
이 글은 "초보를 위한 쿠버네티스 안내서"를 바탕으로 쓰여진 글 입니다.
쿠버네티스 클러스터의 구조
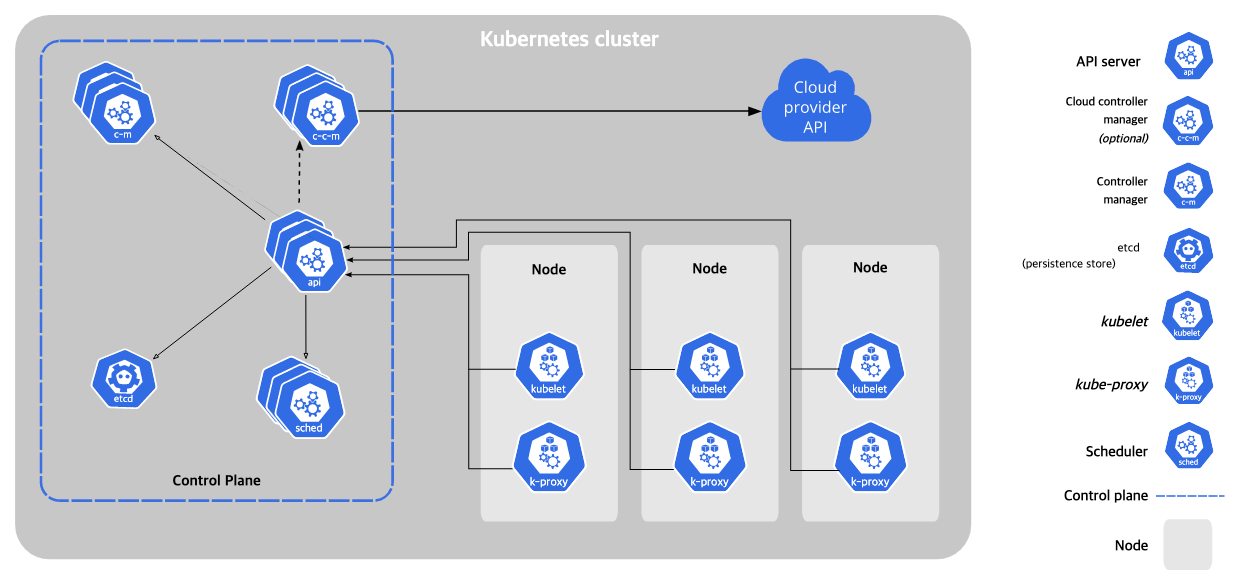
쿠버네티스는 끊임없이 Desired State와 Current State를 비교하여 현재 state를 원하는 state로 유지시킨다.
Master
체크하고 수정하는 부분
etcd
- 모든 상태와 데이터를 저장
- 분산 시스템으로 구성하여 안전성을 높임
- 가볍고 빠르면서 정확하게 설계
- key-value 형태로 저장
api-server
- 상태를 바꾸거나 조회
- etcd와 유일하게 통신하는 모듈
- REST API형태로 제공
- 권한을 체크하여 적절한 권한이 없을 경우 요청을 차단
- 관리자 요청 뿐 아니라 다양한 내부 모듈과 통신
- 수평으로 확장 되도록 디자인
Scheduler
- 새로 생성된 pod을 감지하고 실행할 노드를 선택
- 노드의 현재 상태와 pod의 요구사항을 체크
- 노드에 라벨 부여
Controller
- 논리적으로 다양한 컨트롤러가 존재
- 복제 컨트롤러
- 노드 컨트롤러
- 엔트포인트 컨트롤러
- 끊임없이 상태를 체크하고 원하는 상태를 유지
- 복잡성을 낮추기 위해 하나의 프로세스로 실행
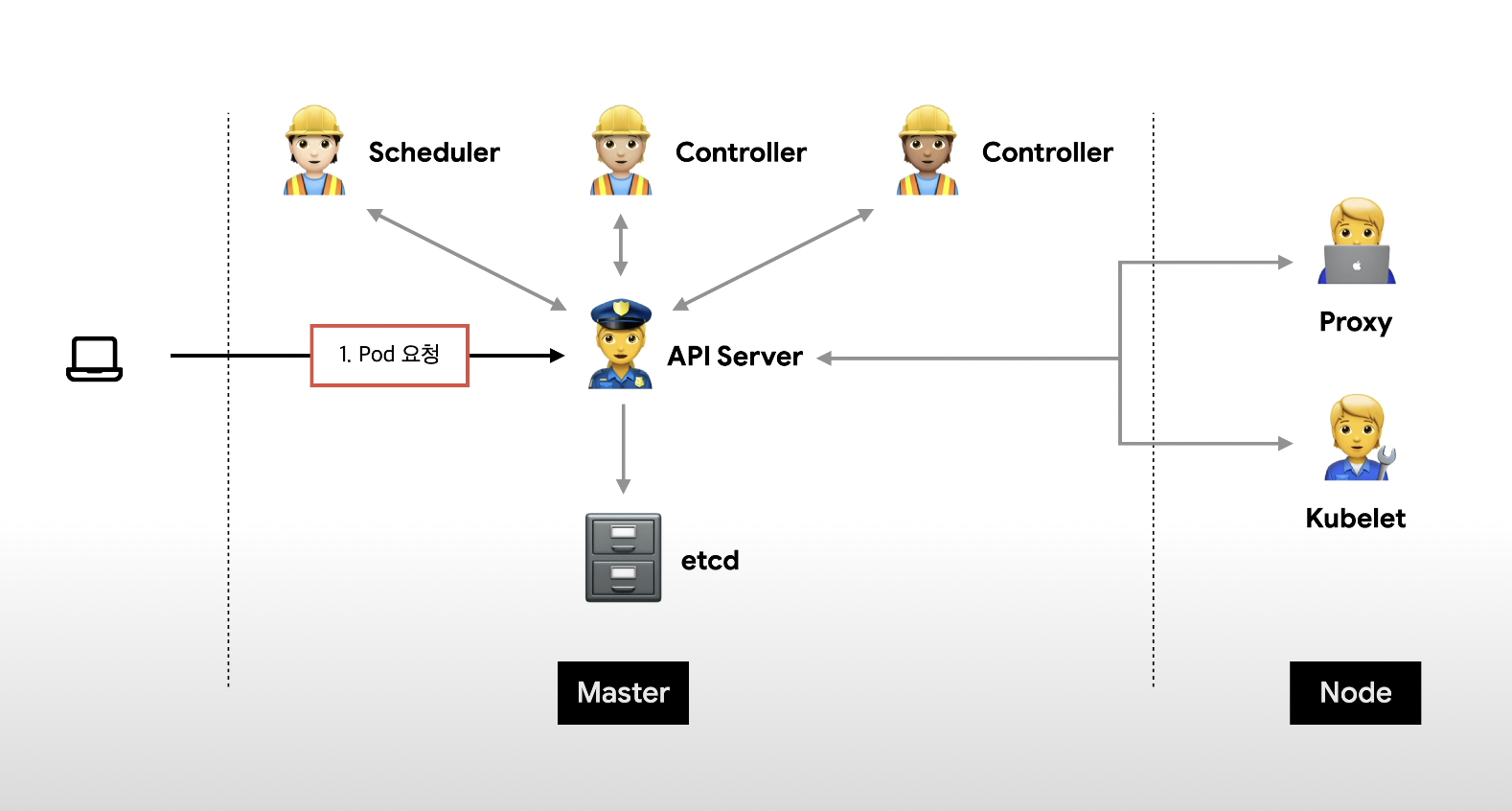
조회흐름
모든 과정은 api-server를 거치면서 진행이 된다.
컨트롤러 -> api server -> etcd -> api server -> controller -> api server -> etct
