Terms
-
Workload: Job descriptions의 집합 (
arrival_time,run_time)arrival_time: 시작 시각
run_time: 실행 시간- Process는 CPU와 I/O 작업을 번갈아 가며 이동한다. (ready와 blocked)
-
Scheduler: 어떤 Job을 실행시킬지 결정하는 알고리즘
-
Metric: Scheduling 퀄리티에 대한 지표
Introduction
Workload에 대한 가정들
- 모든 Job들은 같은 시간동안 실행된다.
- 모든 Job들은 동시에 실행된다.
- 모든 Job들은 I/O를 실행하지 않는다.
- 모든 Job에 대한 run_time을 알고 있다.
Scheduling Metrics
-
Performance metric: Turnaround time
-
Fairness metric
- Performance와 Fairness는 종종 Trade-off관계에 있다.
Schedulers
First In First Out(FIFO)
-
먼저 온 순서대로 처리하는 방법이다.
-
이때 먼저 온 Job이 시간을 오래 끌면 뒤에 있는 Job들도 모두 느려지는 효과가 발생한다.
-
이 경우 첫번째 assumption을 깨보자.
모든 Job들은 같은 시간동안 실행된다.
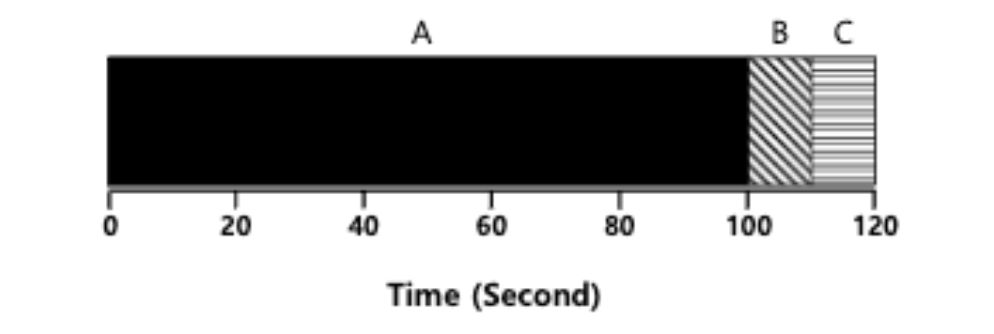
이때 평균 turnaround time은 다음과 같아진다.
따라서 다음 방법을 생각해볼 수 있다.
Shortest Job First (SJF)
-
가장 실행시간이 짧은 Job을 먼저 실행하는 방식이다.
-
이는 Non-preemptive Scheduling에서 가장 짧은 Turnaround time을 갖는다.
-
두번째 가정을 깨보자.
모든 Job들은 동시에 실행된다.
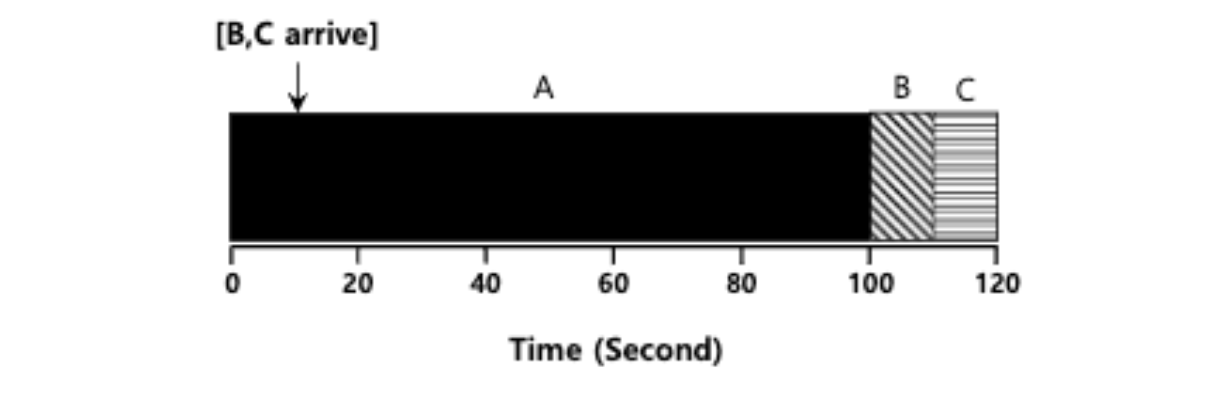
- 이 경우에는 FIFO와 같은 문제를 겪게 된다. 작업을 끊을 수 없기 때문이다.
Preemptive Scheduling
- 이제 작업을 중간에 끊을 수 있다.
- 이렇게 CPU를 뺏을 수 있는 방식을 Preemptive Scheduling이라고 부른다.
