1) 로지스틱 회귀분석
(1) 로지스틱 회귀분석 개요
1. 로지스틱스 회귀분석
- 로지스틱 회귀분석은 회귀분석을 분류에 이용한 방법으로, 독립변수의 선형결합을 이용해 사건의 발생 가능성을 예측하는 분석방법으로 종속변수(y)가 범주형 변수일 때 사용 가능하다.
- 로지스틱 회귀분석은 종속변수가 바로 범주형 변수를 반환하지 않고 각 범주(집단)에 포함될 확률 값을 반환하여 분류한다. 예컨대 '어떤 사건이 발생할 확률과 발생하지 않을 확률'로 나누어서 예측한다.
- 로지스틱스 회귀분석의 변수⭐⭐⭐
- 일반적으로 로지스틱 회귀분석은 종속변수가 속할 수 있는 집단이 주 개로 이진 분류가 기본이며, 세 개 이상의 집단을 분류하는 경우 이를 '다중 로지스틱 회귀분석'이라 한다.
- 로지스틱 회귀분석은 독립변수가 연속형이면서 종속변수가 범주형일 때 가능하다. 만약 독립변수가 범주형일 경우에는 그 범주형 독립변수를 더미변수로 변환하면 가능하다.
- 로지스틱 회귀분석은 독립변수가 어떤 값을 가지든 상관없이 종속변수는 확률값을 가진다. 따라서 로지스틱 회귀분석의 종속변수는 항상 '0과 1'사이의 값을 가지는데, 이를 위해 '오즈(Odds), 로짓(Logit) 변환, 그리고 시그모이드 함수 같은 개념이 등장하게 된다.
(2) ⭐로지스틱 회귀분석의 알고리즘⭐
1. 오즈(Odds)
- 오즈란 성공할 확률이 실패할 확률의 몇 배인지를 나타내는 값이다. 로지스틱 회귀분석에 이 오즈를 사용하여 각 범주(집단)에 분류될 확률 값을 추정한다.
- 예를 들어, 제비를 뽑아 4번의 성공과 1번의 실패를 경험하였다면 오즈는 4다.
- 독립변수(x)가 주어졌을 때 성공확률은 P라고 하면 실패 확률은 1-P이다.

- 로짓변환
- 앞에서 오즈를 살펴보았는데, 오즈는 두 가지 한계를 지닌다. 하나는 음수를 가질 수 없다는 것이고 다른 하나는 확률값과 오즈의 그래프는 비대칭성을 띤다는 것이 그것이다.
- 그래서 이러한 한계를 극복하기 위해 오즈에 로그값을 취한 것이 바로 로짓(logit)이며, 이를 로짓 변환이라고 한다. 이를 표현한 공식은 다음과 같다.
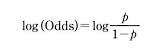
- 오즈의 범위가 무한대에서 확장되며 확률과 고짓값의 그래프는 성공확룔 0.5를 기준으로 대칭 형태를 띠게 된다.
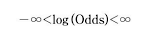
- 로짓변환을 이용한 로지스틱 회귀분석식은 다음과 같다.
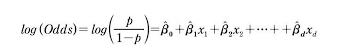
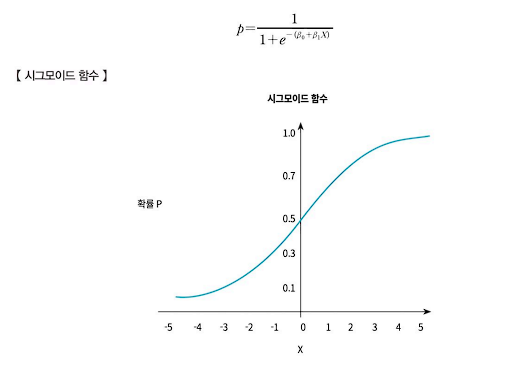
- 시그모이드 함수
- 시그모이드 함수는 로지스틱 회귀분석과 인공신경망 분석에서 활성화 함수로 활용되는 대표적임 함수 중 하나다. 시그모이드 함수는 로짓 함수와 역함수 관계이기 때문에 로짓함수를 통해 시그모이드 함수가 도출된다.
- 앞의 로지스틱 회귀분석식에서 결국 구하고자 하는 확률값이다. 어떤 사건이 발생할 추정 확률을 구한다면 그 사건이 발생할지 혹은 발생하지 않을지 예측이 가능하기 때문이다. 앞의 로지스틱 회귀분석식에서 확률 값을 중심으로 놓고 정리하면 다음과 같은 시그모이드 함수식을 정의할 수 있다.
(3) ⭐로지스틱 회귀분석 예시⭐
- R에 내장된 데이터인 iris를 활용하여 Species를 분류하고자 로지스틱 회귀분석을 시행해본다.




2) 의사결정나무
(1) 의사결정나무 개요
1. 의사결정나무
- 의사결정나무는 자료를 학습하여 특정 분리 규칙을 찾아내고, 그에 따라 몇 개의 소집단으로 분류하는 분석 방법이다. 상위 노드에서부터 하위 노드로 분류하는 과정이 나무가지와 유사한 구조로 나타나며, 의사결정이 진행되는 방식을 한눈에 볼 수 있다.
- 따라서 데이터의 어떤 기준을 바탕으로 분류 기준값을 정의하는지가 알고리즘의 성능에 큰 영향을 미친다. 올바른 분류를 위해서는 상위 노드에서 하위 노드로 갈수록 집단 내에서는 동질성이, 집단간에는 일징성이 커져야 한다.
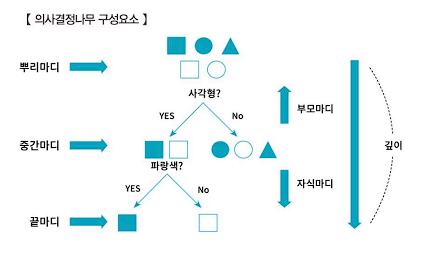
- 의사결정나무 구성요소
- 의사결정나무는 종속변수가 연속형인 회귀트리와 종속변수가 이산형인 분류트리로 구분된다.
- 의사걸졍너무 그림과 같이 상위노드에서 하위노드로 가면서 집단이 분류된다.

