*공부한 내용을 토대로 혼자서 정리하는 글입니다.
틀린 부분이나 보충할 부분 지적 언제든 환영합니다 :)
클라이언트-서버 아키텍처
1. 서버란?
- 서버(server)는 영어 단어 그대로 제공(serve)하는 주체
- 클라이언트에게 네트워크를 통해 정보나 서비스를 제공하는 컴퓨터 시스템으로
컴퓨터 프로그램 (Server program) 또는 장치(Device)를 의미
2. 서버를 쓰는 이유?
- 서버를 사요하지 않을 시 클라이언트가 모든 리소스를 가지고 있어야 하므로 새로운 리소스가 추가될 때마다 업데이트를 해야함
- 따라서 리소스를 제공하는 '서버', 리소스를 사용하는 '클라이언트'를 따로 분리하는게 좋음
- 리소스가 존재하는 곳과 리소스를 사용하는 앱을 분리시킨 것을
2티어 아키텍처, 또는클라이언트-서버 아키텍처라고 부름
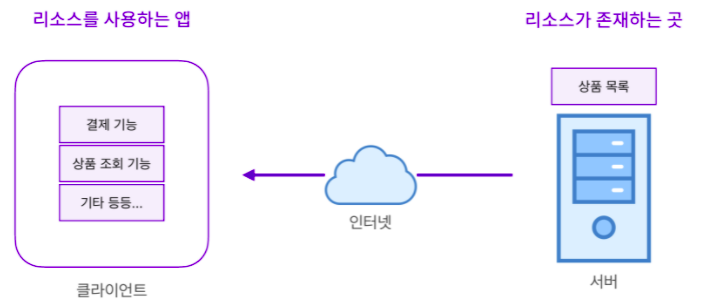
3. 클라이언트는 리소스를 어떻게 사용하는가?
- 클라이언트는 먼저 서버에게 리소스를 "요청"을 하고, 요청을 받은 서버는 리소스를 담아 "응답"을 함
- 요청을 하지도 않았는데 응답이 오는 경우는 없음
- but, 간혹 서버에서 일방적으로 클라이언트에 정보를 전달하는 경우가 있음( ex ) 쿠키 )
