
HTTP 프로토콜
TCP/IP에 있는 다른 많은 프로토콜과 마찬가지로 HTTP도 서버와 클라이언트 간에 통신을 함
HTTP는 클라리언트로부터 리퀘스트가 송신되며, 그 결과가 서버로부터 리스폰스로 돌아옴
-> 반드시 클라이언트 측으로 부터 통신이 시작 됨
Request 예시
GET /index.html HTTP /1.1
Host:www.hackr.jp여기서 GET은 서버에 요구하는 종류를 나타내며 메소드 라고 불림
index.html은 요구 대상인 리소스를 나타냄 -> 리퀘스트 URI
HTTP/1.1은 클라이언트 기능을 식별하기 위한 HTTP 번호
즉 위의 예시는 HTTP 서버 상에 있는 /index.html이라는 리소스가 필요하다는 리퀘스트
리퀘스트 메세지는 메소드, URI, 프로토콜 버젼, 옵션으로 리퀘스트 헤더 필드와 엔티티로 구성되어 있음
메소드, URI, 프로토콜 버젼
POST /form/entry HTTP/1.1
리퀘스트 헤더 필드
Host : hackr.jp
Connection:keep-alive
Content-Type : application/x-www-form-urlencoded
Content-Length : 16
엔티티
name = ueno&age = 37리퀘스트를 받은 서버는 리퀘스트 내용을 처리한 결과를 리스폰스로 클라이언트에게 되돌려줌
Response 예시
HTTP /1.1 200 OK
Date : Tue,10 Jul 2012 06:50:15 GMT
Content-length:362
Content-Type:text/html
<html>HTTP /1.1인 서버의 HTTP 버젼을 나타냄
200 OK는 리퀘스트의 처리 결과를 나타내는 상태 코드와 상태 코드 설명
발생 일시는 헤더 필드 중 하나
HTTP는 Stateless
HTTP는 상태를 계속 유지하지 않는 stateless 프로토콜
-> HTTP 프로토콜 독자적으로, 리퀘스트와 리스폰스를 교환하는 동안에 상태를 관리하지 않음
즉 HTTP 프로토콜은 이전에 보냈던 리퀘스트나 이미 되돌려준 리스폰스에 대해서는 전혀 기억하지 않음
많은 데이터를 매우 빠르게 확실하게 처리하는 범위성을 확보하기 위해 간단하게 설계되어 있음
-> 하지만 스테이트리스 특성만으로는 처리하기 힘든 일들이 증가
ex)
쇼핑몰에 로그인을 하고, 다른 페이지로 이동하더라도 로그인 상태를 유지해야 함