- 의사결정나무의 활용
- 세분화 : 비슷한 특성을 가진 그룹별로 분할
- 분류 : 종속변수의 범주를 몇 개의 등급으로 분류
- 예측 : 데이터들로부터 규칙을 찾아내어 이를 예측에 활용
- 차원 축소 및 변수 선택 : 여러 개의 독립변수들 중에서 종속변수에 큰 영향을 끼치는 변수를 선택
- 교호작용 : 여러 개의 독립변수들을 결합하여 종속변수에 작용하는 규칙을 파악 / 범주형변수를 병합 또는 연속형 변수를 몇 개의 등급으로 이산화
- ⭐의사결정나무의 특징⭐

(2) ⭐의사결정나무의 분석 과정⭐ 
1. 성장
- 성장 단계 : 분석 목적과 자료구조에 따라 적절한 분리 기준과 정지 규칙을 설정해 의사결정나무를 성장시키는 단계다. 각 마디에서 최적의 분리 규칙을 찾아 의사결정나무를 형성하고 적절한 정지 규칙을 만족하면 나무의 성장을 중단한다. 최적의 분할은 불순도 감소량을 가장 크게 하는 분할이다.
- 분리기준 : 의사결정나무는 데이터를 분류하는 방법으로 불순도를 사용한다. 불순도는 자료들의 범주가 한 그룹 안에 얼마나 섞여 있는지를 나타내는 측도로서 분류가 잘 되어 하나의 범주로만 구성되어 있으면 불순도 값은 작도, 다양한 범주의 데이터로 구성되어 있으면 불순도 값은 크다.
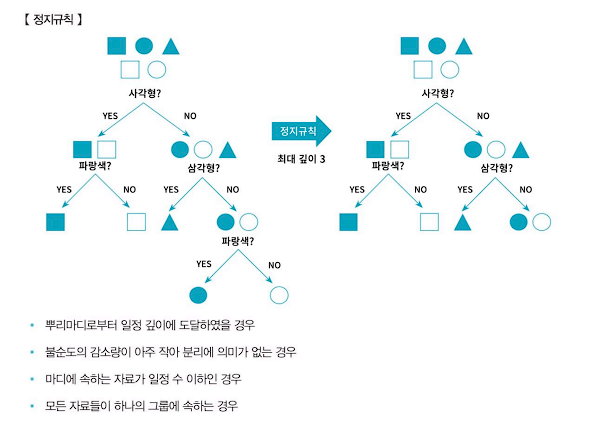
- 정지규칙 : 의사결정나무가 너무 많은 분리 기준을 보유하고 있으면 해석상의 어려움이 발생한다. 따라서 분석자가 설정한 특정 조건하에 현재의 마디에서 더 이상 분리가 일어나지 않고 현재의 마디가 끝마디가 되도록 정지시킨다.


- 가지치기
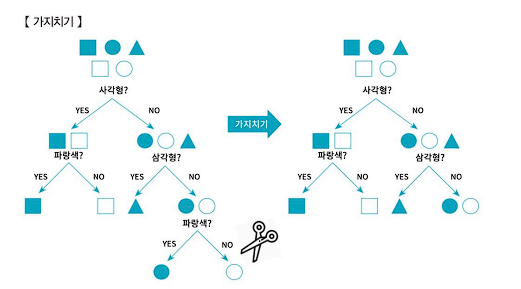
- 의사결정나무도 데이터 마이닝 기법 중 하나로 모형이 복잡한 경우 과적합이, 너무 단순한 경우 과소적합이 발생한다. 의사결정나무의 성장이 끝났지만 모형이 너무 복잡한 경우 과적합이 발생할 수 있어 일부 가지를 적당히 제거하여 적당한 크기의 완성된 의사결정나무 모형으로 만들어준다.
- 타당성 평가
- 형성된 의사결정나무를 평가하는 단계다. 검증용 데이터를 이용해 모델의 예측 정확도를 평가하거나 이익 도표 등의 평가 지표를 이용해 의사결정나무를 평가한다.
- 해석 및 예측
- 구축된 의사결정나무를 예측에 적용하고 이를 해석하는 단계다.
(3) ⭐의사결정나무 예시⭐
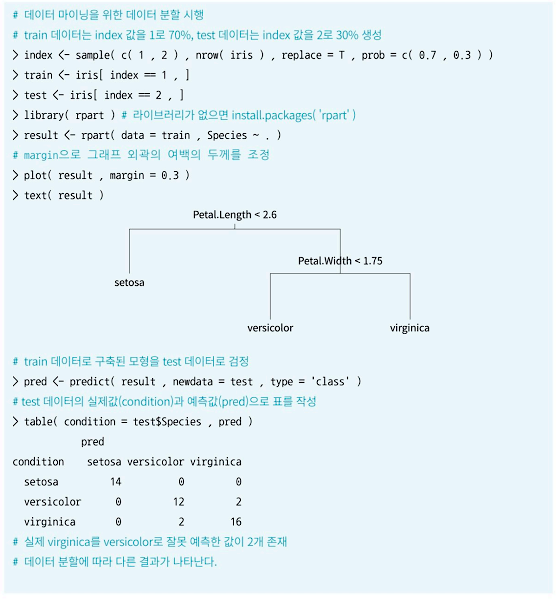
- R의 내장 데이터 iris를 사용하여 의사결정나무를 실습해본다.