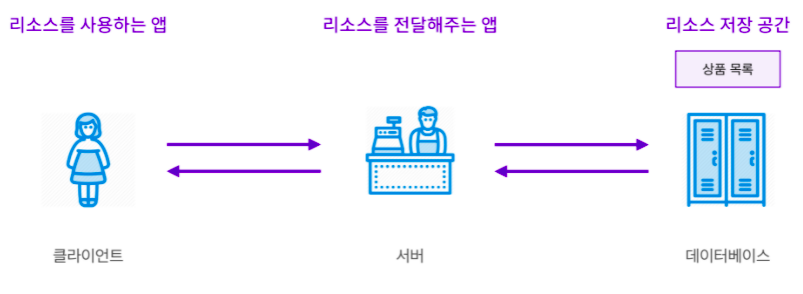
4. 3티어 아키덱처
- 일반적으로 서버는 리소스를 전달해 주는 역할만 담당함
- 따라서 리소스를 저장하는 공간을 별도로 마련해 두는데 이 공간을 "데이터베이스"라고 부름
-
2티어 아키텍처에 데이터베이스를 추가한것을3티어 아키텍처라고 부름
URL과 URI
1. URL(Uniform Resource Locator)이란?
- 네트워크 상에서 웹 페이지, 이미지, 동영상 등의 파일이 위치한 정보를 나타냄
- scheme, hosts, url-path로 구분
2. URI(Uniform Resource Identifier)이란?
- URL의 기본요소인 scheme, hosts, url-path에 더해 query, bookmark를 포함
∴ 'URL은 URI다.' 는 참이고, 'URI는 URL이다.' 는 거짓
3. URL과 URI의 구성
부분 명칭 설명 file://,http://,https://scheme 통신 프로토콜 127.0.0.1,www.google.comhosts 웹 페이지, 이미지, 동영상 등의 파일이 위치한 웹 서버, 도메인 또는 IP :80,:443,:3000port 웹 서버에 접속하기 위한 통로 /search,/Users/username/Desktopurl-path 웹 서버의 루트 디렉토리로부터 웹 페이지, 이미지, 동영상 등의 파일이 위치까지의 경로 q=JavaScriptquery 웹 서버에 전달하는 추가 질문

IP, Port
1. IP
- 컴퓨터 네트워크에서 장치들이 서로를 인식하고 통신을 하기 위해서 사용하는 특수한 번호
- 인터넷에 연결된 모든 PC는 IP 주소체계를 따라 네 덩이의 숫자로 구분 (= IPv4)
- IPv4는 Internet Protocol version 4의 줄임말로, IP 주소체계의 네 번째 버전을 뜻
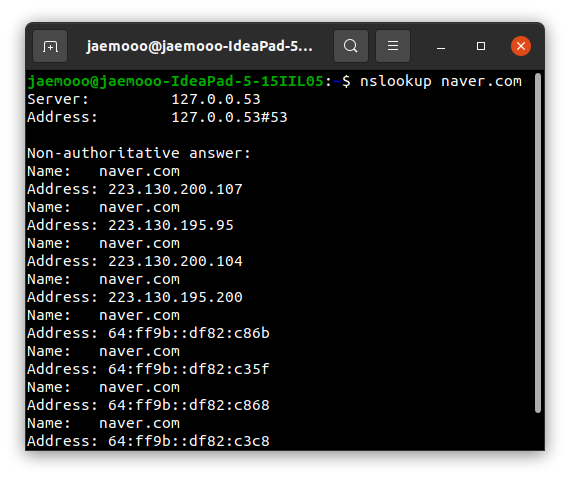
입력 Code :
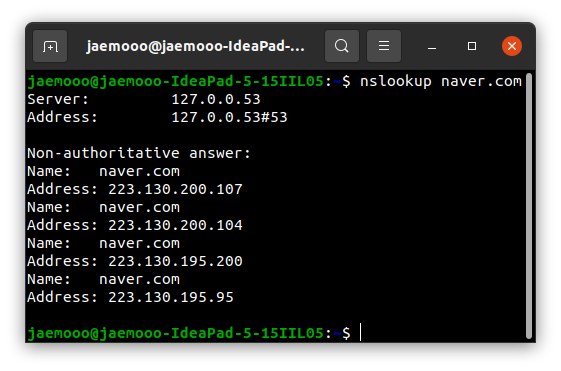
nslookup naver.com: 터미널에서 nslookup을 이용해 IP 주소를 확인
- 외워두면 좋은 IP 주소
-localhost,127.0.0.1: 현재 사용 중인 로컬 PC를 지칭
-0.0.0.0,255.255.255.255: 로컬 네트워크에 접속된 모든 장치와 소통하는 주소.
서버에서 접근 가능 IP 주소를 broadcast address 로 지정하면, 모든 기기에서 서버에 접근
2. PORT
- 하드웨어 장치에도 사용되지만, 소프트웨어에서는 네트워크 서비스나 특정 프로세스를 식별하는 논리 단위
- IP 주소가 가리키는 PC에 접속할 수 있는 통로(채널)을 의미
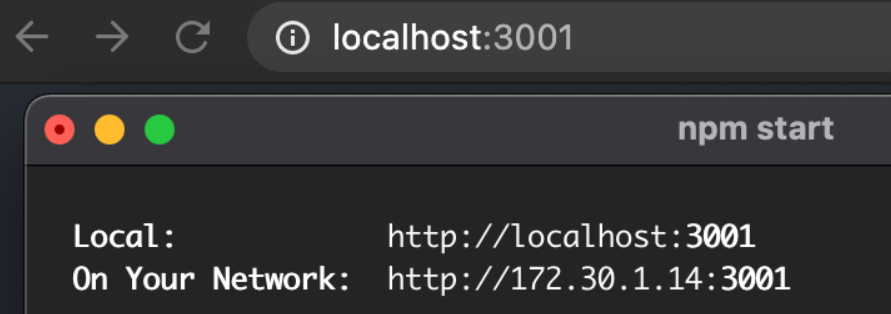
- 리액트를 실행했을 때에는 로컬 PC의 IP 주소로 접근하여, 3000번의 통로를 통해 실행 중인 리액트를 확인할 수 있음
- 이미 사용 중인 포트는 중복해서 사용
- 포트 번호는 0~ 65,535 까지 사용가능
- 0 ~ 1024번 까지의 포트 번호는 주요 통신을 위한 규약에 따라 이미 정해져 있음
ex )
22:SSH
80:HTTP
443:HTTPS
-> 3001번 포트로 실행된 리액트
IP, Port
1. Domain name
- ip는 사람이 이해하고 기억하기 어렵기 때문에 외우기 쉽게하기 위해 각 ip에 이름을 부여한 이름
- IP 주소:
223.130.200.107
- 도메인 이름 :naver.com
- 주소창에 IP 주소(3.34.153.168)를 입력하면,codestates.com으로 이동할 수 있음
2. DNS(Domain Name System)
- 호스트의 도메인 이름을 IP 주소로 변환하거나 반대의 경우를 수행할 수 있도록 개발된 데이터베이스 시스템
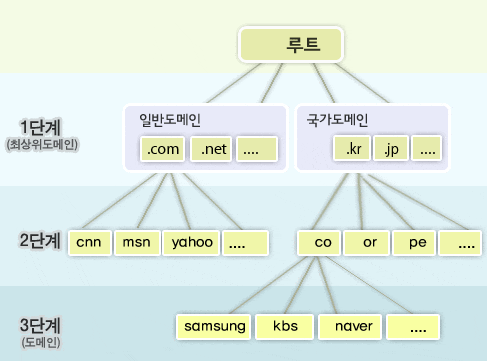
도메인의 구조
DNS 과정
- Ex ) 검색창에 http://google.com 을 검색한다면?
