https://velog.io/@dnrgus1127/PE-File-Format%EC%88%98%EC%A0%95%EC%A4%91
이전 글
RVA와 RAW
PE File Format(1) 글에서 말했듯이. 섹션 헤더는 PE 파일의 섹션이
메모리에 로딩 될 때 필요한 정보들이 저장되어 있다고 했다.
그럼 이제 섹션에서 메모리의 주소와 파일 오프셋을 매핑하는 방법을 공부한다.
이러한 매핑을 RVA to RAW(파일 오프셋) 라고 한다.
- RVA가 속한 섹션을 찾는다.
- 비례식을 이용하여 파일 오프셋(RAW)를 계산한다.
RAW - PointerToRawData = RVA - VirtualAddress
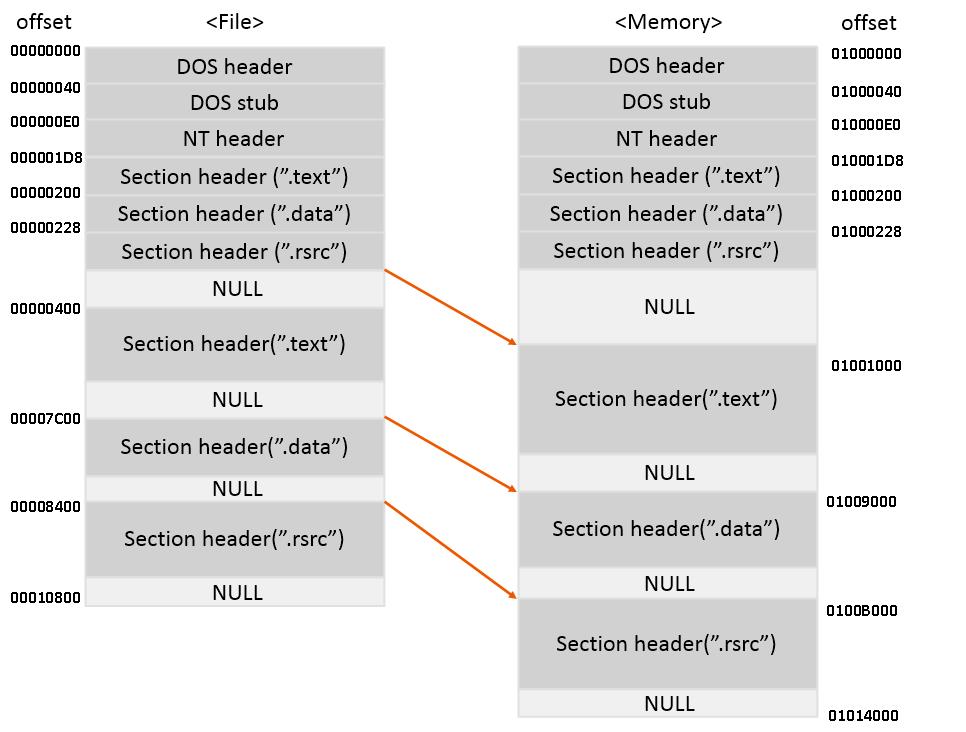
그림을 기준으로 간단한 몇 문제를 풀어보자
Q. RVA = 5000 일때 File Offset(RAW)은?
RAW - PointerToRawData = RVA - VirtualAddress의 기본 공식에서 우리는 RAW 값을 찾아야 하기에 RAW값을 제외하고 다른 항들을 전부 넘겨주면
RAW = RVA - VirtualAddress + PointerOfRawData 라는 식이 나온다
여기서 RVA 값은 5000으로 주어졌다.
그리고, RVA 값인 5000의 위치를 보니 .text섹션에 포함된다는 것을 알 수있다.
VirtualAddress 값은 어떻게 될까?
이 값은 메모리에서 섹션의 시작 주소다. 위에서 .text섹션이라는 것을 알아냈으니, 메모리에서 .text섹션의 시작 위치를 찾으면 된다.
그럼 VirtualAddress값은 1000 이라는 값을 찾을 수 있다.
이제 마지막으로 PointerOfRawData의 값으 찾아보자.
이 값은 바로 파일에서의 섹션의 시작 주소가 된다.
그림에서 파일에서 .text 섹션의 시작 주소는 400 이다.
