 줄에서 공백으로 시작하는 부분을 모두 제거하는 메서드
- {% %}블록: for / endfor와 같은 논리가 포함되어 있으며, 5번 반복 수행
- {{ ds }}: Jinja 템플릿 매개 변수를 참조함
- macros.ds_add(ds, i): 매크로 함수를 호출하여 날짜를 더해 줌
Airflow의 Jinja 템플릿
Airflow에서는 Jinja 템플릿으로 파이프라인에 사용할 수 있는 매개변수와 매크로 세트를 제공하며, 개발자가 자체 매개변수, 매크로 세트를 정의할 수 있도록 제공한다.
매개변수
- {{ ds }}: 오늘의 ‘날짜 스탬프’, YYYY-MM-DD 형식으로 출력
- {{ ds_nodash }}: YYYYMMDD
매크로
- {{ macros.ds_add(ds, 1) }}: 오늘 ‘날짜 스탬프’에 +1을 하는 함수 ⇒ 1일 추가
- {{ macros.ds_format(ds, input_format, output_format) }}: 입력한 String 날짜의 input_format을 지정하고, ouput_format으로 지정된 형식으로 날짜를 변환하여 String으로 반환함
3.3.3 Task Dependencies
Tasks 중 Task1이 실행되면 Task2와 Task3이 실행되는 의존성을 가지고 있다.
- Task1 → Task2
- task1.set_downstream(task2): task1 끝나고 실행될 작업으로 task2 지정
- task2.set_upstream(task1): task2 실행 되기 전에 실행될 작업으로 task1 지정
- task1 >> task2: 비트 시프트 연산자(>>)는 작업을 연결하는 데도 사용됨
- task2 << task1: upstream 종속성 정의
- Task1 → Task2 → Task3
- task1 >> task2 >> task3
- Task1 → (Task2, Task3)
- task1.set_downstream([task2, task3]): task2, task3을 List 데이터 타입으로 지정
- task1 >> [task2, task3]
- [task2, task3] << task1
3.4 Airflow DAG 개발
3.4.1 DAG 개발
import pendulum
from textwrap import dedent
from datetime import datetime, timedelta
from airflow import DAG # 2.7.2ver 설치
from airflow.operators.bash import BashOperator
from support.callback_functions import success_callback, failuer_callback
# 로컬 타임존 생성
local_timezone = pendulum.timezone("Asia/Seoul")
with DAG(dag_id="my_first_airflow_dag",
default_args={
"owner": "mlops.study",
"depends_on_past": False,
"email": ["mlops.study@gmail.com"],
"email_on_failure": False,
"email_on_retry": False,
"retries": 1,
"retry_delay": timedelta(minutes=5),
"on_failure_callback": failure_callback, # 정의 함수
"on_success_callback": success_callback,
},
description='우리가 처음 만들어 보는 Airflow Dag 입니다.',
schedule="0 8 * * *",
start_date=datetime(2023, 5, 1, tzinfo=local_timezone),
catchup=False,
tags=["mlops", "study"],
) as dag:
task1 = BashOperator(
task_id="print_date",
bash_command="date",
)
task2 = BashOperator(
task_id="sleep",
depends_on_past=False,
bash_command = "sleep 5",
retries = 3,
)
templated_command = dedent(
"""
{% for i in range(5) %}
echo "ds = {{ ds }}"
echo "macros.ds_add(ds, {{ i }}) = {{ macros.ds_add(ds, i) }}"
{% endfor %}
"""
)
task3= BashOperator(
task_id="templated",
bash_command="templated_command",
)
task1 >> [task2, task3]- support package에 success, failuere_callback 함수가 존재하지 않기 때문에 함수 추가해야 함
def success_callback(context): print("success_callback!") print(f"context: {context}") def failure_callback(context): print("failure_callback!") print(f"context: {context}")
Flask 호환성 문제
여러 확장 프로그램을 설치하다 보니 호환성 충돌 문제가 잦게 발생한다.
Flask 2.2.5 → airflow 2.7.2와 호환됨
Flasck-Session 0.4.0 이상이어야 호환됨
해결 후 airflow db upgrade로 migration 시켜주니 업데이트 되어있음
3.4.3 DAG 결과 확인
Grid 버튼
- 날짜별 Task의 작업 상태
- Task 재실행, 상태를 변경하기 위해서 실행하는 버튼: Clear, Mask state as …
- Task 실패 시: MoreDetails로 상세 정보 확인
- XCom: 전달된 값 확인 가능
Graph 버튼
Graph로 Task가 표시된다.
방금 실행시켜 success 상태까지는 기다려야 한다.
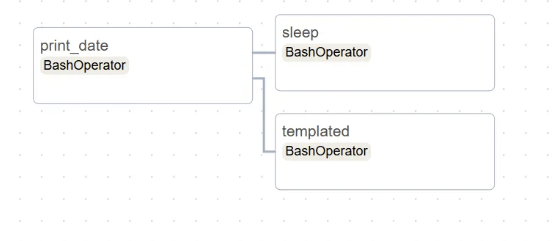
Trigger
시간 설정은 08:00으로 해놨기 때문에 내일 아침이 되어야 볼 수 있다.
기다릴 수 없다면 ⇒ 수동 trigger

