토큰이란?
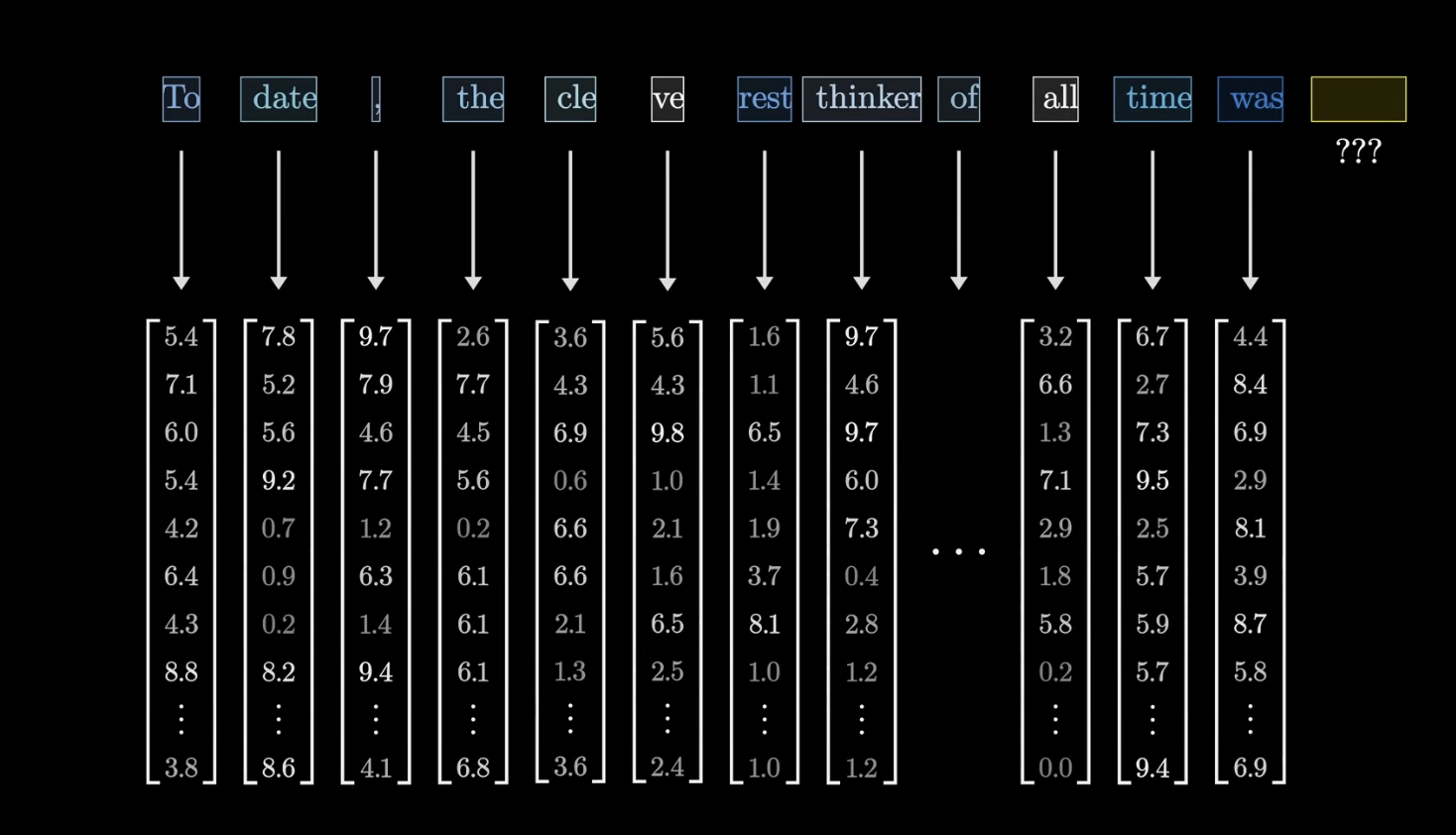
데이터의 가장 작은 단위를 벡터화 한 것으로 이해하면 쉬움
