
현재 포스트는 이후에 습득한 지식으로 인해 내용이 추가, 수정, 삭제될 수 있음
0. 🔖 목차
- 🧶 쓰레드
1-1. 개념
1-2. 멀티 프로세싱과 멀티 쓰레딩 - 🤿 쓰레드 풀
2-1. 개념
2-2. 동시성과 병렬성
1. 🧶 쓰레드
1-1. 개념
쓰레드는 프로세스 내에서 실행되는 실행 단위이다.
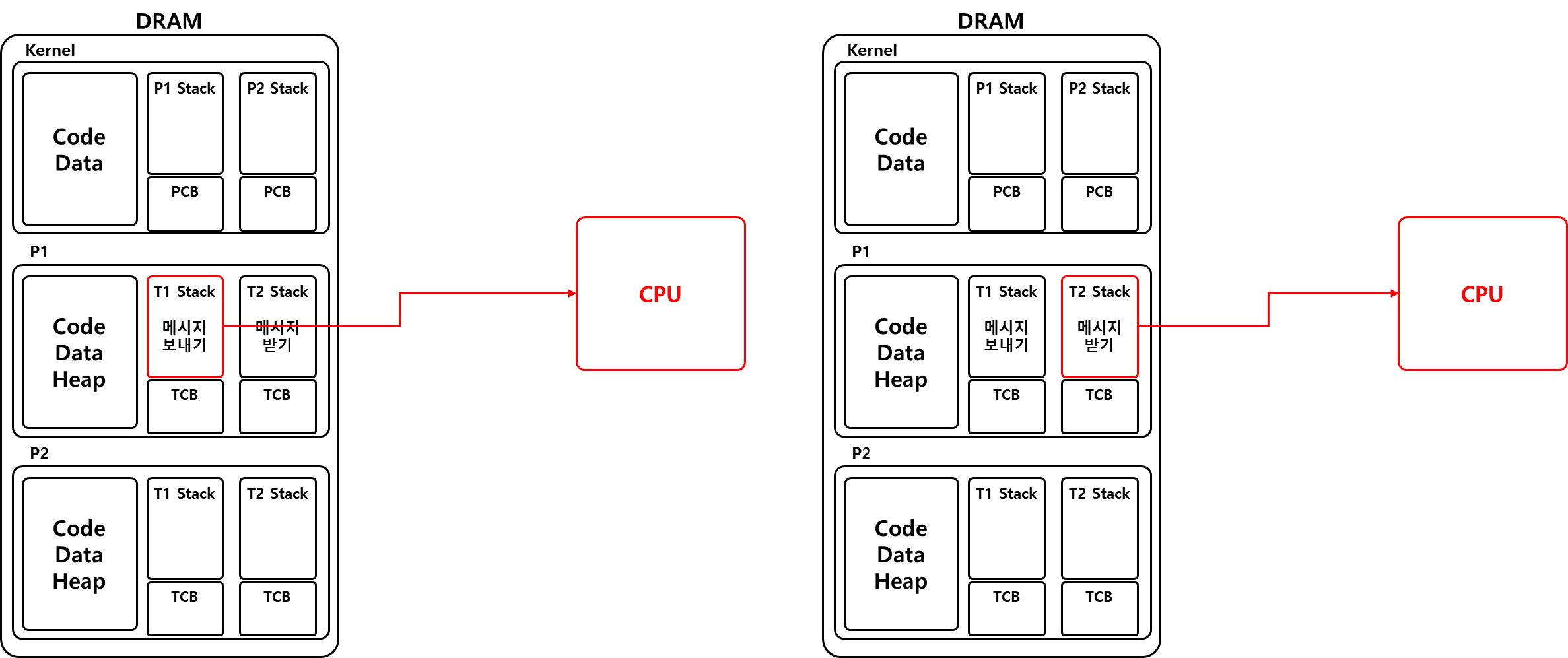
한 프로세스에서 여러 개의 쓰레드를 가질 수 있으며 각 쓰레드는 고유의 stack 영역과 PCB처럼 TCB를 가진다(한 프로세스는 무조건 하나 이상의 쓰레드를 가진다-> 메인 쓰레드).
