시계열 분석
Python 함수
def text_def(a,b):
return a + b
test_def(2,3)
a = 1
def edit_a(i):
global a
a = i
return a + b
test_def(2,3)plot sine wave
y = a sin(2pi ft + t_0) + b
위 두줄 잘 기억하기
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
def plotSinWave(amp, freq, endTime, sampleTime, startTime, bias):
"""
plot sine wave
y = a sin(2 pi f t + t_0) + b
"""
time = np.arange(startTime, endTime, sampleTime)
result = amp * np.sin(2 * np.pi * freq * time + startTime) + bias
plt.figure(figsize=(12, 6))
plt.plot(time, result)
plt.grid(True)
plt.xlabel("time")
plt.ylabel("sin")
plt.title(str(amp) + "*sin(2*pi" + str(freq) + "*t+" + str(startTime) + ")+" + str(bias))
plt.show()plotSinWave(2, 1, 10, 0.01, 0.5, 0)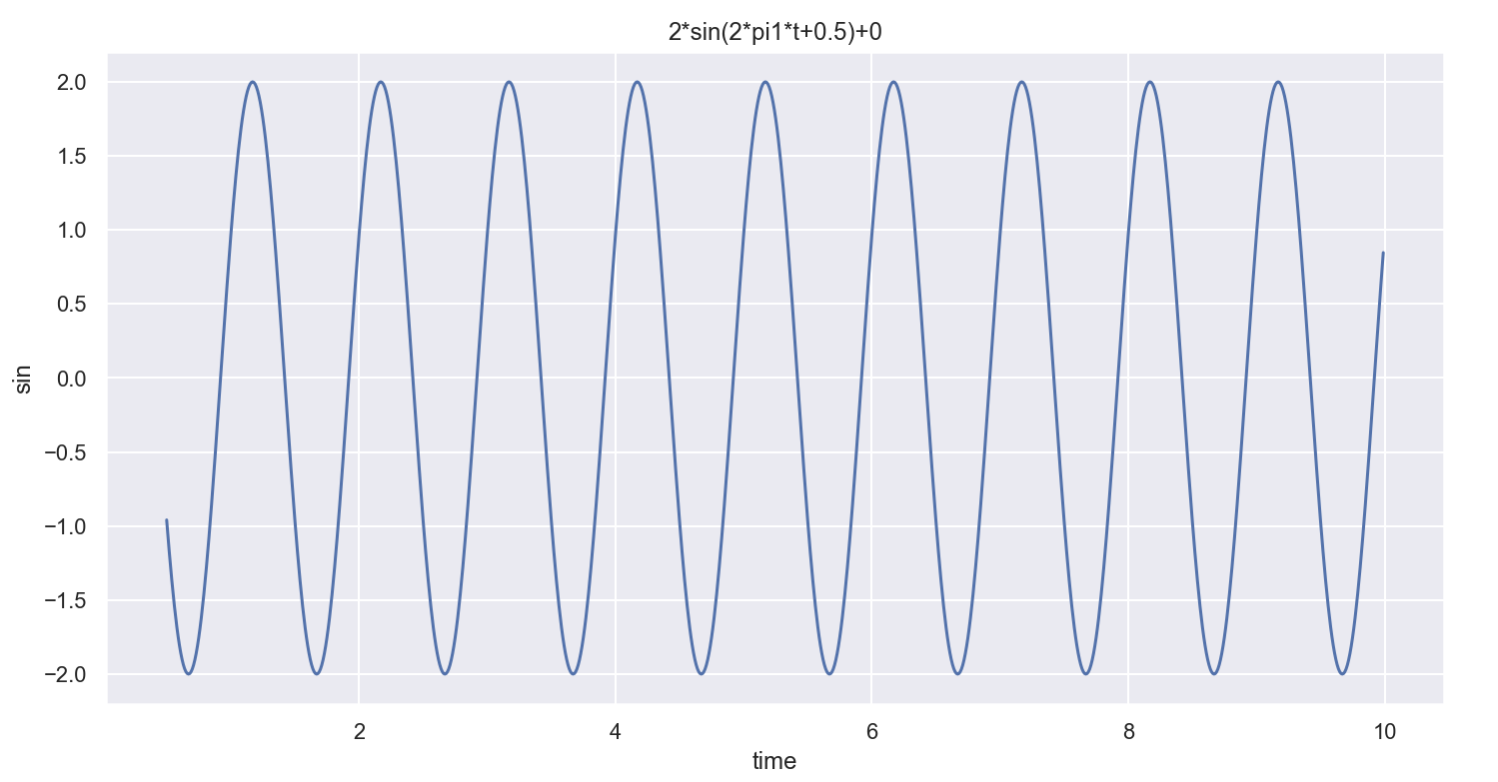
**kwargs #별표 2개가 중요함. keworded arguments
- sin 함수를 구성하기 위해 필요한 인자들을 def의 입력변수를 받음
def plotSinWave(**kwargs):
"""
plot sine wave
y = a sin(2 pi f t + t_0) + b
"""
endTime = kwargs.get("endTime", 1)
sampleTime = kwargs.get("sampleTime", 0.01)
amp = kwargs.get("amp", 1)
freq = kwargs.get("freq", 1)
startTime = kwargs.get("startTime", 0)
bias = kwargs.get("bias", 0)
figsize = kwargs.get("figsize", (12, 6))time = np.arange(startTime, endTime, sampleTime)
result = amp * np.sin(2 * np.pi * freq * time + startTime) + bias
plt.figure(figsize=(12, 6))
plt.plot(time, result)
plt.grid(True)
plt.xlabel("time")
plt.ylabel("sin")
plt.title(str(amp) + "*sin(2*pi" + str(freq) + "*t+" + str(startTime) + ")+" + str(bias))
plt.show()plotSinWave()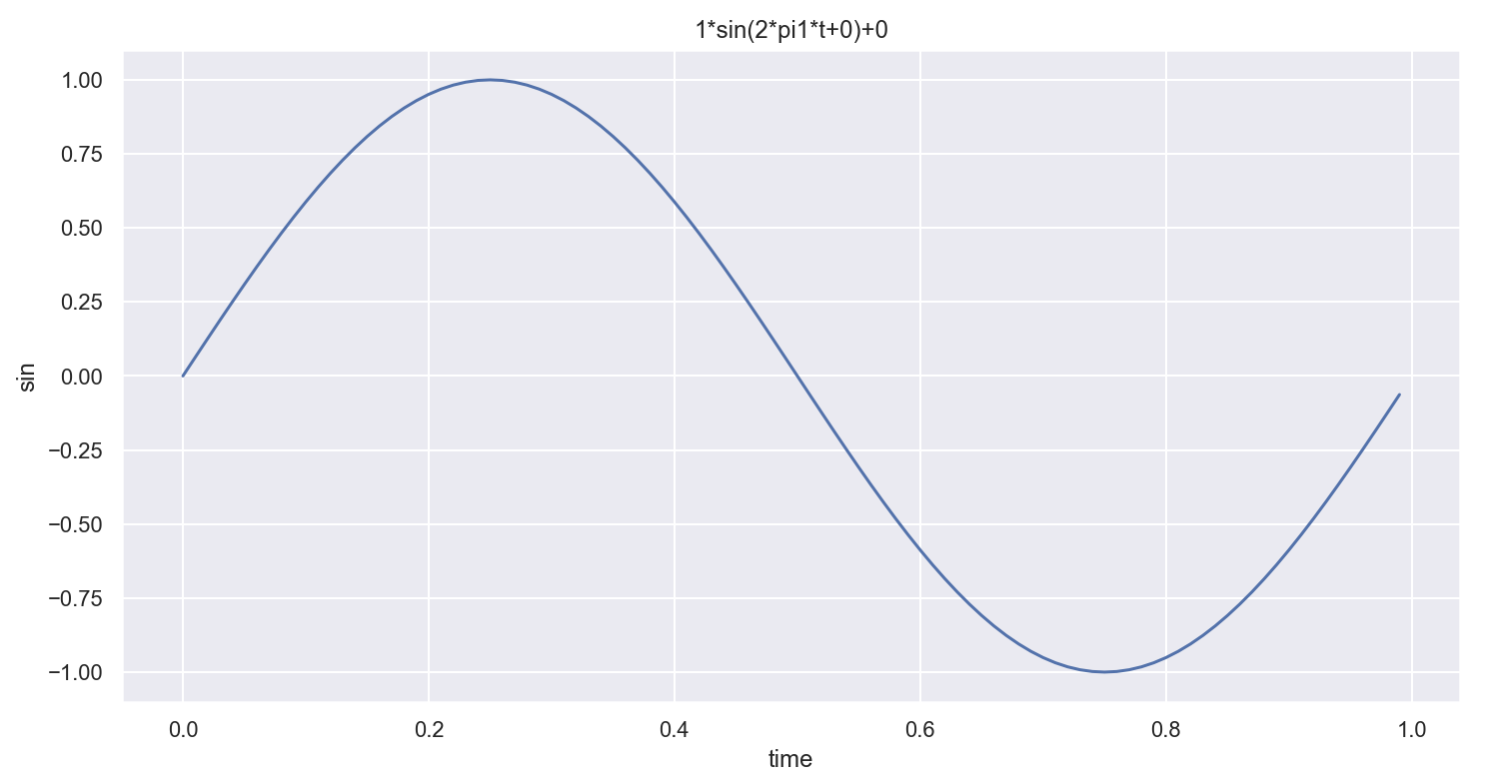
plotSinWave(amp=2, freq=0.5, endTime=10)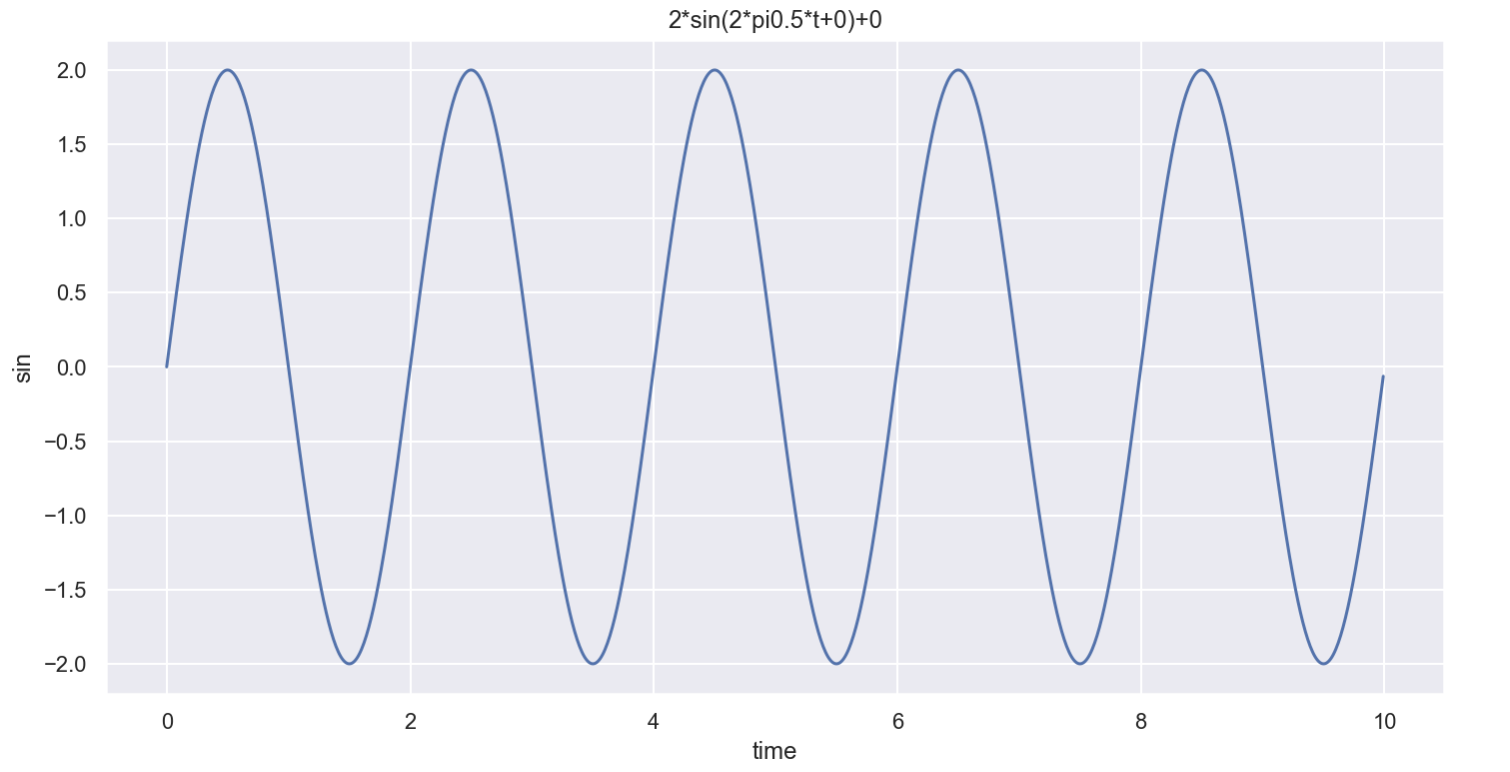
내가 만든 함수를 import 해보자
모듈로 만들어서 import할 수 있게하자.