3) 앙상블 분석
(1) 앙상블 분석 개요
- 앙살븐(ensemble)은 프랑스어로 '함께', '동시에'라는 의미로 음악에서는 1인 이상의 가창이나 연주, 소규모 인원의 합주를 의미한다. 데이터 마이닝에서는 여러 개의 모형을 생성 및 조합하여 예측력이 높은 모형을 만드는 것을 의미한다.
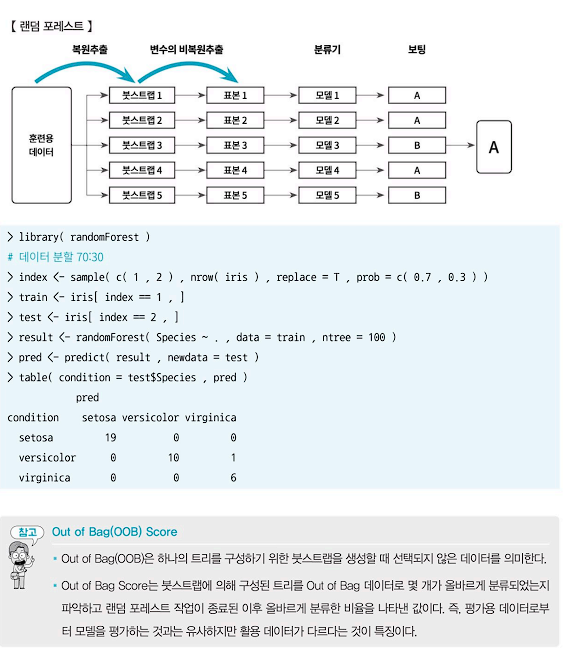
- 앙상블 분석은 결국 모형의 예측력을 높이고자 여러 번의 데이터 분할을 통하여 구축된 다수의 모형을 결합하여 새로운 모형을 만드는 방법이다. 앙상블 분석의 대표적인 방법으로 배깅(bagging), 부스팅(boosting), 랜덤 포레스트(random forest)가 있다.
- 각각의 예측모형에서 독립적으로 산출된 결과를 종합하여 예측의 정확도를 향상시킬 수 있다. 종속 변수의 형태에 따라 회구분석과 분류 분석에 모두 적용할 수 있다.
- 결과가 수치형 데이터인 경우에는 값들의 평균을 통해 최종 결과를 예측하고, 결과가 범주형 데이터인 경우에는 다수결 방식으로 최종 결과를 예측한다.
(2) ⭐앙상블 분석의 종류⭐
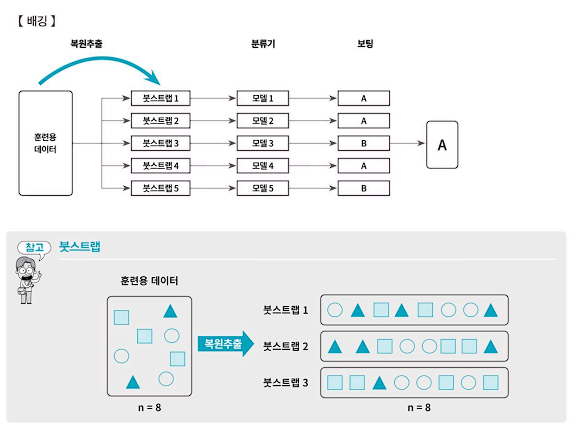
1. 배깅
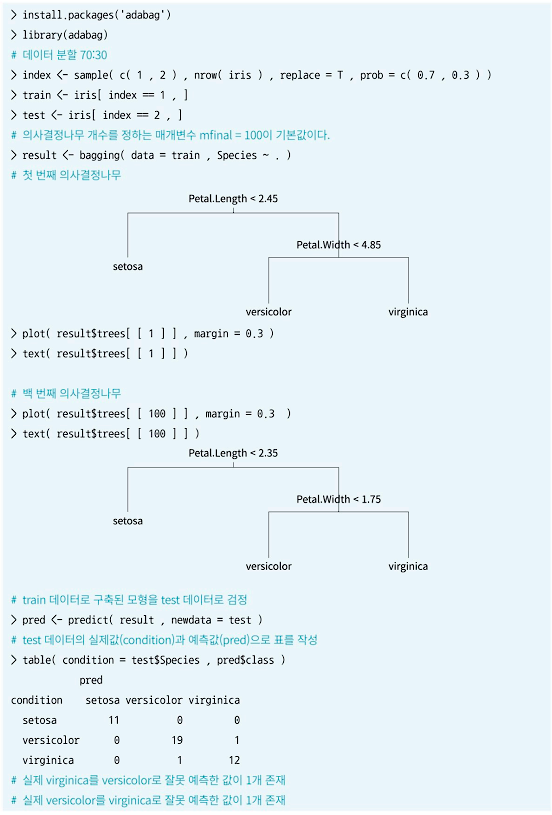
- 배깅은 Bootstrap Aggregating의 줄임말로 여러 개의 붓스트랩(Bootstrap)을 집계하는 알고리즘이다.
- 붓스트랩이란 원본 데이터와 같은 크기의 표본을 랜덤복원추출한 샘플 데이터를 의미하며, 특히 모델 구축을 위한 훈련용(train) 데이터를 가리킨다. 복원추출이기 때문에 하나의 붓스트랩에는 같은 데이터가 여러 번 추출될 수도 있지만, 그렇지 않을 수도 있다.
- 앙상블 분석에서 각각의 모델을 분류기(classfier)라고 부르며, 흔히 의사결정나무를 사용한다. 여러 개의 분류기에 의한 결과를 놓고 다수결에 의하여 최종 결괏값을 선정하는 작업을 보팅(voting)이라 한다.
- 분석을 위한 데이터 모집단의 분포를 현실적으로 알 수 없다. 그러나 하나의 붓스트랩을 구성할 때 원본 데이터로부터 복원추출을 진행하기 때문에 붓스트랩은 알 수 없던 모집단의 특성을 더 잘 반영할 수 있다. 배깅은 모집단의 특성이 잘 반영되는 분산이 작고 좋은 예측력을 보여준다.

