
- R설치
(1) 다양한 통계 분석 프로그램
- 데이터 분석을 위한 도구로는 SAS, SPSS, S-Link 등 다양한 소프트웨어가 있지만 오픈소스라는 큰 특징을 가진 R이 보편적으로 사용되고 있다. 또한 고차원적인 계산이 가능하기 때문에 복잡한 통계기법을 폭넓게 다룰 수 있으며, 데이터 시각화에 최적화된 환경을 제공하기 때문에 한국데이터산업진흥원은 R과 그 개발환경인 RStudio를 데이터 분석 준전문가 자격증 취득을 위한 분석 도구로 선택하였다.
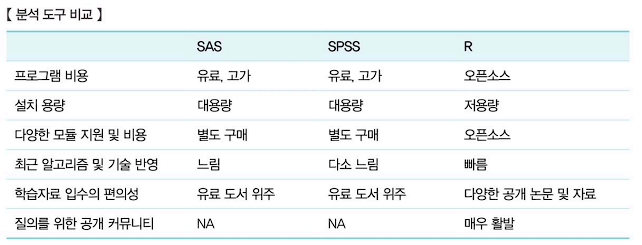
(2) 통계 및 데이터 분서 프로그램 R
- R은 뉴질랜드 통계학자인 로스 이하카(Ross Ihaka)와 캐나다 통계학자인 로버트 젠틀맨(Robert Gentleman)에 의하여 1995년에 제작된 언어로, 빠른 속도로 확산되고 현재까지도 다양한 분야에서 사용되는 오픈소스 통계 분석 도구다.
(3) R 개발 개발 환경이 'RStudio'
- R은 통계 분석을 위한 언어인 반면 RStudio는 사용자가 원하는 대로 R 명령문을 활용해 구현하게 해주는 통합 개발 환경(IDE)이다.
- R언어를 활용하여 작성된 함수에 따라 데이터를 분석하고, 결과 및 시각화된 결과를 사용자에게 개발 환경에서 즉시 보여준다.
- 일반적인 R 환경을 명령 프롬프트(cmd)에 비유한다면 RStudio는 사용자의 편의성을 위한 운영체제 중 하나인 윈도우에 비유할 수 있다.
(4) R 설치
- R을 먼저 설치하고 RStuido를 설치한다.
1) RStudio를 활용한 R 기본 사용법
(1) RStudio 기본 구성
a. 스크립트 창 : 명령문을 작성하여 원하는 라인, 원하는 블록 단위로 문장을 실행할 수 있다. 만약 R을 실행했을 때 R스크립트 창이 보이지 않는다면 Ctrl+Shift+N 또는 상단의 메뉴에서 File->New File->R Script를 클릭한다.
b. 콘솔 창 : R 스크립트 창과 같이 명령문을 작성하고 실행할 수 있으며, 명령문에 의해 발생한 오류, 결과 등을 확인할 수 있다.
c. 환경(Environment)과 히스토리(History) : 환경 창에서는 명령문을 통해 생성된 변수, 불러운 데이터, 생성된 함수 등의 개요를 볼 수 있으며, 히스토리 창에서는 그동안 실행된 과거 명령문을 볼 수 있다.
d. 기타(파일, 산점도, 패키지, 도움말, 기타 뷰어) : 현재 작업 디렉터리에 존재하는 파일, 현재 호출되어 있는 패키지, 산점도 같은 시각화 데이터, 도움말 등을 볼 수 있다. 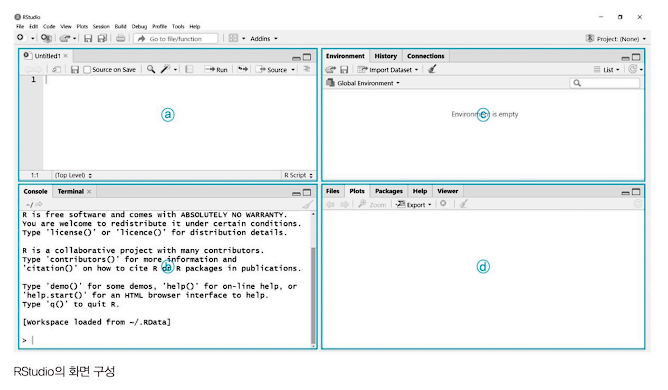
(2) R의 데이터 타입
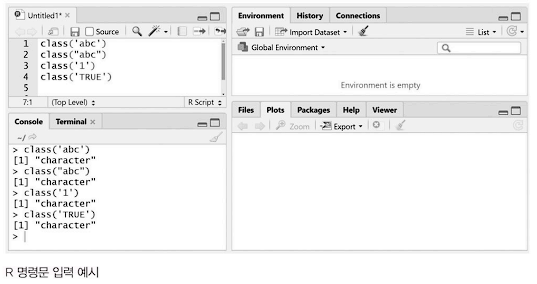
1. 문자형 타입 : character는 문자형 타입으로, 따옴표 혹은 쌍따옴표로 표시할 수 있다. 숫자, 문자, 논리형 모두 따옴표 혹은 쌍따옴표 안에 표시할 경우 모두 문자형이 된다. 각 변수의 타입은 class함수를 이용해 확인할 수 있다. class 함수는 데이터 타입을 문자열로 반환해준다.

