LLM Trend Note (1)
LLM Trend Note (2) Foundation Model과 Emergent Abilities, Instruction Tuning 그리고 Chain-of-Thought Prompting
LLM Trend Note (3) Emergent Abilities, Model scale과 Data size
LLM Trend Note (4) InstructGPT : RLHF, 언어모델과 강화학습의 만남
LLM Trend Note (5) GPT-4 vs LLaMA
LLM Trend Note (6) LLM.int8(), LoRA, Prefix LM, Sparse transfomer, Sparse attention, Model parallelism, Data parallelism
nlp에 입문하여 바보탈출 하는 중인데, 바보 탈출에 큰 도움을 준 글을 내가 볼 용도로 정리해보았다.
LLM Trend Note (1)
LLM
gpt4 - OpenAI
LLaMA - Meta
PaLM - Google
LLM Trend Note (2)
statistic language model - neural language model - transformer architecture - pretrained language model
foundation model
pretrained model을 foundation model이라 지칭하며 새로운 패러다임 제시
- homogenization
단일 모델이 광범위한 작업에 유용
최첨단 nlp 모델은 BERT, RoBERTa, BART, T5등과 같은 몇 가지 기본 모델 중 하나로 채택됨
높은 레버리지 - emergence
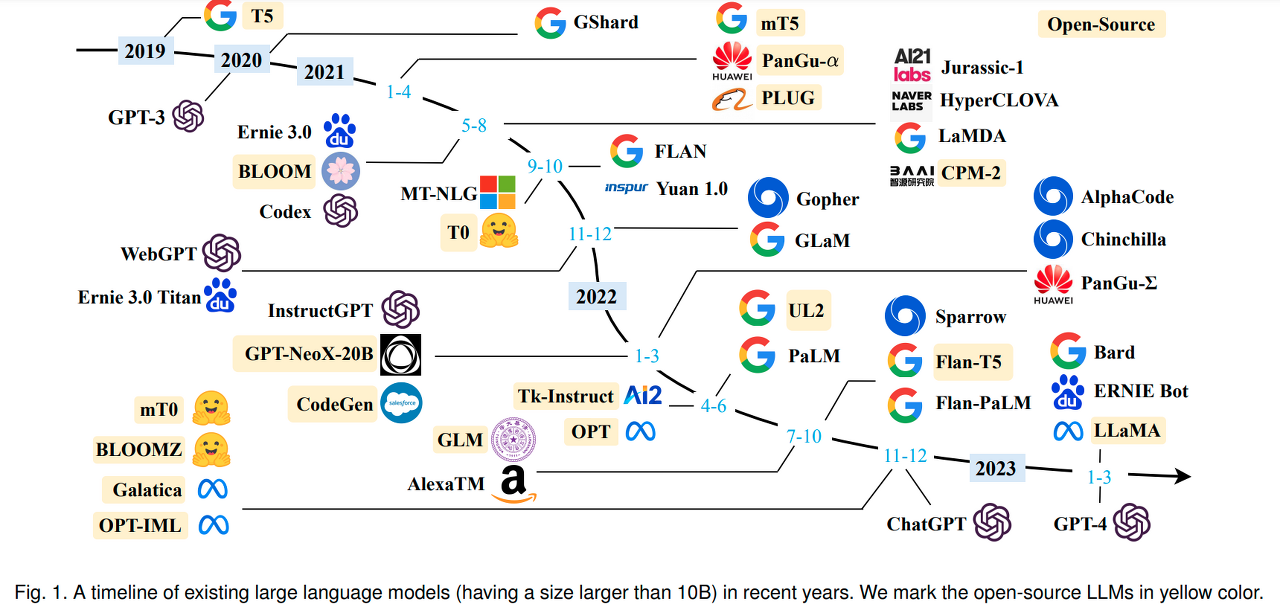
LLM: 수백억~수천억 개 파라미터를 가진 PLM
파라미터 수가 일정 수준을 초과한 LLM은 BERT와 같은 million 단위의 소규모 LM에 없는 성능을 나타냄(= in-context learning: zero-shot, one-shot, few-shot)
prompt learning
gpt3 논문에서 소개하고 있는 zero-shot, one-shot, few-shot은 모델의 inference 단계에서 이뤄짐 (= gradient를 계산해 모델 파라미터 업데이트를 하는 과정에서 학습되는 게 아님)
instruction tuning - FLAN
chain-of-thought prompting - PaLM
instruction tuning - FLAN
zero-shot learning ability를 개선하는 방법을 제안하는 것이 논문의 목적
LaMDA 모델 사용
모델로 하여금 자연스럽게 user의 instruction에 따르는 답변을 내놓게 함
