
정규 표현식 살펴보기
정규 표현식(Regular Expressions)은 복잡한 문자열을 처리할 때 사용하는 기법으로, 파이썬만의 고유 문법이 아니라 문자열을 처리하는 모든 곳에서 사용한다. 정규 표현식을 배우는 것은 파이썬을 배우는 것과는 또 다른 영역의 과제이다.
🤔 정규 표현식은 왜 필요한가
주민등록번호를 포함하고 있는 텍스트가 있다.
이 텍스트에 포함된 모든 주민등록번호의 뒷자리를 * 문자로 변경해 보자.- 전체 텍스트를 공백 문자로 나눈다(split).
- 나뉜 단어가 주민등록번호 형식인지 조사한다.
- 단어가 주민등록번호 형식이라면 뒷자리를 ``로 변환한다.
- 나뉜 단어를 다시 조립한다.
data = """
park 800905-1049118
kim 700905-1059119
"""
result = []
for line in data.split("\n"):
word_result = []
for word in line.split(" "):
if len(word) == 14 and word[:6].isdigit() and word[7:].isdigit():
word = word[:6] + "-" + "*******"
word_result.append(word)
result.append(" ".join(word_result))
print("\n".join(result))🤯 대가리 터진다
⇒ 정규 표현식을 이용하면 코드가 굉장히 간결해진다
정규 표현식의 기초, 메타 문자
메타 문자란 원래 그 문자가 가진 뜻이 아닌 특별한 용도로 사용하는 문자를 말한다.
. ^ $ * + ? { } [ ] \ | ( )정규 표현식에 위 메타 문자를 사용하면 특별한 의미를 갖게 된다.
📌 문자 클래스
[abc]
# 문자 클래스를 만드는 메타 문자인 [ ] 사이에는 어떤 문자도 들어갈 수 있다.- "a"는 정규식과 일치하는 문자인 "a"가 있으므로 매치
- "before"는 정규식과 일치하는 문자인 "b"가 있으므로 매치
- "dude"는 정규식과 일치하는 문자인 a, b, c 중 어느 하나도 포함하고 있지 않으므로 매치되지 않음
Dot(.)
a.b # === "a + 모든문자 + b"
# 정규 표현식의 Dot(.) 메타 문자는 줄바꿈 문자인 \n을 제외한 모든 문자와 매치됨을 의미한다.- "aab"는 가운데 문자 "a"가 모든 문자를 의미하는
.과 일치하므로 정규식과 매치된다. - "a0b"는 가운데 문자 "0"가 모든 문자를 의미하는
.과 일치하므로 정규식과 매치된다. - "abc"는 "a"문자와 "b"문자 사이에 어떤 문자라도 하나는있어야 하는 이 정규식과 일치하지 않으므로 매치되지 않는다.
반복(*)
ca*t
# 이 정규식에는 반복을 의미하는 * 메타 문자가 사용되었다. 여기에서 사용한 *은 * 바로 앞에 있는 문자 a가 0부터 무한대로 반복될 수 있다는 의미이다.
# 메모리상 2억개로 제한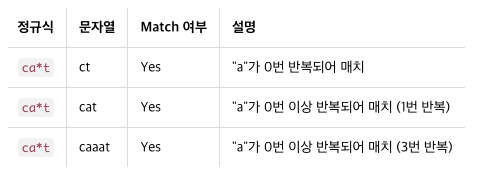
반복(+)
ca+t # === "c + a(1번 이상 반복) + t"
# 반복을 나타내는 또 다른 메타 문자로 +가 있다. +는 최소 1번 이상 반복될 때 사용한다. 즉 *가 반복 횟수 0부터라면 +는 반복 횟수 1부터인 것이다.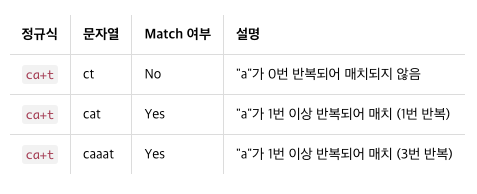
반복 ({m,n}, ?)
ca{2}t # === "c + a(반드시 2번 반복) + t"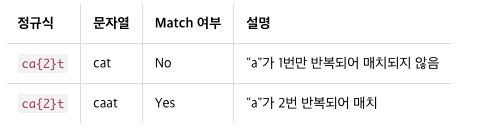
ca{2,5}t # === "c + a(2~5회 반복) + t"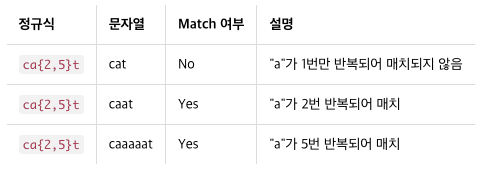
ab?c # === "a + b(있어도 되고 없어도 된다) + c"
# === {0,1}파이썬에서 정규 표현식을 지원하는 re 모듈
>>> import re
>>> p = re.compile('ab*')re.compile을 사용하여 정규 표현식(위 예에서는 ab*)을 컴파일한다. re.compile의 결과로 돌려주는 객체 p(컴파일된 패턴 객체)를 사용하여 그 이후의 작업을 수행할 것이다.