-
숫자형 타입 : 계산이 가능한 데이터를 숫자형 타입이라 한다. 숫자형 타입에는 numeric(숫자형), double(실수), integer(정수), complex(복소수) 등이 있다. double은 숫자형 타입으로 숫자로만 표현이 가능하다. Inf는 Infinite의 약자로, 무한대를 의미하며, -Inf는 음의 무한대를 의미한다.

-
논리형 타입 : logical은 논리형 타입으로 참 혹은 거짓을 의미한다.

-
NaN, NA, NULL : NaN은 'Not a Number'의 약자로 음수의 제곱근을 구하려고 시도하는 것과 같은 경우에 오류와 함께 숫자가 아님을 반환한다. 'Not Available'의 약자인 NA와 NULL은 결측값을 의미한다. NA는 하나의 공간을 차지하는 결측값을 의미하는 반면 NULL은 공간을 차지하지 않는 존재하지 않는 값을 의미한다.

2) R기본 문법
(1) 연산자
-
대입 연산자 : 대입 연산자는 변수에 값을 할당하기 위해 사용하는 연산자로, 크게 5가지가 있다. 변수에 값이 정상적으로 할당되었다면 RStudio의 오른쪽 상단에 있는 환경 창에 변수와 그에 대응되는 값 혹은 데이터의 개요가 등록될 것이다.

-
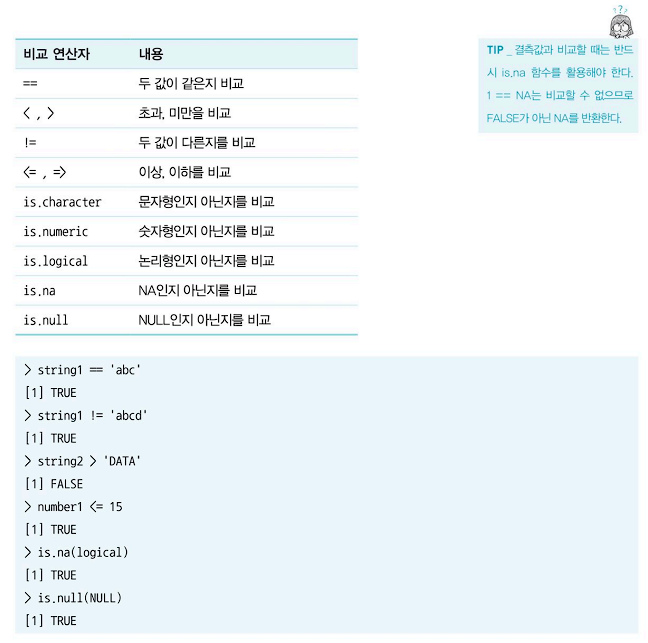
비교 연산자 : 대입 연산자에 의하여 할당된 값과 변수를 비교하거나 임의의 숫자, 문자 혹은 논리값을 비교할 수 있다. NA는 비교할 값이 존재하지 않으므로 어떤 것과 비교를 하더라도 NA를 반환한다.
-
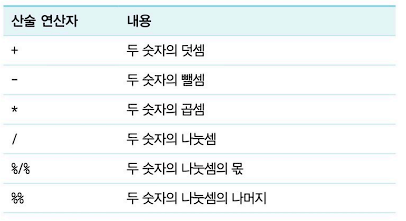
산술 연산자 : 두 숫자형 타입의 계산을 위한 연산자로서 다양한 연산이 가능하다.

-
기타 연산자 : 논리값을 계산하기 위해 연산자로는 부정 연산자, AND 연산자, OR 연산자가 있다.

(2) R 데이터 구조
1. 벡터
- 벡터는 타입이 같은 여러 데이터를 하나의 행으로 저장하는 1차원 데이터 구조이다.
- '연결한다'라는 의미의 'concatenate'의 c를 써서 데이터를 묶을 수 있다.