이말은 즉 쓰레드들은 한 프로세스의 코드, 데이터, 힙 영역을 공유한다는 뜻이며 TCB를 통해 같은 프로세스의 작업을 여러 개 실행할 수 있다는 뜻이 된다.
카카오톡을 예로 들어보자.
카카오톡이라는 프로세스에 쓰레드가 없고 프로세스 자체가 하나의 작업 단위라면 메세지를 보내는 작업(A라고 하자)을 하다 인터럽트가 걸리고 메세지를 받는 작업(B라고 하자)을 수행했을 때 PCB에 A가 인터럽트 당하기 직전의 레지스터 정보들이 B의 레지스터 정보들로 덮어씌워질 것이다(스택도 마찬가지).
즉, 메세지를 보내는 작업을 처음부터 다시 해야한다. 이를 해결하려면 작업 단위마다 프로세스를 더 만들어야 하는데 이는 매우 비효율적이고 데이터 공유가 힘들다.
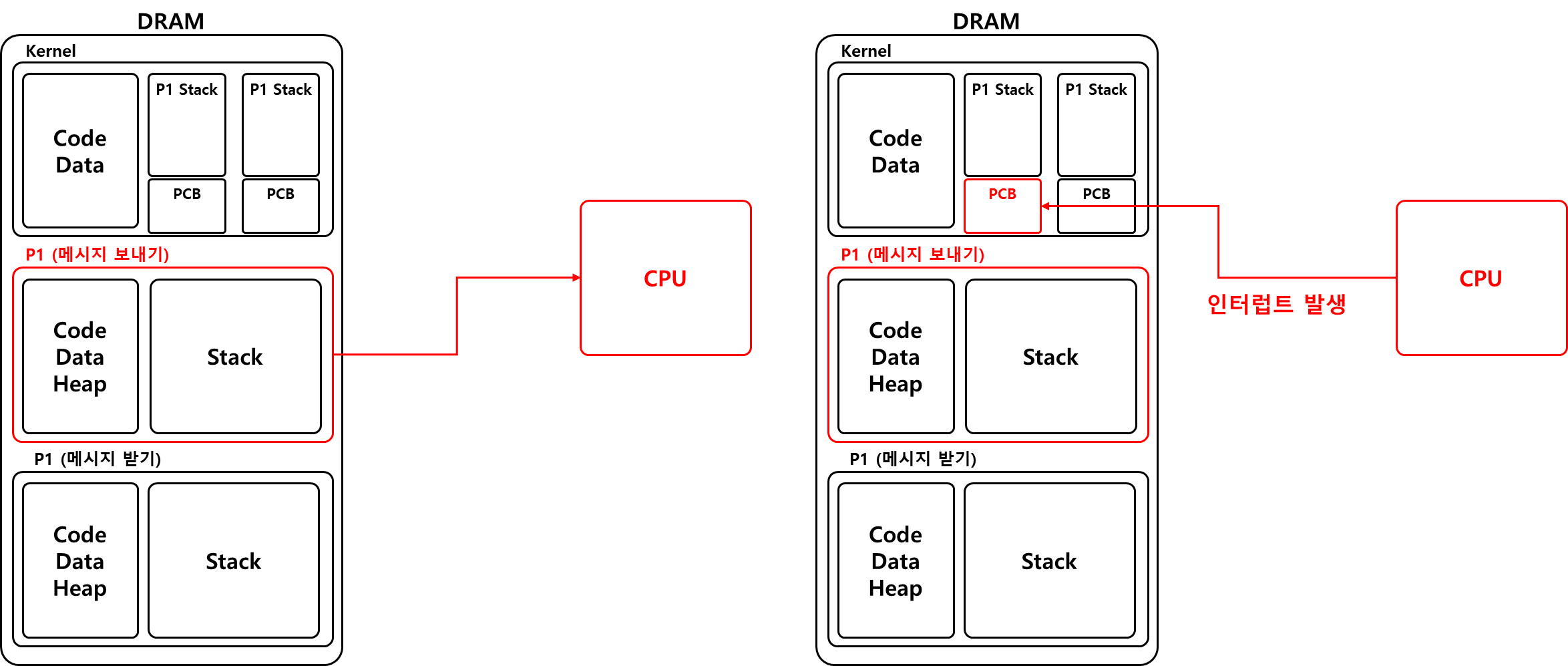
각 작업의 프로세스를 생성(System Call을 통해 프로세스가 메모리에 자원을 할당)하거나 Context Switch 하면 오버헤드가 발생하고 프로세스 사이에 데이터를 주고받기가 힘들어진다.