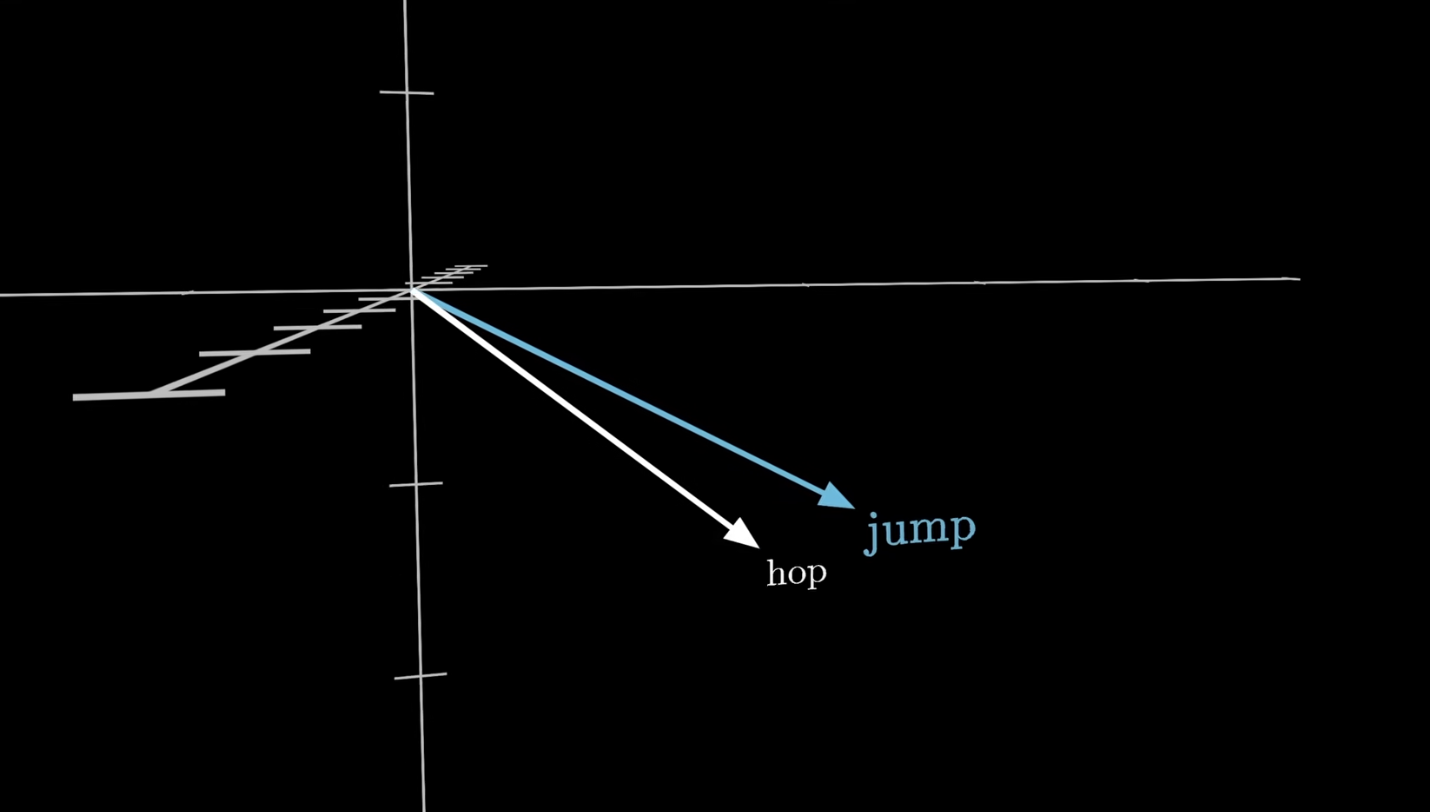
의미가 비슷한 단어들은 상대적으로 비슷한 위치에 있을 수 있음
Embedding
