성능의 두가지 지표
-
처리 시간(응답 시간)
ex) 일괄 처리에 1시간이 걸렸다, 웹사이트 표시하는데 5초가 걸린다 처럼 어떤 특정 처리의 시작부터 종료까지 걸린 시간을 나타냄 -
처리율
속도 개념(단위 시간이 포함됨), ex) 트랜잭션을 단위 시간에 몇건 처리 가능한가에 대한 측정 단위를 나타냄
(트랜잭션 초당 50건 처리시 50TPS : Transaction Per Second)
처리율이 성능에서 중요한 이유는 시스템의 자원 용량을 결정하는 요인이기 때문
-> 처리율이 높은 시스템일수록 CPU나 메모리 같은 하드웨어 자원이 매우 필요한것을 의미
-> 동시에 실행하는 사용자 수가 많아질수록 필요한 물리자원도 증가
한 가지의 자원이라도 한계에 이른 시점에는 응답시간이 상승하고 처리율이 떨어지는데, 이때 최초로 한계에 이른 자원을 버틀넥 포인트(병목)이라고 함
-> 즉 동시에 실행되는 처리가 가장 많은 순간을 설정해서 자원을 준비하지 않으면 정점일때 극단적인 지연을 일으키게 됨
-> 이렇게 처리율과 응답시간이 극단적으로 나빠지는 시점을 한계점이라고 함
-> 정점을 상정한 자원을 확보해 두는 것을 Sizing, Capacity Planning 이라고 함
엑세스 집중도를 파악하기 쉬운 시스템의 경우엔 문제가 없지만, 정점이 정기적이지 않는 온라인 상거래나 게임 사이트는 특별 세일과 같은 이벤트에 발생하므로 어느 정도 엑세스가 집중될지 예측하기 어려움
-> 또한 정점이 아닐 때와 필요한 자원량이 정점일때 필요 자원량에 차이가 커서 정점에 맞춘 자원을 준비하면 역으로 평상시에는 자원이 낭비되는 문제 발생
-> 이 처럼 돌발형 엑세스 집중에 대응하는 수단의 한가지로 주목 받은 것이 클라우드
클라우드란 가상화를 기반으로 자원량을 유연하게 변동할 수 있는 기술
데이터베이스와 병목의 관계
데이터베이스는 시스템에서 가장 병목이 되기 쉬운 포인트
- 취급하는 데이터양이 가장 많음
최근들어 데이터의 폭발의 경향이 강해짐에 따라 데이터를 보존하는 저장소 자원에서 병목이 일어나는 경우가 많음
- 자원 증가를 통한 해결이 어려움
데이터베이스는 클라우드같이 동적으로 자원을 증감할 수 있는 아키텍처를 적용하기 힘듬
-> DB의 병목지점은 CPU나 메모리가 아닌 저장소(하드디스크), 저장소는 스케일 아웃이 어려움( DB는 기본적으로 Active-StandBy, Active-Active 구성 밖에 취할 수 없음)
-> 저장소를 포함해 스케일 아웃이 가능한 것은 Shared Nothing 뿐인데 이를 적용할 수 있는 요건은 한정되어 있음(MySQL에서 리플리케이션을 스케일 아웃 대용으로 하는 전략이 주로 적용된 이유)
이러한 제한때문에 데이터베이스에서는 튜닝 기술이 발달
-> 튜닝이란 애플리케이션을 효율화해 같은 양의 자원이라도 성능을 향상하게 하는 기술
-> 자원 추가에 따른 성능 문제 해결은 어려우므로 주어진 자원 범위 내에서 융통성있게 처리하는 것이 중요하다
DB SQL문 결과 통지
데이터베이스 SQL 문을 받아 사용자에게 결과를 통지할때까지의 과정을 알아보자!