이제 식에 대입해 보자
RAW = RVA - VirtualAddress + PointerOfRawData
RAW = 5000 - 1000 + 400 = 4400
즉 파일 오프셋은 4400임을 알아냈다.
파일과 메모리를 구분하기 힘들다면 파일은 로딩되기 전,
메모리는 로딩된 후 라고 생각하면 된다.
VirtualAddress값이 왜 01001000이 아니라 00001000인가에 대해서 의문을 가질 수도 있다.
하지만 여기서 01000000은 ImageBase값이다. 즉 파일이 로딩될 때
다른 프로세스와 출돌되지 않기 위해서 구분되는 프로세스의 구분 값이다.
IAT
공부하고 있는 책에서 PE 헤더를 처음 배울 때 가장 난관인 부분이 IAT 라고 한다.
나도 전에 이 책을 공부할 때 이 부분에서 막혀서 진도를 못나가다가 시험과 겹쳐서 리버싱 공부를 그만뒀었다. ㅡ.ㅡ;
IAT는 (Import Address Table)이다. 여기에는 프로세스, 메모리, DLL구조 등에 대한 내용이 함축되어 있다.
DLL
DLL(Dynamic Linked Library), 우리말로 동적 연결 라이브러리 라고 한다.
초기의 라이브러리 방식들은 DLL 개념이 없었고, 개발자가 라이브러리 함수를 사용하면 컴파일러는 해당 라이브러리의 코드를 그대로 복사해서 프로그램에 삽입하는 방식을 사용했다.
하지만 OS가 발전하면서 Windows 32비트 환경을 사용하기 위해서만 해도
매우 많은 라이브러리 함수들을 사용해야 했고, 멀티 태스킹이 지원하게 되면서
여러 프로그램들이 동시에 실행되면 메모리에 동일한 라이브러리가 로딩되면서
메모리의 낭비, 또 코드가 중복 저장되면서 발생하는 디스크 공간의 낭비도 발생했다.
그래서 Windows 설계자들이 프로그램에 라이브러리를 탑재하는 것이 아니라.
- 별도의 라이브러리 파일(DLL) 에 구성해서 필요에 따라서 불러 사용하고
- 이미 메모리에 로딩된 DLL의 코드, 리소스는 Memory Mapping 기술로 Process를 공유해서 쓰자.
- 라이브러리 업데이트 시 해당 DLL만 교체함으로서 편하게 바꾸자.
라는 이유로 DLL을 사용하게 되었다.
DLL로딩 방식은 사용되는 순간에 로딩하고, 사용이 끝나면 메모리에서 해제하는
Explicit Linking 방식과, 프로그램 시작시 로딩되고, 프로그램 종료 시 해제되는 Implicit Linking 방식 총 2가지로 나뉜다.
우리가 공부하는 IAT는 Implicit Linking에 대한 매커니즘을 제공한다.
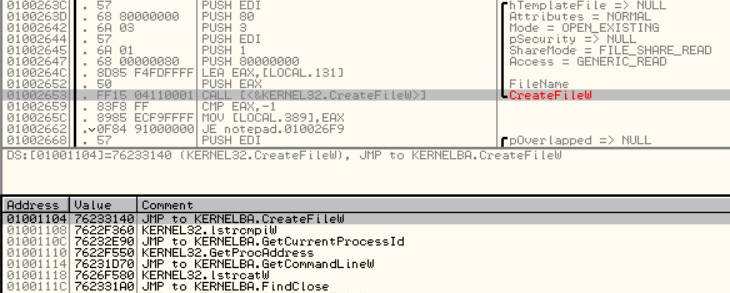
디버거로 확인한 notepad.exe에서 CreateFileW 라는 라이브러리 함수를 호출하는 코드다.
왜 직접 호출하지 않을까?
어셈블리 코드를 보면 01002653 CALL [<&KERNEL32.CreateFileW>] 로 해석하면
KERNEL32 라이브러리(DLL)의 CreateFileW 함수를 호출한 것이다.
근데 호출하는 모습을 보면 직접적으로 호출하지 않고,
01001104주소를 통해서 76233140주소에 위치한 CreateFileW를 호출한다.
간단히 생각해 보면 CALL 76233140 으로 직접 호출하면 더 간단하고 편할 것 같은데 왜 이런 방식을 사용하냐는 의문이 든다.