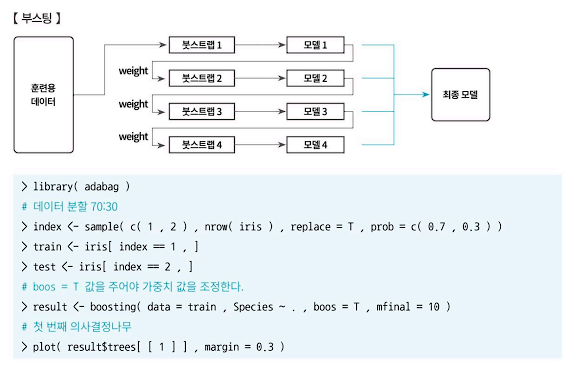
- 부스팅
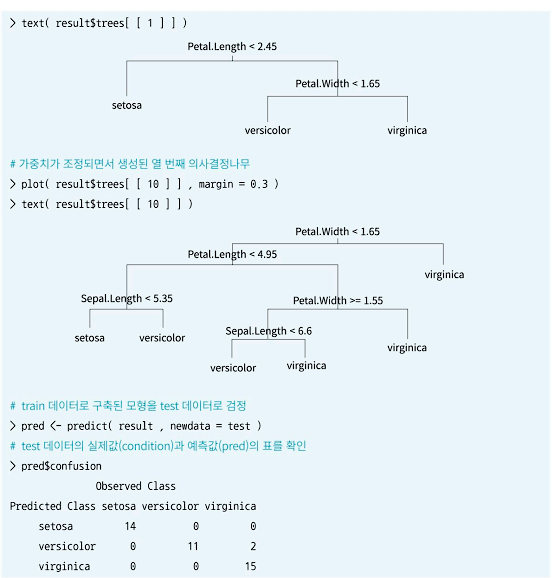
- 부스팅은 여러 개의 모형을 구축한다는 점에서 배깅과 유사하지만, 배깅은 각 분류기(모델)가 독립적인 데 반해, 부스팅은 독립적이지 않다.
- 부스팅은 이전 모델을 구축한 뒤 다음 모델을 구축할 때 이전 분류기에 의해 잘못 분류된 데이터에 더 큰 가중치를 주어 붓스트랩을 구성한다. 따라서 약한 모델들을 결합하여 나감으로써 점차적으로 강한 분류기를 만들어 나가는 과정이다.
- 대표적인 부스팅 방법으로 에이다부스팅(AdaBoosting)이 있으며, 그 밖에 Gradient Boost, XGBoost, Light GBM 등이 있다.
- 붓스트랩을 재구성하는 과정에서 잘못 분류된 데이터에 더 큰 가중치를 주어 표본을 추출하기 때문에 훈련오차를 빠르게 줄일 수 있다. 예측 성능 또한 배깅보다 성능이 뛰어나다고 할 수 있다.
- 랜덤 포레스트
- 랜덤 포레스트(Random Forest)는 서로 상관성이 없는 나무들로 이루어진 숲을 의미한다. 방법은 배깅과 유사하나 배깅에 더 많은 무작위성을 주는 분석 기법이다.
- 많은 무작위성으로 생성된 서로 다른 여러 개의 트리로 구성되어 있기 때문에 포레스트(Forest, 숲)라 명명되었으며, 여러 개의 약한 트리들의 선형 결합으로 최정 결과를 얻는 모델이다.
- 분류의 경우에는 다수결로 최종 결과를 구하지만 회귀의 경우네느 평균 또는 중앙값을 구하는 방법을 사용한다.
- 배깅에서는 각 붓스트랩을 활용하여 트리를 구성할 때 트리의 모든 마디가 불순도가 제일 작아지는 최적의 분할을 실시한다. 그러나 랜덤 포레스트는 각 마디에서 최적의 분할이 아닌 표본추출 과정이 한 번 더 반복되어 추출된 표본을 대상으로 최적의 분할을 실시한다.
- 따라서 랜덤 포레스트는 큰 분산을 갖고 있다는 의사결정나무의 단점을 보완하여 분산을 감소시키고 모든 분류기들이 높은 비상관성을 갖기 때문에 일반화의 성능을 향상시킬 수 있다. 또한 의사결정나무의 특징을 물려받아 이상값에 민감하지 않다는 장점이 있다.
- 인공신경망 분석
(1) 인공신경망 개요
- 인공신경망은 인간의 뇌를 모방하여 만들어진 학습 및 추론 모형이다.
- 인간의 뇌는 여러 시냅스의 결합으로 신호를 전달받아 일정 기준치를 초과할 때 뉴런이 활성화되고 출력 신호를 내보낸다. 뉴런과 뉴런 사이는 시냅스로 연결되어 있는데, 입력신호가 다른 뉴런으로 전달되기 위해서는 신호의 강도가 일정 기준치를 초과해야 한다. 인공신경망 분석은 이러한 뇌의 구조를 수학적으로 단순화해 모델링한 것이다.
- 인공신경망 분석에서 값이 입력되면 개별 신호의 정도에 따라 값이 가중된다. 가중된 값에 평향(bias)이라는 상수를 더한 후 활성함수를 거치면 인공신경망의 출력값이 생성된다.
- 인공신경망의 등장과 발전으로 인하여 머신러닝(Machine Learning)을 넘어서서 딥러닝(Deep Learning)이 등장했으며, 현재의 CNN, RNN등과 같은 다양한 알고리즘의 기반을 마련했다.