gpt3보다 작은 모델을 fine-tuning하여 모델에게 instruction following 능력을 부여함
(방법)
0. 기존 공개된 데이터셋들을 총 12개 카테고리로 분류
0. 각 데이터셋들을 instruction 형식으로 수정
1. finetune on many tasks (instruction - label)
2. inference on unseen task
Chain-of-Thought Prompting - PaLM
LLM의 규모를 극한으로 몰아붙였을 때 few-shot 능력이 얼마나 상승할지
Transformer 모델 사용
PaLM에 CoT prompting 기법을 적용해 Gopher가 어려움을 겪음 multi-step reasoning(arithmetic reasoning, commonsense reasoning)에서 좋은 성능을 냄
(방법)
모델에게 prompt를 줄 때 문제에 대한 답만 주지 않고 문제를 푸는 데 필요한 사고과정을 함께 줌
LLM Trend Note (3)
alignment problem: 모델이 HHH 기준을 충족시키지 않는 문제
InstructGPT의 RLHF technique
AGI(Artificial General Intelligence)
더 많은 데이터를 더 큰 모델에 학습시키는 방법만이 emergent abilities를 확장할 수 있는 유일한 길일까?
-> 상대적으로 작은 LLM에서 emergence가 발견되었다는 보고가 여러 논문을 통해 발표되고 있다
T0: (비교적) 적은 데이터와 작은 모델로 FLAN보다 나은 성능
Chinchilla: Gopher보다 작은 모델, 많은 데이터로 나은 성능
PaLM 62B: gpt3 175B, LaMDA 137B보다 작은 모델, 많은 데이터로 나은 성능
=> 데이터를 추가할 때 얻을 수 있는 이득은 엄청난 반면, 모델 크기를 키웠을 때의 이득은 미미하다
고품질 데이터로 훈련된 모델일 경우 파라미터가 적어도 emergence가 나타날 수 있을까?
InstructGPT
gpt3와 동일한 아키텍쳐를 베이스 모델로 하여 파라미터 스케일을 1.3B, 6B, 175B 세가지 버젼으로 달리해 구현한 모델
1.3B InstructGPT와 175B GPT-3가 생성한 문장의 실제 인간의 선호도를 비교한 결과,
사람은 1.3B InstructGPT가 생성해낸 문장을 선호했다 (300B개의 토큰만 봤음에도)
(방법)
LLM + RLHF(Reinforcement Learning Human Feedback)
RLHF: 모델이 "데이터의 품질을 스스로 판별하여" 더 나은 결과물을 만들어낼 수 있게 함
LLM Trend Note (4)
RLHF
알고리즘의 편향을 필터링하거나 제거할 수 있는 방법을 지도학습 기반의 단일 딥러닝 모델에 손실함수화할 수 있을까?