-> 하지만 HTTP/1.1은 상태를 유지하지 않는 프로토콜
-> 이러한 니즈를 해결하기 위해 쿠키라는 기술이 도입됨
쿠키로 인해 HTTP를 이용한 통신에서도 상태를 계속 관리할 수 있게 되었음
리소스 식별
HTTP는 URI를 사용하여 인터넷 상의 리소스를 특정함
-> 이를 통해 인터넷 상의 어떤 장소에 있는 리소스도 호출 가능
클라이언트는 리퀘스트를 보낼 때 리퀘스트에 URI를 포함 시켜야 함
모든 URI를 리퀘스트 URI에 포함하는 경우
GET http://hackr.jp/index.html HTTP/1.1
HOST 헤더 필드에 네트워크 로케이션을 포함하는 경우
GET /index.html HTTP/1.1
Host:hacker.jp서버 자신에게 리퀘스트를 보내는 경우에는 리퀘스트 URI에 * 지정 가능
OPTIONS * HTTP/1.1HTTP 메서드(서버에 임무 부여)
GET : 리소스 획득
GET 메서드는 리퀘스트 URI로 식별된 리소스를 가져오게 함
리소스가 텍스트이면 그대로 반환하고, GGI와 같은 프로그램이면 실행해서 출력된 내용을 돌려줌
예시
GET /index.html HTTP/1.1
HOST : www.hackr.jp
GET /index.html HTTP/1.1
Host : www.hackr.jp
If-Modified-Since:Thu, 12 Jul 2012 07:30:00 GMTPOST : 엔티티 전송
GET으로도 엔티티를 전송할 수는 있지만, 일반적으로 POST를 사용
POST는 GET과 기능이 비슷하지만, 리스폰스에 의한 엔티티를 획득하는 것만이 목적이 아님
클라이언트 쪽에서 "이 정보를 너에게 알려줄게!"라는 느낌
POST /submit.cgi HTTP/1.1
Host : www.hackr.jp
Content-length : 1500
위에 대한 리스폰스로 submit.cgi가 수신한 데이터의 처리한 결과를 되돌려줌PUT : 파일 전송
FTP에 의한 파일 업로드와 같이, 리퀘스트 중에 포함된 엔티티를 리퀘스트 URI로 지정한 곳에 보존하도록 요구
HTTP/1.1 PUT 자체에는 인증 기능이 없어, 보안상 문제로 인해 웹사이트에서는 사용 X
-> 웹 애플리케이션 등에 의한 인증 기능과 짝을 이루는 경우나 REST와 같이 웹 끼리 연계한느 설계 양식을 사용 시 이용하는 경우 있음
POST /example.html HTTP /1.1
