1. Join?
2개 이상의 테이블을 연결해 데이터를 조회하는 방법
여러 테이블에 분산된 데이터를 논리적으로 결합해 하나의 결과 집합으로 만드는 연산
두 테이블의 조인을 위해서 PK와 FK 관계로 맺어져야 함.
SELECT 컬럼명
FROM 테이블A
JOIN 테이블B ON 테이블A.공통컬럼 = 테이블B.공통컬럼;
- 공통컬럼은 두 테이블의 관계를 연결하는 키 역할을 함
2. JOIN 유형
| JOIN 유형 | 기준 테이블 유지 | 일치하지 않는 데이터 처리 | 사용 예시 |
|---|---|---|---|
| INNER JOIN | 없음 | 제외 (공통키의 행만 결합) | 교집합 |
| LEFT JOIN | 왼쪽 | NULL | 왼쪽 우선 |
| RIGHT JOIN | 오른쪽 | NULL | 오른쪽 우선 |
| FULL JOIN | 양쪽 | NULL | 모든 데이터 |
| CROSS JOIN | 없음 | 곱집합 | 조합 계산 |
| SELF JOIN | 동일 테이블 | - | 계층 구조 탐색 |
내부조인은 두 테이블 모두 데이터가 있어야 결과가 나오지만, 외부 조인은 한쪽에만 데이터가 있어도 결과가 나옴
1) INNER JOIN
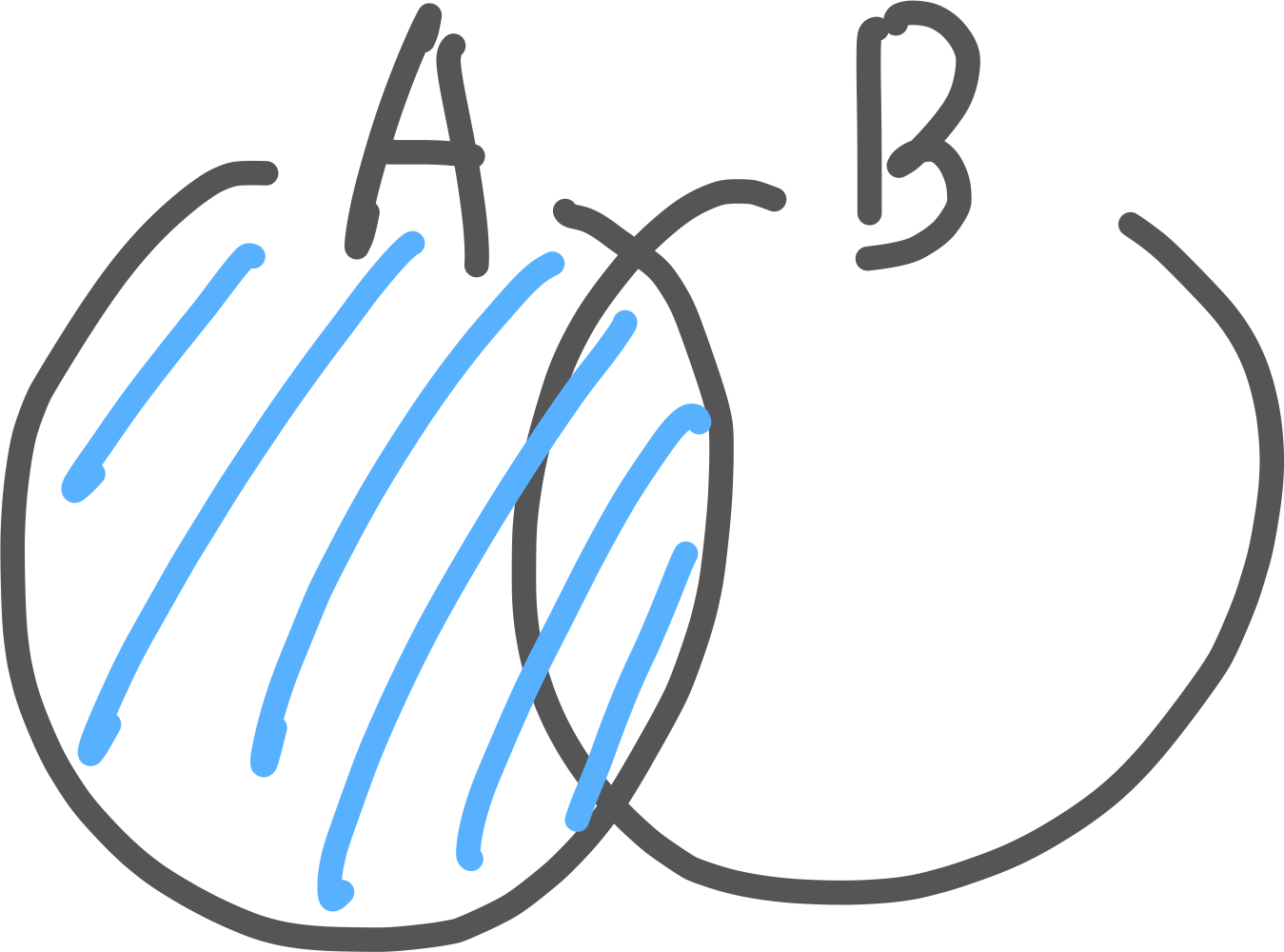
두 테이블 모두에서 조건이 일치하는 행만 가져옴
SELECT 열목록
FROM 첫번째테이블
INNER JOIN 두번째테이블
ON 조인조건
WHERE 검색조건2) LEFT JOIN (OUTER)

왼쪽 테이블의 모든 데이터 + 오른쪽 테이블의 일치하는 데이터 (없으면 NULL)