고전적인 지도학습 기반의 단일 foundation model 만으로는 자신이 만들어낸 문장, 음성, 이미지, 영상이 HHH 기준을 충족하는지 알 수 없다
Deep Reinforcement Learning from Human Preferences (2017)
-> 강화학습 시 human feedback이 있을 때가 없을 때보다 효과적
Fine-Tuning Language Models from Human Preferences (2019)
-> 강화학습을 text summarization task를 수행하는 PLM에 적용
-> RL 알고리즘 중 하나인 PPO(proximal policy optimization) 사용
Learning to summarize from human feedback (2020)
-> 인간이 직접 품질을 비교한 데이터셋을 바탕으로 human feedback을 학습한 모델을 강화학습의 reward function으로 사용
-> 입력 데이터가 편향되었다 하더라도 알고리즘 편향 없이 human feedback이 의도하는 품질의 summarization 수행
Training language models to follow instructions with human feedback (2022)
InstructGPT: LLM + RLHF
-
pretraining a language model
SFT(supervised fine-tuning)
OpinAI에서는 human annotator를 고용해 prompt에 대하여 사람의 선호를 반영한 label 쌍으로 이루어진 고품질의 데이터셋 구축
1.3B, 6B, 175B 3가지 크기의 GPT-3에 fine-tuning 시켰다 -
