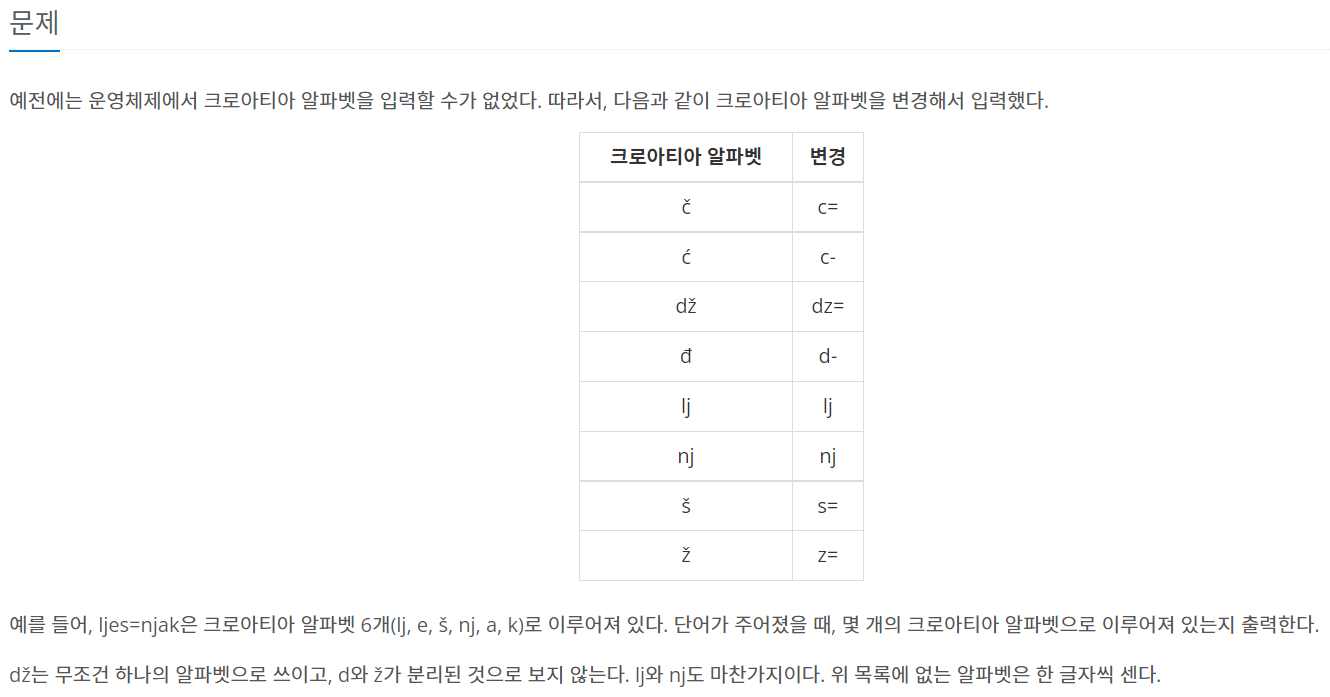
💡문제접근
크로아티아 알파벳과 대응되는 부분을 하나로 처리하기 위해 replace()를 사용했다.
replace() 함수의 결과값을 따로 저장하지 않아 약간 시간을 허비했던 문제였다.
💡코드(메모리 : 30616KB, 시간 : 40ms)
word = str(input())
word = word.replace("c=", "*")
word = word.replace("c-", "*")
word = word.replace("dz=", "*")
word = word.replace("d-", "*")
word = word.replace("lj", "*")
word = word.replace("nj", "*")
word = word.replace("s=", "*")
word = word.replace("z=", "*")
print(len(word))