LM (언어 모델, Language Model) 이란, 인간의 언어를 이해하고 생성하도록 훈련된 일종의 인공지능 모델이다. 언어 모델의 품질은 크기나 훈련된 데이터의 양 및 다양성, 훈련 중에 사용된 학습 알고리즘의 복잡성에 따라 달라진다.
LLM (거대 언어 모델, Large Language Model) 이란, 대용량의 언어 모델을 의미한다. LLM은 딥 러닝 알고리즘과 통계 모델링을 통해 자연어 처리(Natural Language Processing, NLP) 작업을 수행하는 데에 사용한다. 이 모델은 사전에 대규모의 언어 데이터를 학습하여 문장 구조나 문법, 의미 등을 이해하고 생성할 수 있다.
예를 들어, 주어진 문맥에서 다음 단어를 예측하는 문제에서 LLM은 문장 내의 단어들 사이의 유사성과 문맥을 파악하여 다음 단어를 생성할 수 있다. 이러한 작업은 기계 번역, 텍스트 요약, 자동 작문, 질문 응답 등 다양한 NLP 과제에 활용된다. LLM은 GPT(Generative Pre-trained Transformer)와 BERT(Bidirectional Encoder Representations from Transformers)와 같은 다양한 모델들이 있다. 이러한 모델들은 수천억 개의 매개변수를 가지고 있다. 최근에는 대용량의 훈련 데이터와 큰 모델 아키텍처를 사용하여 더욱 정교한 언어 이해와 생성을 달성하는데 주목을 받고 있다.
NLP vs. LLM
NLP와 LLM은 관련이 있는 개념이지만, 서로 다른 개념이다.
NLP는 인간의 언어를 이해하고 처리하는 데 초점을 맞춘 인공지능 분야이다. NLP는 컴퓨터가 자연어 텍스트를 이해하고 분석하는 기술을 개발하는 것을 목표로 한다. NLP는 문장 구문 분석, 텍스트 분류, 기계 번역, 질의 응답 시스템, 감정 분석 등과 같은 다양한 작업에 활용된다.
반면 LLM은 큰 데이터셋을 사용하여 훈련된 대용량의 언어 모델을 가리킵니다. 딥 러닝 기술과 통계 모델링을 사용하여 자연어 처리 작업을 수행할 수 있다.
즉, NLP는 자연어 처리 분야 전반을 아우르는 개념이며, 텍스트를 이해하고 처리하는 기술에 초점을 둡니다. LLM은 NLP의 한 부분으로, 대량의 언어 데이터를 바탕으로 학습된 언어 모델을 사용하여 특정 NLP 작업을 수행하는데 초점을 둡니다. NLP는 더 넓은 의미의 개념이며, LLM은 그 안에서 특정한 접근 방식과 모델을 가리키는 한 가지 형태입니다.
LLM (거대 언어 모델) 작동 원리
언어 모델의 유형
모델 개발 단계는 다음과 같다.
- SLM (Small Language Model): 제한된 양의 텍스트 데이터를 학습하여, 작업 전반에 걸쳐 국소적인 문맥을 이해하는 데에 초점을 맞춥니다. 작은 규모에도 불구하고, SLM은 가볍고 실행 속도도 빠른 특징을 가지고 있습니다.
- NLM (Neural Language Model): NLM은 기존의 통계 기반 언어 모델보다 더 정확한 성능을 제공합니다. 이러한 모델은 주로 단어 임베딩, 문장 완성, 기계 번역 등 다양한 NLP 작업에 사용됩니다.
- PLM (Pretrained Language Model): PLM은 대규모 데이터셋으로 미리 학습되며, 이후 다양한 NLP 작업에 전이학습(Transfer Learning)을 통해 적용됩니다. BERT와 GPT와 같은 주요 모델들은 이 PLM에 속합니다.
연구자들은 PLM을 확장하면 다운스트림 작업에서 모델 용량이 향상될 수 있다는 사실을 발견했다. 많은 연구에서 훨씬 더 큰 PLM을 훈련하면서 성능 한계를 탐색해보고자 했다. 이러한 대형 PLM은 소형 PLM과는 다르게, 일련의 복잡한 작업을 해결할 때 놀라운 능력을 발휘한다는 점이 밝혀졌다. 예를 들어, GPT-3는 상황을 학습하여 단발성 과제를 해결할 수 있는 능력을 가졌지만 GPT-2는 그렇지 못했다. 따라서 연구 커뮤니티에서는 이러한 대형 PLM을 두고 “대규모 언어 모델(LLM)”이라는 용어를 사용하기 시작했습니다. 즉, LLM은 언어 모델의 현주소이자 최종 개발 단계라고 할 수 있습니다.