- .py 파일을 만들기 위해서 vscode를 사용하자.
%%writefile ./drawSinWave.py
import numpy as np
import matplotlib.pyplot as plt
def plotSinWave(**kwargs):
"""
plot sine wave
y = a sin(2 pi f t + t_0) + b
"""
endTime = kwargs.get("endTime", 1)
sampleTime = kwargs.get("sampleTime", 0.01)
amp = kwargs.get("amp", 1)
freq = kwargs.get("freq", 1)
startTime = kwargs.get("startTime", 0)
bias = kwargs.get("bias", 0)
figsize = kwargs.get("figsize", (12, 6))
time = np.arange(startTime, endTime, sampleTime)
result = amp * np.sin(2 * np.pi * freq * time + startTime) + bias
plt.figure(figsize=(12, 6))
plt.plot(time, result)
plt.grid(True)
plt.xlabel("time")
plt.ylabel("sin")
plt.title(str(amp) + "*sin(2*pi" + str(freq) + "*t+" + str(startTime) + ")+" + str(bias))
plt.show()
if __name__ == "__main__":
print("hello world~!!")
print("this is test graph!!")
plotSinWave(amp=1, endTime=2)
import drawSinWave as dSdS.plotSinWave()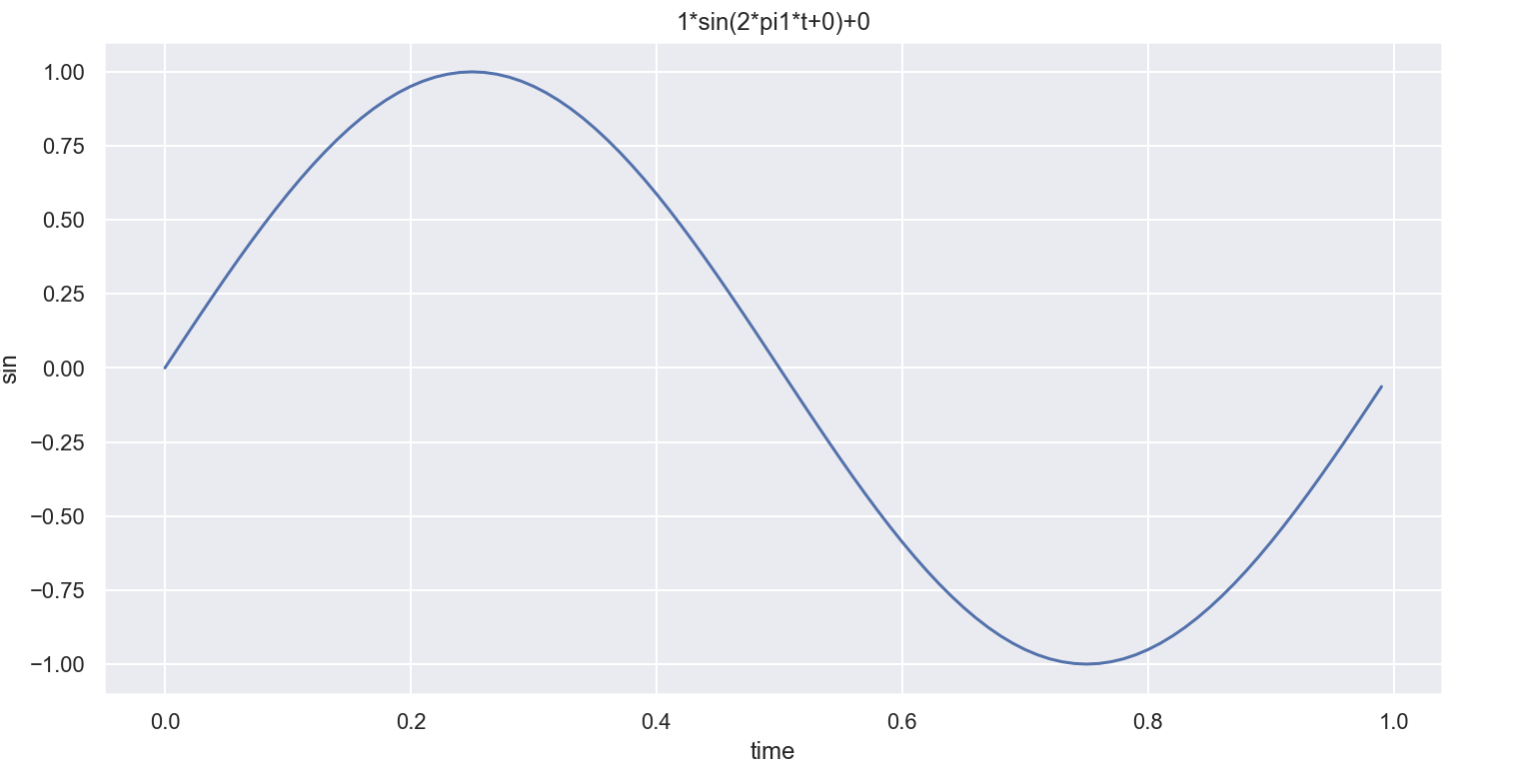
dS.plotSinWave(freq=5)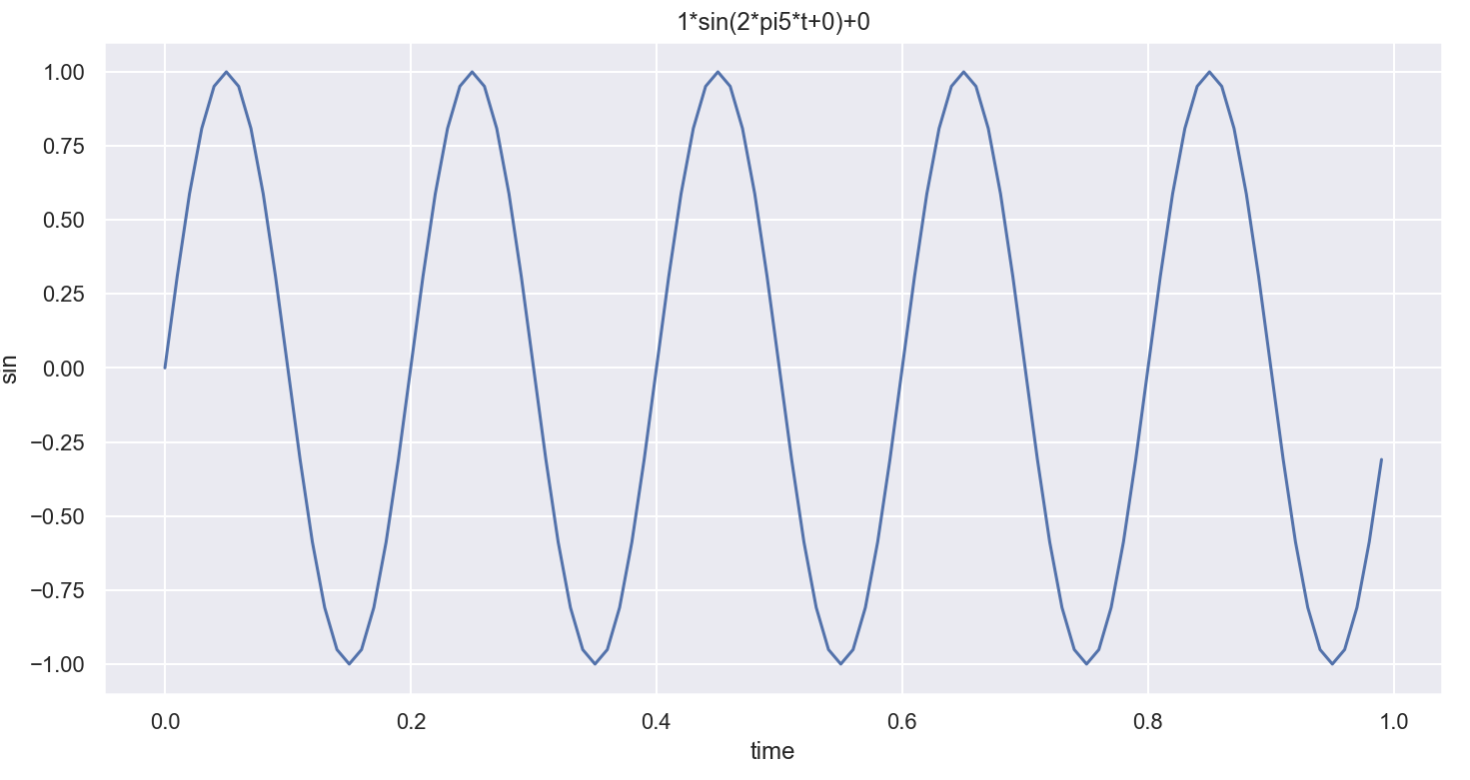
2. Fbprophet 기초
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline 예제1.