SELECT 열목록
FROM 첫번째테이블
LEFT/RIGHT/FULL OUTER JOIN 두번쨰테이블
ON 조인조건
WHERE 검색조건3) RIGHT JOIN

오른쪽 테이블의 모든 데이터 + 왼쪽 테이블의 일치하는 데이터 (없으면 NULL)
4) FULL JOIN
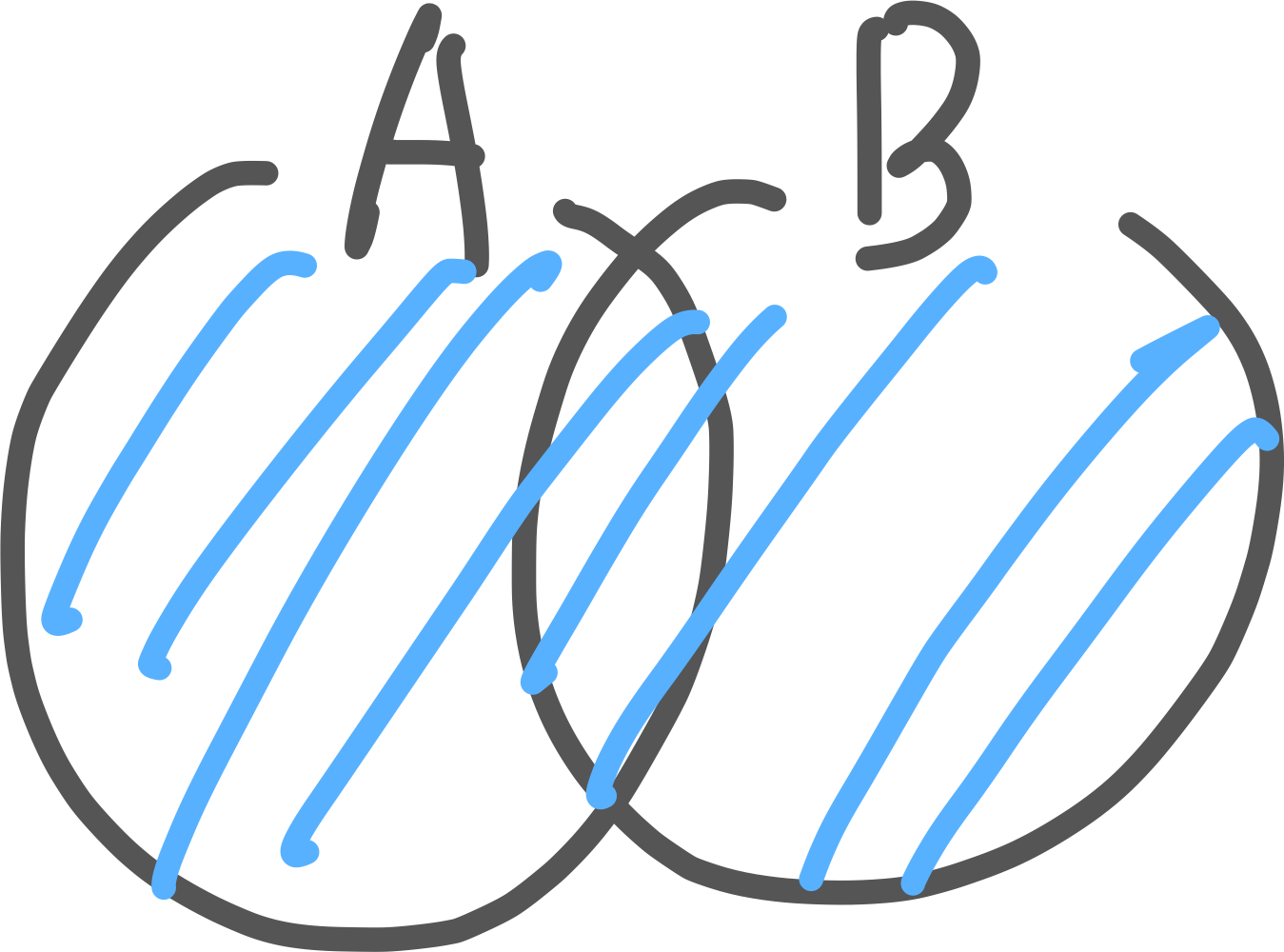
양쪽 테이블의 모든 데이터를 결합 (일치하지 않는 부분은 NULL)
5) CROSS JOIN
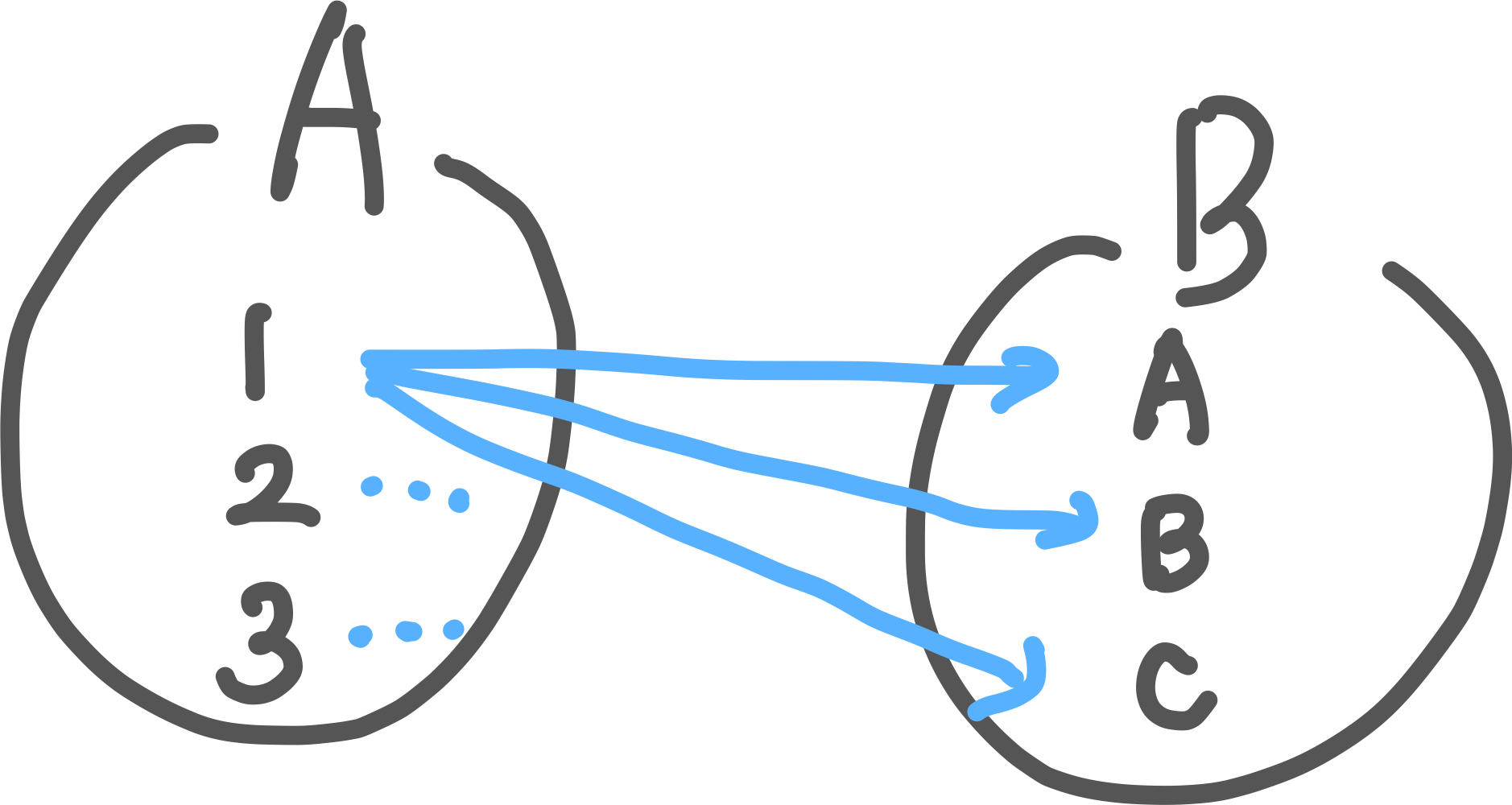
모든 경우의 수(카티전 곱)를 결합
한 쪽 테이블의 모든 행과 다른 쪽 테이블의 모든 행을 조인하여 모든 가능한 조합은 반환함.
