
집계함수
COUNT
SELECT COUNT(*) FROM products;products 테이블안에 행(rows)의 갯수를 세어준다.
SELECT COUNT(DISTINCT name) FROM porducts;중복된 이름은 제외하고 count를 세어준다.
SUM
SELECT SUM(price) FROM products;
AVG
SELECT AVG(price) FROM products;이렇게만 하면 NULL값은 제외하고 평균값을 계산 하게 됨.
SELECT SUM(price)/COUNT(*) FROM products;NULL값까지 포함하고 평균값을 계산하게 된다.
MIN
SELECT MIN(price) FROM products;
MAX
SELECT MAX(price) FROM products;
전체 다 출력해보기
SELECT COUNT(price),SUM(price),AVG(price),MIN(price),MAX(price) FROM products;
GROUP BY
그룹을 지어 통계(SUM,AVG 등등)를 내고 싶을 때 사용한다.
SELECT supplierid,categoryid,AVG(price) FROM products GROUP BY supplierid,categoryid
HAVING
GROUP BY를 할 때 price가 100이 넘어가는 것만 보고 싶을 때
WHERE절을 사용하면 되지 않을까?
안된다!!
WHERE절은 GROUP BY 이전에 실행되기 때문에 그룹을 짓기 이전에 필터링을 걸어버린다!
그래서, GROUP BY의 필터링은 HAVING이 담당한다!!
SELECT supplierid, categoryid, AVG(price) FROM products GROUP BY supplierid,categoryid HAVING AVG(price) >100
CASE
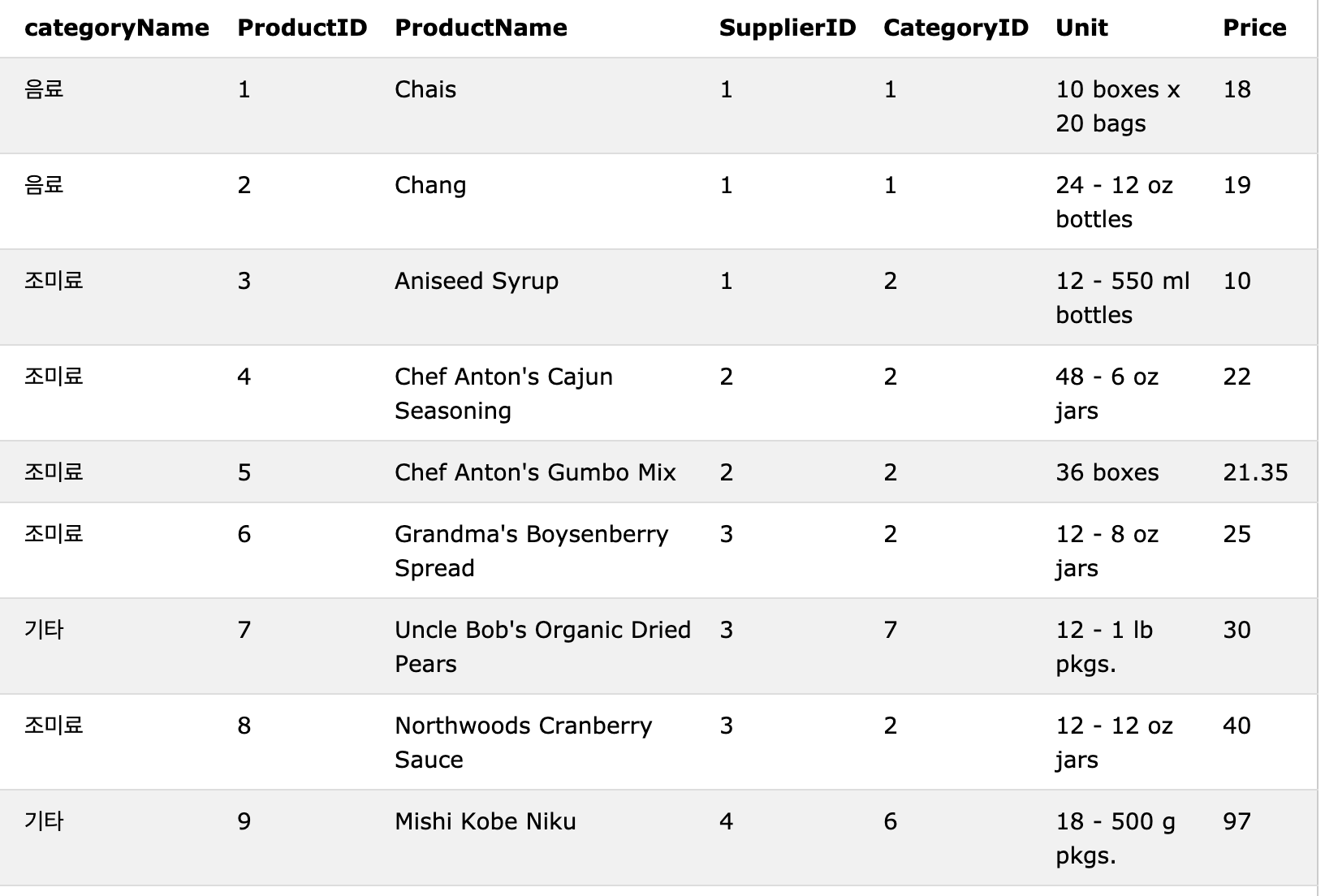
SELECT CASE WHEN categoryid=1 THEN '음료' WHEN categoryid=2 THEN '조미료' ELSE '기타' END AS 'categoryName',* FROM productscategoryid가 1이면 음료, 2이면 조미료,나머지는 기타로 처리 하는 열을 생성한다.

생각하는 개발자 되기