(2) 인공신경망의 알고리즘

1. ⭐활성함수⭐
- 인공신경망은 노드에 입력되는 값을 바로 다음 노드로 전달하지 않고 비선형 함수에 통과시킨 후 전달한다. 이때 사용되는 비선형함수를 활성함수라고 한다.
- 어떤 활성함수를 사용하느냐에 따라 그 출력값이 달라지므로 적절한 활성함수를 사용하는 것이 중요하다. 대표적인 활성함수로는 시그모이드 함수, 소프트맥스 함수, ReLU함수 등이 있다.
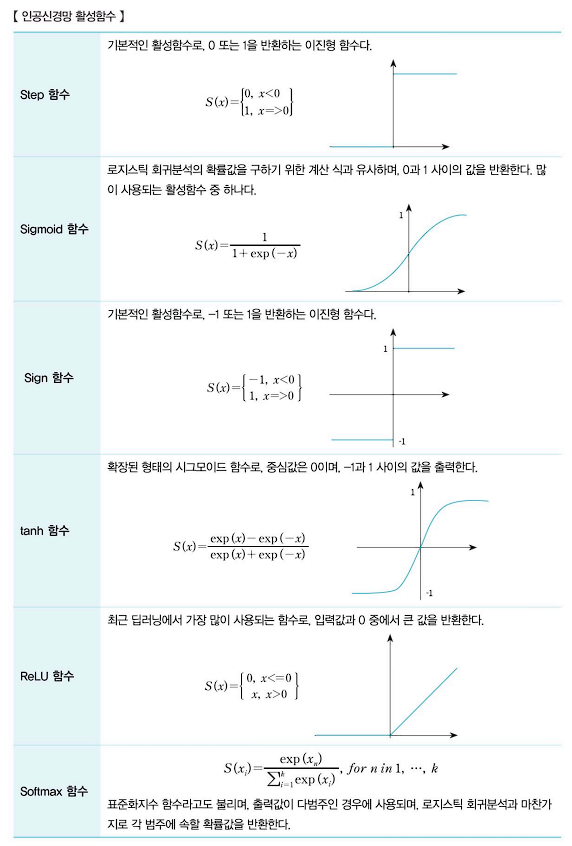
- ⭐인공신경망의 계층구조⭐
- 하나의 인공신경망은 데이터를 입력하는 입력층, 데이터를 출력하는 출력층을 갖고 있는 단층신경망과 입력층과 출력층 사이에 보이지 않는 다수의 은닉층을 가지고 있을 수 있는 다층신경망으로 구분할 수 있다. 은닉층이 존재하지 않는 단층신경망은 한계점이 있기에 일반적인 인공신경망은 다층신경망을 의미한다.
- 입력층은 데이터를 입력받아 시스템으로 전송하는 역할을 한다. 은닉층은 신경망 외부에서는 은닉층의 노드에 직접 접근할 수 없도록 숨겨진, 말 그대로 은닉한 층이다. 은닉층은 입력층으로부터 값을 전달받아 가중치를 계산한 후 활성함수에 적용하여 결과를 산출하고 이를 출력층으로 보낸다. 출력층은 학습된 데이터가 포함된 층으로, 활성함수의 결과를 담고 있는 노드로 구성된다. 출력층의 노드 수는 출력 범주의 수로 결정된다. 분류 문제일 경우 출력층의 노드는 각 라벨의 학률을 포함한다.
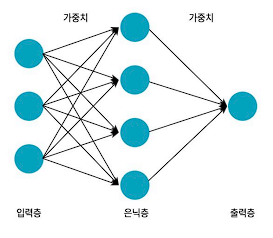
- 인공신경망 학습(역전파 알고리즘)
- 인공신경망은 여러 개의 퍼셉트론으로 구성되어 있기 때문에 각 퍼셉트론이 보유한 여러 개의 가중치 wi값의 결정이 중요하다. 인공신경망은 지도학습의 한 종류로 입력층(독립변수)가 출력층(반응변수)의 데이터에 따른 이상적인 가중치 wi값을 결정해야 한다.
- 가중치 값의 결정은 입력층에서 출력층으로 찾아 나가는 순전파 알고리즘을 먼저 활용한다. 이때 발생한 오차들을 줄이고자 출력층에서는 입력층 방향으로 거꾸로 찾아 나가는 역전파 알고리즘을 활용하여 가중치 값들을 새롭게 조정한다. 훈련용(train) 데이터의 자료들이 순차적으로 입력될 때마다 가중치가 새롭게 조정되는 것을 인공신경망이 학습한다고 표현한다. 이때 전체 자료들에 의하여 학습이 한 번 되는 것을 1 epoch라 하면 일정 수의 epoch에 도달하거나 혹은 원하는 수준의 정확도를 얻을 때까지 위 작업을 반복한다.
(3) ⭐인공신경망의 종류⭐
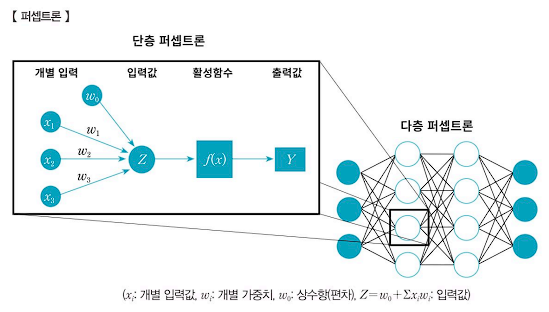
1. 단층 퍼셉트론(단층 신경망)
- 단층 신경망이라고도 하며 입력층이 은닉층을 거치지 않고 바로 출력층과 연결된다.
- 퍼셉트론은 여러 개의 개별 입력 데이터를 받아 하나의 입력 데이터로 가공하여 활성함수에 의하여 출력값을 결정한다. 퍼셉트론의 출력값은 또 다른 퍼셉트론의 입력 데이터가 된다.
- 단층 퍼셉트론은 다수의 입력값을 받아 하나의 출력값을 출력하는데, 이 출력값이 정해진 임곗값을 넘었을 경우 1을 출력하고 넘지 못했을 경우에는 0을 출력한다.
- 다층 퍼셉트론(다층 신경망)
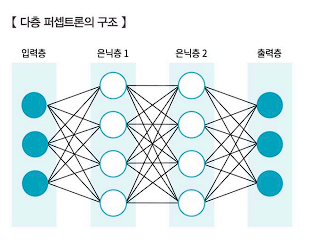
- 하나의 퍼셉트론은 데이터를 입력하는 입력층, 데이터를 출력하는 출력층을 갖고 있는 단층 퍼셉트론과 입력층과 술력층 사이에 보이지 않는 다수의 은닉층을 가지고 있을 수도 있는 다층 퍼셉트론으로 구분할 수 있다. 은닉층이 존재하지 않는 단층 퍼셉트론은 한계점이 있기에 일반적으로 인공신경망을 부를 때 다층 퍼셉트론을 의미한다.
- 다층 퍼셉트론은 단층 퍼셉트론보다 학습하기가 어려우며 은닉층의 노드의 수가 너무 적으면 복잡한 의사결정 경계를 구축할 수 없고, 은닉층의 노드의 수가 너무 많으면 일반화가 어렵기 때문에 과적합 문제를 발생하며, 너무 적은 은닉층과 은닉노드의 과소적합 문제가 발생하기 때문에 적절한 노드 수를 찾는 것이 중요하다.
(4) 인공신경망 예시
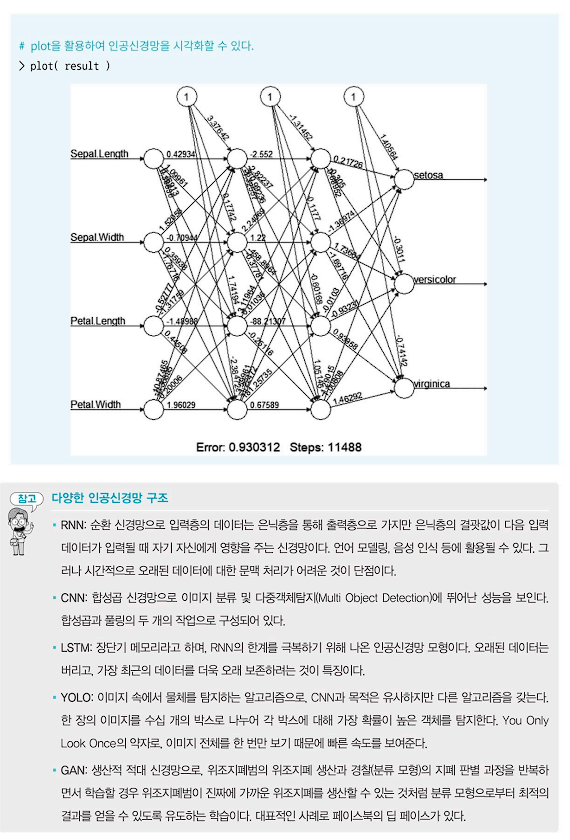
- R의 내장 데이터인 iris를 사용하여 인공신경망을 활용해본다.