ON 조건절이 필요없음.
6) SELF JOIN

같은 테이블을 두 번 참조하여 스스로 조인하는 기법
테이블에 별칭(Alias)을 붙여서 구분함.
주로 계층형 데이터를 다룰 때 사용함.
SELECT e.name AS employee, m.name as manager
FROM employess e
JOIN emplyees m
ON e.manager_id = m.id;3. JOIN 조건
1) ON
- 모든 JOIN 유형에서 사용 가능
- 조인을 수행할 때 사용됨 (테이블을 결합할 때의 조건)
- LEFT/RIGHT/FULL JOIN등에서 일지하지 않는 데이터는 NULL로 채워짐.
- JOIN 이후에도 WHERE로 추가 필터링 가능함.
SELECT * FROM users u
JOIN orders o
ON u.id = o.user_id;2) USING
- 두 테이블에 컬럼 이름이 동일할 때만 사용 가능함.
- 결합 시 동일 이름의 컬럼을 하나의 컬럼으로 합쳐서 반환함.
SELECT *
FROM employees
JOIN departments
USING (dept_id);3) WHERE
- JOIN이 끝난 후에 결과 행을 필터링함.
- 보통 INNER JOIN에서 사용됨.
- ON 없이 WHERE만 사용할 수 있음.
3. NULL 처리의 이해
| JOIN 유형 | NULL 처리 방식 | 예시 |
|---|---|---|
| INNER JOIN | 조건 불일치(NULL)는 제외 | NULL 행 제외 |
| LEFT JOIN | 오른쪽 매칭 없으면 NULL 채움 | NULL 포함 |
| RIGHT JOIN | 왼쪽 매칭 없으면 NULL 채움 | NULL 포함 |
| FULL JOIN | 매칭 없는 쪽은 NULL 채움 | 양쪽 NULL 가능 |
JOIN 조건에서 NULL은 비교 불가능함.
SQL에서 NULL은 ‘값이 없음’이기 때문에 비교연산자 != , = 로 비교 불가함
-- WHERE을 사용하는 경우
WHERE dept_id IS NULL; INNER JOIN에서의 NULL
INNER JOIN은 두 테이블의 조건이 일치해야 하므로, NULL이 있는 경우 비교가 불가능해 조인되지 않음.
SELECT e.name, d.name
FROM emplyoees e
INNER JOIN departments d
ON e.dept_id = d.id;
-- dept_id가 null인 직원에 대해서는 조인되지 않음LEFT JOIN에서의 NULL
오른쪽 테이블에 매칭이 없을 경우, NULL로 채움
SELECT e.name, d.name
FROM empployees e
LEFT JOIN departments d
ON e.dept_id = d.id;[employess]
| id | name | dept_id |
|---|---|---|
| 1 | Alice | 1 |
| 2 | Bob | 2 |
| 3 | Carol | NULL |
| 4 | David | 5 |
[deparments]
| id | name |
|---|---|
| 1 | Sales |
| 2 | HR |
| 3 | Marketing |
- 왼쪽 테이블(
employees)은 모두 유지됨. ON e.dept_id = [d.id](http://d.id/)조건으로
→ dept_id가 일치하는 경우에만 departments의 정보(d.name)가 붙음- 일치하지 않거나, dept_id가 NULL이면 NULL로 표시됨
[result]
| e.name | d.name |
|---|---|
| Alice | Sales |
| Bob | HR |
| Carol | NULL |
| David | NULL |
RIGHT JOIN에서의 NULL
SELECT *
FROM employees e
RIGHT JOIN departments d
ON e.dept_id = d.id;[employess]
| id | name | dept_id |
|---|---|---|
| 1 | Alice | 1 |
| 2 | Bob | 2 |
| 3 | Carol | NULL |
| 4 | David | 5 |
[deparments]
| id | name |
|---|---|
| 1 | Sales |
| 2 | HR |
| 3 | Marketing |
| 4 | Engineering |
- 오른쪽 테이블 departments가 유지되고, e테이블에서 일치하는 값이 추가됨
| e.id | e.name | e.dept_id | d.id | d.name |
|---|---|---|---|---|
| 1 | Alice | 1 | 1 | Sales |
| 2 | Bob | 2 | 2 | HR |
| NULL | NULL | NULL | 3 | Marketing |
| NULL | NULL | NULL | 4 | Engineering |