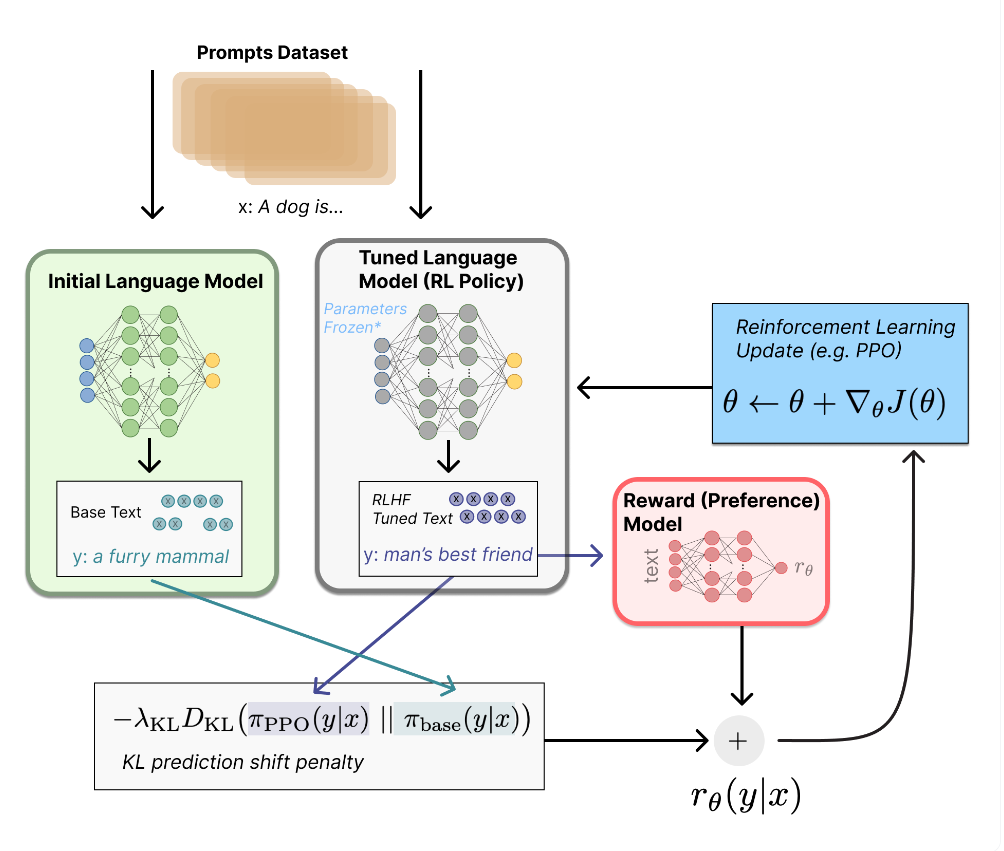
gathering data and training a reward model
SFT 모델을 약간 수정해 prompt와 그에 대한 response를 입력받아 scalar reward를 출력하는 RM 만듦 -
fine-tuning the LM with reinforcement learning
RL Policy = tuned language model = SFT model
initial language model(마찬가지로 SFT)은 RL Policy가 RM을 통해 업데이트될 때, 인간의 선호가 반영된 답변으로 부터 너무 벗어난 문장을 생성하지 않게 제한을 걸어주는 패널티 역할
LLM Trend Note (5)
StackLLaMA
StackExchange의 질문답변 데이터셋, Meta의 LLaMA, TRL 라이브러리(RLHF를 pytorch로 구현함) 사용
- SFT
LLaMA를 StackExchange 질문답변 dataset으로 causal language modeling - RM
StackExchange dataset을 활용해 RM 학습 - RLHF
(1) 1단계에서 준비한 LM(RL policy)로 prompt와 response 수집
(2) 2단계에서 준비한 RM에 넣어 reward 계산
(3) LM의 카피본에도 같은 prompt와 response 넣어 KL-divergence 값 구해 최종 reward 계산
LLM Trend Note (6)
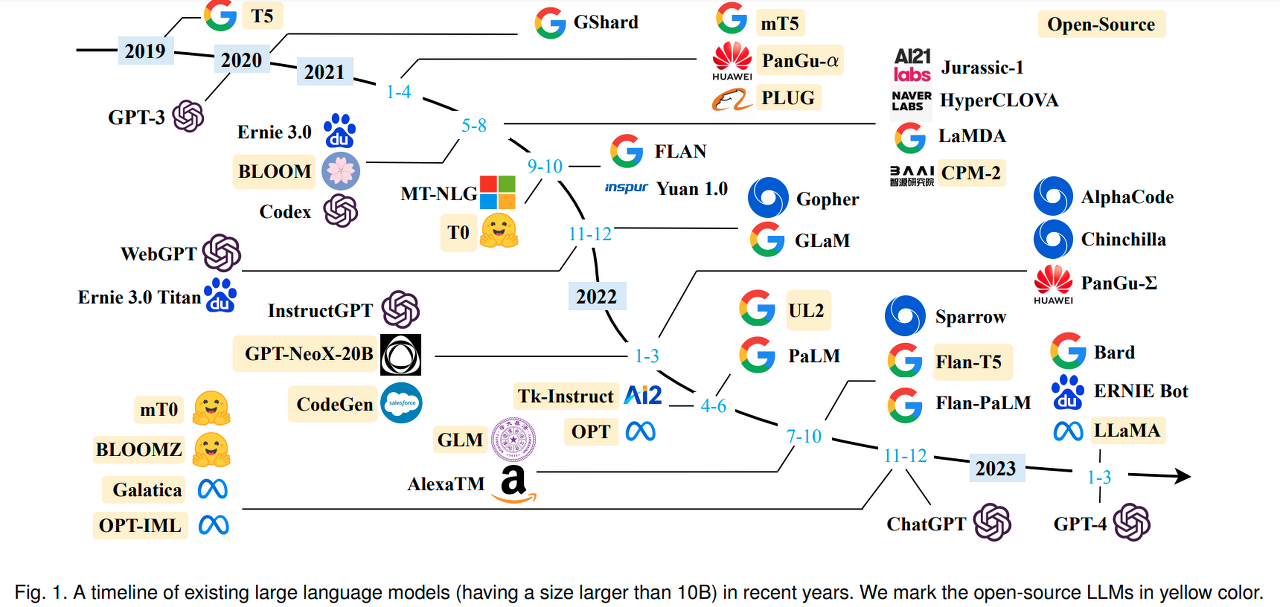
현시점에서 가장 강력한 emergence를 보여주는 LLM은 instruction tuning과 RLHF가 적용된 LLM(각각 (2)의 FLAN과 (4), (5)의 InstructGPT를 통해 살펴봄)
