사실 GC부터 할려고 했는데 갑자기 쓰레드가 땡겨서...
시작합니다.
쓰레드(Thread)는 프로세스 내에서 독립적으로 실행되는
작업의 단위입니다. 각각의 쓰레드는 프로세스 내의 자원을 공유하면서 동시에 여러 작업을 수행할 수 있습니다. 이를 통해 다중 작업(multi-tasking)이나 다중 처리(multi-processing)를 구현할 수 있습니다.
이게 무슨 뜻이냐하면
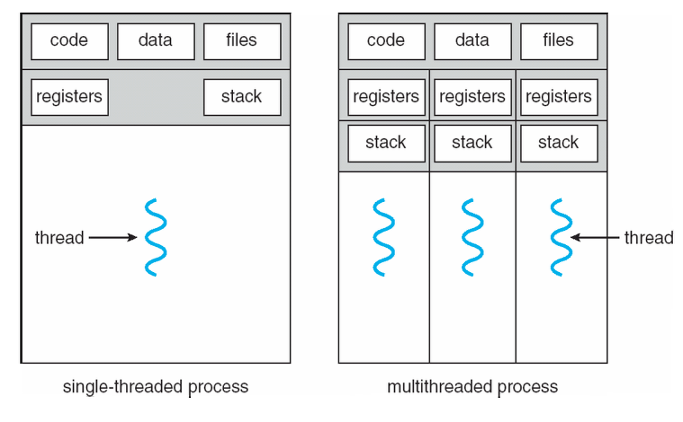
싱글스레드와 멀티스레드의 특징들부터 알아볼게요
싱글 쓰레드(Single-Thread)
싱글 쓰레드는 하나의 쓰레드만을 사용하여 작업을 처리하는 모델입니다. 프로그램이 순차적으로 실행되며, 한 번에 하나의 작업만 처리됩니다. 예를 들어, 웹 브라우저가 싱글 쓰레드로 동작하는 경우, 한 번에 하나의 페이지만 로드되고, 사용자가 다른 페이지를 요청할 때까지 이전 작업이 완료될 때까지 기다려야 합니다. 이러한 모델은 간단하고 예측 가능하지만, 여러 작업을 동시에 처리할 수 없으며, 작업이 느리게 진행될 수 있습니다.
멀티 쓰레드(Multi-thread)
멀티 쓰레드는 여러 쓰레드를 사용하여 작업을 동시에 처리하는 모델입니다. 각 쓰레드는 독립적으로 실행되며, 서로 다른 작업을 수행할 수 있습니다. 이를 통해 여러 작업을 동시에 처리하여 시스템의 성능을 향상시키고, 응답성을 향상시킬 수 있습니다. 예를 들어, 웹 서버가 멀티 쓰레드로 동작하는 경우, 여러 클라이언트 요청을 동시에 처리할 수 있으며, 한 클라이언트의 요청이 블로킹되더라도 다른 클라이언트의 요청을 처리할 수 있습니다.
이렇게만 보면 멀티 쓰레드가 Goat인데 물론 문제가 있겠죠?
쓰레드 간 동기화와 관련된 문제를 처리해야하고 이로 인해 프로그래밍이 복잡해진다는 단점이 있습니다.
동기화 예시 함 보러 가실게요.
문제 상황
두 개의 쓰레드가 동시에 같은 계좌에서 자금을 인출하려고 할 때.
class BankAccount {
private int balance = 1000; // 초기 계좌 잔액
public void withdraw(int amount) {
if (balance >= amount) {
balance -= amount;
System.out.println("Successfully withdrawn: " + amount);
} else {
System.out.println("Insufficient funds!");
}
}
}
public class BankExample {
public static void main(String[] args) {
BankAccount account = new BankAccount();
// 두 개의 쓰레드에서 동시에 계좌에서 자금을 인출하는 시도
Thread t1 = new Thread(() -> {
account.withdraw(800);
});
Thread t2 = new Thread(() -> {
account.withdraw(800);
});
t1.start();
t2.start();
}
}이제 동기화를 사용해서 문제 해결하기.