5) 나이브베이즈 분류
(1) 베이즈 이론(Bayes Theorem)
1. 베이즈 이론(베이지안 확률)
- 베이즈 이론은 확률을 해석하는 이론이다. 통계학에서 확률은 크게 빈도 확률과 베이지안 확률로 구분할 수 있다. 이 둘의 계산 방법은 크게 다르지 않지만 해석하는 방법에서 차이가 나는데, 빈도 확률은 객관적으로 확률을 해석하고 베이지안 확률은 주관적으로 확률을 해석한다.
- 빈도 확률이란 사건이 발생한 횟수의 장기적인 비율을 의미한다. 빈도 확률은 근복적으로 반복되는 어떤 사건의 빈도를 다루는 것으로, 모집단으로부터 반복적으로 표본을 추출했을 때 추출된 표본이 사건 A에 포함되는 경향을 사건 A의 확률이라 한다.
- 이에 반해 베이지안 확률은 사전확률과 우도확률을 통해 사후확률을 추정하는 정리로, 데이터를 통해 확률을 추정할 때 현재 관측된 데이터의 빈도만으로 분석하는 것이 아니라 분석자의 사전지식(이미 알려진 사실 혹은 분석자의 주관)까지 포함해 분석하는 방법이다.
- 베이즈 정리에서 확률은 '주장 혹은 믿음의 신뢰도'로 나타난다. 통계학 책에 따라서는 베이즈 이론을 '두 확률변수의 사전 확률과 사후 확률 사이의 관계를 나타내는 정리'라고 정의하기도 한다.
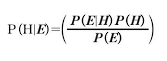
(2) 나이브 베이즈 분류
1. 나이브 베이즈 개념
- 나이브 베이즈 분류 모델은 베이즈 정리를 기반으로 한 지도학습 모델로, 스팸 메일 필터링, 텍스트 분류 등에 사용할 수 있다.
- 나이브 베이즈는 데이터의 모든 특징 변수가 서로 동등하고 독립적이라는 가정하에 분류를 실행한다. 질환 유무를 분류할 수 있게 해주는 특성들은 나이브 베이즈 분류기에서 서로 연관성이 없고, 각각의 특성이 질환의 유무에 독립적으로 기여하는 것으로 간주한다.
- 나이브 베이즈 알고리즘
- 나이브 베이즈 알고리즘은 이진 분류 데이터가 주어졌을 때 베이즈 이론을 통해 범주 a, b가 될 확률을 구하고, 더 큰 확률값이 나오는 범주에 데이터를 할당하는 알고리즘이다. 범주 a b에 속할 확률은 다음과 같다.
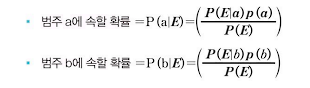
- P(a)와 P(b)는 사전확률로, 범주 a와 b에 해당하는 레코드를 전체 레코드로 나눈 비율을 의미한다. P(E)는 두 수식에 겹쳐 나오므로 생략하고 계산할 수 있으며, 데이터가 변수 v1, v2, v3로 구성되어 있다면 다음과 같이 표현할 수 있다.
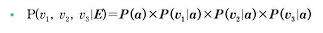
6) k-NN 알고리즘
(1) k-NN(k-Nearest Neighbor)알고리즘의 개요
- 'k-NN(k-Nearest Neighbor)'은 'k-최근접이웃'으로도 불리는 분류 알고리즘의 하나다. k-NN은 지도학습인 분류 분석에 속하지만 실은 군집의 특성도 가지고 있어 책에 따라서는 Semi(준)-지도학습으로 분류하기도 한다.
- k-NN은 정답 라벨이 있는 데이터들 속에서 정답 라벨이 없는 데이터들을 어떻게 분류할 것인지에 대한 해결방법으로 사용된다. 간단히 말해서, 정답 라벨이 없는 자신의 데이터를 분류하기 위해 정답 라벨이 있는 주변의 데이터들을 분석해서 가장 가까이에 있는 데이터의 라벨을 확인하는 것이다.
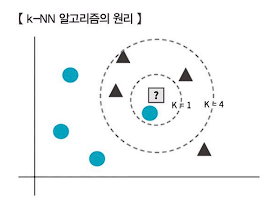
(2) k-NN 알고리즘의 원리⭐⭐
- k-NN은 정답 라벨이 없는 새로운 데이터를 입력 받았을 때 그 데이터로부터 가장 가까이에 있는 데이터의 정답 라벨을 확인하여 새로운 데이터의 정답 라벨을 결정한다.
- 아래의 그림을 보면 이해하기 쉬울 것이다. 네모칸 물음표 데이터 주변에 가장 가까이에 있는 데이터를 보면 가장 가까운 데이터의 정답 라벨은 파란색 동그라미다. 여기서 k는 주변 데이터 수를 의미하는데, k를 '4'로 확장시켜 보면 검정색 세모가 더 많이 보인다. 그럼 이 데이터는 파란 동그라미인가? 검정색 세모인가? 결국 k값을 어떻게 정하는 게 좋을 것인가 하는 문제가 생긴다.
- 결국 k-NN은 k값을 어떻게 정하는지가 관건이다. 일반적으로는 최적의 k값을 찾기 위해 총 데이터들의 제곱근 값을 사용한다.
- k-NN은 함수가 오직 지역적으로 근사하고 모든 계산이 분류될 때까지 연기되는 인스턴스 기반 학습이다. 그래서 통계학에서 '게으른 학습'이라고도 부른다. 또 k-NN 알고리즘은 가장 간단한 기계학습 알고리즘이기도 하다.
7) 서포트벡터머신