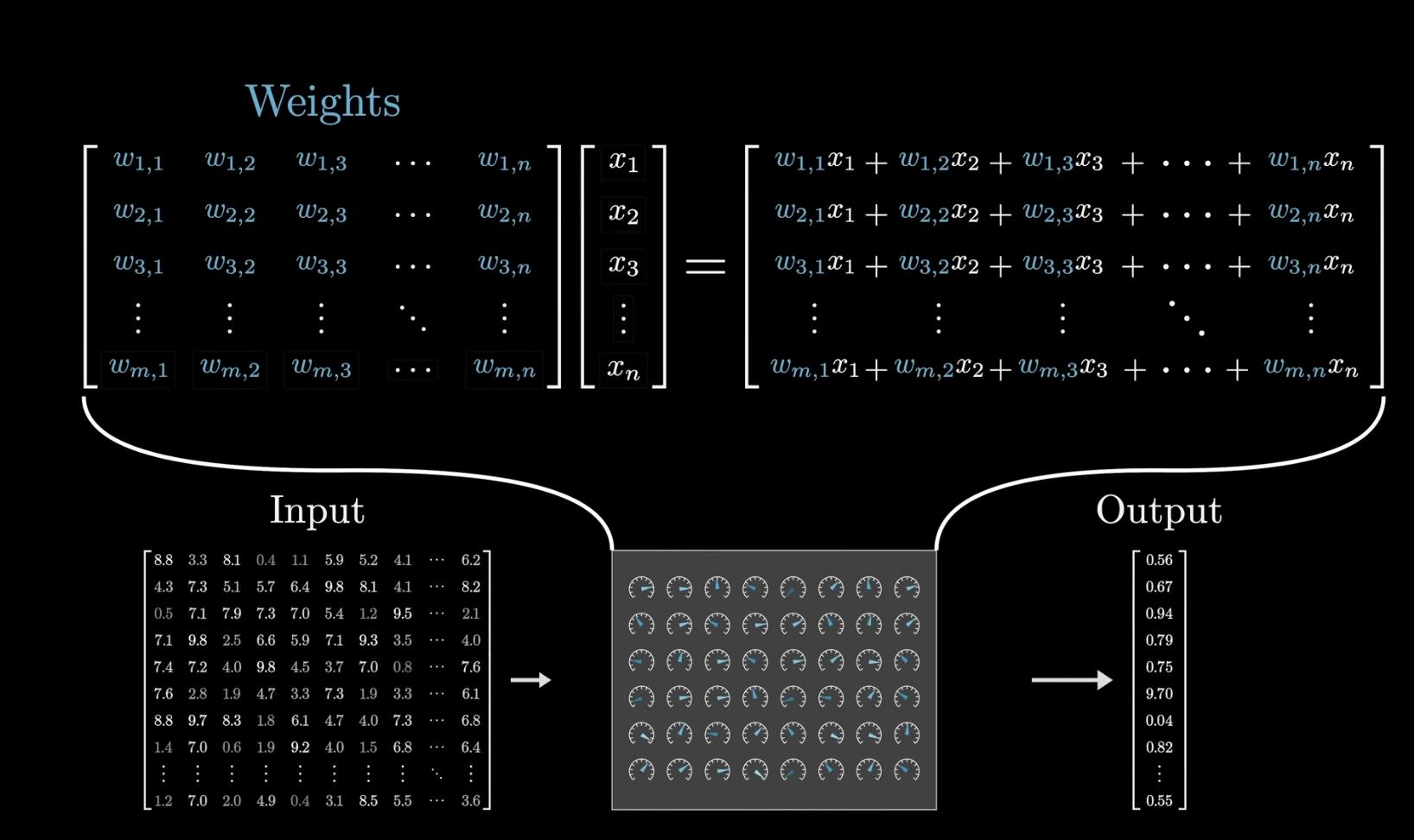
학습 가능한 매개변수 (Weight)로 단어 벡터간의 연산을 진행해 output을 도출한다.