- 그리고 이 방식을 SJF에 방식이 STCF(Shortest Time-to-Completion First)이다.
Shortest Time-to-Completion First (STCF)
- SJF에 preemption을 추가한 방식이다.
- 새로운 Job이 시스템에 들어오면, 남아있는 Job과 새 Job을 계산하여 남은 시간이 적은 Job을 먼저 실행시킨다.
새로운 metric: Response Time
- 이는 Job이 처음으로 Schedule될 때까지의 시간을 의미한다.
- 이 시간을 줄이는 것이 실질적으로 사용자 경험을 좋게 할것이며, STCF와 같은 알고리즘은 별로 좋지 않다.
Round Robin (RR) Scheduling
- Time slicing Scheduling
- 이는 각 Job을 딱 time slice만큼만 실행시키고, Run Queue에 있는 다음 작업으로 변경시킨다.
- Time slice는 Scheduling Quantum 이라고도 불린다.
- 이는 job이 끝날때까지 반복되며, timer-interrupt 주기의 배수로만 설정할 수 있다.
- 이는 Response Time 측면에서는 유리하지만, Turnaround Time의 측면에서는 좋지 않다.
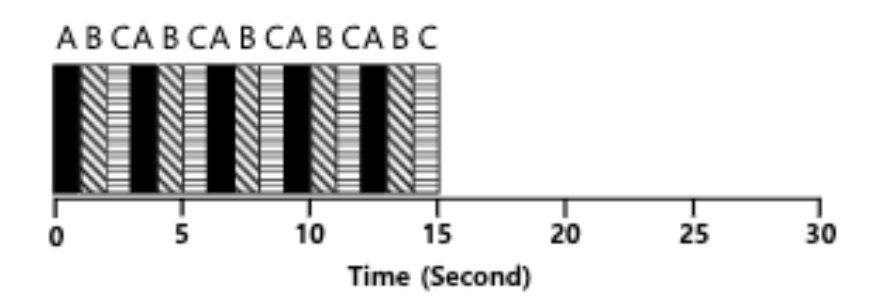
Length of Time Slice
-
짧은 Time slice: 더 짧은 response time을 갖겠지만, context switching의 비용이 성능에 영항을 미칠 것이다.
-
긴 Time slice: switching 비용은 무시할만 하겠지만, response time은 길어질 것이다.
Incorporating I/O
- 모든 프로그램은 I/O를 수행하므로 세번째 가정을 깨보자.
모든 Job들은 IO를 실행하지 않는다.
- 그러면 당연하게도 CPU가 I/O 때문에 쉬는 시간에는 다른 프로세스를 실행시켜야 할 것이다.
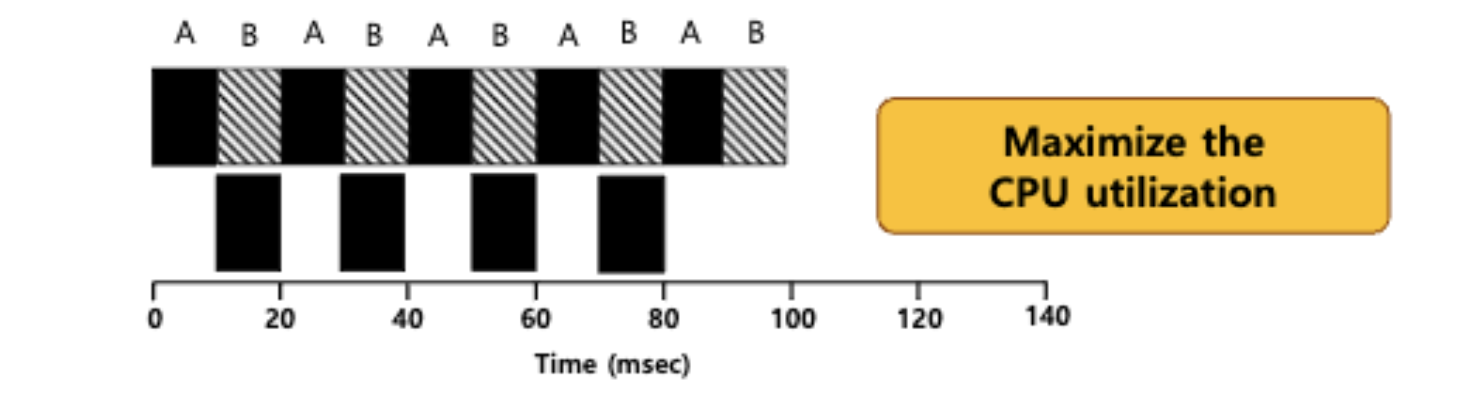
Multi-Level Feedback Queue (MLFQ)
-
이는 과거로부터 미래를 학습하는 Scheduller이다.