동기화는 한 번에 하나의 쓰레드만이 특정 블록을 수행하도록 보장합니다.
class BankAccount {
private int balance = 1000; // 초기 계좌 잔액
public synchronized void withdraw(int amount) {
if (balance >= amount) {
balance -= amount;
System.out.println("Successfully withdrawn: " + amount);
} else {
System.out.println("Insufficient funds!");
}
}
}동기화는 이렇게 여러 쓰레드 간의 상호작용을 조율하고, 데이터의 일관성과 무결성을 유지하는 데
중요한 역할을 합니다. 하지만 과도한 동기화는 성능에 부정적인 영향을 미칠 수 있으므로 적절하게 사용해야합니다.
뭔 얘기냐 하면...
예시를 또 들어볼게요(과도한 동기화)
과도한 동기화
import java.util.ArrayList;
import java.util.List;
class SharedResource {
private List<Integer> list = new ArrayList<>();
public synchronized void addItem(int item) {
list.add(item);
}
public synchronized void removeItem(int item) {
list.remove(Integer.valueOf(item));
}
public synchronized boolean containsItem(int item) {
return list.contains(item);
}
}
public class SynchronizationExample {
public static void main(String[] args) {
SharedResource resource = new SharedResource();
Thread producerThread = new Thread(() -> {
for (int i = 0; i < 100000; i++) {
resource.addItem(i);
}
});
Thread consumerThread = new Thread(() -> {
for (int i = 0; i < 100000; i++) {
resource.removeItem(i);
}
});
producerThread.start();
consumerThread.start();
try {
producerThread.join();
consumerThread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("List size: " + resource.getListSize());
}
}
쓰레드가 많지 않기 때문에 문제가 발생하진 않을 것 같지만 실제 상황에서는 많은 쓰레드가 동시에 실행 될 경우
성능 저하나 데드락이 발생할 수 있어요.
그래서 동기화 블록을 최소화하는 것이 좋고 Lock 객체를 사용해서 더 세밀한 제어를 한다거나,
동시성 컬렉션을 사용해서 동시에 안전하게 작업할 수 있어요.
Lock 객체 예시도 들어볼까요?
Lock 예시
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
class Counter {
private int count = 0;
private Lock lock = new ReentrantLock();
public void increment() {
lock.lock();
try {
count++;
} finally {
lock.unlock();
}
}
public int getCount() {
lock.lock();
try {
return count;
} finally {
lock.unlock();
}
}
}
public class LockExample {
public static void main(String[] args) {
Counter counter = new Counter();
Runnable task = () -> {
for (int i = 0; i < 1000; i++) {
counter.increment();
}
};
Thread thread1 = new Thread(task);
Thread thread2 = new Thread(task);
thread1.start();
thread2.start();
try {
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Final count: " + counter.getCount());
}
}
Lock 인터페이스를 구현한 ReentrantLock 객체를 사용해서 동기화를 수행하는데
increment() 메서드와 getCount() 메서드에서는 먼저 lock을 획득하고(lock.lock()) 작업을 수행한 후
finally 블록에서 lock을 반납합니다.
이제 동시성 컬렉션도 알아봐야겠죠?
동시성 컬렉션 예시
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
public class ConcurrentCollectionExample {
public static void main(String[] args) {
ConcurrentMap<String, Integer> map = new ConcurrentHashMap<>();
Runnable task = () -> {
for (int i = 0; i < 1000; i++) {
map.put(Integer.toString(i), i);
}
};
Thread thread1 = new Thread(task);
Thread thread2 = new Thread(task);
thread1.start();
thread2.start();
try {
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Final map size: " + map.size());
}
}
컬렉션프레임워크 정리 마렵네...
여기서 ConcurrentMap은 내부적으로 세분화된 lock을 활용해서 동시에 안전하게 작업을 수행할 수 있도록 합니다.
결론은 동기화를 사용할 때는 신중하게 고려하고 필요한 경우에만 사용하도록 합시다.
이제.... 쓰레드를 봤으니 프로세스 안 나올 수가 없겠죠?
프로세스 갑니다.
프로세스
프로세스는 운영체제에서 실행 중인 프로그램을 나타냅니다. 각 프로세스는 독립적인 메모리 공간을 할당받으며, 실행 중인 프로그램의 인스턴스입니다. 각 프로세스는 최소한 하나 이상의 쓰레드를 포함하고 있습니다.
쓰레드와 프로세스의 차이점
- 독립성: 각각의 프로세스는 독립적인 메모리 공간을 가지고 실행되지만, 쓰레드는 같은 프로세스 내에서 공유된 메모리를 사용합니다.