이런 방식은 예전에 DOS를 사용했던 시절의 방식이라고 한다.
우리가 만드는 프로그램은 컴파일 하는 당시에는 이 프로그램이 어느 환경
(win 98,XP,vista,7,10) 또는 언어 , Service Pack 등에서 실행될 지 알 수 없고,
이런 환경에 따라서 KERNEL32.DLL의 버전과 호출하고자 하는
함수(Ex CreateFileW)의 위치가 달라지게 된다.
또 문제가 하나 더 있다. 사용되는 DLL 파일이 여러개인 경우다.
보통 DLL 파일의 ImageBase 값은 01000000인데, A.dll과 B.dll이 있을 때 A.dll이 이미 01000000 위에서 로딩 되었다면 B.dll은 다른 ImageBase 값 위에서 로딩되어야 한다.
헌데 컴파일 시 라이브러리 함수 주소를 하드코딩 했다면 이런 경우 문제가 발생하게 된다.
IMAGE_IMPORT_DESCRIPTOR
PE 파일에는 자신이 어떤 라이브러리를 IMPORT(제공받는지)하는지에 대한 정보를 IMAGE_IMPORT_DESCRIPTOR 구조체에 명시하고 있다.
(IMPORT Directory Table이라고도 한다.)
typedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics; // 0 for terminating null import descriptor
DWORD OriginalFirstThunk; // RVA to original unbound IAT (PIMAGE_THUNK_DATA)
} DUMMYUNIONNAME;
DWORD TimeDateStamp; // 0 if not bound,
// -1 if bound, and real date\time stamp
// in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (new BIND)
// O.W. date/time stamp of DLL bound to (Old BIND)
DWORD ForwarderChain; // -1 if no forwarders
DWORD Name;
DWORD FirstThunk; // RVA to IAT (if bound this IAT has actual addresses)
} IMAGE_IMPORT_DESCRIPTOR;
typedef IMAGE_IMPORT_DESCRIPTOR UNALIGNED *PIMAGE_IMPORT_DESCRIPTOR;
winnt.h에 저장되어 있는 IMAGE_IMPORT_DESCRIPTOR 구조체다
보통 우리가 사용하는 프로그램들은 여러 개의 라이브러리를 임포트하고 있다.
그렇기 때문에 라이브러리의 개수만큼 구조체 배열의 형식으로 존재하고 있다.
구조체 배열의 마지막은 NULL구조체로 끝나고 있다.
중요한 멤버는 아래 표의 항목들이다.
| 항목 | 의미 |
|---|---|
| OriginalFirstThunk | INT(Import Name Table)의 주소(RVA) |
| Name | Library 이름 문자열의 주소(RVA) |
| FirstThunk | IAT(Import Address Table)의 주소(RVA) |
INT는 Import Name Table을 말한다.
IMAGE_IMPORT_BY_NAME라는 구조체 포인터 배열로 이루어져있다.
즉 INT의 원소들은 IMAGE_IMPORT_BY_NAME구조체들에 대한 주소를 가지는 것이다.
PE로더가 이 주소를 획득하여 해당 구조체로 이동, 이후 구조체를 읽어서 해당 함수의 시작 주소를 얻는 용도로 사용된다.
typedef struct _IMAGE_IMPORT_BY_NAME {
WORD Hint;
CHAR Name[1];
} IMAGE_IMPORT_BY_NAME, *PIMAGE_IMPORT_BY_NAME;이런 형태의 구조체고 Hint는 하나의 식별자 라고 생각하면 될 것이고, Name은 말 그대로 함수 이름 문자열이다.
GetProcAddress라는 함수에 Name 값을 인자로 줘서 해당 함수의 시작 주소를 찾는데 사용된다.
OriginalFirstThunk 는 이 INT의 주소(RVA값)를 가지고 있는 멤버다.
NAME에는 임포트해서 사용하는 라이브러리의 이름이 들어있다.
예를 들어서 내가 CatFish.dll이라는 라이브러리를 임포트해서 사용하고 있다면 Name 멤버에 "CatFish.dll"이 저장되어 있는 것이다.
IAT는 Import Address Table로 INT, IMAGE_IMPORT_BY_NAME 등을 이용해서 얻은 함수의 시작 주소들을 저장하는 배열이다.