(1) 서포트벡터머신의 개요
- 서포트벡터머신(SVM:Support Vector Machine)은 지도학습에 주로 이용되며 특히 분류 성능이 뛰어나 분류 분석에 자주 사용된다.
- 서포트벡터머신은 초평면(hyper-plane)을 이용하여 카테고리를 나누어 비확률적 이진 선형모델을 만든다.
(2) 서포트벡터머신(SVM) 알고리즘
- 서포트벡터머신은 분류할 때 가장 높은 마진을 가져가는 방향으로 분류한다. 마진이 크면 클수록 학습에 사용하지 않는 데이터가 들어오더라도 분류를 잘 할 가능성이 높기 때문이다. 그래서 분류 분석에서 예측력이 높다.
- 일반적으로 서포트벡터머신은 분류 또는 회귀분석에 사용 가능한 초평면 또는 초평면들의 집합으로 구성되어 있다. 초평면이 가장 가까운 데이터와 큰 차이를 가진다면 오차가 작아지기 때문에 좋은 분류를 위해서는 어떤 분류된 점에 대해서 가장 가까운 학습 데이터와 가장 먼 거리를 가지는 초평면을 찾아야 한다.
- 초평면 f(x)는 wTx+b=0으로 나타낼 수 있다.
8)⭐분류 모형 성과 평가⭐
(1) 성과 평가 개요
- 지금까지 다양한 분류 분석 기법들을 알아보았다. 여러 분류 기법들을 적용해보고 여러 모델 중 가장 예측력이 좋은 모델을 최종 모델로 선정하기 위해서는 평가 기준이 필요하다.
- 모형 평가의 기준으로는 다른 데이터에서도 안정적으로 적용이 가능한지 판단하는 일반화, 모형의 계산 양에 비한 모형의 성능을 고려하는 효율성, 구축된 모형의 분류 정확도 등의 기준이 있다.
- 여기서는 컨퓨전캐트릭스(Confusion Matrix, 혼동행렬)라고도 불리는 오분류표, ROC 커브, 이익도표, 향상도곡선 등에 대해 알아보기로 한다.

(2) 오분류표와 평가 지표⭐⭐⭐

- 분류 분석 성과 평가는 간단히 말해서 분류 분석 모형이 내놓은 답과 실제 정답이 어느 정도 일치하는지를 판단하는 것이다. 일반적으로 정답과 예측값은 True와 False, 0과 1, 양성과 음성, Yes와 No 등의 이진 분류 클래스 레이블을 갖는다.
- 분류 분석 후 예측한 값과 실제 값을 차이를 교차표(Cross Table) 형태로 정리한 것을 오분류표 혹은 컨퓨전매트릭스(Confusion Matrix, 혼동행렬)라고 부른다.
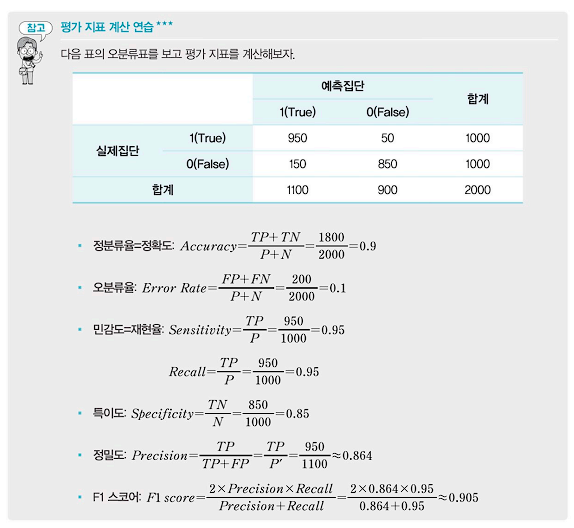
- 오분류표는 실제값과 예측치의 값에 대한 옳고 그름을 표로 나타낸 것으로, 분류오차의 정확한 추정치를 얻기 위해서 평가용(test) 데이터로부터 계산되어 얻은 표다. 훈련용(train) 데이터를 활용한 오분류표는 과적합의 위험성이 존재하기 때문이다. 아래의 표에서 실제집단과 예측집단의 위치를 헷갈리지 않도록 주의하자.