-> 이들의 단점의 "크기": 모델의 크기가 커지면 단일 GPU에 원하는 크기의 배치로 학습을 최적화시키는 일이 어려워질 수밖에 없다
StackLLaMA의 경우)
- reference model과 active model 간에 레이어를 공유하고 헤드만 학습시키는 방법으로 해소
- 모델 가중치를 8bit로 로드 (LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale)
- LoRA 기법 (PLM의 가중치를 고정시키는 대신 어텐션 레이어에 훈련 가능한 rank decomposition 행렬을 주입해 연산비용을 획기적으로 낮춤)
- 허깅페이스에서는 위 기법들을 망라한 PEET library 제공
# 모델 아키텍쳐 자체에 대한 심도 깊은 연구의 필요성 제기
FLAN의 예시)
- FLAN에 쓰인 LaMDA는 디코더 기반 트랜스포머 모델
- 단, 어텐션 기법은 T5에 사용된 아키텍쳐를 그대로 사용
T5)
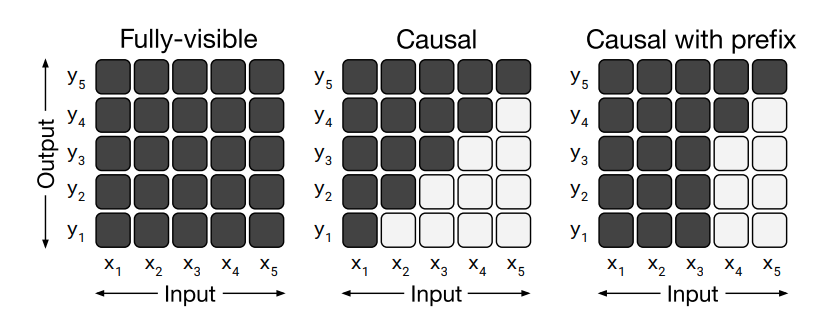
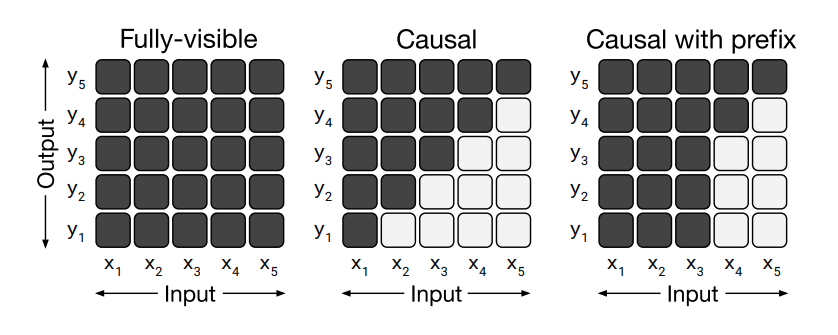
- Vanilla Transformer에서는 마스킹과 관련해 두 종류의 어텐션만 사용 (fully-visible attention, causal attention)
- T5에서는 여기에 causal with prefix attention 추가 (입력 시퀀스의 앞쪽 몇 개 토큰만 fully-visible attention 수행, 나머지 뒤쪽 토큰들에는 causal attention 수행)
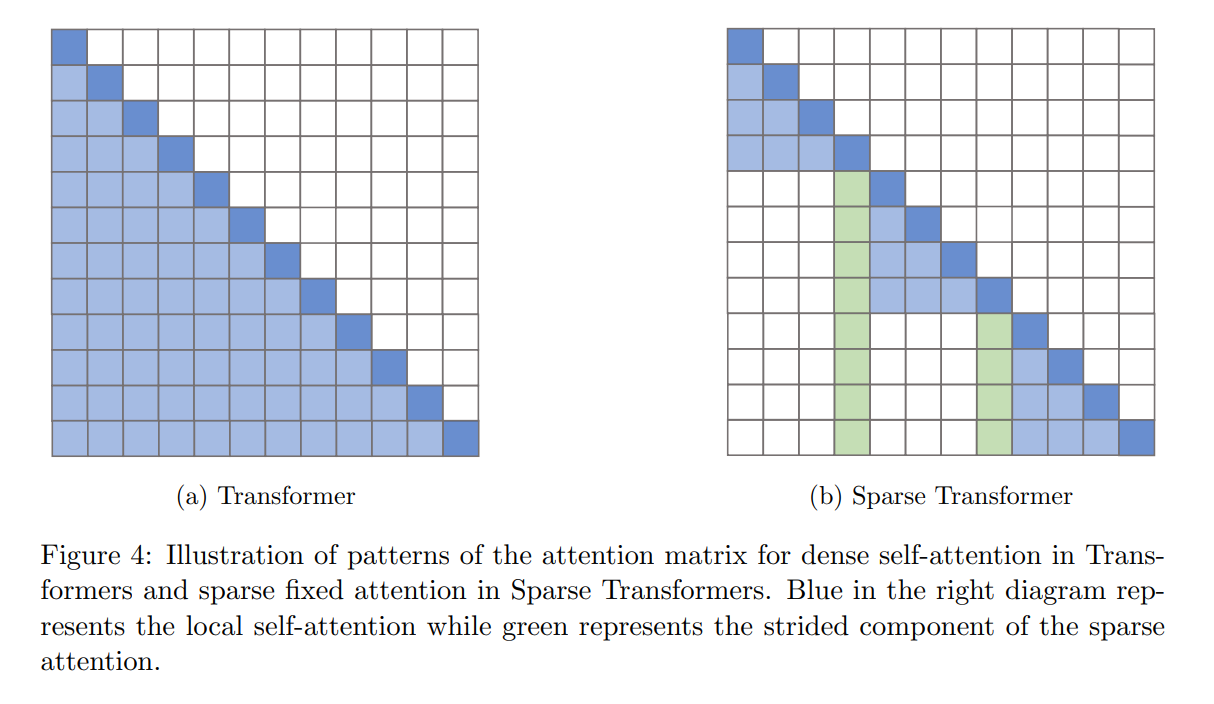