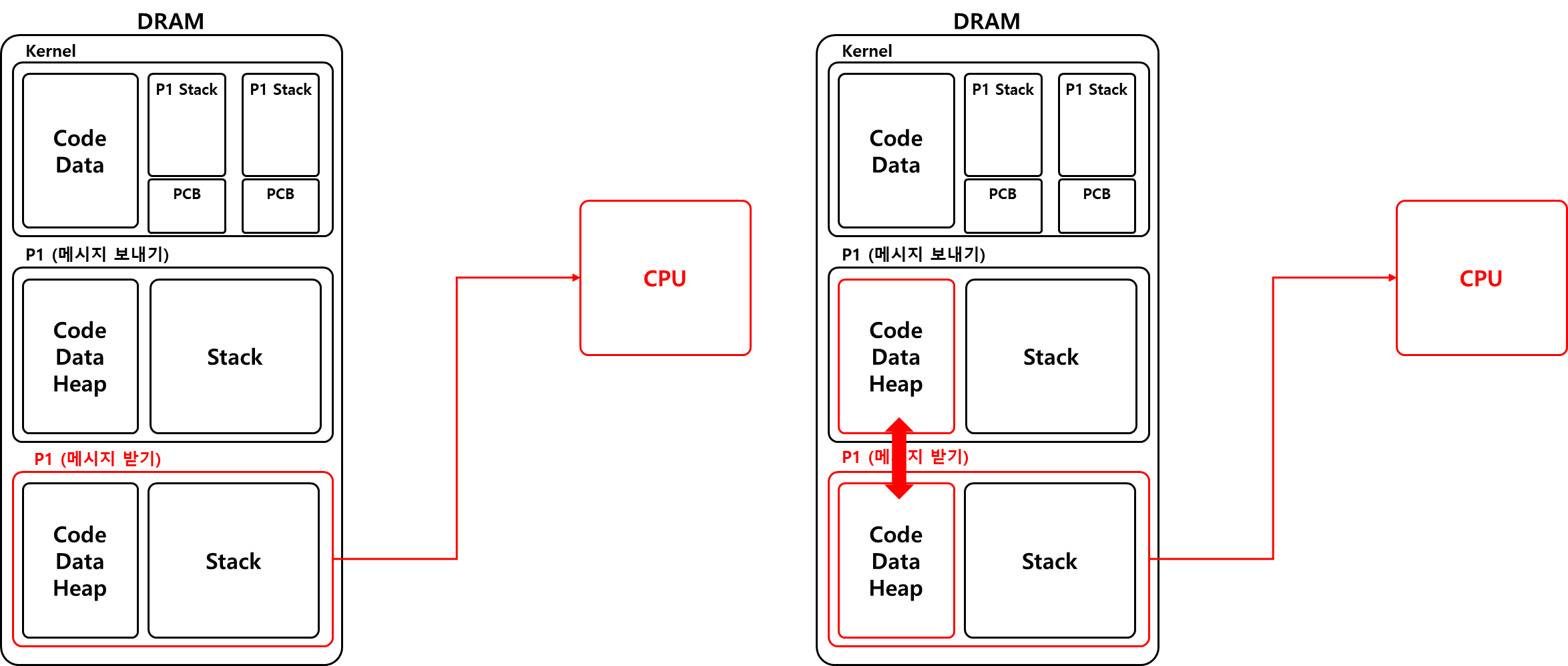
때문에 한 프로세스에 여러 스택과 TCB를 만들어서 각 작업 단위마다의 진척도를 기록하기 위해 쓰레드가 필요하다.