-참고-
- PE 헤더에서의 Table은 배열을 의미한다.
- INT와 IAT는 long 타입(4바이트)배열이고 그 끝은 NULL로 끝난다.
- INT에서 각 원소의 값은 IMAGE_IMPORT_BY_NAME 구조체 포인터다.
- INT와 IAT의 크기는 같아야만 한다.
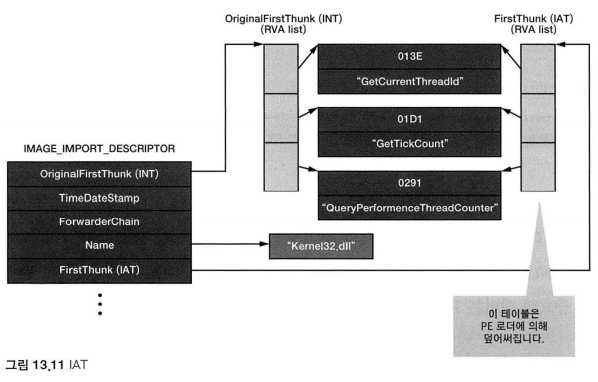
notepad.exe의 kernel32.dll(라이브러리)에 대한 IMAGE_IMPORT_DESCRIPTOR의 구조를 나타내고 있다.
PE 로더가 IMPORT하는 함수의 주소를 IAT에 입력하는 순서는 다음과 같다.
IMAGE_IMPORT_DESCRIPTOR(이하 IID)의 Name멤버를 읽어서 라이브러리의 이름 문자열(kernel32.dll)을 얻는다.- 해당 라이브러리를 메모리에 로딩한다.
- IID의
OriginalFirstThunk멤버를 읽어서 INT 주소를 얻는다. - INT에서 배열의 값을 하나씩 읽어서
IMAGE_IMPORT_BY_NAME주소를 얻는다. IMAGE_IMPORT_BY_NAME의 Hint나 Name멤버를 비교하며 원하는 함수의 시작 주소를 찾는다.
-> GetProcAddress("함수명")과 같은 방식으로 시작 주소를 얻는 것 같다.- IID의 FirstThunk(IAT)멤버를 읽어서 IAT주소를 얻는다.
- 해당 IAT 배열 값에 위에서 구한 함수 주소를 입력한다.
- INT가 끝날 때 까지(NULL)을 만날 때 까지 4-7을 반복한다.
처음 이 과정을 봤을 땐 "이게 무슨 🦮소리지..?" 싶었다.
사실 지금도 조금 헷갈리긴 하지만..
천천히 과정을 따라가다보면 이해가 갈 것이다.
IAT 파트를 크게 정리해보자면
-
프로그램에서 라이브러리 함수를 호출할 때 함수 시작 주소를 하드코딩할 경우 DLL 파일이 여러개 거나 환경에 따라 주소가 달라지기 때문에
IAT라는 주소 배열을 이용해서 호출을 한다. -
PE 파일 로딩시
IMAGE_IMPORT_DESCRIPTOR라는 구조체를 읽어서 프로그램 동작에 필요한 라이브러리를 메모리에 로딩시키고, 해당 구조체의 멤버를 읽어서 프로그램에 사용되는 라이브러리 함수들의 시작 주소를 구한다. -
2에서 구한 함수들의 시작 주소를 IAT배열에 채워넣는다.
-
프로그램 코딩 시에는 함수 호출시 주소가 실제 함수의 시작 주소가 아닌 해당 함수의 시작 주소가 들어올 IAT배열의 원소의 주소가 들어가 있다.
실제 IMAGE_IMPORT_DESCRIPTOR 배열의 위치
IID 구조체 배열은 PE 헤더가 아니라 PE 바디에 위치한다.
하지만 그곳을 찾아가기 위한 정보는 PE 헤더에 위치한다.
IMAGE_OPTIONAL_HEADER32.DataDirectory[1].VirtualAddress의 값이
IID 구조체 배열의 시작 주소가 된다.
IMAGE_OPTIONAL_HEADER32는 NT 헤더에 속하고 있다

이 부분이 DataDirectory[1]이 된다.
160~163의 주소가 VirtualAddress가 되고, 164~167부분이 Size가 된다.
해석하면 Import Directory의 RVA주소는 7604가 되는 것이고, 크기는 C8이다.