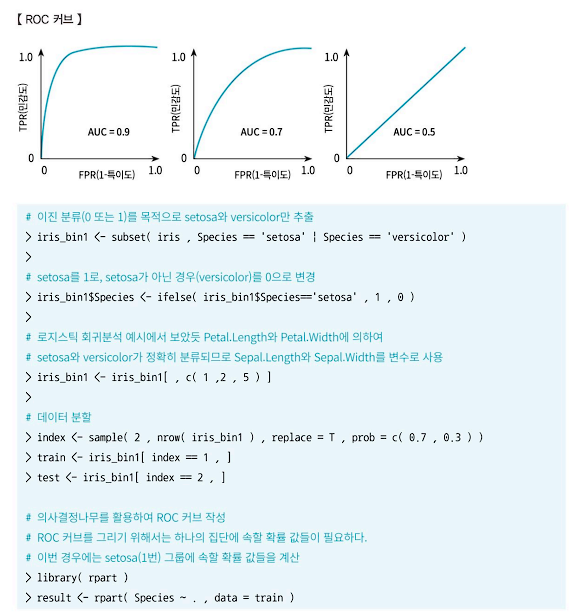
(3) ⭐ROC 커브⭐
- ROC 커브(Receiver Operating Characteristic Curve)는 분류 분석 모형의 평가를 쉽게 비교할 수 있도록 시각화한 그래프다.
- x축은 FPR(1-xmrdleh)값을, y축은 TPR(민감도)값을 갖는 그래프다. 이진 분류(0또는 1) 모형의 성능을 평가하기 위해 사용된다.
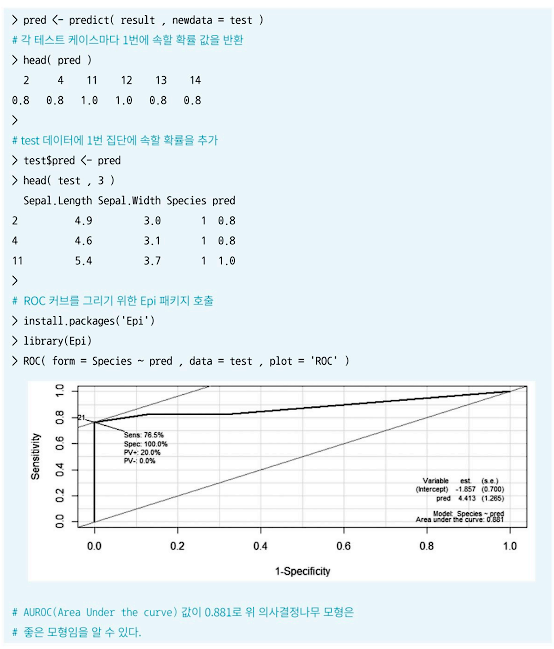
- ROC 커브의 아래 면적을 나타내는 'AUROC(Area Under ROC)'의 값이 1에 가까울수록 모형의 성능이 우수하며, 0.5에 가까울수록 무작위로 예측하는 랜덤 모델에 가까운 좋지 못한 모형이다.
(4) ⭐이익도표(Lift Chart)⭐
- 이익도표(Lift Chart), 이득곡선(Gain Curve) 혹은 이득도표(Gain Chart)라고도 하며 모델의 성능을 판단하기 위해 작성한 표다.
- 목표범주(위 예제에서 setosa, 1번 그룹)에 속할 확률을 내림차순으로 정렬하여 몇 개의 구간으로 나누어 각 구간에서의 성능을 판단하고 랜덤 모델보다 얼마나 더 뛰어난 성능을 보이는지를 판단한다.
- 일반적으로 '0.5'에서 cut-off하며, '1.0'이 가장 높은 기준이 된다.
- 예를 들어, 다음의 이익도표를 살펴보자.
- 200개의 자료 중 40개가 그룹1에 속해 있는 평가용(test) 데이터셋이 있을 때 구축된 모형으로 200개 각각의 자료에 대해 그룹12에 속할 확률을 구하고 내림차순으로 정렬한 후 구간을 나누었다. 그리고 이익도표를 그려보았다.

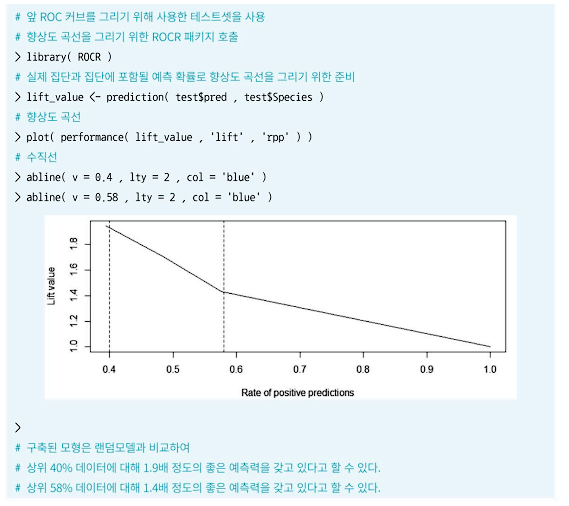
(5) 향상도 곡선(Lift Curve)⭐
- 랜덤 모델과 비교하여 해당 모델의 성과가 얼마나 향상되었는지 구간별로 파악하기 위한 그래프다. 좋은 모델일수록 큰 값에서 시작하여 급격히 감소한다.

뭐든 열심히