파스
데이터베이스는 SQL 문을 받으면 이 SQL 문이 문법적으로 잘못된 부분이 없는지 점검
-> 이러한 동작을 파스(parse)라고 함(담당하는 프로그램은 parser)
parse 시점에서 구문에 오류가 발견된다면 DB는 SQL문을 오류 메세지와 함께 사용자에게 되돌림
-> SQL문을 실행하는 내부 프로세스의 제 1단계는 parse
-> parse를 무사히 통과하면 DB는 이 SQL문으로부터 어떠한 플랜을 세우려고 함 (SQL 문에 필요한 데이터를 어떤 경로로 접근 할지)
옵티마이저
위와 같이 세우는 계획을 실행계획 또는 엑세스 플랜이라고 하며, 실행 계획을 결정하는 내부 프로그램을 옵티마이저(Optimizer)라고 함(최적화)
-> 실행 계획을 세운다는 프로세스를 자신이 수행하는 것이 RDB의 큰 특징
-> C나 JAVA와 다르게 SQL 문에는 데이터를 특정하는 조건만 쓰여 있을 뿐 어떻게 해서 그 데이터를 입수할지에 대한 수단을 생각하는 것은 DB(옵티마이저) 스스로
한개의 SQL에서 가능한 실행계획은 복수개가 있어서 이중에서 어떤 것이 가장 효율적인지는 인간보다 컴퓨터쪽이 정확하면서 고속으로 계산 가능
-> 보통은 옵티마이저에게 실행계획을 맡기지만, 엔드 사용자가 hint를 통해 실행 계획을 지정한는 것도 가능(기본적으로는 해서는 안된다고 합의된 사항)
통계정보
옵티마이저, 실행계획과 더불어 또 하나 성능에 큰 영향을 주는 개념은 통계정보(Statistics)
통계정보란 옵티마이저가 실행계획을 세울때 참고하는 정보
통계정보에 포함되는 데이터 예시
- 테이블의 행수,열수
- 각 열의 길이와 데이터형
- 테이블의 크기
- 열에 대한 기본키나 NOT NULL 제약의 정보
- 열 값의 분산과 편향 등등
옵티마이저는 이와 같은 데이터를 입력으로 해서 SQL 문에서 고속화할수 있는 실행 계획을 세움
- 파스 -> 2. 실행계획 작성(통계정보 참조) -> 3. 실행계획 평가 -> 4. 데이터 엑세스
통계정보를 참조하지 않고 직접 테이블에서 정보를 얻으면 좋지 않을까?
-> 통계 정보란 테이블에 들어있는 데이터를 샘플링 추출해서 계산한 것이라 완전히 정확한 정보 X
->물론 테이블의 전체 데이터를 참조하는 편이 정확한 데이터를 입수하는데 좋지만 데이터 수집 시간이 너무 오래 걸림
-> 테이블 크기가 크면 참조할때(== SQL 문 실행) 실행만으로 수분에서 수십분이 걸림