쓰레드를 사용하면 그림과 같이 추가적인 프로세스를 생성할 필요가 없어지고 자원을 공유하며 Context Switch 또한 빨라서 오버헤드가 작아진다.
1-2. 멀티 프로세싱과 멀티 쓰레딩
멀티 프로세싱
하나의 부모 프로세스가 여러 개의 자식 프로세스를 생성하는 방법
브라우저 프로세스가 부모 프로세스라면 브라우저의 탭은 자식 프로세스이다.
부모 프로세스는 자식 프로세스의 PID를 갖고 있다.
아래와 같은 특징이 있다.
- 여러개의 자식 프로세스 중 하나에 문제가 발생해도 다른 자식 프로세스는 영향을 받지 않음
- Context Switching 과정에서 캐쉬 메모리 초기화 등 무거운 작업이 진행되면서 오버헤드가 발생
- 프로세스 간 통신을 하기 위해서는 IPC를 통해야 함
- 프로세스 간 공유하는 메모리가 없어서 Context Switching이 발생하면 데이터를 처음부터 불러와야 함
멀티 쓰레딩
앞서 설명했듯 프로세스 하나에 여러 쓰레드를 생성하는 방법
아래와 같은 특징이 있다.
- 시스템 자원 소모 감소 (자원의 효율성)
- 프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어서 자원을 효율적으로 관리할 수 있음
- 시스템 처리량 감소 (처리 비용)
- 쓰레드 간 데이터를 주고 받는 것이 간단해지면서 시스템 자원 소모가 줄어듦
- 쓰레드 사이의 작업량이 작아 쓰레드 간 Context Switching이 활발하게 일어남
- 동기화 문제나 교착 상태가 발생할 수 있음
- 교착 상태(Deadlock): 둘 이상의 쓰레드가 서로의 작업이 끝나기만을 기다리며 작업을 더 이상 진행하지 못하는 상태
- 동기화 문제: 멀티 스레드가 프로세스 내의 같은 자원을 공유함으로써 발생하는 문제
- 하나의 쓰레드가 문제가 발생하면 프로세스 전체가 영향을 받음
2. 🤿 쓰레드 풀
2-1. 개념
쓰레드 풀은 미리 정의된 개수의 쓰레드를 생성하고 유지한다.
여기에 속한 쓰레드는 작업이 필요할 때마다 사용된다.
작업이 요청되면 쓰레드 풀은 사용 가능한 쓰레드 중 하나를 할당하고 해당 작업을 실행시킨다.
작업이 완료되면 해당 쓰레드는 다시 풀에 반환되어 재사용될 수 있다.
이를 통해 쓰레드 생성 및 삭제에 따른 오버헤드를 줄이고 쓰레드의 재사용성을 높일 수 있다.
2-2. 동시성과 병렬성
동시성
싱글 코어에서 멀티 스레드를 동작시키기 위한 방식으로 멀티 태스킹을 위해 여러 개의 스레드가 번갈아가면서 실행되는 성질
동시성을 이용한 싱글 코어의 멀티 태스킹은 각 스레드들이 병렬적으로 실행되는 것처럼 보이지만 사실은 번갈아가면서 조금씩 실행되고 있는 것
병렬성
멀티 코어에서 멀티 스레드를 동작시키는 방식으로, 한 개 이상의 스레드를 포함하는 각 코어들이 동시에 실행되는 성질
병렬성은 데이터 병렬성(Data parallelism)과 작업 병렬성(Task parallelism)으로 구분됨
데이터 병렬성
데이터 병렬성은 전체 데이터를 쪼개 서브 데이터들로 만든 뒤, 서브 데이터들을 병렬 처리하여 작업을 빠르게 수행하는 것을 말함
자바8에서 지원하는 병렬 스트림이 데이터 병렬성을 구현한 것
서브 데이터는 멀티 코어의 수만큼 쪼개어 각각의 데이터들을 분리된 스레드에서 병렬 처리
작업 병렬성
작업 병렬성은 서로 다른 작업을 병렬 처리하는 것
대표적인 예는 웹 서버로, 각각의 브라우저에서 요청한 내용을 개별 스레드에서 병렬로 처리