- 리소스 공유: 프로세스는 각각이 독립된 메모리 공간을 가지므로, 리소스를 공유하기 위해
IPC(Inter-Process Communication)를 사용해야 합니다. 반면에 쓰레드는 같은 프로세스 내에서 공유된 메모리를 사용하기 때문에, 데이터를 공유하기 위해 별도의 메커니즘이 필요하지 않습니다. - 생성 및 종료 오버헤드: 프로세스는 생성 및 종료에 많은
오버헤드가 발생할 수 있지만, 쓰레드는 비교적 작은 오버헤드로 생성 및 종료할 수 있습니다. - 병렬성: 프로세스는 다른 프로세스와 완전히 독립적으로 실행되므로
병렬 처리가 가능합니다. 반면에 쓰레드는 같은 프로세스 내에서 실행되기 때문에, 동시에 여러 쓰레드가 실행되더라도 실제로 동시에 실행되는 것은 아닙니다.
예로는 웹 브라우저가 하나의 프로세스이며 각 탭은 다른 쓰레드입니다. 쓰레드를 사용해서 각 탭에서 동시에 여러 웹
페이지를 로드할 수 있습니다.
텍스트 편집기가 하나의 프로세스이며 각 문서 편집창은 다른 쓰레드입니다. 이를 통해 여러 문서를 동시에 편집할 수 있씁니다.
이제 IPC(Inter-Process Communication)이나 오버헤드를 궁금해하실 분들을 위해....(내가 궁금했음)
IPC(Inter-Process Communication)란?
IPC(Inter-Process Communication)는 서로 다른 프로세스 간에 데이터를 교환하고 통신하기 위한 메커니즘을 의미합니다. 각각의 프로세스는 독립적인 메모리 공간을 가지고 있기 때문에, IPC를 사용하여 프로세스 간에 데이터를 전달하고 서로 통신할 수 있습니다.
IPC의 종류
-
파이프(Pipe):
단방향 통신을 위한 IPC 메커니즘으로, 두 프로세스 간에 바이트 스트림을 전달합니다. 부모 프로세스와 자식 프로세스 사이에서 주로 사용됩니다. -
명명된 파이프(Named Pipe 또는 FIFO): 파일 시스템에서 이름을 가진 파이프로, 서로 다른 프로세스 간에
양방향 통신을 할 수 있습니다. 이름있는 파이프는 파일 시스템을 통해 생성되며, 독립적인 프로세스들 간에도 통신이 가능합니다. -
메시지 큐(Message Queue): 메시지 큐는 메시지를 보내고 받는 프로세스 간의 통신을 제공합니다. 각 메시지는 특정한 형식을 가지고 있으며,
비동기식으로 전달될 수 있습니다. -
공유 메모리(Shared Memory):
두 개 이상의 프로세스가 같은 메모리 공간을 공유하여 데이터를 주고받을 수 있습니다. 공유 메모리는 데이터를 직접 읽고 쓰기 때문에 빠르게 통신할 수 있지만, 동기화가 필요합니다. -
소켓(Socket): 네트워크를 통해 프로세스 간에 통신하는 데 사용됩니다.
TCP/IP나 UDP와 같은 프로토콜을 사용하여 데이터를 주고받을 수 있습니다. 소켓은 로컬 머신 뿐만 아니라 원격 머신과의 통신에도 사용됩니다.
오버헤드(Overhead)란?
"오버헤드(Overhead)"는 어떤 작업이나 프로세스를 수행하는 데 추가적으로 소비되는 자원 또는 비용을 의미합니다. 이는 주로 시스템의 성능을 저하시키는 요소로 작용할 수 있습니다.
발생 원인
-
알고리즘
복잡도: 일부 알고리즘이나 프로세스는 추가적인 계산이 필요하거나 더 많은 메모리를 사용하여 작업을 수행해야 할 수 있습니다. -
데이터 구조: 데이터를 저장하고 처리하는 데 사용되는 구조는 오버헤드를 초래할 수 있습니다. 예를 들어, 배열의 크기를 동적으로 조정하는 경우에는 추가적인 메모리 할당 및 복사 작업이 필요합니다.
-
네트워크 통신: 데이터를 네트워크를 통해 전송하는 경우에는
데이터 패킷화,프로토콜 오버헤드등의 추가 작업이 발생할 수 있습니다.
이 둘은 나중에 깊게 다뤄볼게요~!