즉, p는 이제 패턴 객체가 되어 p에 패턴에 맞춰야한다

match
match 메서드는 문자열의 처음부터 정규식과 매치되는지 조사한다
import re
>>> p = re.compile('[a-z]+')
# 매치가 되는 경우
>>> m = p.match("python")
>>> print(m)
<re.Match object; span=(0, 6), match='python'> # 잘 매치됨
# 매치가 되지 않는 경우
>>> m = p.match("3 python")
>>> print(m)
Nonesearch
일치하는 객체를 찾아준다
>>> m = p.search("3 python")
>>> print(m)
<re.Match object; span=(2, 8), match='python'>findall
일치하는 string을 리스트로 리턴함
>>> result = p.findall("life is too short")
>>> print(result)
['life', 'is', 'too', 'short']finditer
일치하는 string을 이터레이터 객체 = 이터러블 = 순환 가능한 객체로 리턴해줌
>>> result = p.finditer("life is too short")
>>> print(result)
<callable_iterator object at 0x01F5E390>
>>> for r in result: print(r)
<re.Match object; span=(0, 4), match='life'>
<re.Match object; span=(5, 7), match='is'>
<re.Match object; span=(8, 11), match='too'>
<re.Match object; span=(12, 17), match='short'>위 4가지 메서드로 생성되는 객체는 match 객체이다
match 객체의 메서드
일치하는 객체(= match 객체) 가 사용할수 있는 메서드
- 어떤 문자열이 매치되었는가?
- 매치된 문자열의 인덱스는 어디서부터 어디까지인가?

컴파일 옵션
정규식을 컴파일 할 때 옵션을 사용할 수 있다
# 옵션 ㄴㄴ
import re
p = re.compile('[a-z]+')
# 옵션 넣으면?
import re
p = re.compile('[a-z]+', 옵션을 넣는곳)DOTALL(S)
.이 줄바꿈 문자를 포함하여 모든 문자와 매치할 수 있도록 한다.
# 기존
>>> import re
>>> p = re.compile('a.b')
>>> m = p.match('a\nb')
>>> print(m)
None
# DOTALL
>>> p = re.compile('a.b', re.DOTALL)
>>> m = p.match('a\nb')
>>> print(m)
<_sre.SRE_Match object at 0x01FCF3D8>IGNORECASE(I)
대소문자에 관계없이 매치할 수 있도록 한다.
>>> p = re.compile('[a-z]', re.I)
>>> p.match('python')
<_sre.SRE_Match object at 0x01FCFA30>
>>> p.match('Python')
<_sre.SRE_Match object at 0x01FCFA68>
>>> p.match('PYTHON')
<_sre.SRE_Match object at 0x01FCF9F8>MULTILINE(M)
여러줄과 매치할 수 있도록 한다. (
^,$메타문자의 사용과 관계가 있는 옵션이다)
# 기존
import re
p = re.compile("^python\s\w+")
data = """python one
life is too short
python two
you need python
python three"""
print(p.findall(data)) # ['python one']
# MULTILINE(M)
import re
p = re.compile("^python\s\w+", re.MULTILINE)
data = """python one
life is too short
python two
you need python
python three"""
print(p.findall(data)) # ['python one', 'python two', 'python three'] VERBOSE(X)
verbose 모드를 사용할 수 있도록 한다. (정규식을 보기 편하게 만들수 있고 주석등을 사용할 수 있게된다.)
charref = re.compile(r'&[#](0[0-7]+|[0-9]+|x[0-9a-fA-F]+);')
# 예시
charref = re.compile(r"""
&[#] # Start of a numeric entity reference
(
0[0-7]+ # Octal form
| [0-9]+ # Decimal form
| x[0-9a-fA-F]+ # Hexadecimal form
)
; # Trailing semicolon
""", re.VERBOSE)쉽게 말해 긴 정규 표현식에다가 설명을 넣어도 ㄱㅊ게 할수있게 함
백슬래시 문제
파이썬 표현식에는 백슬래시로 시작하는 표현식이 많기 때문에 백슬래쉬 뒤에 오는 문자열은 개발자의 의도와 다를 수 있다
\section # === [ \t\n\r\f\v]ection
# \s 문자가 whitespace로 해석되어 의도한 대로 매치가 이루어지지 않는다.
\\section ## \section 으로 인식함
# \를 Raw String(= 특수문자를 무시한다) 이라 말해주면 됨
>>> p = re.compile(r'\\section')강력한 정규 표현식의 세계로
📌 메타 문자
아직 살펴보지 않은 메타 문자에 대해서 모두 알아보자
|
| 메타 문자는 or과 동일한 의미로 사용된다. A|B라는 정규식이 있다면 A 또는 B라는 의미가 된다.