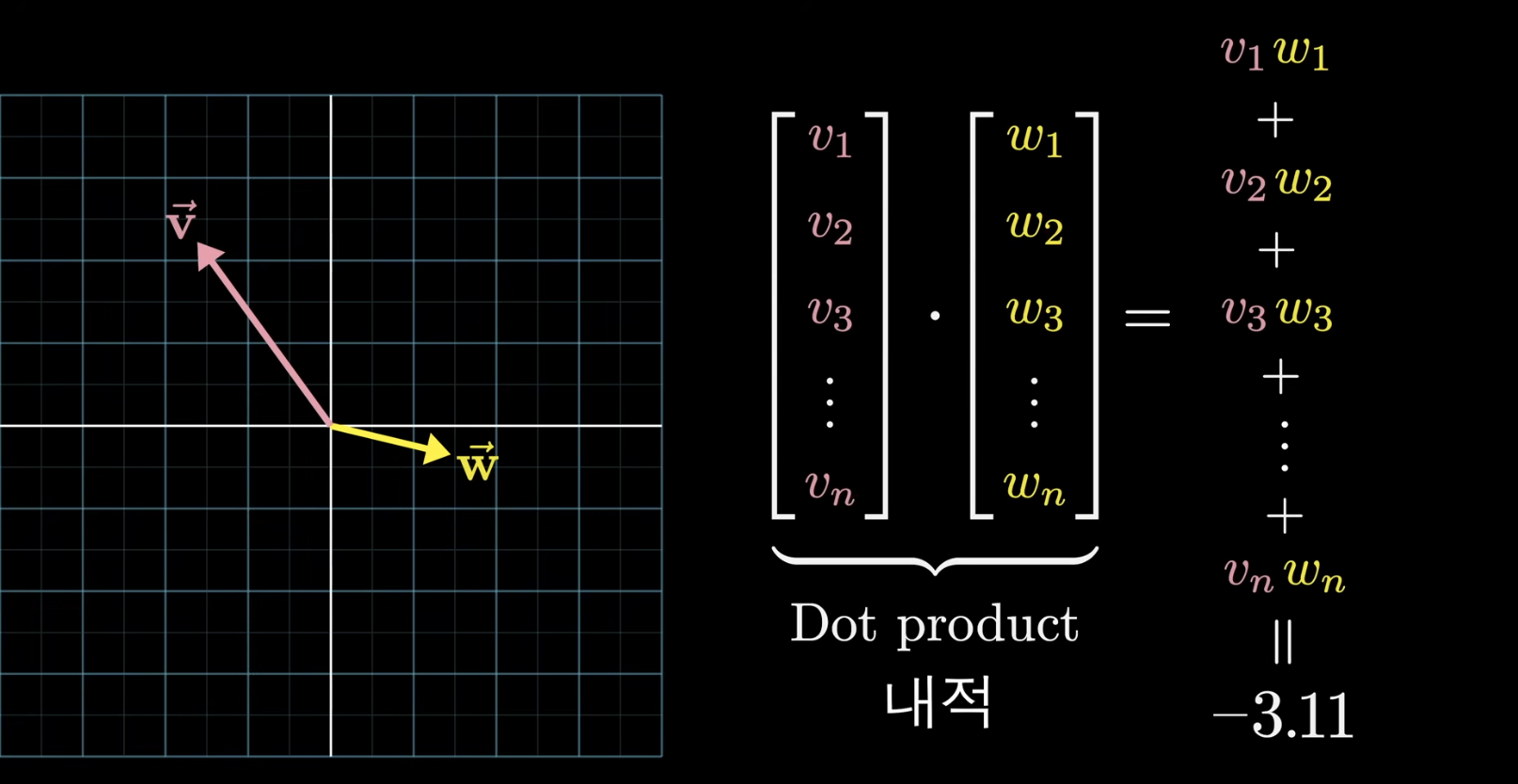
이때 비슷한 단어끼리는 양수, 서로 다른 의미를 가진 단어끼리는 음수의 값을 가지게 됨
- 이 입력 데이터는 일차원일수도 있고, 고차원 Tensor일 수 있음