#데이터 프레임을 만들기
time = np.linspace(0, 1, 365*2)
result = np.sin(2*np.pi*12*time)
ds = pd.date_range("2018-01-01", periods=365*2, freq="D")
df = pd.DataFrame({"ds": ds, "y": result})
df.head()#만든 데이터 프레임 그래프로 확인하기
df["y"].plot(figsize=(10, 6));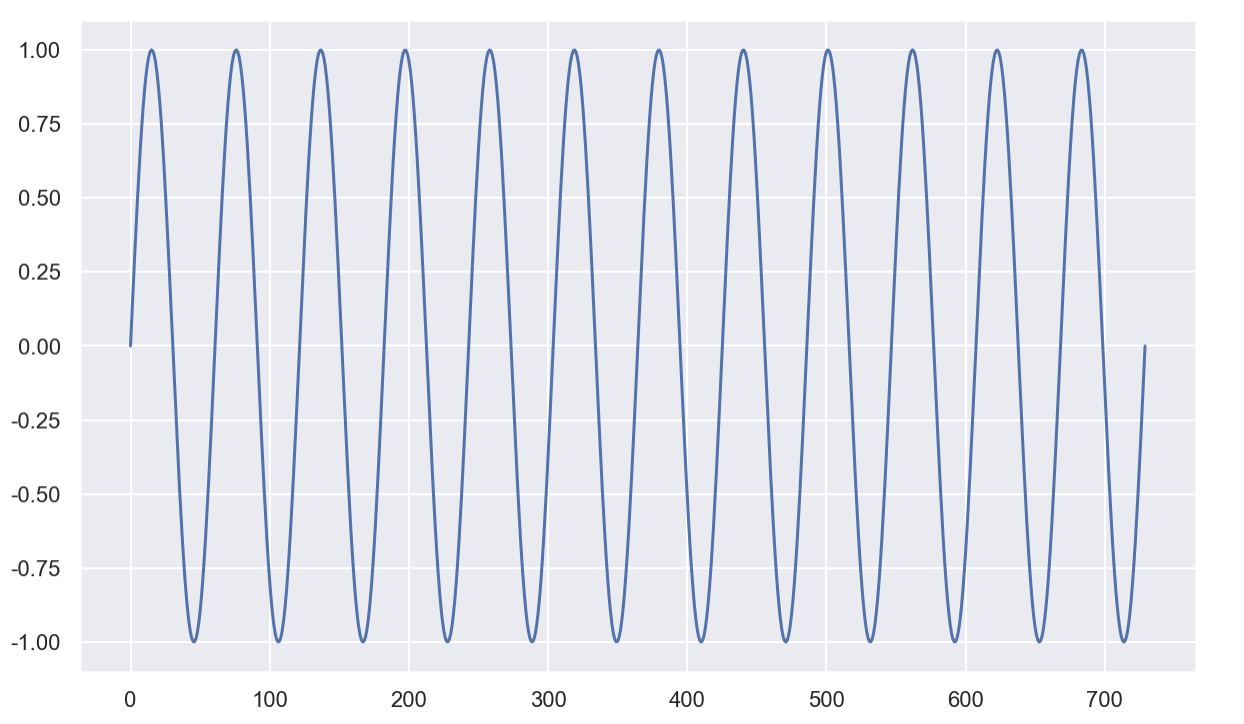
#시계열 데이터 예측을 위한 fbprohet 불러오기
from fbprophet import Prophet
#학습시키기
m = Prophet(yearly_seasonality=True, daily_seasonality=True)
m.fit(df);
#예측하기
future = m.make_future_dataframe(periods=30)
forecast = m.predict(future)
#예측한 데이터 그래프로 확인하기
m.plot(forecast);
3. 주식 데이터 분석
from bs4 import BeautifulSoup
from urllib.request import urlopen, Request
url = "https://finance.yahoo.com/quote/035420.KS/history?p=035420.KS&guccounter=1"
req = Request(url, headers={"User-Agent": "Chrome"})
page = urlopen(req).read()
soup = BeautifulSoup(page, "html.parser")
table = soup.find("table")
df_raw = pd.read_html(str(table))[0]
df_raw.head()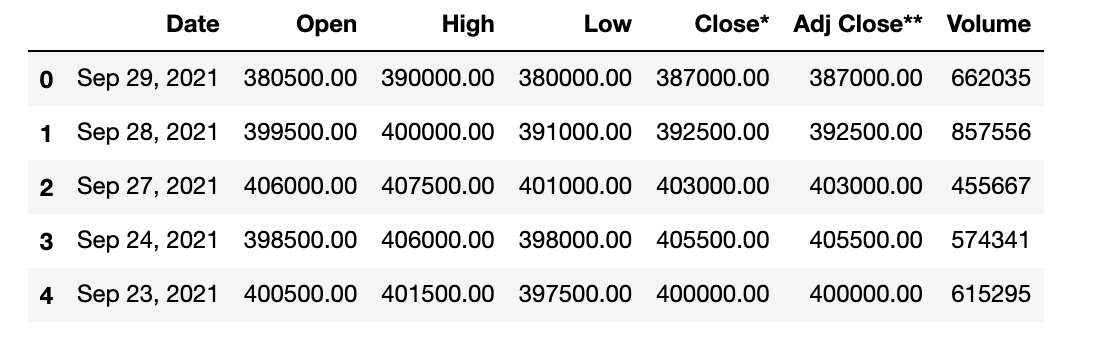
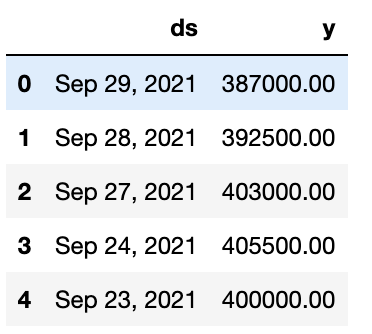
# fbprophet을 사용하는 형식에 맞춰준 뒤, 맨 마지막 NaN 값이 있어서 제외
df_tmp = pd.DataFrame({"ds": df_raw["Date"], "y": df_raw["Close*"]})
df_target = df_tmp[:-1]
df_target.head()
# hardcopy 후, 날짜를 fbprophet이 요구하는 형태로 변형
df = df_target.copy()