node
실제 컨테이너가 실행되는 부분
프록시
- 네트워크 프록시와 부하 분산 역할
- 성능상의 이유로 별도의 프록시 프로그램 대신 iptable 또는 IPVS를 사용
큐블릿
- 각 노드에서 실행
- pod를 실행/중지하고 상태를 체크
- CRI(Container Rumtime Interface)
- docker
- Containerd
- CRI-O
- ...
pod
- 가장 작은 배포단위
- 각 파드마다 고유한 ip를 부여받은
- 여러개의 컨테이너가 하나의 pod에 속할 수 있음
ReplicaSet
- 여러개의 pod을 관리
- 새로운 pod는 Templet을 참고하여 생성
- 신규 pod을 생성하거나 기존 pod을 제거하여 원하는 수를 유지
Deployment
- 배포 버전을 관리
- 내부적으로 ReplicaSet을 이용
그 밖에도...
데몬셋
- 모든노드에파드 하나씩만 띄우고 싶을 때 ex) 로그 수집
스테이트풀셋
- 순서대로 팟을 실행하거나 같은 볼륨을 재활용하고싶을때
Service
ClusterIP
- 클러스터 내부에서 사용하는 프록시
- pod는 동적이지만 서비스는 고유 ip를 가짐
- 클러스터 내부에서 서비스 연결은 DNS를 이용
nodeport
- 노드에 노출되어 외부에서 접근 가능한 서비스
- 모든 노드에 동일한 포트로 생성
loadBalancer
- 하나의 ip주소를 외부에 노출
ingress
- 도메인 또는 경로별 라우팅
- nginx, HAAProxy, ALB
일반적으로 팟만 띄우는 경우는 거의 없다.