- 벡터를 생성할 때 c안에 콤마를 구분자로 써서 성분을 직접 입력할 수 있지만 콜론(:)을 활용하여 시작값과 끝값을 지정해 벡터를 생성할 수도 있다.

- 행렬
- 행렬은 2차원 구조를 가진 벡터다. 벡터의 성질을 가지고 있으므로 행렬에 저장된 모든 데이터는 같은 타입이어야 한다.
- 그렇지 못할 경우 자동으로 타입 변환을 수행한다.
- matrix를 사용하여 행렬을 만들 경우 nrow를 사용하여 행의 수를 결정하거나 ncol을 사용하여 열의 수를 결정할 수 있다.

- matrix를 사용하여 행렬을 만들 경우 행렬의 값들이 열로 저장되는 것을 볼 수 있따. 하지만 byrow옵션에 T(TRUE)를 지정하면 값들이 열이 아닌 행으로 저장된다.

- 행렬을 만드는 또 다른 방법은 벡터에 차원을 주는 방법이다. dim 함수를 사용하면 행의 개수와 열의 개수를 지정하여 행렬로 변환할 수 있다. 또한 다음 페이지의 콘솔 창에서 볼 수 있듯이 dim함수는 벡터를 행렬로 변환할 뿐만 아니라 주어진 행렬이 몇 개의 행과 몇 개의 열로 구성되어 있는지 행렬의 크기를 나타내기도 한다.

- 배열
- 3차원 이상의 구조를 갖는 벡터를 배열이라고 한다.
- 배열 또한 벡터의 성질을 가지고 있으므로 하나의 배열에 포함되는 데이터는 모두 같은 타입이어야 한다. array를 사용하여 배열을 만들 수 있으나 몇 차원의 구조를 갖는지 dim 옵션에 명시해야 한다.
- 그렇지 않으면 1차원 벡터가 생성된다.

- 배열을 생성하는 또 다른 방법으로 행렬과 마찬가지로 dim 함수를 사용해서 벡터에 차원을 지정해 만들 수 있다.

- 리스트
- 리스트는 데이터 타입, 데이터 구조에 상관없이 사용자가 원하는 모든 것을 저장할 수 있는 자료구조다. 즉, 리스트는 성분 간에 이질적인 특징을 가지고 있다.
- 다음은 R 콘솔에서 list()를 사용해서 list를 담을 변수를 선언하고 첫 번째 성분으로 숫자형 데이터를, 두 번째 성분으로는 벡터를, 세 번째 성분으로는 행렬을, 네 번째 성분으로는 배열을 담은 뒤 리스트를 출력한 결과다.

- 데이터프레임
- 데이터프레임은 데이터 분석을 위한 2차원 구조를 갖는 관계형 데이터 구조로서 R에서 가장 많이 활용되는 데이터 구조다.
- 행렬과 같은 모양을 갖지만 여러 개의 벡터로 구성되어 있기 때문에 각 열은 서로 다른 타입의 데이터를 가질 수 있다.


3) R 내장 함수
(1) 기본 함수 
(2) 통계 함수 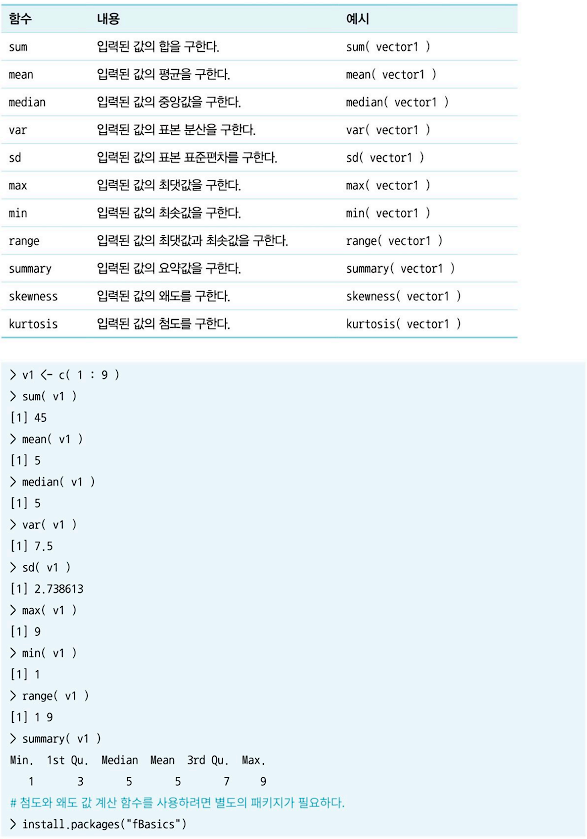

4) R 데이터 핸들링
(1) 데이터 이름 변경
- 행렬, 배열, 데이터프레임과 같이 2차원 이상의 데이터 구조는 colnames와 rownames 함수를 사용하여 행과 열의 이름을 알 수 있으며, 이름을 지정할 수 있다.