df["ds"] = pd.to_datetime(df_target["ds"], format="%b %d, %Y")
df.head()#확인해보니 데이터형 타입 중 object가 있어서 float으로 변경해야한다.
df.info()
# 데이터 프레임에 있는 것을 학습시켜보자
m = Prophet(yearly_seasonality=True, daily_seasonality=True)
m.fit(df);
# 학습시킨 데이터를 기반으로 예측해보자
future = m.make_future_dataframe(periods=30)
forecast = m.predict(future)
forecast[["ds", "yhat", "yhat_lower", "yhat_upper"]].tail()
#예측한 데이터를 그래프에서 확인해보자.
plt.figure(figsize=(12, 6))
plt.plot(df["ds"], df["y"], label="real")
plt.grid(True)
plt.show()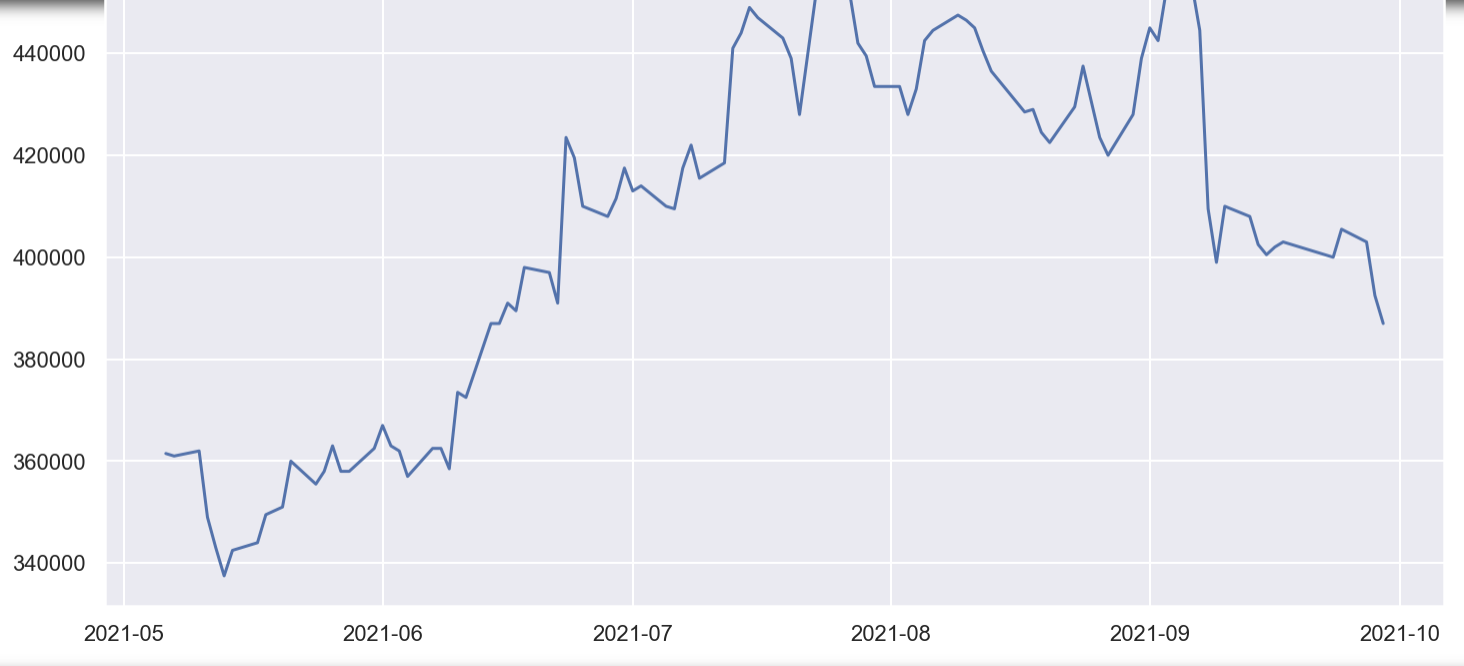
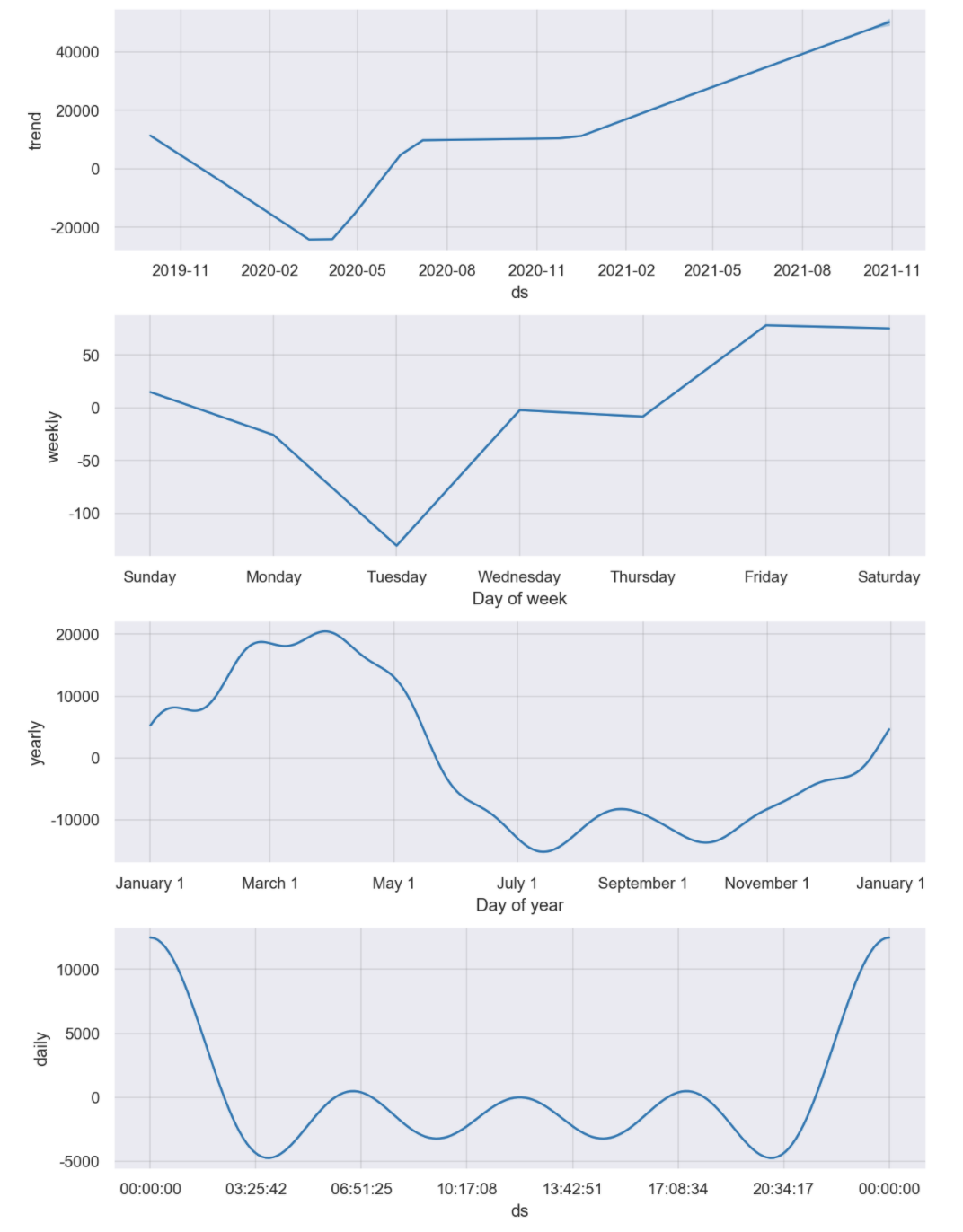
#그래프에서 트렌드를 파악해보자
m.plot_components(forecast);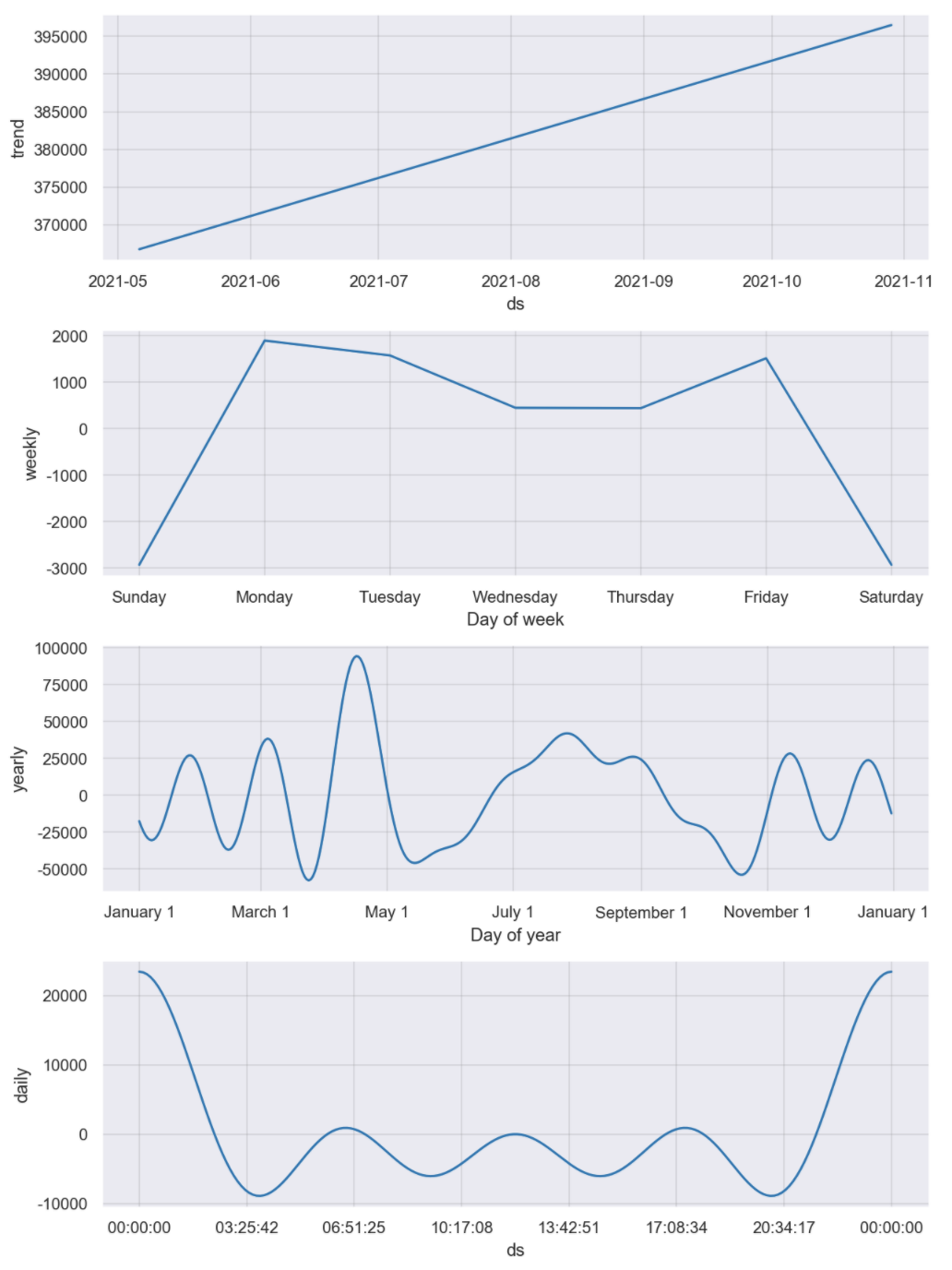
예제) KIA 주식 분석
# 기아 자동차의 종목코드를 가지고 기간을 입력한다
import yfinance as yf
from pandas_datareader import data
yf.pdr_override()
start_date = "2010-03-01"
end_date = "2018-02-28"
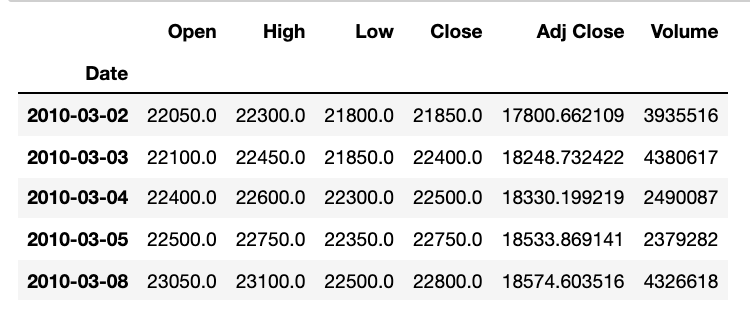
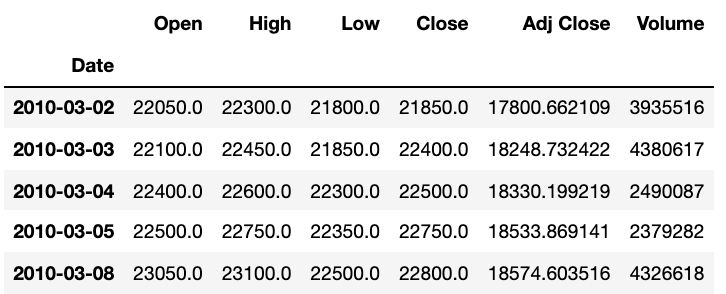
KIA = data.get_data_yahoo("000270.KS", start_date, end_date) #KIA 주식 코드입력, 시작일자, 끝나는 일자
KIA.head()
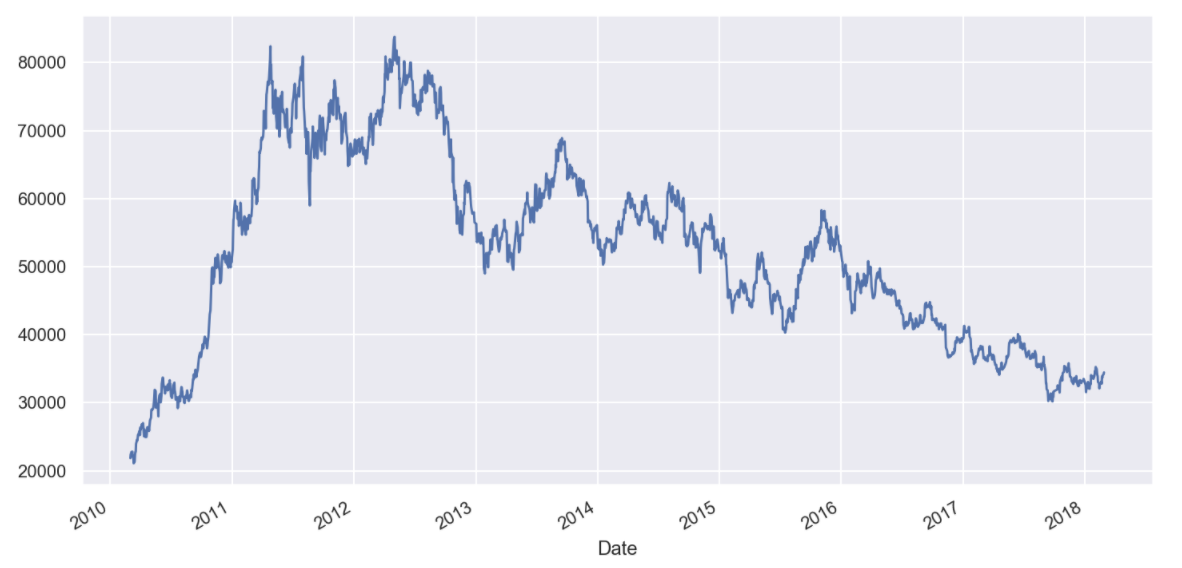
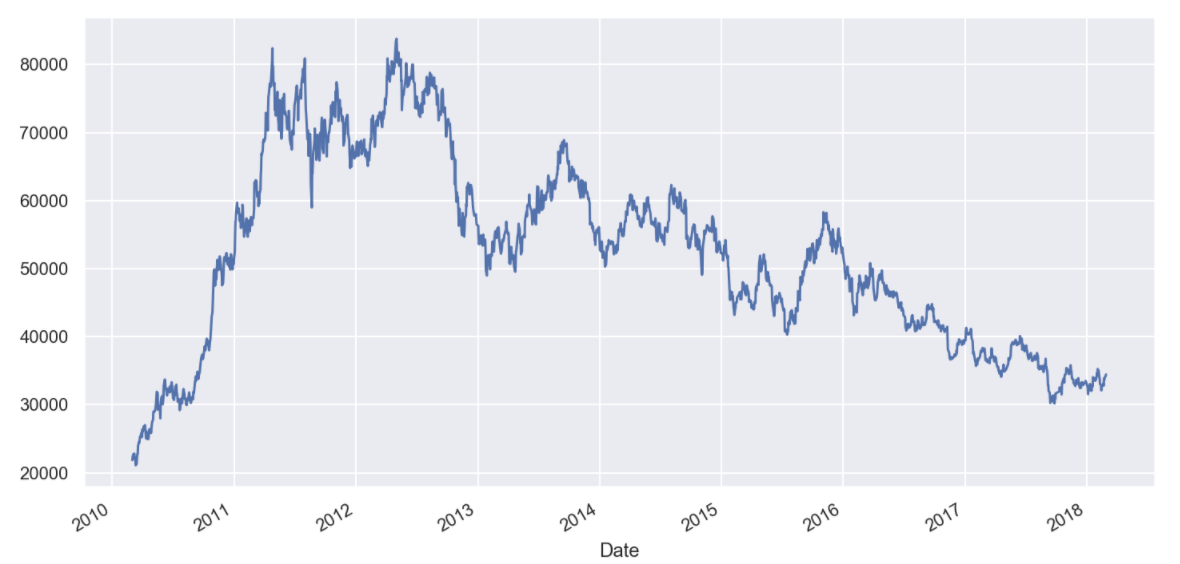
# 종가 데이터를 그래프로 확인해보자
KIA["Close"].plot(figsize=(12, 6), grid=True);
# accuracy 확인을 위한 데이터
KIA_trunc = KIA[:"2017-11-30"]
KIA_trunc.head()