디플로이나 서비스를 이용해서 팟을 생성하고 노드포트나 로드밸런서를 붙혀서 외부와 연결해서 사용한다.
API호출
원하는 상태를 다양한 오브젝트로 정의하고 서버에 yaml형식으로 전달
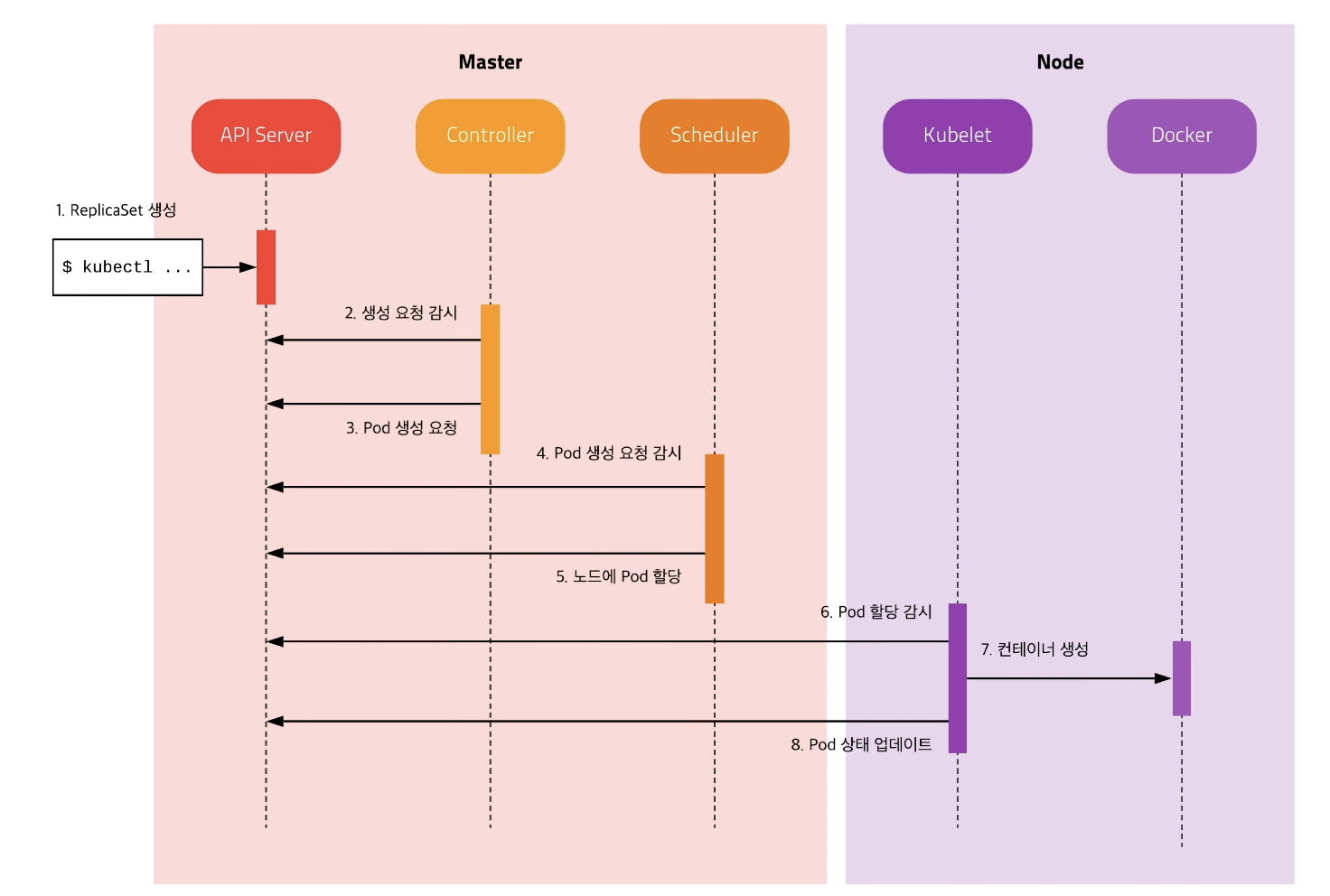
쿠버네티스가 실행되는 도식은 위와 같이 실행되게 된다.

Better Than Yesterday