문자열 처리(결합)
String s1 = "Hello";
String s2 = " Java";
System.out.print(s1+s2);
문자열 처리(일부 떼어내기)
-> text.subString(0,2); ==> string 자릿수 0 ~ (2미만) 까지.
String s1 = "Hello";
System.out.println(text.substring(0, 1));
System.out.println(text.substring(2, 4));
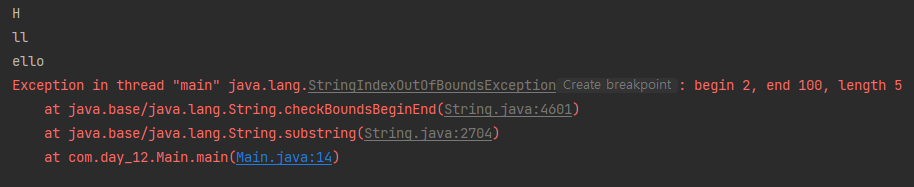
System.out.println(text.substring(1));
System.out.println(text.substring(2, 100)); // 범위를 벗어나면 오류생김.
문자열 처리(일부 치환)
String s1 = "HELLO";
System.out.println(s1.replace("LL", "XX"));
-> LL을 XX로 바꿔줌.
문자열 처리(분리)
아래 코딩은 String s1의 문자열을 ","이 나올때마다 ,이 나오는 부분전부분까지 배열 Splited[0]부터 차례대로 넣는다. 제일 끝 문자열은 ,이 있어도 없어도 상관없이 넣는다.
String s1 = "1,2,3";
String splited[] = s1.split(",");
for (String s : splited) {
System.out.println(s);
}
문자열 처리(대소문자 변경)
string.toLowerCase(); => 소문자로 변경
string.toUpperCase(); => 대문자로 변경
문자열 처리(내용 비교)
String string0 = "hello", String string1 = "HELLO" 일 때
string0.equals(string1) -> false
string0.equalsIgnoreCase(string1) - > true
equalsIgnoreCase는 대소문자를 무시하고 비교한다.
문자열 처리(검색)
String s1 = "HELLO";
System.out.println(s1.indexOf('E')); -> 1출력 ('H'는 0출력됨. 일치하는게 없는경우 -1 출력.)
문자열이 들어간 위치를 출력해줌. 중복이 있는경우 처음 발견한것만 가능. 다른 문장을 찾는방법은 검색하도록.
문자열 처리(길이)
string.length() -> 문자열 길이 출력.
string.isEmpty() -> 문자열 길이가 0인지 아닌지 출력
string.isBlank() -> 문자열 길이가 0인지 또는 공백으로만 되었는지 출력
"123".contains(string) -> string 문자열에 123이 포함되어 있는지 아닌지 출력
endsWith() : 끝나는 단어가 맞는지
indexOf() : 단어가 몇 번째에 있는지
lastIndexOf() : 뒤에서 몇 번째에 단어가 있는지
trim() : 좌우 공백 제거
replace("a","b") : string에 a라고 적힌부분을 b로 바꿔줌.
StringBuilder
append()메서드로 결합한 결과를 내부 메모리(버퍼)에 담아두고 toString()으로 결과같을 얻는다.
메서드 체인. StringBuilder sb = new StringBuilder();로 선언된 sb를 append할때
sb.append("a").append("b").append("c")....; 이렇게 이어가도 된다.
정규표현식
- 정규표현식 문장이 되는지 확인 또는 예시,메뉴얼 보는 사이트 : https://regexr.com/
- c에서 정규표현식 사용하는 예시 : https://stackoverflow.com/questions/1085083/regular-expressions-in-c-examples
- 나무위키 정규표현식 참고
https://namu.wiki/w/%EC%A0%95%EA%B7%9C%20%ED%91%9C%ED%98%84%EC%8B%9D?from=%EC%A0%95%EA%B7%9C%ED%91%9C%ED%98%84%EC%8B%9D#s-3.1
tip
1." "내에서 역슬래시를 표현하고 싶으면 역슬래시를 두번 써주고 "[ ]"안에 쓰고싶으면 역슬래시는 4번 적어주면 된다.
2. "^U." , "^[UBJ]."
=> ^U.* 문자열 첫글자는 U 이여야하고 나머지 뒤에는 문자열이 몇개가 와도 상관이 없다는 뜻
=> "^[UBJ]D$" 은 문자열 첫글자는 U,B,J중에서 하나여야하고 끝은 D여야 한다는 뜻.
=> ^은 바로 뒤에 오는 글자가 문자열 첫글자. $앞에 오는 문자가 문자열 마지막글자 의미.
예시
package com.day_12;
public class Quiz {
public static void main(String[] args) {
문제1();
문제2();
문제3();
}
private static void 문제3() {
String s1 = "";
String s2 = "A1";
String s3 = "UDFSdfd";
//.*은 모든 문자열을 의미. ""도 포함.
if(s1.matches(".*")) {
System.out.println("3-1번문제 됨");
}
// ^A는 문자열 맨앞은 A로 시작
// \d(""에서는 \\d로 적어야 \d라는 뜻.)는 모든숫자를 의미한다.[0-9]와 같음.
// [0-9]?는 [0-9]중 하나를 적어도 되고 아무것도 없어도 된다는 의미.
if (s2.matches("^A\\d[0-9]?")) {
System.out.println("3-2번문제 됨");
}
// ^U는 문자열 맨앞은 U로 시작
// [A-Z]{3}에서 [A-Z]는 A~Z까지중 문자하나를 의미하고 {3}은 앞의 문자 3개반복을 의미.
// ^U[A-Z]{3}의미는 문자열 첫문자는 U이고 2~4번째 문자는 영어대문자이어야 한다는 뜻.
// .*은 아무문자를 몇글자고 적어도 된다는뜻. 즉, 여기에서는 [A-Z]{3}과 d$사이에는 어떤문자가 몇글자든 들어와도 상관없다는 뜻
// d$은 문자열 끝은 d로 끝나야 한다는 뜻.
if(s3.matches("^U[A-Z]{3}.*d$")) {
System.out.println("3-3번문제 됨");
}
}
public static void 문제2() {
String s0 = new String("C:\\dev");
String s1 = new String("abc.txt");
StringBuilder sb = new StringBuilder();
String words[];
if (isValidSlash(s0)) {
sb.append(s0).append("\\").append(s1);
}
else{
sb.append(s0).append(s1);
}
String s = sb.toString();
System.out.println(s);
}
public static boolean isValidSlash(String string) {
return !string.matches(".*\\$"); //앞에 어떤문자든 몇글자든 상관없고 끝글자가 역슬래시일때 false출력한다.
}
private static void 문제1() {
StringBuilder sb = new StringBuilder();
String splitedByComma[];
for (int i = 0; i < 101; i++) {
sb.append(i).append(",");
// if(i != 100){ //위에 append(",") 없애고 이거 키면 100뒤에 "," 생성안됨
// sb.append(",");
// }
}
String s = sb.toString();
System.out.println(s);
}
}