Attention
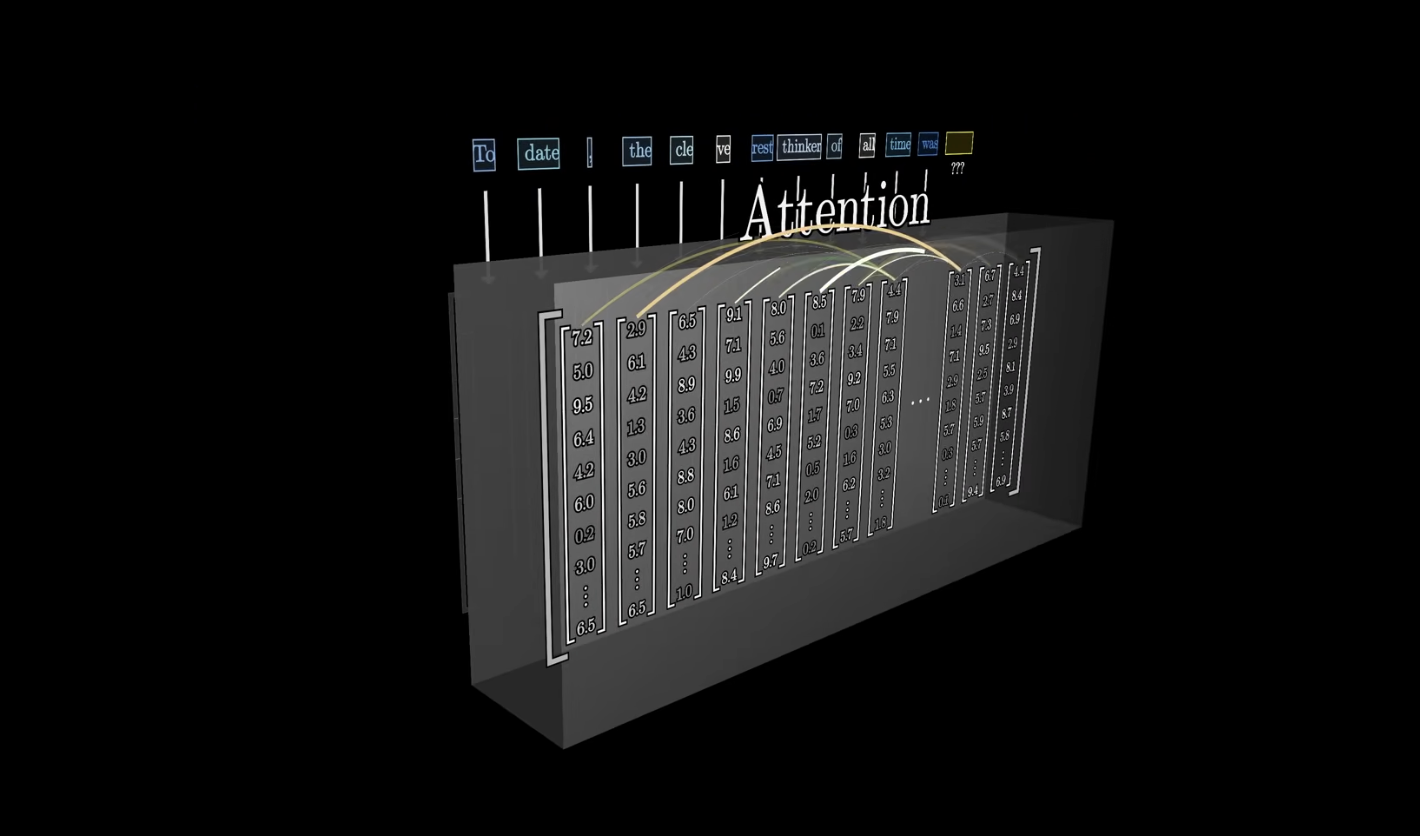
이렇게 각 열(토큰)의 벡터들은 서로 연산하며 의미를 업데이트하게 됨 -> 벡터 값 업데이트
ex) 동음이의어 등..