#forecast를 위한 준비
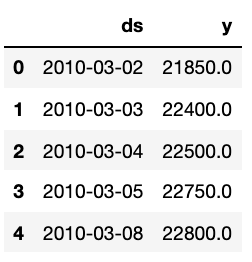
# forecast를 위한 준비
df = pd.DataFrame({"ds": KIA_trunc.index, "y":KIA_trunc["Close"]})
df.reset_index(inplace=True)
del df["Date"]
df.head()
#학습시키기
m = Prophet(yearly_seasonality=True, daily_seasonality=True)
m.fit(df);
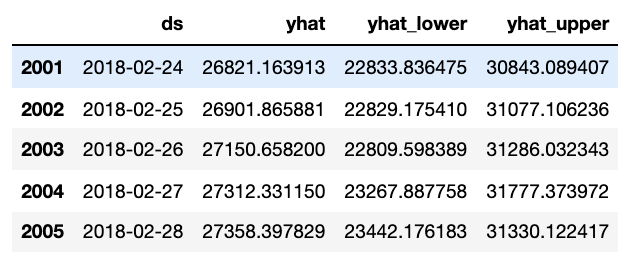
#예측하기
future = m.make_future_dataframe(periods=90)
forecast = m.predict(future)
forecast[["ds", "yhat", "yhat_lower", "yhat_upper"]].tail()
#시각화하기
m.plot(forecast);
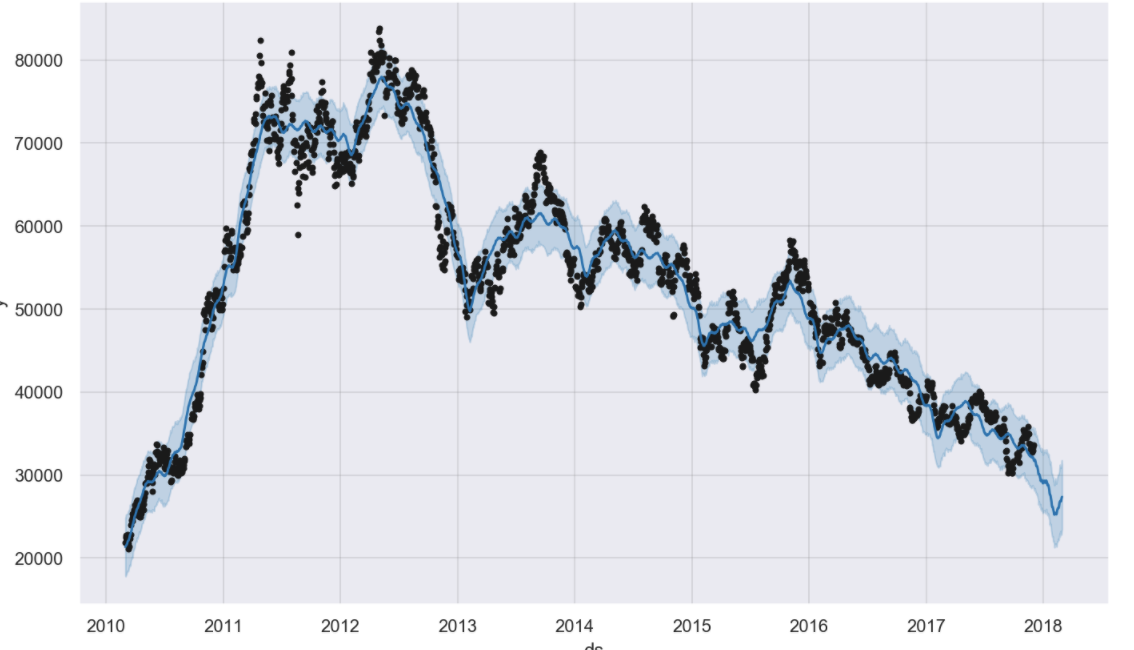
#트렌드 파악을 위해 컴포넌츠별로 확인하기
m.plot_components(forecast);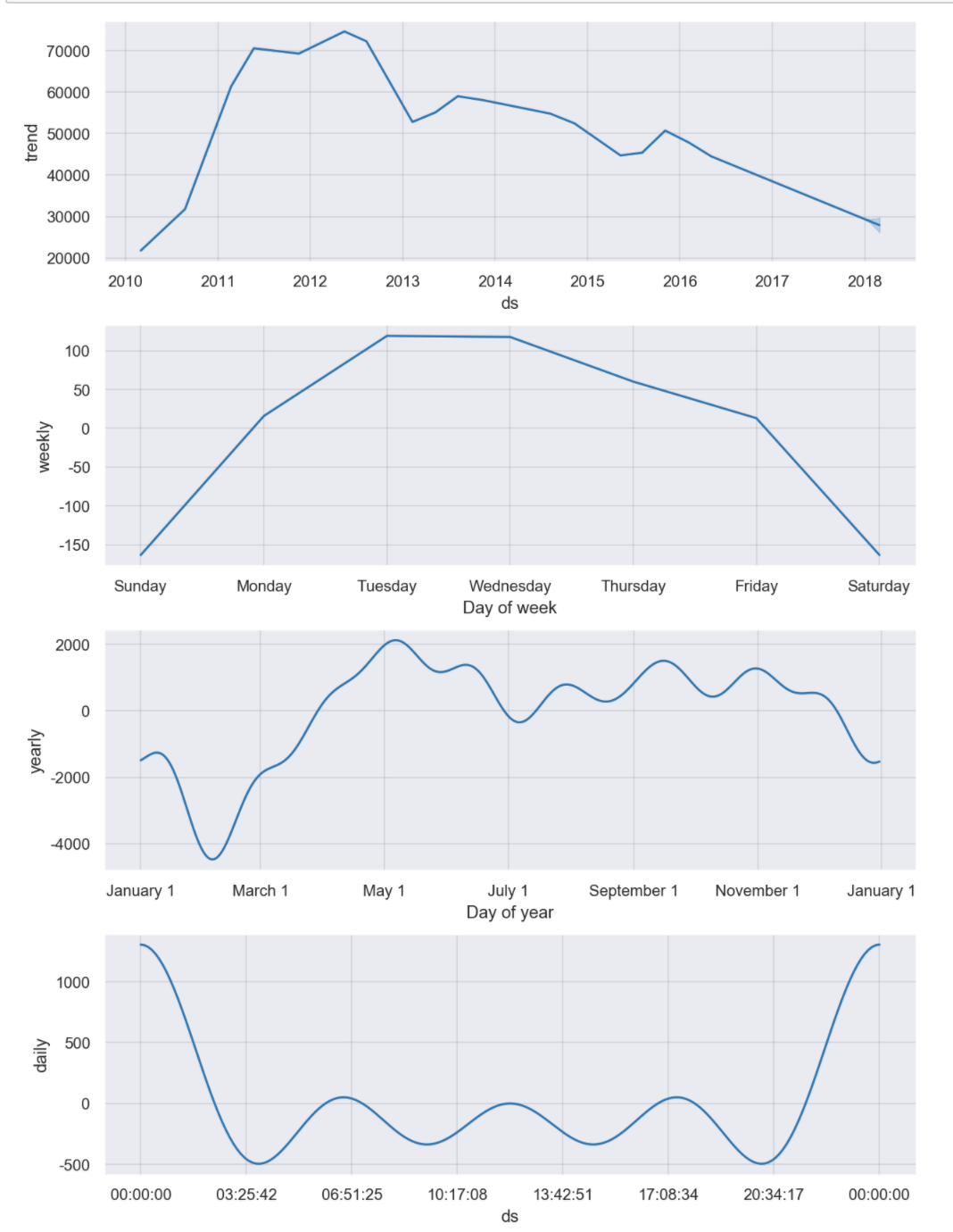
plt.figure(figsize=(12, 6))
plt.plot(KIA.index, KIA["Close"], label="real")
plt.plot(forecast["ds"], forecast["yhat"], label="forecast")
plt.grid(True)
plt.legend()
plt.show()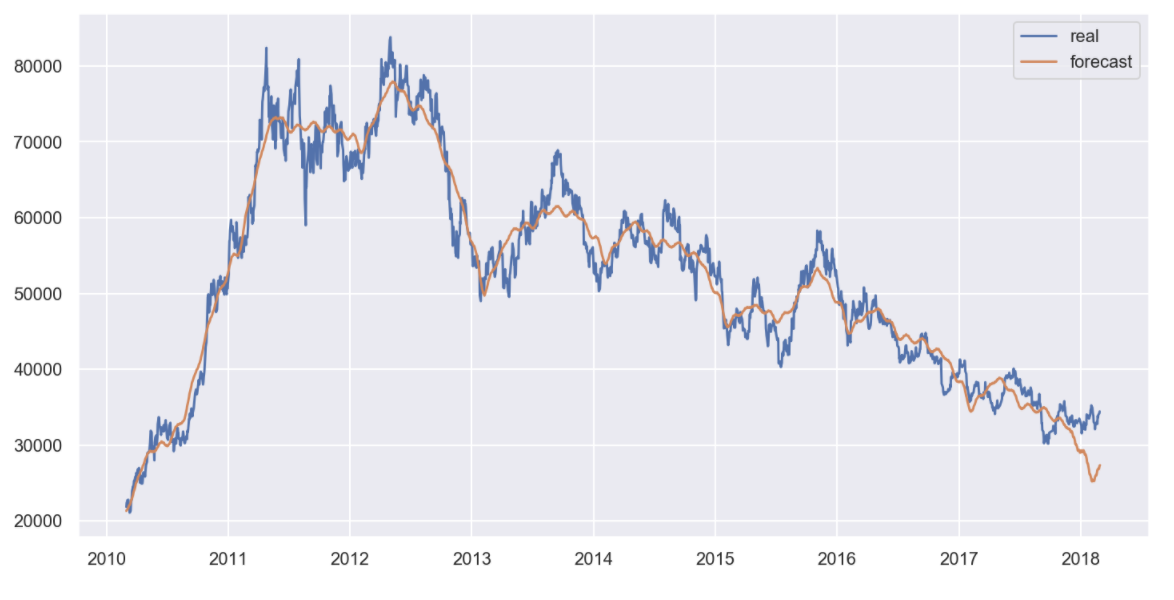
예제) 대한항공 주식 분석하기
start_date = "2010-03-01"
end_date = "2018-02-28"
KoreaAir = data.get_data_yahoo("003490.KS", start_date, end_date)
KoreaAir.tail()
#위에서 불러온 데이터의 head와 tail을 확인하여 정확하게 불러왔는지 확인한다
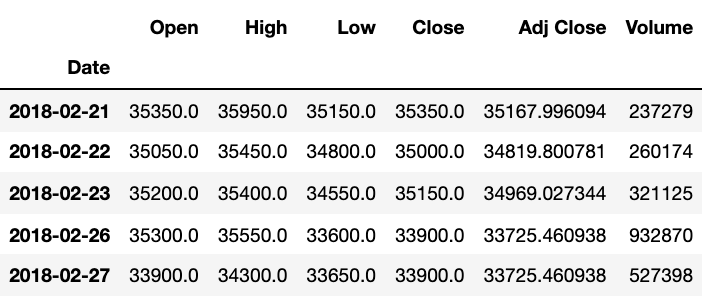
KoreaAir["Close"].plot(figsize=(12, 6), grid=True);
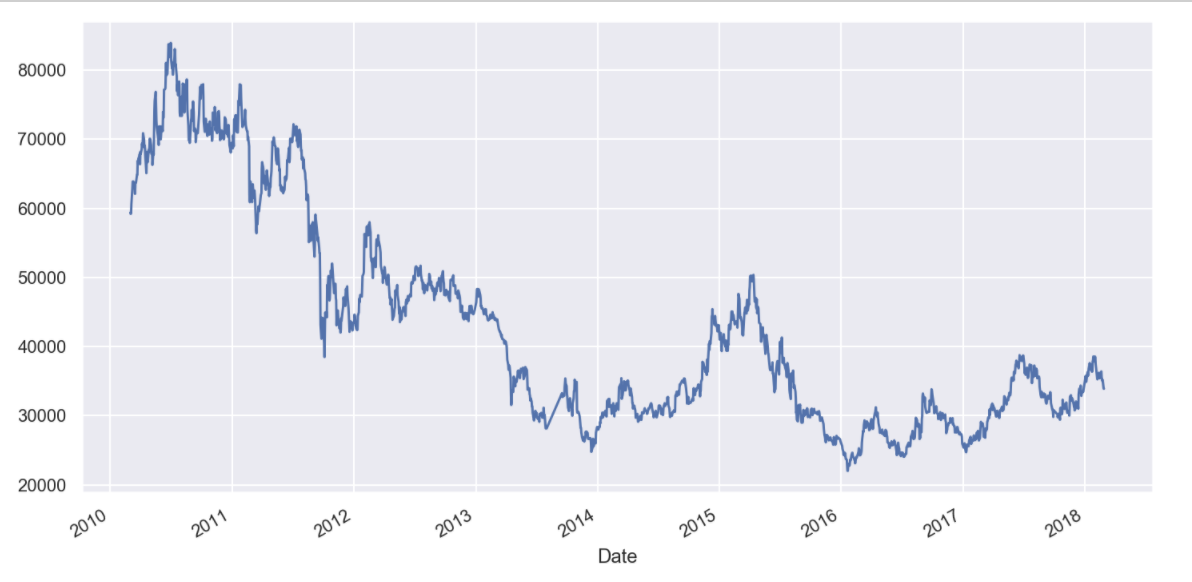
# accuracy 데이터 분리
KoreaAir_trunc = KoreaAir[:"2017-11-30"]
KoreaAir_trunc.tail()
