SQL은 주로 DBMS에 저장된 테이블을 조작하기 위해 사용
-> 테이블은 스키마에 저장되어 있음(Mysql에서는 데이터베이스와 같다!)
데이터베이스에서 테이블을 살펴보려면
show databases;
use 데이터베이스명
show tables;데이터베이스가 다르면 같은 이름의 테이블을 작성할 수 있음!
데이터베이스명.테이블명 형태로 명시적으로 선택 가능
// 밑 두 구문은 같은 역할
select distinct district from city where countrycode = 'KOR';
select district from city where countrycode = 'KOR' group by district;COUNT, SUM, AVG, MAX, MIN과 같은 집약함수는 기본적으로 NULL을 제외하고 집계하지만, COUNT 함수만은 COUNT(*)로 표기하여 NULL을 포함한 전체 행을 집계
GROUP_CONCAT 함수
컬럼에 저장된 내용을 하나의 문자열로 가져와야하는 경우에 사용하는 함수가 GROUP_CONCAT 함수
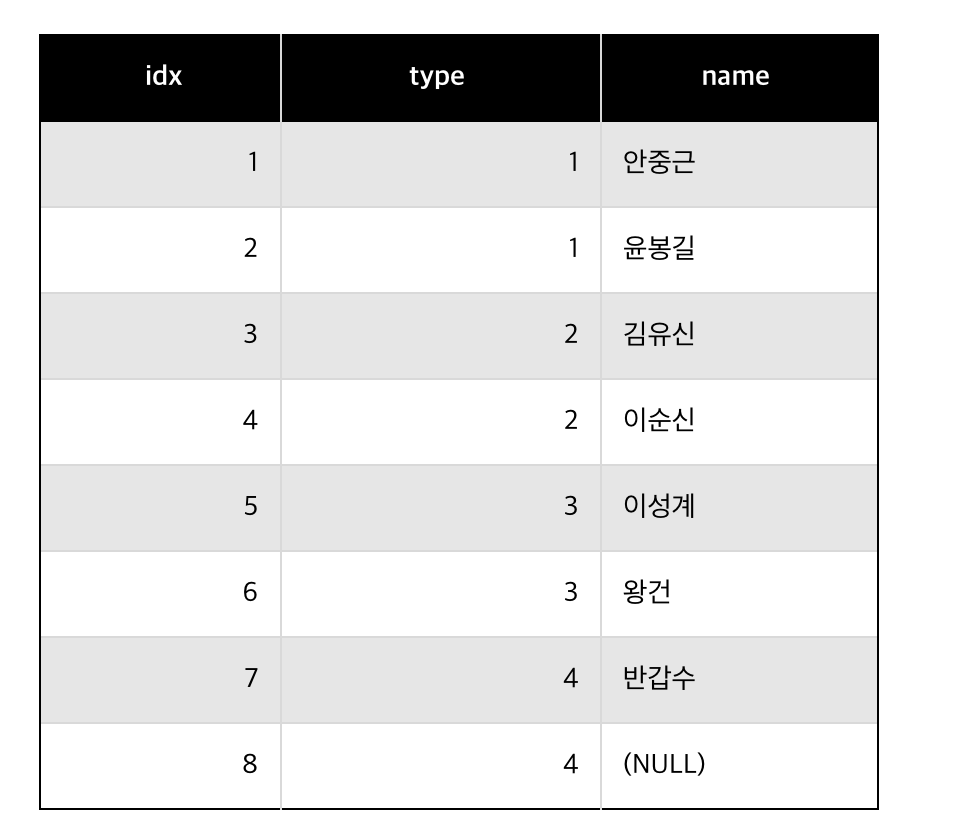
SELECT GROUP_CONCAT(name, ":", type) AS hero_string FROM hero_collection;
안중근:1,윤봉길:1,김유신:2,이순신:2,이성계:3,왕건:3,반갑수:4위 함수의 경우 중복되는 값이 있어도 여러개 출력될수 있는데 이때는 DISTINCT 키워드를 추가하자
만약 테이블과 같은 구조의 테이블을 작성하고 싶다면(데이터는 없음)
create table citycopy like city;뷰를 작성하고 복수 테이블에서 선택하기
뷰란 데이터를 가지고 있지 않은 일종의 가상 테이블
예를 들어 경기도(countrycode = "KOR" and district = "kyonggi")의 id,name,population을 표시하는 뷰를 작성한다 가정
create view citykyonggi as select id, name, population from city
where countrycode = "KOR" and district = "kyonggi"이때 작성한 뷰는 SQL문으로 접근시에는 테이블과 다르지 않음
select * from citykyonggi;서브쿼리 예시
create view citykorea as select id, name, district, population from city
where countrycode = "kor";
// 위 뷰에서 인구가 평균 이상인 도시 세기
select count(*) from citykorea where population >
(select avg(population) from citykorea);
// 각 행정구역 내에서 인구가 평균보다 많은 도시를 집어냄
select district, name, population from citykorea as c1 where population >
(select avg(population) from citykorea as c2 where c1.district = c2.district group by district);뷰는 SQL 시점에서 보면 테이블과 동일하지만, 테이블과 같은 데이터는 가지고 있지 않으며,단지 테이블에 대한 SELECT를 가지고 있음
장점
- 복잡한 SELECT 문을 일일이 매번 기술할 필요 없음
- 필요한 열과 행만 사용자에게 보여줄수 있고, 갱신 시에도 뷰 정의에 따른 갱신으로 한정할 수 있다
- 위 이점들을 데이터 저장 없이(기억장치 용량을 사용하지 않고) 실현 가능
- 뷰를 제거해도 참조하는 테이블은 영향을 받지 않음
CREATE VIEW 뷰 명 (열명1, 열명 2 ..... ) AS SELECT 문;뷰로의 입력, 갱신의 제한
어떤 행이 대응하는지 모르거나 어떤 값을 넣으면 좋을지 모르는 경우에는 갱신 불가
-> ex) GROUP BY로 집약한 수치나 distinct로 얻은 값을 갱신하는 경우에는 결과의 기반이 되는 테이블의 n행 중 어떤 수치를 갱신하는 것이 좋을지 알수 없음
-> 또한 2가지 이상의 테이블을 조합해 작성한 뷰를 갱신할 때는 어느 테이블을 갱신하면 좋을지 알수 없는 경우가 있음