통계정보 수집이라는 것은 SQL 문을 고속으로 실행할 수단을 찾기 위한 준비작업
-> 이러한 준비작업이 오래 걸린다는 것은 배보다 배꼽이 큰 상황
-> 통계정보의 다소 부정확함은 눈감아줘도 충분한 속도를 얻을 수 있음
통계정보는 다음 명령으로 볼 수 있다
show table status;
show index from 테이블명;예시


결과로 인덱스의 일람과 그 속의 통계정보가 일부 표시됨
->ex) Cardinality; 인덱스 대상의 분산이나 편향을 의미
SQL문의 실행계획을 취득하는 방법
-> SQL 문 앞에 EXPLAIN을 붙이면 됨

table 열은 데이터의 취득 대상인 테이블을 의미
row 열은 해당 SELECT 문이 엑세스한 레코드의 행수임
type 열을 보면 ALL이라고 나와있음
-> 이는 테이블에 대한 엑세스 방법을 나타냄
-> 테이블 엑세스 방법으로는 풀스캔(ALL)과 레인지 스캔(range) 2가지가 있다
풀스캔은 테이블에 포함된 레코드를 처음부터 끝까지 읽어들이는 방법
레인지 스캔은 테이블의 일부 레코드만 엑세스 하는 방법
-> 관계형 DB에서 엑세스 방법은 기본적으로 2가지 패턴밖에 없음


인덱스를 사용하면 풀 스캔을 하지않고 레인지 스캔을 함으로 검색과 질의에 대한 처리가 빠르게 이루어짐
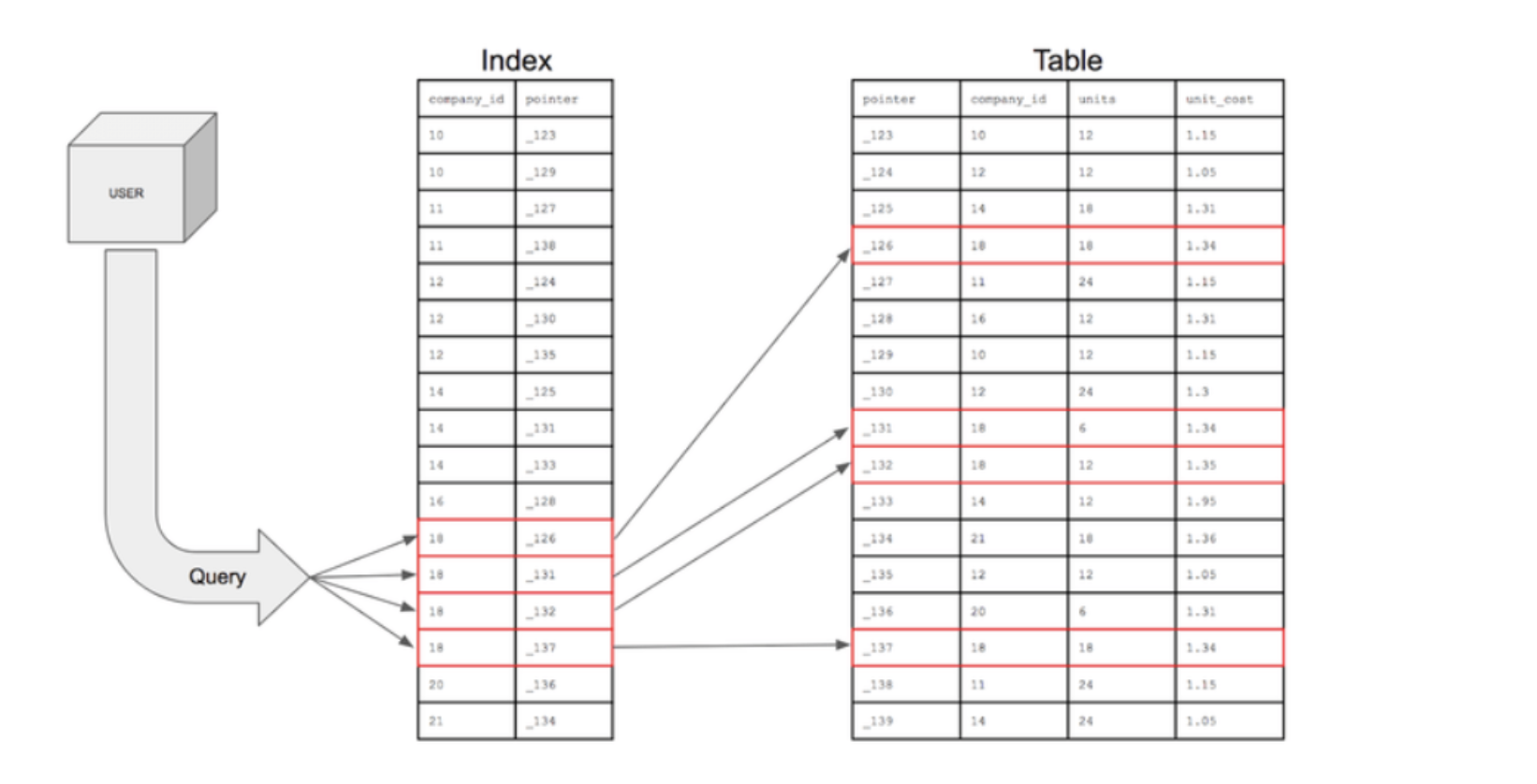
possible_keys와 key 영역은 풀스캔때는 NULL이지만, 레인지 스캔에서는 둘다 PRIMARY라는 키워드가 표시
-> 레인지 스캔 시에는 인덱스가 필요
-> 책을 비유로 들지만, 인덱스가 없으면 어떤 단어가 서적의 몇 페이지에 있는지 알수 없어서 전체책을 읽어 봐야함
-> 즉 적절한 인덱스가 없으면 DB는 어쩔수 없이 풀 스캔을 해야 함
PRIMARY라는 키워드는 인덱스를 사용함을 의미
-> DBMS에서 기본키를 구성하는 열에는 반드시 인덱스가 작성되어 있음
예를 들어 City 테이블에 ID열이 기본키이고 이에 대한 인덱스가 존재한다고 가정하자
-> 가령 ID이외의 열을 WHERE 구에서 범위 축소 조건으로 한다해도 Range Scan이 되지 않음
풀스캔을 하지 않기 위해 인덱스를 만든다 가정