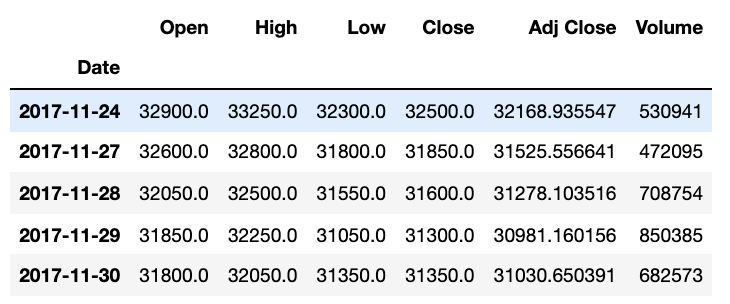
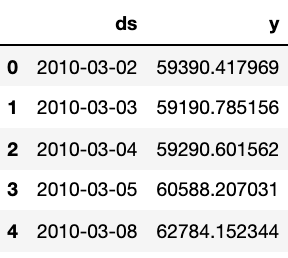
# forecast를 위한 준비: forecast에 맞는 형식으로 데이터프레임에 넣어준다
df = pd.DataFrame({"ds": KoreaAir_trunc.index, "y": KoreaAir_trunc["Close"]})
df.reset_index(inplace=True)
del df["Date"]
df.head()
#학습시켜준다
m = Prophet(yearly_seasonality=True, daily_seasonality=True)
m.fit(df)
#예측해보자
future = m.make_future_dataframe(periods=90)
forecast = m.predict(future)
forecast[["ds", "yhat", "yhat_lower", "yhat_upper"]].tail()
#yhat = 예측값
#yhat_lower = 예측에 대한 신뢰구간 하단
#yhat_upper = 예측에 대한 신뢰구간 상단
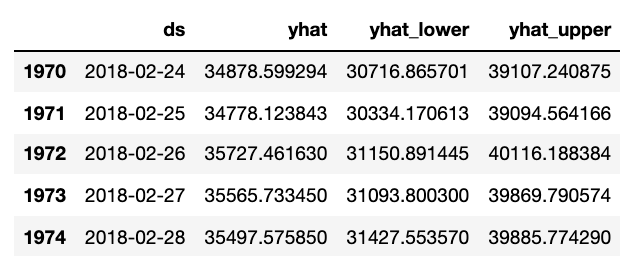
#그래프로 시각화
m.plot(forecast);
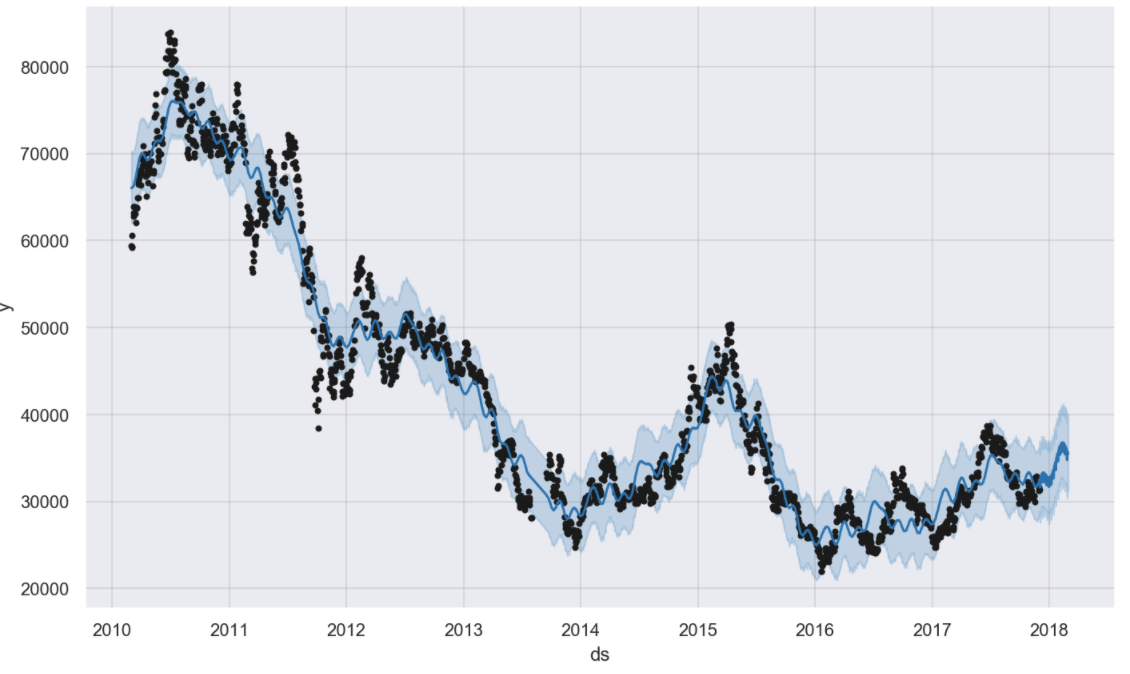
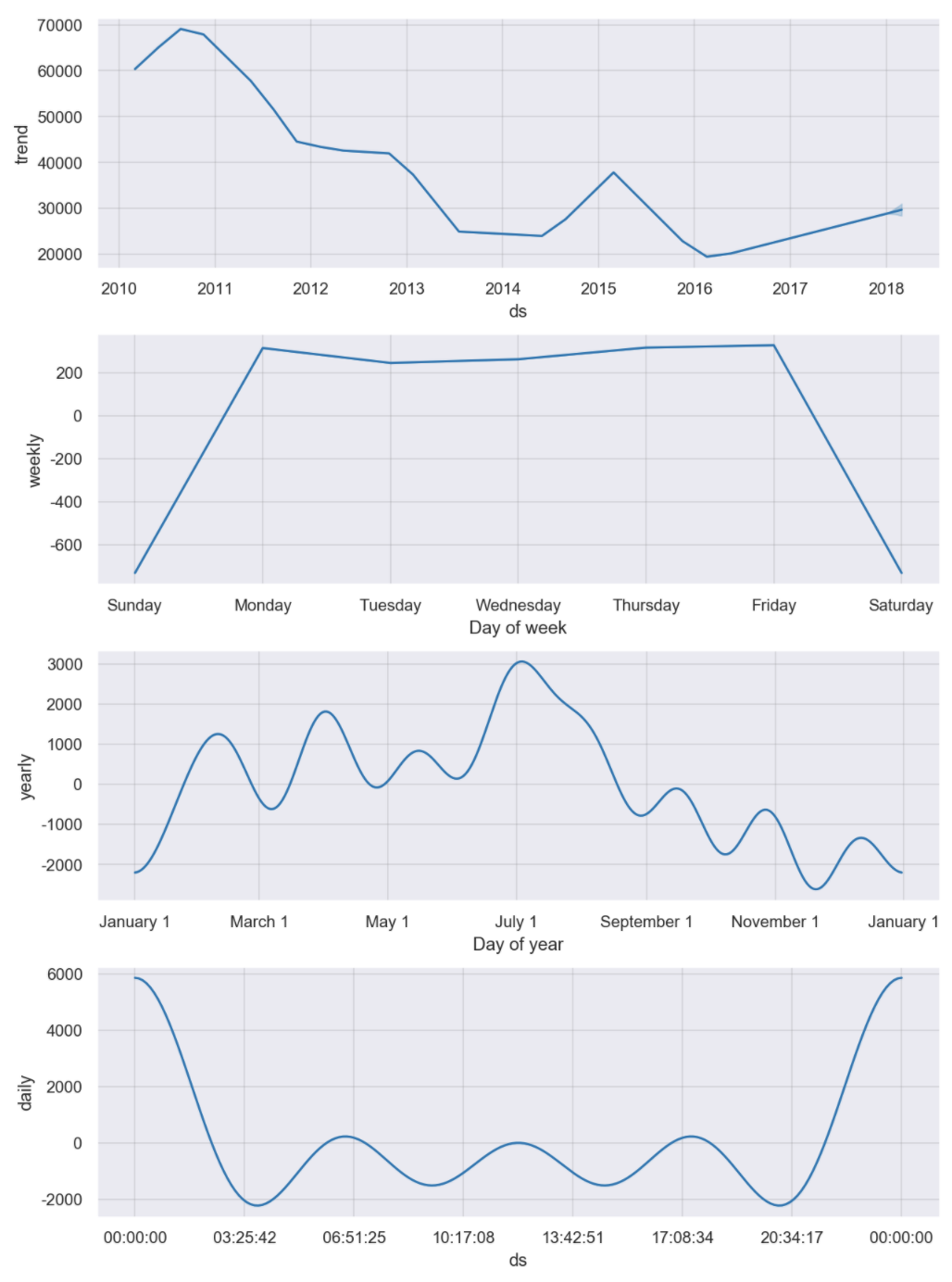
#컴포넌츠별로 그래프
m.plot_components(forecast);
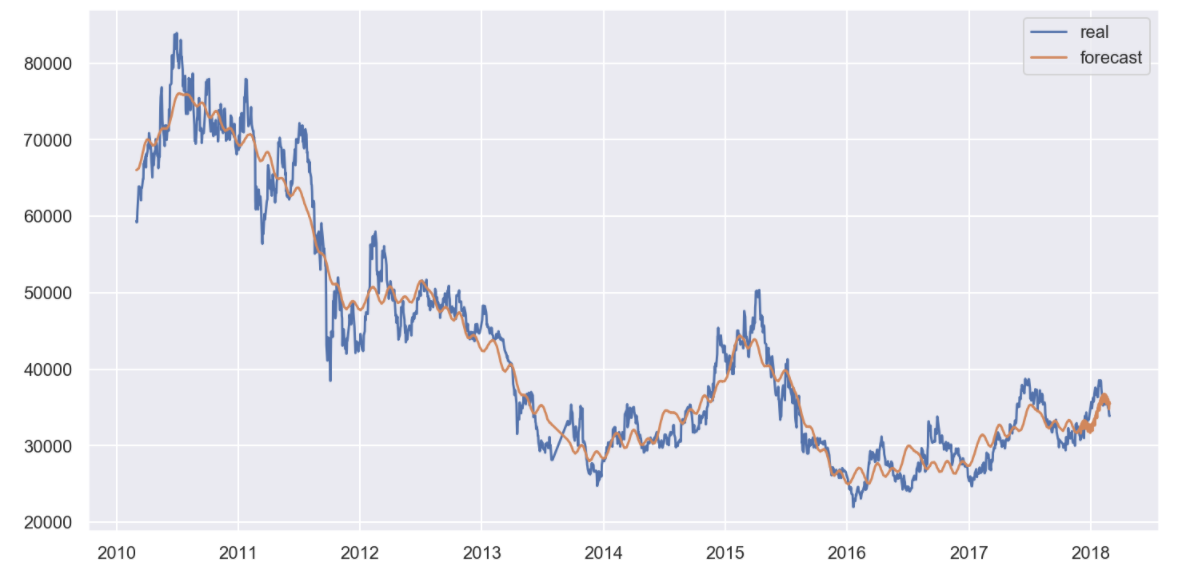
# 실제와 예측값 비교 그래프
plt.figure(figsize=(12, 6))
plt.plot(KoreaAir.index, KoreaAir["Close"], label="real")
plt.plot(forecast["ds"], forecast["yhat"], label="forecast")
plt.grid(True)
plt.legend()
plt.show()
4. 조금 특이한 형태의 데이터에 대한 forecast
# Logistic 성장형 그래프를 가진 데이터에 대한 forecast
df = pd.read_csv("../data/05_example_wp_R2.csv", index_col=0)
df["y"].plot(figsize=(12, 4), grid=True);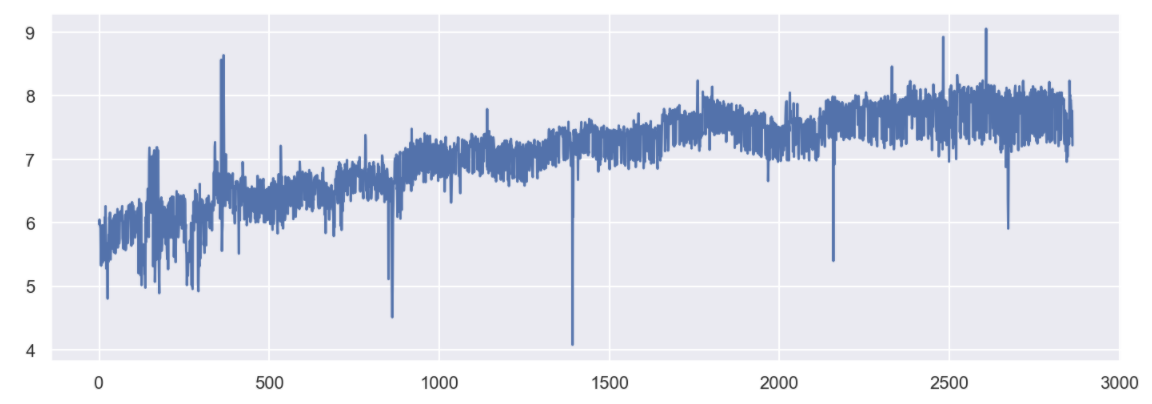
#cap 컬럼 추가