여기서의 의미는 특정한 벡터로 인코딩하는 것과 동일한 의미
Multilayer Perceptron
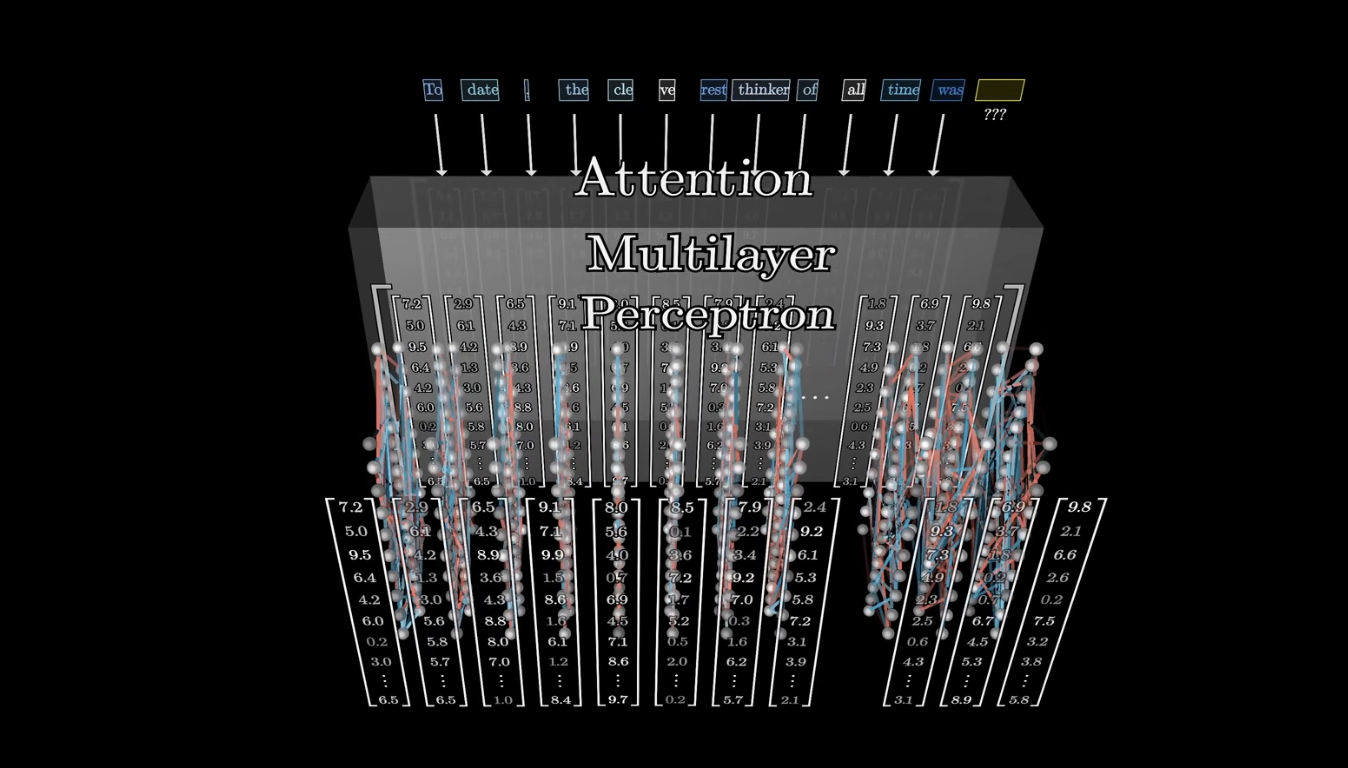
Multilayer Perceptron을 통해서 병렬로(같은 벡터 끼리만) 추가적인 연산을 진행해 값을 업데이트 하게 됨
-> 각 벡터가 어떤 역할을 하는지에 대한 연산을 진행함
그리고 레이어 사이사이에 정규화 진행!