1. www.google.com을 브라우저 주소창에 침
2. Browser는 캐싱된 DNS 기록들을 통해 www.google.com에 대응되는 IP 주소가 있는지 확인함
- 모든 URL들에는 고유의 IP 주소가 지정되어 있음
- nslookup www.google.com을 터미널에 작성하면 해당 사이트의 IP 주소를 알려줌 -> 216.58.197.228
3. 웹사이트 이름을 브라우저에 검색하면 브라우저는 DNS 기록을 4가지의 캐시에서 확인함
1 ) 가장 먼저 브라우저 캐시를 확인함
- 브라우저는 일정기간 동안(유저가 이전에 설정한)의 DNS 기록들을 저장하고 있음
- "DNS query가 이 곳에서 가장 먼저 실행이 됨"2 ) 그 다음에 브라우저는 OS 캐시를 확인함
- 브라우저 캐시에 웹사이트 이름의 IP 주소가 발견되지 않았다면,
브라우저는 systemcall을 통해서 OS가 저장하고 있는 DNS 기록들의 캐시에 접근함3 ) 그 다음에는 라우터 캐시를 확인함
- 컴퓨터에 DNS기록을 찾지 못하면 브라우저는 DNS 기록을 캐싱하고 있는 라우터와 통신을 해서 찾으려고 함
(라우터란? 컴퓨터 네트워크 간에 데이터 패킷을 전송하는 네트워크 장치.
패킷의 위치를 추출하여, 그 위치에 대한 최적의 경로를 지정하며, 이 경로를 따라 데이터 패킷을 다음 장치로 전달)4 ) 그래도 못 찾는다면 마지막으로, ISP 캐시를 확인함
- ISP는 DNS 서버를 구축하고 있고 브라우저가 마지막으로 DNS 기록이 있기를 바라며 접근하게 됨
(ISP란? Internet Service Provider 약자. 우리가 아는 SK, LG, KT 등등이 해당)
4. www.google.com을 호스팅하고 있는 서버의 IP 주소를 찾기 위해 DNS query를 내보냄
- DNS query의 목적은 여러 다른 DNS 서버들을 검색해서 해당 사이트의 IP 주소를 찾는 것임
- 따라서 IP 주소를 찾을 때 까지 DNS 서버에서 다른 DNS 서버를 오가면서 반복적으로 검색하거나
못 찾아서 에러가 발생할 때 까지 검색을 진행함 ( 이러한 검색을 recursive search(재귀적 탐색) 이라고 함)1 ) DNS recursor가 root name server에 연락을 함
2 ) root name 서버는 .com 도메인 name server로 리다이렉트함
3 ) .com name server는 google.com name server로 리다이렉트함
4 ) google.com name server는 DNS 기록에서 www.google.com에 매칭되는 IP 주소를 찾고 DNS recursor로 보내게 됨
5. 브라우저가 서버와 TCP connection을 함
- 클라이언트와 서버간 데이터 패킷들이 오가려면 TCP connection이 되어야 함
- TCP/IP three-way handshake라는 프로세스를 통해서 클라이언트와 서버간 connection이 이뤄지게 됨
- 단어 그대로 클라이언트와 서버가 SYN과 ACK메세지들을 가지고 3번의 프로세스를 거친 후에 연결이 됨1 ) 클라이언트 머신이 SYN 패킷을 서버에 보내고 connection을 열어달라고 물어봄
2 ) 서버가 새로운 connection을 시작할 수 있는 포트가 있다면 SYN/ACK 패킷으로 대답
3 ) 클라이언트는 SYN/ACK 패킷을 서버로부터 받으면 서버에게 ACK 패킷을 보냄
6. Browser가 웹 서버에 HTTP 요청을 함(request를 보냄)
- 클라이언트의 브라우저는 GET 요청을 통해 서버에게 www.google.com 웹페이지를 요구함
- browser identification(User-Agent 헤더)
- 받아들일 요청의 종류(Accept 헤더)
- 추가적인 요청을 위해 TCP connection을 유지를 요청하는 connection 헤더
- 브라우저에서 얻은 쿠키 정보
- 기타 등등
7. 서버가 요청을 처리하고 response를 생성
- 웹서버는 브라우저로부터 요청을 받고 request handler한테 요청을 전달해서 요청을 읽고
response를 생성하게 함
- Request handler란 ASP.NET, PHP, Ruby 등으로 작성된 프로그램을 의미함
- 이 request handler는 요청과 요청의 헤더, 쿠키를 읽어서 요청이 무엇인지 파악하고
필요하다면 서버에 정보를 업데이트 함
- 그 다음에 response를 특정한 포맷으로(JSON, XML, HTML) 작성
8. 서버가 HTTP response를 보냄
- 서버의 response에는 요청한 웹페이지, status code, compression type(Content-Encoding),
어떻게 인코딩 되어 있는지, 어떻게 페이지를 캐싱할지(Cache-Control), 설정할 쿠키가 있다면 쿠키, 개인정보 등이 포함됨
9. Browser가 HTML content를 보여줌
- HTML을 렌더링 후 태그들을 체크해 추가적으로 필요한 요소들을 GET으로 요청함
- 불러온 파일들은 브라우저에 의해 캐싱되어 다시 불러지지 않도록 함