df["cap"] = 8.5
df.tail()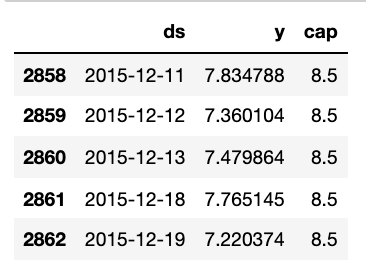
#logistic 함수를 이용하여 예측하기
m = Prophet(growth="logistic", daily_seasonality=True)
m.fit(df);
future = m.make_future_dataframe(periods=1826)
future["cap"] = 8.5
forecast = m.predict(future)
m.plot(forecast);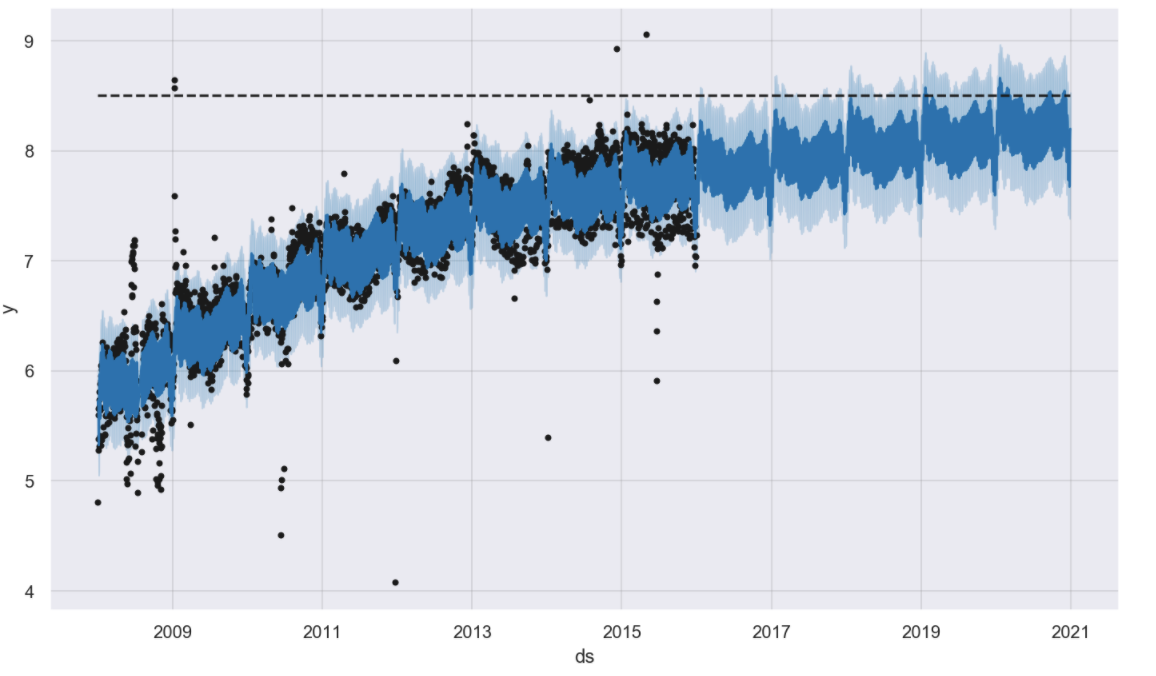
5. 비트코인 데이터 fbprophet으로 분석하기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import time
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from bs4 import BeautifulSoup
from fbprophet import Prophet
%matplotlib inline
url = "https://bitcoincharts.com/charts/bitstampUSD#rg730ztgSzm1g10zm2g25zv"
driver = webdriver.Chrome("../driver/chromedriver")
driver.get(url)
# 스크롤
xpath = '//*[@id="content_chart"]/div/div[2]/a'
variable = driver.find_element_by_xpath(xpath)
driver.execute_script("return arguments[0].scrollIntoView();", variable)
variable.click()
#BeautifulSoup사용해서 태그
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
table = soup.find("table", "data")
table
driver.quit()
#테이블 불러오기
df = pd.read_html(str(table))
bitcoin = df[0]
bitcoin.head()
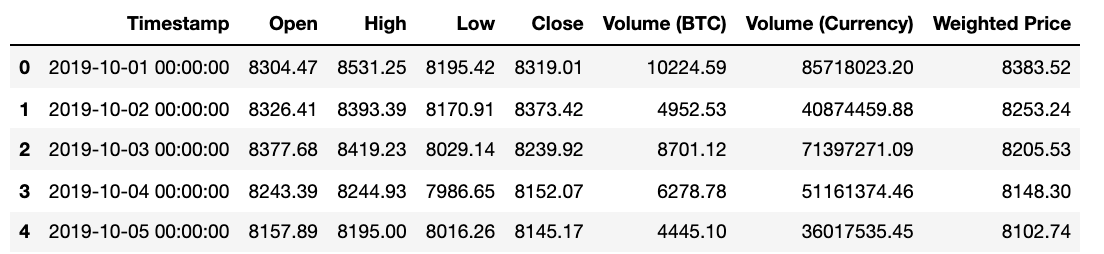
#저장하기
bitcoin.to_csv("../data/05_bitcoin_history.csv", sep=",") # sep옵션을 사용하여 띄어쓰기(공백) 말고 다른 문자를 넣을 수 있도록 할 수 있습니다.