- Softmax 함수 사용해서 각 단어의 확률 분포로 나타낼 수 있도록 함
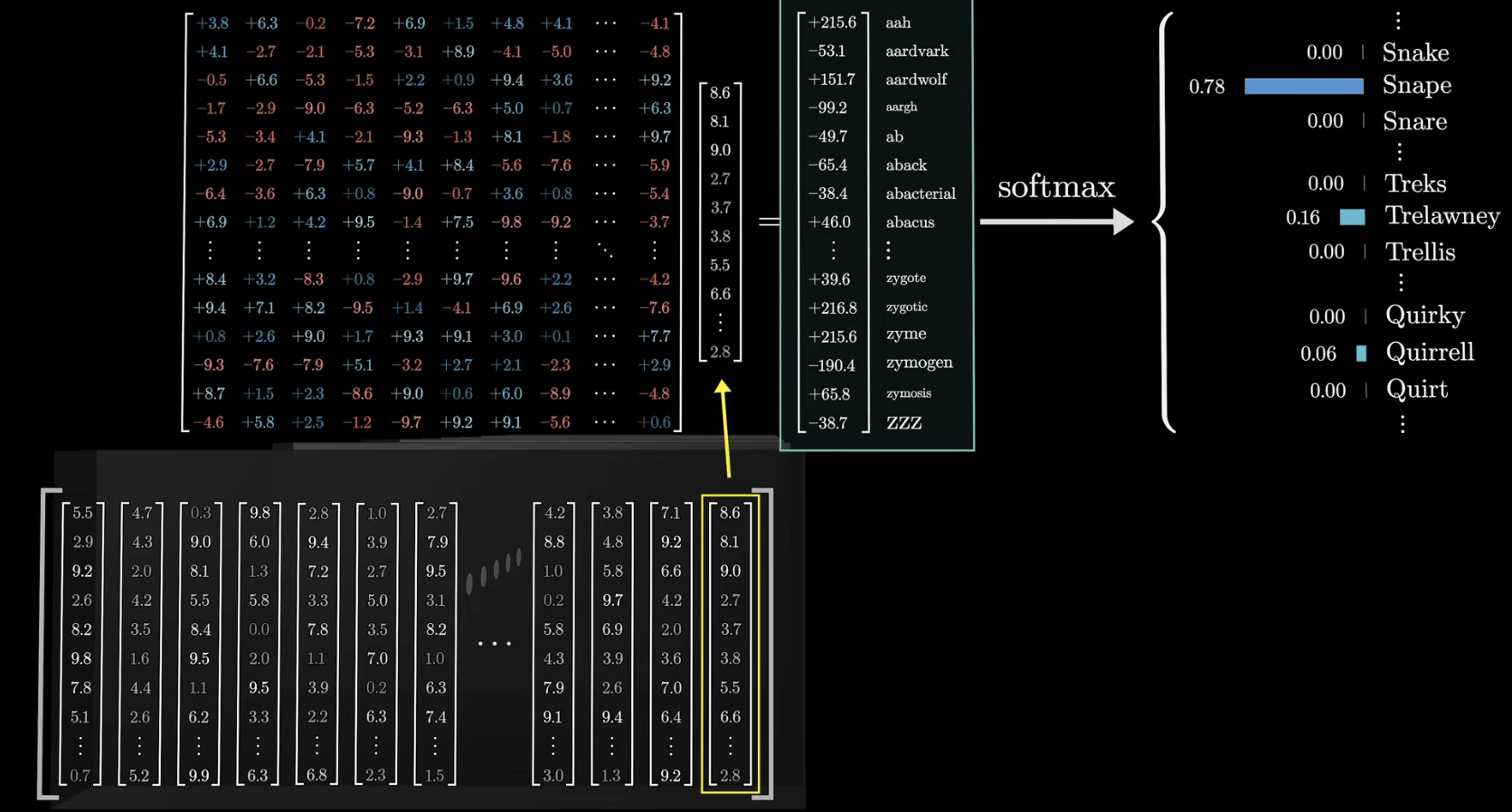

이때 Temperature 라는 T 변수를 조정하며 어느정도로 균일한 확률을 보일 건지 정해줌 - T가 클수록 : 데이터의 확률이 균등하게 조정됨 (뒤에 어떤 단어가 올 지 더 많은 가능성 부여)
- T가 작을수록 : 가장 높은 확률을 보이는 단어의 확률이 1에 가까워짐 (하나만 선택될 확률 증가)
기본 로직
- 처음 임베딩 매트릭스 (기본 정의 매트릭스)를 통해서 단어의 벡터를 그대로 가져옴
- Attention 과정을 거쳐 단어의 의미를 업데이트 (맥락정보 업데이트)
- 이 때 Context size를 통해서 모델이 처리할 수 있는 맥락 참고 텍스트 사이즈를 정해줘야 함
- Multilayer Perceptron을 통해서 추가적인 연산 진행해줌 (병렬 처리)
- 마지막에 올 단어를 예측하기 위해서 필요한 것은 각 단어의 확률 분포 (높은 확률을 갖는 단어가 등장해야 함)
- 이 때 , 확률 분포로 정규화 하기 위해 Softmax 함수 사용

뇽안