# 어텐션 연산 자체에 대한 연구 필요
- self attention 연산은 일반적으로 O(n^2)의 시간복잡도 요구하지만 이를 O(log n)으로 단축시키는 새로운 어텐션 메커니즘
- Sparce Transformer: 모든 토큰에 어텐션을 수행하는 게 아니라 특정 토큰에 선택적으로 어텐션 (facebookresearch에서 공개한 라이브러리 xformers)
- Flash Attention (어텐션 연산이 이루어지는 물리적 공간인 GPU의 HBM과 SRAM 간의 메모리 read/write 수를 줄일 수 있는 새로운 어텐션 메커니즘
=> 결과적으로 LLaMA는 위와 같은 기법을 활용해 모드 어텐션 가중치를 저장하지 않고, causal language modeling시 마스킹되는 부분에 대한 key/query score을 계산하지 않는 multi-head attention을 사용함으로써 메모리 공간을 절약하고 어텐션 속도도 향상시킴
# multiple GPU 사용이 가능한 환경이라면
=> LLM을 효율적으로 분산학습시킬 수 있는 분산학습 알고리즘 필요

거대해진 모델과 데이터들을 parallel할 수 있는 학습 기법 필요
-
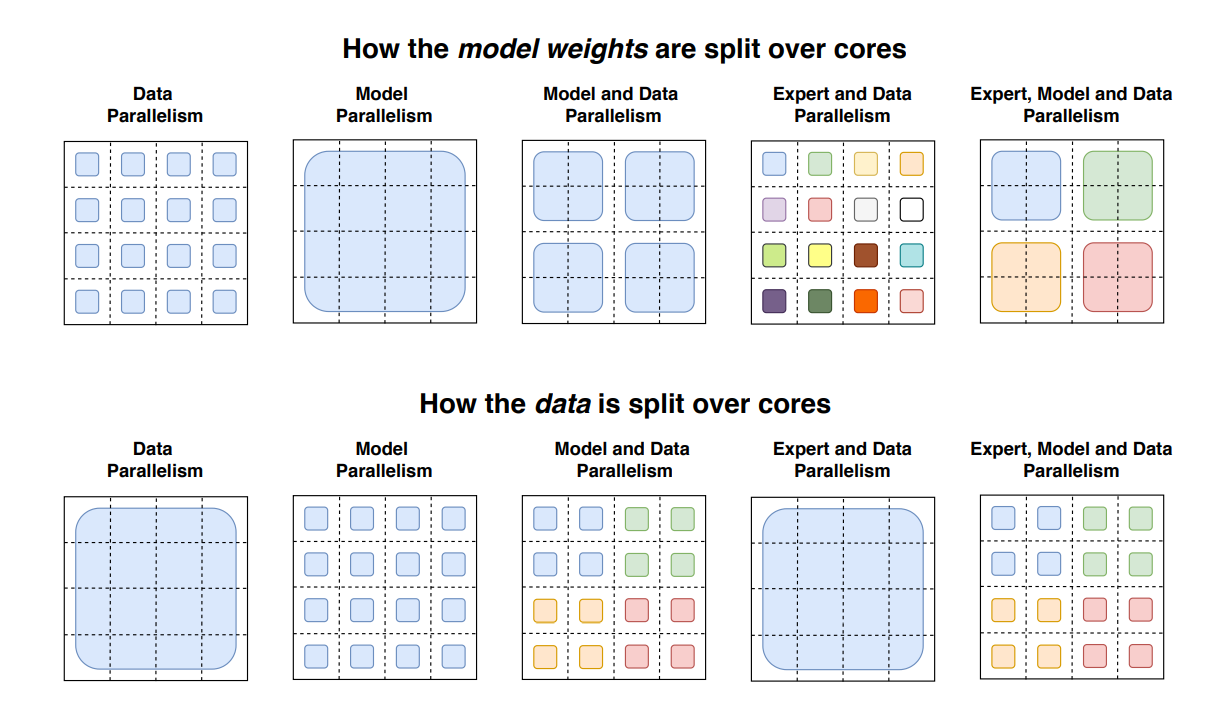
모델 가중치가 코어간에 분할되는 방식
Data parallelism: 서로 다른 코어에 모델 복제본들이 분할
Model parallelism: 코어 간에 하나의 모델이 걸쳐 있음
Model and Data parallelism: 위 두 방식 결합
Expert and Data parallelism: MoE 방식
Expert, Model, and Data parallelism: 위 네 방식 결합 -
데이터 배치가 코어간에 분할되는 방식