수동 trigger로 인하여 Last Run이 현재 시각이다.
Calendar 버튼
2023년 1월부터의 DAG 실행 결과 확인 가능
Task Duration 버튼
Task 실행된 시간 확인 가능
Airflow로 Workflow를 개발하다 보면, 다양한 오류를 만날 수 있고 그 결과를 확인해야 하는 일이 생긴다. 이럴 때 앞에 나온 설명대로 Task의 상태를 확인할 수 있고, 정상적으로 Task가 동작했는지 또는 오류가 발생하면 어떤 오류를 나타내는지 확인할 수 있다.
3.5 Data Extraction Pipeline 개발
SQL 작업을 데이터 파이프라인으로 구축하는 과정을 살펴보면서 SQL 쿼리의 로직이 Airflow DAG의 Task로 어떻게 변환되는지 확인해 볼 것이다.
ML Pipeline의 Data Extraction 단계를 구현하기 전에 데이터 파이프라인을 미리 경험하고, 데이터 과학자의 SQL을 주기적을 동작시키기 위해 추가로 고려해야 할 사항들을 알아본다.
3.5.1 준비 사항
apache-airflow-providers-mysql 설치
Airflow에서 MySQL 또는 MariaDB를 사용하기 위해서 MySQL에서 제공하는 패키지를 설치해야 함
- python 개발 환경은 프로젝트 내에 설정하였으므로, pycharm 터미널 내에서 실행해야 함
- mysql과 관련된 패키지는 설치되지 않은 것을 확인할 수 있음
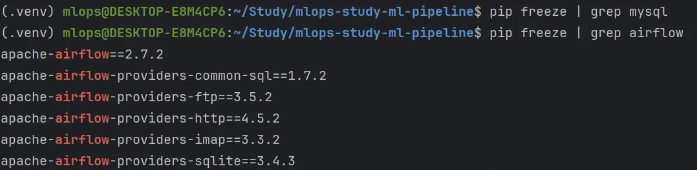
- 터미널에서 Python mysqlclient 패키지를 설치하기 위해, mysql과 pkg-config를 먼저 설치

- apache-airflow-providers-mysql 패키지 설치

Airflow Connection 추가
Airflow에서 Feature Store(MySQL)을 접속해서 데이터를 처리하려면 Connection을 추가해야 함

3.5.2 DAG 개발
이제 Airflow에서 MariaDB를 사용해 데이터를 처리하는 데이터 파이프라인을 개발할 준비가 되었다.
DAG 생성
import pendulum # 날짜 및 시간 관련 작업 python 라이브러리
from datetime import datetime
from airflow import DAG
from airflow.providers.common.sql.operators.sql import SQLExecuteQueryOperator
from support.callback_functions import success_callback, failure_callback
local_timezone = pendulum.timezone('Asia/Seoul')
conn_id = "feature_store"
task = SQLExecuteQueryOperator(
task_id="create_table_ineligible_loan_model_features_02",
conn_id=conn_id,
sql="drop table mlops.ineligible_loan_model_features"
)
with DAG(dag_id="data_extract_pipeline",
default_args={
"owner": "mlops.study",
"depends_on_past": False,
"email": ["mlops.study@gmail.com"],
"on_failure_callback": failure_callback,
"on_success_callback": success_callback,
},
description='데이터추출_파이프라인',
schedule=None, # 주기적으로 실행되지 않도록 None으로 설정
start_date=datetime(2023, 5, 1, tzinfo=local_timezone),
catchup=False,
tags=["mlops", "study"],
) as dag:- 파이프라인이 주기적으로 실행되지 않도록 schedule 항목은 None으로 설정한다.
Task 개발
SQLExecuteQueryOperator는 데이터베이스에서 다양한 쿼리(DDL, DML)를 수행하도록 도와주는 오퍼레이터이다. 또한 칼럼 또는 테이블 수준에서의 데이터 품질을 체크하는 기능도 제공한다.
01_data_extract.sql 파일의 SQL을 하나씩 Task로 정의하여 DAG에 추가한다.
출처
Apache AirFliow2를 사용한 머신러닝 OPS[MLOP]
https://fueled.com/the-cache/posts/backend/devops/mlops-with-airflow2/
MLOps 구축 가이드북 - 김남기