이제 한번 해당 주소로 가보자, 한데 지금 VirtualAddress는 RVA 주소다.
즉 메모리에 로딩 된 이후의 상대 주소라는 얘기고, 파일에서의 주소를 찾으려면 RVA to RAW 변환 공식을 이용해야 한다.
RAW - PointerToRawData = RVA - VirtualAddress
File Offset = 7604 - 1000 + 400 = 6A04 (16진수)
이제 6A04로 가보자.
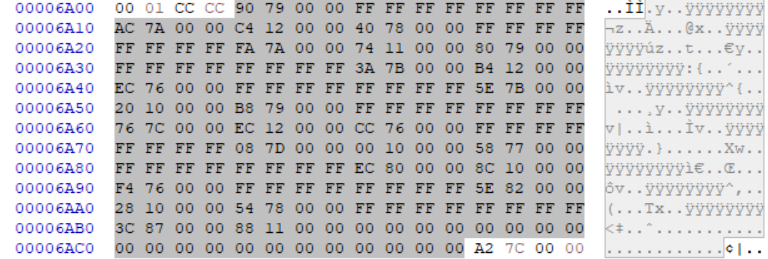
크기가 C8이라고 했으므로 6A04 ~ 6ACC 까지가 실제 Import Directory가 된다.
해당 구조체의 멤버들과 그 값들이다.
| File Offset | Member | RVA | RAW |
|---|---|---|---|
| 6A04 | OriginalFirstThunk(INT) | 00007990 | 00006D90 |
| 6A08 | TimeDateStamp | FFFFFFFF | - |
| 6A0C | ForwarderChain | FFFFFFFF | - |
| 6A10 | Name | 00007AAC | 00006EAC |
| 6A14 | FirstThunk(IAT) | 000012C4 | 000006C4 |
RAW값들은 RVA값을 공식에 대입해서 구한 파일 오프셋들이다.
일단 Name 멤버가 가리키고 있는 주소로 이동해보자(00006EAC).

오른쪽의 text를 보니 comdlg32.dll이라는 라이브러리의 이름이 보인다.
라이브러리 이름을 찾았으니, 이제 INT를 찾으러 가보자
INT의 주소는 OriginalFirstThunk가 가지고 있다고 했다.
해당 값으로 이동해보자 (00006D90).

해당 위치로 이동해보니 주소 배열로 이루어져 있는 것을 볼 수 있다.
INT의 크기가 얼만지는 모르지만 INT와 IAT는 널값으로 끝난다고 이전에 설명한 적이있기에 NULL을 만나는 부분까지가 전부 INT배열이다.
이번엔 주소 배열의 첫 번째로 따라가보도록 하자
RVA가 7A7A이므로 RWA를 계산하면 6E7A가 나온다.

6E7A의 처음 2바이트는 Ordinal 값으로 라이브러리에서 함수의 고유 번호다.
그 뒤로 'PageSetupDlgW'라는 함수 이름이 문자열이 보인다.
이 문자열을 보고 함수의 실제 주소를 획득한다.
(실제 주소 획득 방법은 EAT파트에서 나온다.)
실제 주소를 획득했다고 치고, IAT를 찾으러 가보자
IAT의 주소는 FirstThunk 멤버가 가르키고 있다.
이동해보자(000006C4)

IAT도 널값을 만날 때 까지가 배열이 된다.
드래그되어 있는 부분이 comdlg32.dll에 대한 IAT 배열 영역이다.
원소 값들이 이미 하드코딩 되어있지만 이들은 큰 의미가 없고,
PE 파일이 메모리에 로딩 될 때 우리가 위에서 구한 실제 주소값으로 대체된다.
(2)글은 거의 IAT에 대한 내용만 했는데 이 부분이 Windows리버싱에서 중요한 개념이라고 한다. 역시 중요한 부분은 어렵다..
예전에 이 파트를 공부할 때는 책만 보고 실제로 주소를 따라가 보지도 않아서 그런지 거의 이해가 안됐던 기억이 난다.
velog를 쓰면서 직접 주소를 찾아가보고 정리를 해보니 무슨 말인지 이해가 된다.
만약 이부분이 이해가 가지 않는다면 처음부터 따라가면서 한 두번정도 읽고 정리해보는 것을 추천한다.