-
목적
- Turnaround time을 짧게 하는 것 -> 더 짧은 job을 먼저 실행한다.
- Response time을 짧게 하는 것.
MLFQ: Basic Rules
- MLFQ는 여러개의 queue를 갖는다.
- 각각의 queue는 다른 priority level을 갖는다.
Rule 1: 만약 A의 priority가 B의 priority보다 높다면 A를 실행한다.
Rule 2: 만약 A의 priority가 B의 priority와 갖다면 RR 방식으로 실행한다.
그러면 Priority는 어떻게 설정할까?
- MLFQ는 관측되는 행동으로부터 job의 priority를 설정한다.
- 이를 위해 추가적인 Rule을 설정하자.
Rule 3: 갓 실행된 Job은 최상위 priority를 갖는다.
Rule 4a: 만약 time slice를 다 쓴다면 priority를 낮춘다.
Rule 4b: 만약 time slice가 끝나기 전 CPU를 포기한다면 priority를 유지한다.
Basic MLFQ의 세가지 문제
-
Starvation
-
Game the scheduler
-
A program may change its behavior over time
Priority Boost
Rule 5: 일정한 time period S가 지난 후에, 모든 Job들을 최상위 Queue로 올려준다.
Better Accounting
Rule 4: Job이 주어진 레벨에서 일정 시간 이상으로 CPU를 사용한다면 Priority를 낮춘다.
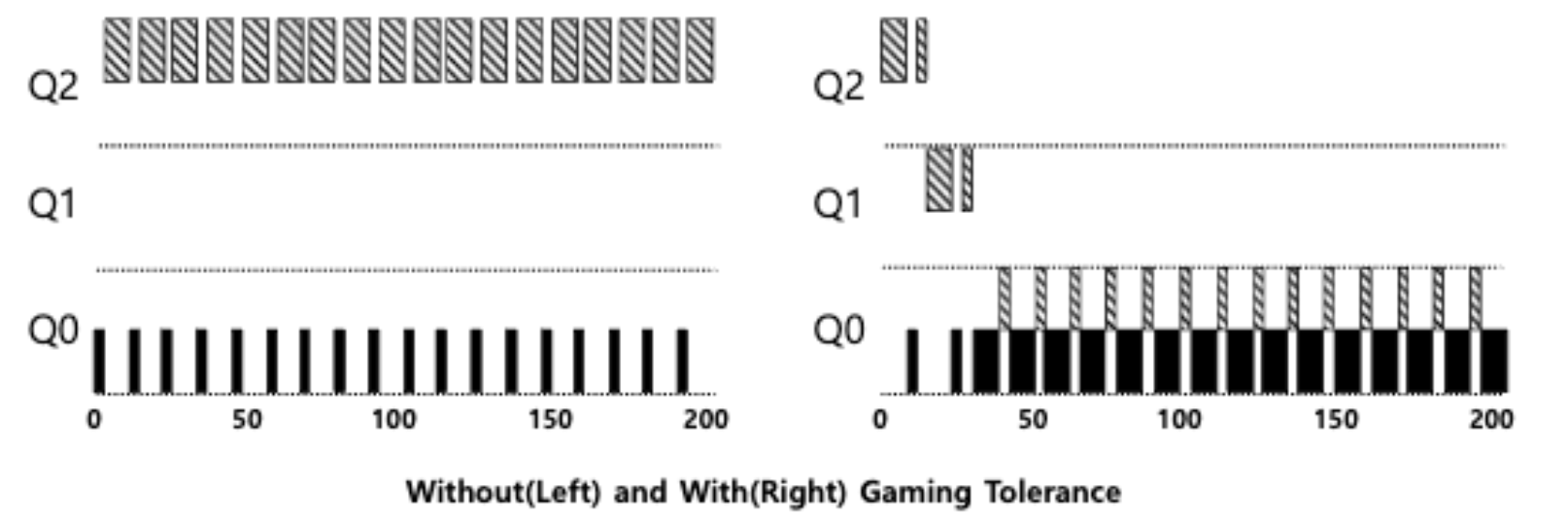
Tuning MLFQ
- 높은 우선순위를 갖는 queue는 더 짧은 time slice를 갖는다.
- 낮은 우선순위를 갖는 queue는 더 긴 time slice를 갖는다.
Solaris MLFQ implementation
Solaris는 Time Sharing scheduling class에 대하여
- 60개의 Queue
- 천천히 증가하는 time-slice length
- 최대 20ms, 최저 수백ms
- 1초마다 Priority boost를 실행한다.