bitcoin = pd.read_csv("../data/05_bitcoin_history.csv", index_col=0)
bitcoin.tail()
# 분석하고 싶은 항목(Close)만 가지고, Prophet 적용
df = pd.DataFrame({"ds": bitcoin["Timestamp"], "y": bitcoin["Close"]})
m = Prophet(yearly_seasonality=True, daily_seasonality=True)
m.fit(df);
# 향후 30일간의 forecast
future = m.make_future_dataframe(periods=30)
forecast = m.predict(future)
m.plot(forecast);
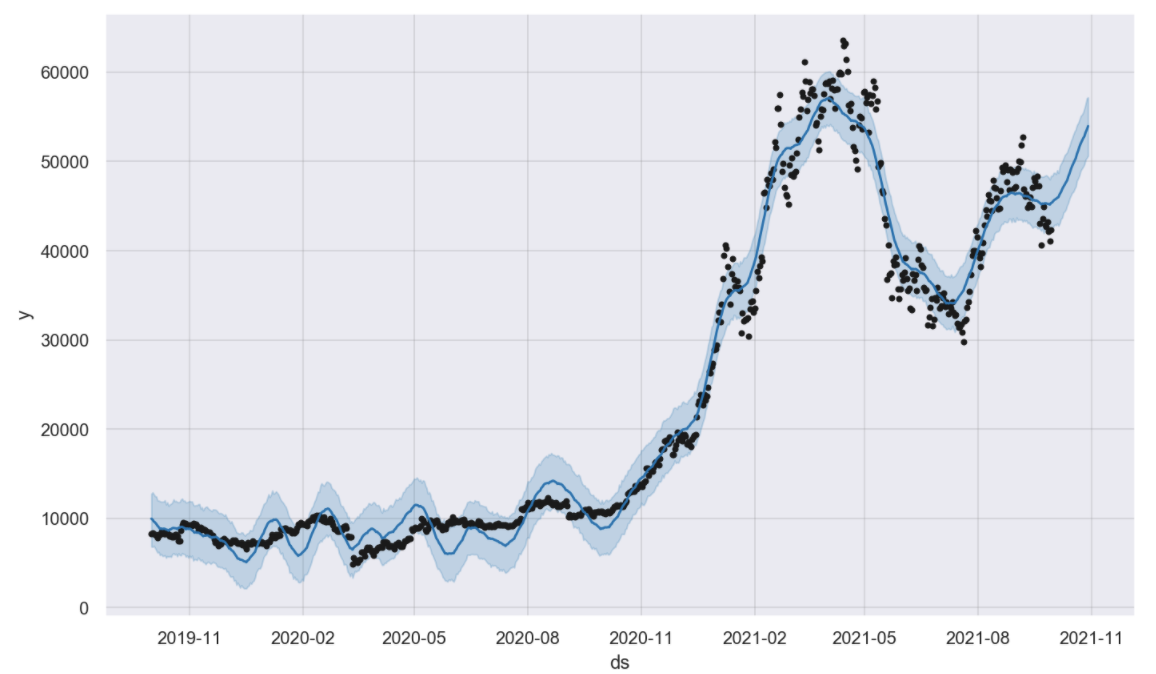
# 트렌드 파악하기
m.plot_components(forecast);
list에 아이템 추가
students = ['홍길동', '박찬호', '이용규', '박승철', '김지은']
print('students : {}'. format(students))
print('students length : {}'.format(len(students)))
print('last index : {}'.format(len(students)-1))
students.append('강호동')
print('students : {}'. format(students))
print('students length : {}'.format(len(students)))
print('last index : {}'.format(len(students)-1))
scores = [['국어', 88],
['영어', 91]]
print('scores : {}'. format(scores))
print('scores length : {}'.format(len(scores)))
print('last index : {}'.format(len(scores)-1))
#과목별 점수 따로 따로
for subject, score in scores:
print('과목: {}, 점수: {}'.format(subject, score))
#리스트 append는 리스트 형식 그대로 추가됨
myFamilyAge = [['아빠', 40], ['엄마', 38], ['나', 9]]
print(myFamilyAge)
myFamilyAge.append(['동생', 1])
print(myFamilyAge)
for name, age in myFamilyAge:
print('{} : {}'.format(name, age))특정 위치에 아이템을 추가하는 방법
- insert()함수를 이용하면 특정 위치(인덱스)에 아이템을 추가할 수 있다. 해당 인덱스 위치에 있는 아이템은 뒤로 밀려난다.
students.insert(3, '홍길동')#오름차순으로 정렬되어 있는 숫자들 사이에 추가
numbers = [1, 3, 6, 11, 45, 54, 62, 74, 85]
inputNumber = int(input('숫자 입력: '))
insertIdx = 0
for idx, number in enumerate(numbers):
print(idx, number)
if insertIdx == 0 and inputNumber < number:
insertIdx = idx
numbers.insert(insertIdx, inputNumber)
print('numbers : {}'.format(numbers))리스트의 아이템을 삭제
- pop()함수를 이용하면 마지막 인덱스에 해당하는 아이템을 삭제할 수 있다.
- pop(3) #3번째 인덱스 삭제. 4번째 인덱스가 한칸씩 자동으로 앞으로 밀려온다.
studentsA = ['홍길동', '박찬호', '이용규', '박승철', '김지은', '강호동']
print('studentsA : {}'.format(studentsA))
print('studentsA length: {}'.format(len(studentsA)))
studentsA.pop()
print('studentsA: {}'.format(studentsA))
print('students length: {}'.format(len(studentsA)))
studentsA = ['홍길동', '박찬호', '이용규', '박승철', '김지은', '강호동']
print('studentsA : {}'.format(studentsA))
print('studentsA length: {}'.format(len(studentsA)))
#제거된 인덱스 = rValue
rValue = studentsA.pop(3)
print('rValue: {}'.format(rValue))
- **하나의 ‘강호동’ 데이터만 삭제
students.remove(‘강호동’) #여러개의 ‘강호동’데이터를 삭제하고 싶은 경우
While ‘강호동’ in students:
students.remove(‘강호동’)removeItem = input(‘t삭제 대상 입력: ‘)
While 문- extend() 함수를 이용하면 리스트에 또 다른 리스트를 연결할 수 있다.
덧셈 연산자를 이용해서 리스트를 연결할 수도 있다.
group1.extend(group2)
#group 1에 group2가 추가됨- 두 리스트가 더해져서 새로운 리스트가 됨 (겹치는 숫자 모두 추가)
addList = myFavoriteNumbers + friendFavoriteNumbersResult = []
For number in addList:
if number not in result:
result.append(number)
print(‘result: {}’.format(result))—
리스트 연결(확장)
-sort() 함수를 이용하면 아이템을 정렬
내림차순 : 변수이름.sort(reverse=True)
오름차순 : 변수이름.sort(True)아이템 순서 뒤집기 (순서가 앞 뒤로 바뀜)
reverse()- 슬라이싱 - 원하는 아이템만 뽑는 것
음수를 사용하면 뒤에서 카운트하여 시작
[-5:-2]
뒤에서 5번째부터 뒤에서 3번째까지 ( -2는 -3부터 카운트)
문자열도 슬라이싱이 가능하다.
슬라이싱할때 단계를 설정할 수 있다.
[2:-2:2] = 앞에서 두번째포함하여 시작. 하나 건너뛰고 그다음꺼 포함
슬라이싱을 이용해서 아이템을 변경할 수 있다.
Students[1:4] = [‘park chance’, ‘lee yonggyu’, ‘gang hodong’
앞에서 2번째부터 3번째까지 슬라이스해서 대체. 해당 슬라이스에 들어가는 아이템이 3가지이지만 들어갈 문자는 2개면 그대로 3개 사라지고 2개만 추가
길이는 아이템 수
숫자 하나이면 해당 숫자앞까지 슬라이싱
- 리스트의 나머지 기능들(1)
리스트도 곱셈 연산이 가능하다.
아이템이 3개이고 곱셈연산(ㅇㅖ, *2)를 줄경우 아이템 3개가 뒤에 한번 더 추가된다.
특정 아이템의 인덱스를 찾자.
index(item)함수를 사용하면 item의 인덱스를 알아낼 수 있다.
searchIdx = students.index(‘강호동’, 2, 6) #리스트안에 3번째와 5번째 사이에서의 강호동의 인덱스
count() 함수를 이용하면 특정 아이템의 개수를 알아낼 수 있다.
count(‘강호동’)
del students[index값] #인덱스 위치의 아이템 삭제 여러개인경우 하나만 삭제됨
del students[1:4] #인덱스 1-3사이가 삭제됨
del students[2: ] #인덱스 1까지 빼고 다 삭제됨import random
sampleList = random.sample(Range(1,11),10) #10개 중에 1,11사이의 수실습
import random
types = ['A', 'B', 'AB', '0']
todayData = []
typeCnt = []
for i in range(100): #for문이 100번 돌도록
type = types[random.randrange(len(types))]
#무작위로 뽑기위해 랜덤사용. types의 갯수 만큼 = len
todayData.append(type)
print('todayData: {}'.format(todayData))
print('todayData: {}'.format(len(todayData)))
#혈액형 종류가 몇개인지
for type in types:
print('{}형 : {}개'.format(type, todayData.count(type)))

Learning Data Science