(2) 데이터 추출
- R이 보유한 여러 데이터 구조, 즉 벡터, 행렬, 배열, 리스트, 데이터프레임 모두 인섹싱을 지원하기 때문에 대괄호 기호([,])를 사용하여 원하는 위치의 데이터를 손쉽게 얻을 수 있으며 행과 열의 이름으로도 데이터를 얻을 수 있다.

- 데이터프레임에서는 $기호를 사용하여 원하는 열의 데이터를 구할 수 있으며, $와 []를 혼용할 수있다.

(3) 데이터 결합
- R에서 벡터, 행렬, 데이터프레임을 서로 결합하는 방법은 다양하다. 그중 데이터를 행으로 결합하는 rbind와 열로 결합하는 cbind가 대표적이다.


- 행렬과 행렬, 데이터프레임과 데이터프레임의 경우 행의 수 혹은 열의 수가 같을 경우 결합이 가능하다. 하지만 벡터와 벡터의 결합에서는 재사용 규칙으로 인하여 부족한 데이터를 앞에서부터 다시 재활용하여 사용하며 오류와 함께 결과를 반환한다.

5) 제어문
(1) 반복문
- 반복문은 대표적인 제어문 중 하나로 특정 부분의 코드가 반복적으로 수행되도록 한다.
- for 반복문과 while 반복문의 두 가지 종류가 있다.


(2) 조건문
- 조건문은 반복문과 함께 가장 많이 사용되는 제어문 중 하나로서 참과 거짓에 따라 특정 코드가 수행될지 혹은 수행되지 않을지를 결정한다.


(3) 사용자 정의 함수
- 자주 사용되는 구문을 필요할 때마다 작성하지 않고 하나의 함수로 명명하여 저장하였다가 필요한 경우 함수를 호출해서 대신할 수 있다.


(4) 주석
- 주석은 R에서 실행되지 않는 문장으로, 바로 위 혹은 바로 아래에 위치한 R코드를 설명하거나 함수를 설명할 목적으로 작성하는 글로서 #을 사용하여 표시한다.

6) 통계분석에 자주 사용되는 R함수
(1) 숫자 연산 
(2) 문자 연산 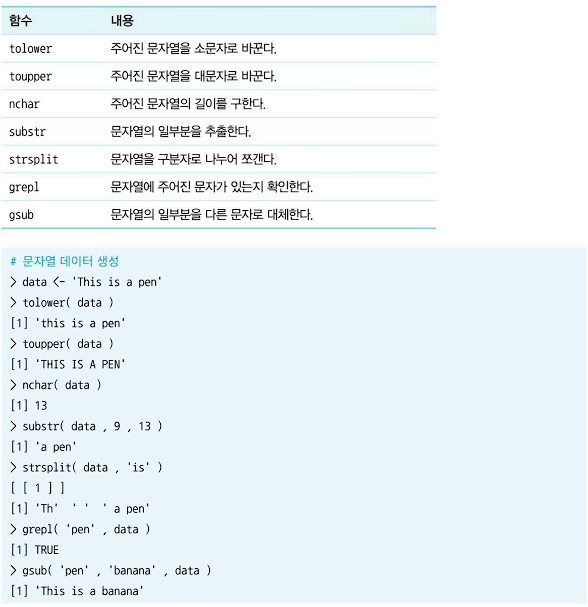
(3) 벡터 연산 
(4) 행렬 연산 
(5) 데이터 탐색 
(6) 데이터 전처리 

(7) 정규분포(기본값은 표준 정규 분포로 mean=0, sd=1이다) 
(8) 표본추출 
(9) 날짜 


(10) 산점도 
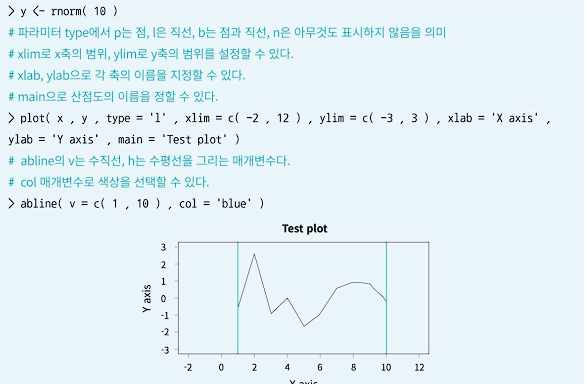
(11) 파일 읽기 쓰기 
(12) 기타 