Host:www.hackr.jp
Content-type : text/html
Content-Length:1500
리스폰스
상태 코드 204 No Content 내려줌
(서버 상에 example.html이 작성되어 있다)POST 메소드는 지정된 리소스에 엔티티를 제출할 때 사용되며, PUT 메소드는 새 엔티티로 타겟 리소스를 대체할 때 사용
-> POST는 데이터 처리를 위해 제출할 때 사용되고, PUT은 자원을 업데이트할 때 사용
HEAD : 메세지 헤더 취득
GET과 같은 기능이지만 메세지 바디는 돌려주지 않음
-> URI 유효성과 리소스 갱신 시간을 확인하는 목적으로 사용
DELETE : 파일 삭제
PUT 메서드와 반대, 리퀘스트 URI로 지정된 리소스의 삭제를 요구
HTTP /1.1에서는 PUT과 같이 인증기능이 없어 웹사이트에서 사용 X
OPTIONS : 제공하고 있는 메소드의 문의
리퀘스트 URI로 지정한 리소스가 제공하고 있는 메서드를 조사하기 위해 사용
OPTIONS * HTTP /1.1
Host : www.hackr.jp
리스폰스
HTTP /1.1 200 OK
Allow : GET,POST, HEAD, OPTIONSTRACE: 경로 조사
요청이 서버로 전송될때, 수행된 중간 과정과 각 단계에서 수행된 작업을 추적하고자 할때 사용
리퀘스트를 보낼 때 Max-Forwards라는 헤더 필드에 수치를 포함시켜 서버를 통과할때마다 수치르 줄여감
-> 수치가 0이 된곳을 끝으로, 리퀘스트를 마지막으로 수신한 곳에서 상태 코드 200 OK 리스폰스를 되돌려줌
크로스 사이트 트레이싱과 같은 공격을 일으키는 보안성 문제로 인해 보통은 잘 사용 안함
CONNECT : 프록시에 터널링 요구
터널링은 프록시 서버를 거쳐 원격 서버와 통신할 때, 프록시 서버가 요청과 응답을 암호화하고 압축하는 기능을 의미
프록시에 터널 접속 확립을 요함으로써, TCP 통신을 터널링하기 위해 사용
-> 프록시 서버는 클라이언트와 서버 사이의 중개 컴퓨터, 클라이언트로부터 요청을 받아, 그 요청을 클라이언트의 이름으로 적절한 서버에 전송
-> 네트워크 성능 개선, 특정 웹 사이트 접근 차단, 보안 강화 등 다양한 목적으로 사용
주로 SSL(HTTPS)/TLS 등의 프로토콜로 암호화된 것을 터널링 하기 위해 사용