CREATE INDEX ind_district ON City(district);인덱스를 만든 후 해당 열에 쿼리로 질의를 할때, 인덱스를 사용하라는 지시를 DBMS에 수행하지 않아도 옵티마이저에서 어떠한 실행계획이 더 빠를지 판단하고, 자동으로 인덱스를 사용하는 실행계획으로 바뀜
인덱스를 사용하면 SQL문을 변경하지 않아도 성능을 개선할 수 있고, 테이블의 데이터에 영향을 주지 않으며, 일정한 효과를 기대 가능
기본키의 인덱스나 직접 만든 인덱스는 BTREE로 되어있음
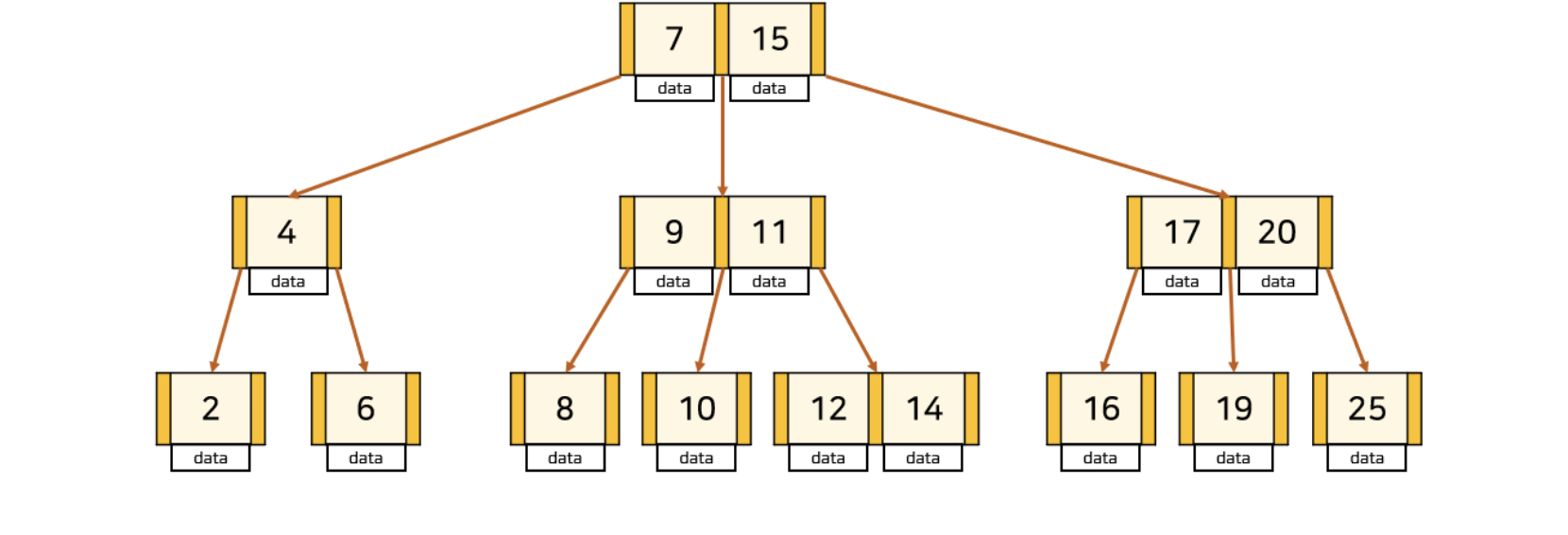
B-TREE
BTREE란 관계형 DB에서 튜닝의 기본이 되는 인덱스, 데이터가 순서를 유지하고 있다는 것이 핵심
트리 구조는 DB에 한정하지 않고, 시스템 세계에서 데이터를 유지하기 위해 자주 사용하는 구조
-> 특정 데이터를 찾는 것에 매우 효율적이고, 단시간 내 실행 가능
예를들어 배열이 데이터가 정렬된 상태로 있지 않다면, 가장자리에서 부터 하나씩 조사하는 방법밖에 없음 -> 이는 선형 탐색
위 경우 운이 좋으면 빨리 찾을수 있지만, 최악의 경우 n번 만큼 탐색을 진행할 수도 있다
-> 반면 트리구조는 동일한 열에 대한 검색 대상의 값에 따른 성능차가 거의 나지 않음
B-TREE는 기본적으로 균형 트리 형태(루트로부터 리프까지의 거리가 일정)를 유지하고 있음
-> 하지만 갱신이 반복되면 서서히 균형이 깨지게 되는데, 이때는 정기적으로 인덱스 재구성을 해서 트리의 균형을 찾는 작업이 필요
-> 또한 데이터양이 증가할수록 우수한 개선 효과를 발휘(로그 함수 형태)
쓸데없이 많이 만든 인덱스는 데이터베이스 설계의 안티 패턴의 한가지
- 인덱스 갱신의 오버헤드로 갱신 처리의 성능이 떨어짐
인덱스는 테이블에 새로운 데이터가 추가되거나, 기존의 데이터에 대해 갱신 제거가 실행되면 자동으로 인덱스 자신도 갱신하는 기능을 갖춤
-> 기능 자체는 우수하지만, 갱신할때마다 인덱스 갱신도 부수적으로 발생한다는 것을 인지해야 함!
- 의도한 것과 다른 인덱스가 사용됨
사용할 인덱스가 많으면 옵티마이저도 인간처럼 해매게 됨
인덱스를 만들때 기준
-
크기가 큰 테이블만 만든다
작은 테이블은 풀이던 레인지이던 큰 의미 없음 -
기본키 제약이나 유일성 제약이 부여된 열에는 불필요
위 경우 자동으로 인덱스가 작성되어 있음 -
카디널리티가 높은 열에 만든다
카디널리티란 값의 분산도를 나타내는데 , 특정 열에 대해 많은 종류의 값을 가지고 있다면 카디널리티가 높다