>>> p = re.compile('Crow|Servo') # Crow 또는 Servo
>>> m = p.match('CrowHello')
>>> print(m)
<re.Match object; span=(0, 4), match='Crow'>^
^ 메타 문자는 문자열의 맨 처음과 일치함을 의미한다.
>>> print(re.search('^Life', 'Life is too short'))
<re.Match object; span=(0, 4), match='Life'>
>>> print(re.search('^Life', 'My Life'))
None$
^ 메타 문자와 반대의 경우이다. 즉 $는 문자열의 끝과 매치함을 의미한다.
>>> print(re.search('short$', 'Life is too short'))
<re.Match object; span=(12, 17), match='short'>
>>> print(re.search('short$', 'Life is too short, you need python'))
None\b
공백을 나타내는 메타문자
>>> p = re.compile(r'\bclass\b')
>>> print(p.search('no class at all'))
<re.Match object; span=(3, 8), match='class'>
>>> print(p.search('the declassified algorithm'))
None📌 그루핑
() 를 이용해 표현식을 묶어줌
abc를 반복되는걸 찾고 싶으면?
(ABC)+
>>> p = re.compile('(ABC)+')
>>> m = p.search('ABCABCABC OK?')
>>> print(m)
<re.Match object; span=(0, 9), match='ABCABCABC'>
>>> print(m.group())
ABCABCABC
# 그루핑중 원하는 그룹만 뽑아 올수있다
>>> p = re.compile(r"(\w+)\s+\d+[-]\d+[-]\d+")
>>> m = p.search("park 010-1234-1234")
>>> print(m.group(1))
park
# 그루핑된 문자열 재참조하기
>>> p = re.compile(r'(\b\w+)\s+\1') # (그룹) + " " + 그룹과 동일한 단어
# 재참조 메타 문자 \1, \1은 정규식의 그룹 중 첫 번째 그룹을 가리킨다.
>>> p.search('Paris in the the spring').group()
'the the'
# 그루핑된 문자열에 이름 붙히기 (?P<그룹명>...)
>>> p = re.compile(r"(?P<name>\w+)\s+((\d+)[-]\d+[-]\d+)")
>>> m = p.search("park 010-1234-1234")
>>> print(m.group("name"))
park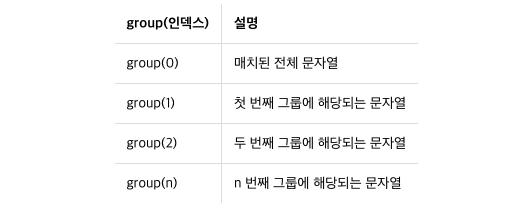
📌 전방 탐색
긍정형: (?=)
검색에는 포함되지만 검색 결과에는 제외됨
>>> p = re.compile(".+(?=:)") # 조건에선 찾되, 결과에선 빠지게 하고 싶을때. (?=:)는 :를 제외 한다는말
>>> m = p.search("http://google.com")
>>> print(m.group())
http부정형: (?!)
검색에 제외해서 출력함
import re
p = re.compile(".*[.](?!bat$|exe$).*$",re.M)
l = p.findall("""
autoexec.exe
autoexec.bat
autoexec.jpg
""")
print(l)📌 문자열 바꾸기
정규식과 매치되는 부분을 다른 문자로 쉽게 바꿀수 있다.
>>> p = re.compile('(blue|white|red)') # 정규식
>>> p.sub('colour', 'blue socks and red shoes') # 위 정규식과 2번째 인자가 일치하는 부분을 1인자로 바꾼다
'colour socks and colour shoes'📌 Greedy vs Non-Greedy
import re
>>> s = '<html><head><title>Title</title>'
>>> len(s)
32
>>> print(re.match('<.*>', s).span()) # Greedy '<html><head><title>Title</title>' 최대에서 가장 첫번째<>안의 문자를 가져옴
(0, 32)
>>> print(re.match('<.*>', s).group()) # Non-Greedy '<html><head><title>Title</title>'<>가 최소로 가장 첫번째 문자를 가져옴
<html><head><title>Title</title>