CONNECT 프록시 서버 : 포트 HTTP 버젼CONNECT 메서드는 일반적으로 프록시 서버를 통해 HTTPS 요청을 처리할 때 주로 사용
-> 이를 위해 프록시 서버는 요청을 웹 서버로 전송하고, 웹 서버로부터 응답을 받아 클라이언트로 전송
| 메소드 | 설명 | 제공하고 있는 HTTP 버전 |
|---|---|---|
| GET | 리소스 취득 | 1.0, 1.1 |
| POST | 엔티티 바디 전송 | 1.0, 1.1 |
| PUT | 파일 전송 | 1.0, 1.1 |
| HEAD | 메세지 헤더 취득 | 1.0, 1.1 |
| DELETE | 파일 삭제 | 1.0, 1.1 |
| OPTIONS | 서포트하고 있는 메서드 문의 | 1.1 |
| TRACE | 경로 조사 | 1.1 |
| CONNECT | 프록시에 터널링 요구 | 1.1 |
| LINK | 리소스 간에 링크 관계 확립 | 1.0 |
| UNLINK | 링크 관계 삭제 | 1.0 |
LINK,UNLINK는 폐기됨
지속 연결로 접속량을 절약
TCP 커넥션 연결
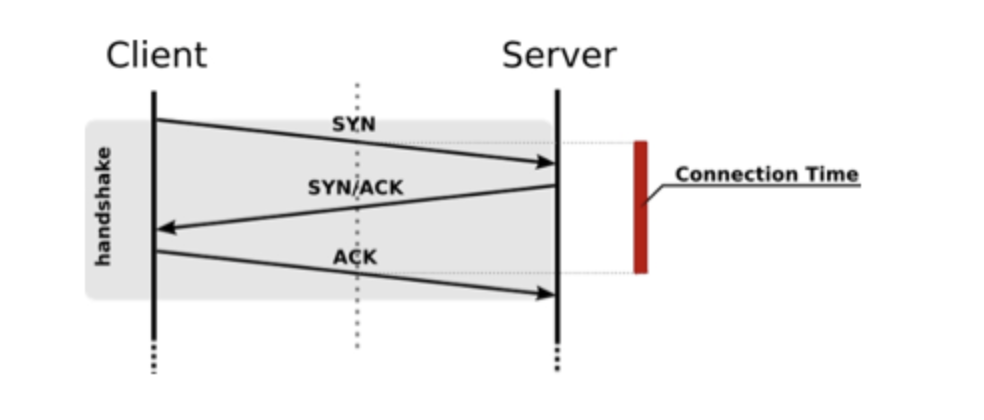
TCP 커넥션 종료

HTTP 초기 버젼에서는 HTTP 통신을 한번 할때마다 TCP에 의해 연결 및 종료를 했었음
-> 작은 사이즈의 텍스트를 보내는 경우에는 문제가 없음
하나의 HTML 문서에 여러 개의 이미지 등이 포함된 웹페이지를 리퀘스트하면 다량의 통신 발생
- TCP 커넥션 연결
- HTTP 리퀘스트/리스폰스
- TCP 커넥션 종료
위 3과정이 HTML 문서를 획득할 때, 이미지 획득, 다른 이미지 획득 .... 할때마다 반복됨
-> 이를 해결하기 위해 지속 연결 방법을 고안
-> 이는 어느 한쪽이 명시적으로 연결을 종료하지 않는 이상 TCP 연결을 계속 유지하는 방법
지속 연결
지속 연결은 1회의 TCP 커넥션 연결로 리퀘스트와 리스폰스 교환을 여러번 함
- TCP 커넥션 연결(SYN, SYN/ACK, ACK)
- HTTP 리퀘스트, 리스폰스 과정 여러번 반복
- TCP 커넥션 종료(FIN, ACK, FIN, ACK)
지속 연결의 경우 TCP 커넥션의 연결과 종료를 반복되는 오버헤드를 줄여주기 때문에 서버에 대한 부하가 경감됨
-> 웹 페이지 빨리 표시
파이프라인화
지속 연결은 여러 리퀘스트를 보낼 수 있도록 HTTP pipelining화를 가능하게 함