LLM 용어
- 단어 임베딩: 단어들을 고차원 벡터로 표현하여 각 단어 간의 유사성과 관계를 캡처하는 기술
- 주의 메커니즘: 입력 시퀀스의 다양한 부분에 가중치를 부여하여 모델이 중요한 정보에게 집중할 수 있도록 하는 기술
- Transformer: 주의 메커니즘을 기반으로 한 인코더와 디코더 구조의 신경망 모델로, 길이가 다른 시퀀스를 처리하는 데 탁월한 성능
- Fine-tuning LLMs: 사전 학습된 대규모 언어 모델을 특정 작업에 적용하기 위해 추가 학습하는 과정
- Prompt engineering: 모델에 입력하는 질문이나 명령을 구조화하여 모델의 성능을 향상시키는 과정
- Bias (편향): 모델이 학습 데이터의 불균형이나 잘못된 패턴을 포착하여 실제 세계의 현실과 일치하지 않는 결과를 내놓는 경향
- 해석 가능성: LLM이 가진 복잡성을 극복하고 AI 시스템의 결과와 결정을 이해하고 설명할 수 있는 능력
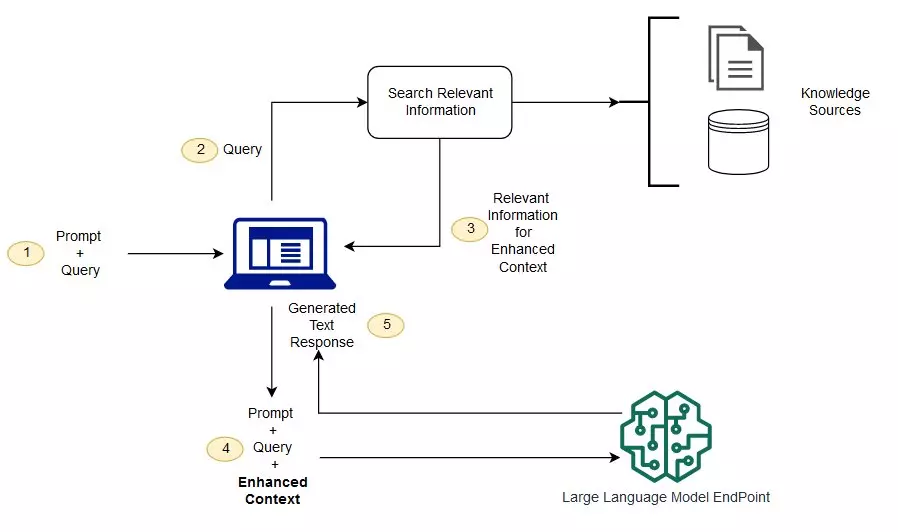
LLM이 언어를 학습하는 과정에는 딥 러닝의 원리가 활용된다. LLM은 딥 러닝의 방식으로 방대한 양을 사전 학습(Pre-trained)한 전이 학습 (Transfer) 모델이라고 할 수 있다.
LLM은 문장에서 가장 자연스러운 단어 시퀀스를 찾아내는 딥 러닝 모델이다.
문장 속에서 이전 단어들이 주어지면 다음 단어를 예측하거나 주어진 단어들 사이에서 가운데 단어를 예측하는 방식으로 작동한다.
LLM을 학습시키는 방법은 대부분 큰 양의 텍스트 데이터를 기계학습 알고리즘에 입력하는 것이다. 이때 일반적으로, 먼저 토큰화(tokenization)과 같은 전처리 과정을 거쳐 문자열 데이터를 분리한 다음, BERT, GPT, GPT-2, GPT-3, T5 등의 모델을 사용하여 학습한다.
파인튜닝/프롬프트 튜닝
파인 튜닝 (Fine-tuning)
사전 학습된 언어 모델 전체를 대상으로 추가 작업 데이터를 이용하여 모델을 재학습시키는 방법법. 사전 학습한 모델을 초기 가중치로 사용하고, 특정 작업에 대한 추가 학습 데이터로 모델을 재학습
- 모델 파라미터의 일부 또는 전체를 재학습하기 때문에 작업 특정성(task-specific)이 높은 모델을 얻을 수 있다.
- 대량의 추가 작업 데이터가 필요할 수 있다.
- 일반적으로 새로운 작업에 대해 파인 튜닝하는 데 시간이 오래 걸릴 수 있다.
- 특정 작업에 특화된 예측 수행 가능성이 높아진다.
프롬프트 튜닝 (Prompt tuning)
입력 텍스트에 특정 구조화된 프롬프트(prompt)를 추가하거나 수정하여 모델의 동작을 조정하는 방법. 특정 작업에 맞는 최적의 프롬프트 구성을 실험하고, 모델 출력을 조작하여 원하는 결과를 얻을 수 있도록 모델을 조정.
- 사전 학습된 모델의 파라미터를 고정하고, 프롬프트 구성을 조정하여 특정 작업에 적합한 결과를 얻는다.
- 기존 데이터에 추가 작업하지 않아도 되므로 데이터 확보에 대한 부담을 줄일 수 있다.
- 작업 특정성이 낮고, 다양한 작업에 대해 유연한 조정이 가능.
- 초기 설정과 프롬프트 구성에 대한 실험이 필요하며, 설정에 따른 성능 차이가 있을 수 있다.