-> 파이프라인화로 인해, 이전에는 리퀘스트 송신 후에 리스폰스를 수신할때까지 기다린 뒤에 리퀘스트를 보낸 반면, 리스폰스를 기다리지 않고 바로 다음 리퀘스트를 보낼 수 있음
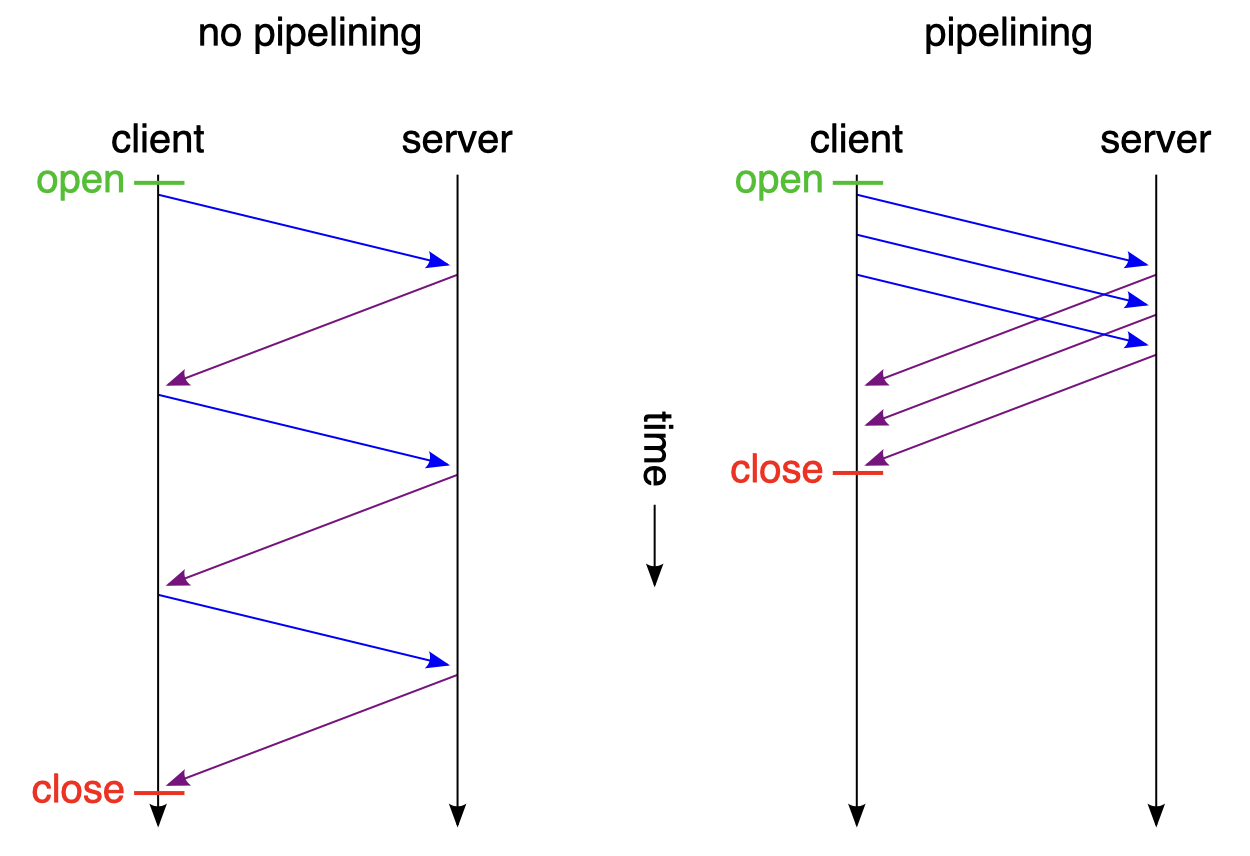
예를들어, HTML 한페이지에 10개의 이미지를 포함한 웹페이지를 리퀘스트한 경우, 개별 연결보다 지속 연결이 리퀘스트 완료가 빠르고, 지속 연결보다 파이프라인화 쪽이 빠름
쿠키를 사용한 상태 관리
HTTP는 스테이트리스 프로토콜이기 때문에, 과거에 교환했었던 리퀘스트와 리스폰스의 상태 관리 X
-> ex) 인증이 필요한 웹 페이지에서 상태 관리를 하지 않는다면 인증 마친 상태를 잊어버리기 때문에, 새로운 페이지를 이동할때마다 재차 로그인 정보를 보내든지, 리퀘스트마다 매개변수나 추가 정보를 붙여서 로그인 상태를 관리해야 함
stateless 프로토콜은 상태를 유지하지 않아, 서버의 CPU나 메모리 같은 리소스의 소비를 억제한다는 이점이 존재
쿠키란 리퀘스트와 리스폰스에 쿠키 정보를 추가해서 클라이언트의 상태를 파악하기 위한 시스템
쿠키는 서버에서 리스폰스로 보내진 Set-Cookie라는 헤더 필드에 의해 쿠키를 클라이언트에 보존함
-> 이후 클라이언트가 같은 서버로 리퀘스트를 보낼 때, 자동으로 쿠키 값을 넣어서 리퀘스트 송신
-> 이때 서버는 클라이언트가 보낸 쿠키를 확인해서 어느 클라이언트가 접속했는지 체크하고 서버 상의 기록을 확인해서 이전 상태를 확인 가능
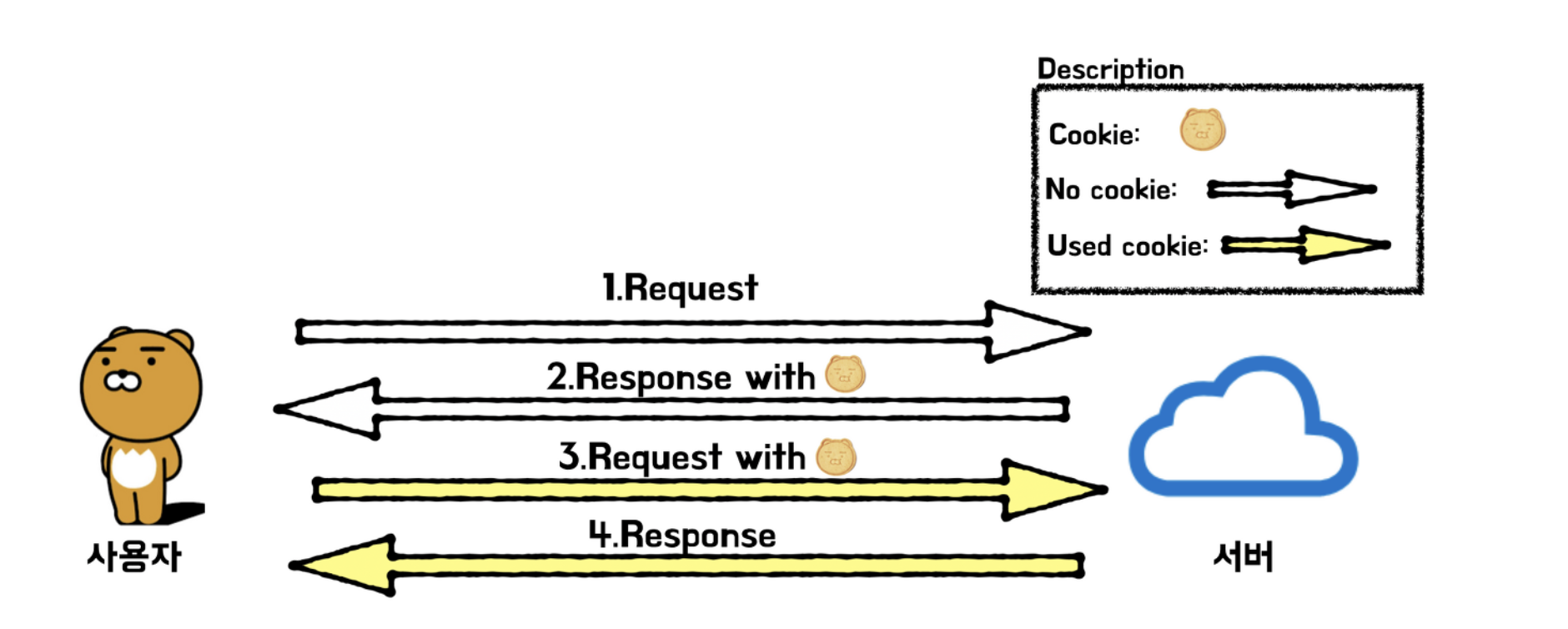
처음 리퀘스트 (쿠키를 가지고 있지 않은 상태)
GET /reader/ HTTP/1.1
HOST:www.youngjin.com
* 헤더 필드에 쿠키 X리스폰스(서버가 쿠키를 발행하여 클라이언트 쪽에 보관)
HTTP /1.1 200 OK
Date, Thu, 12 Jul 2012 07:12:20 GMT
Server : Apache
(Set-Cookie : sid = ~~: path : ~~ => 10-OCT-12 07:12:20 GMT>
Content-Type : text/plain: charset=UTF-8이후 리퀘스트(보관하고 있던 쿠키를 자동 송신)
GET /image/ HTTP /1.1
HOST : www.youngjin.com
Cookie : sid=1342077140226724