Transformer의 기본 구조
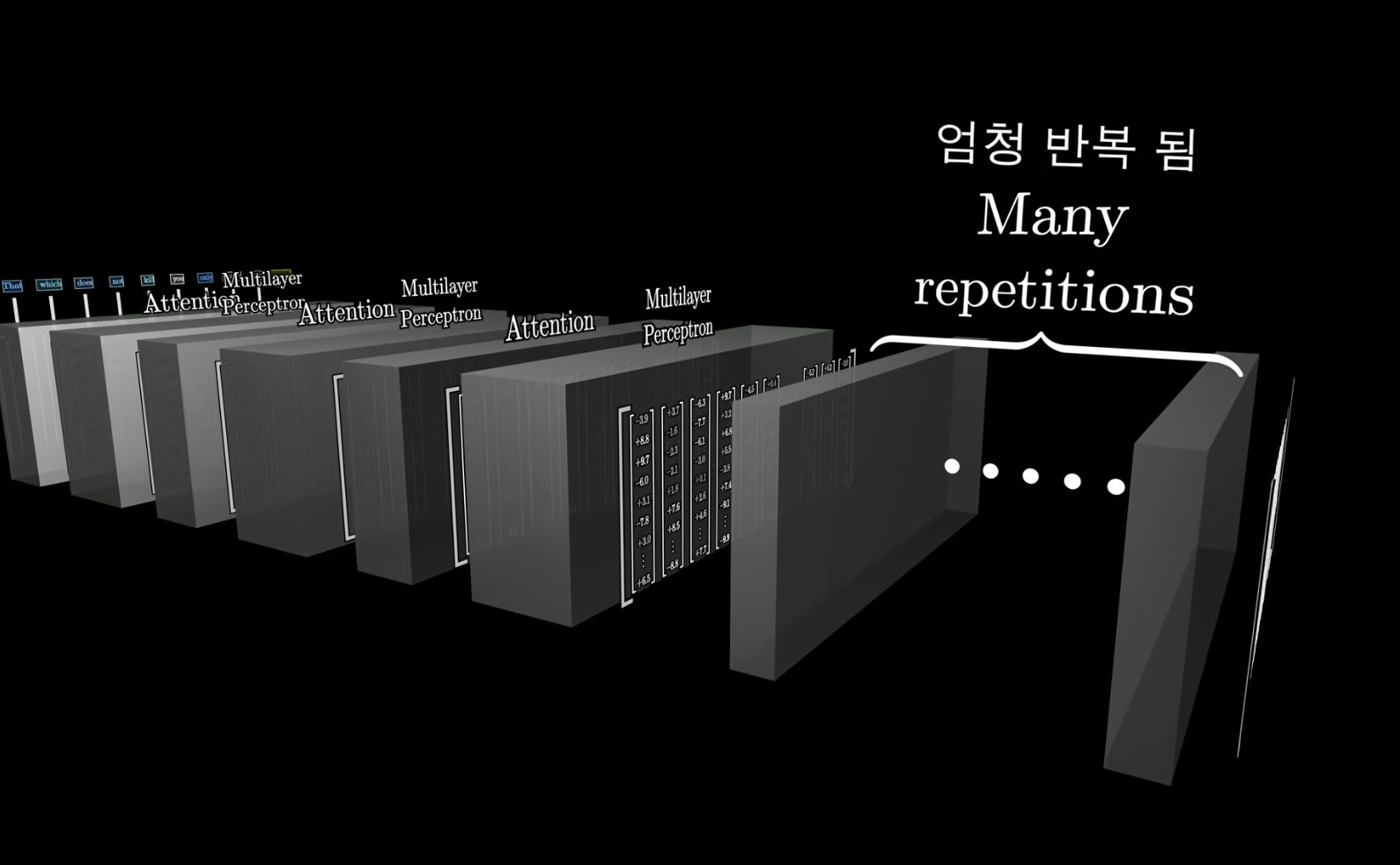
Attention block
- 모든 단어는 고차원 공간에 임베딩 되어 있음 !
- 각 단어들은 Attention 블록을 거치면서 다양한 문맥을 가질 수 있도록 업데이트 됨
MLP
- 어떤 사실 정보를 저장하기에는 MLP쪽이 더 많은 정보를 가지고 있음
MLP의 기본 전제
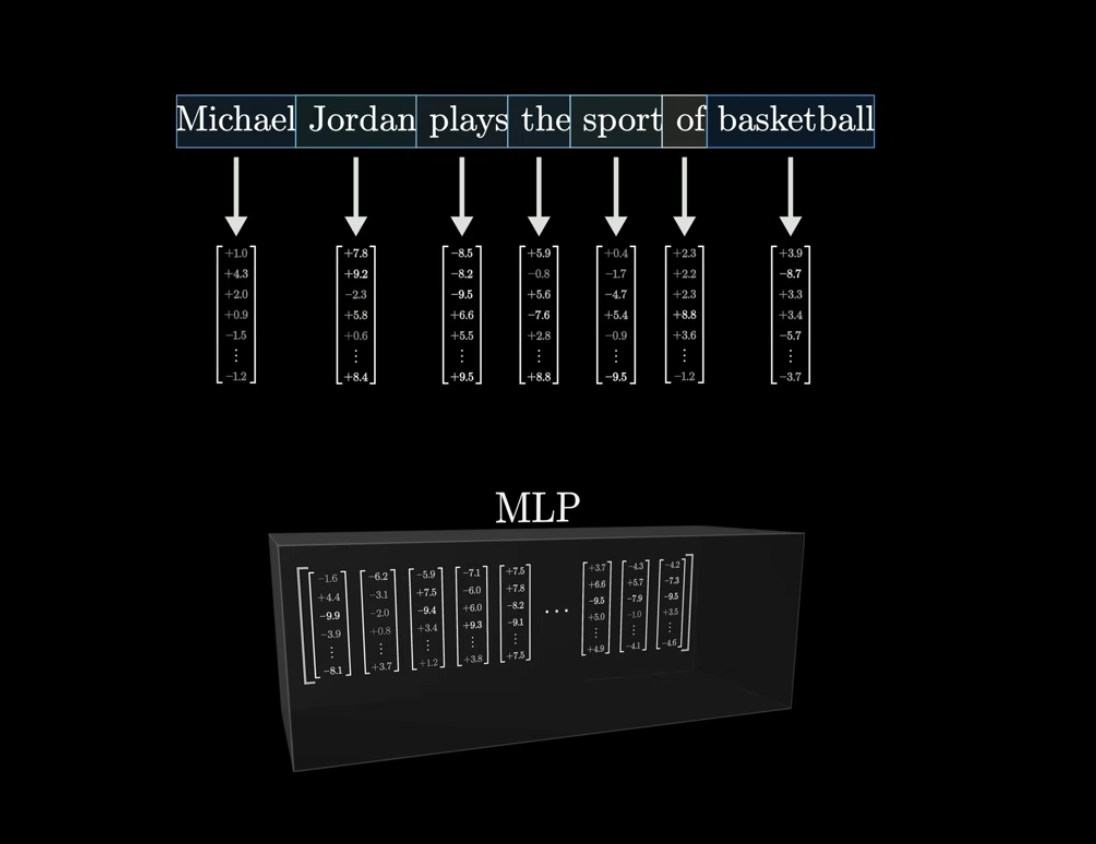
- 각 임베딩 데이터들이 MLP 블록 안으로 들어오게 된다
- 그리고 각 단어들은 각각 고유한 벡터를 가지고 있음
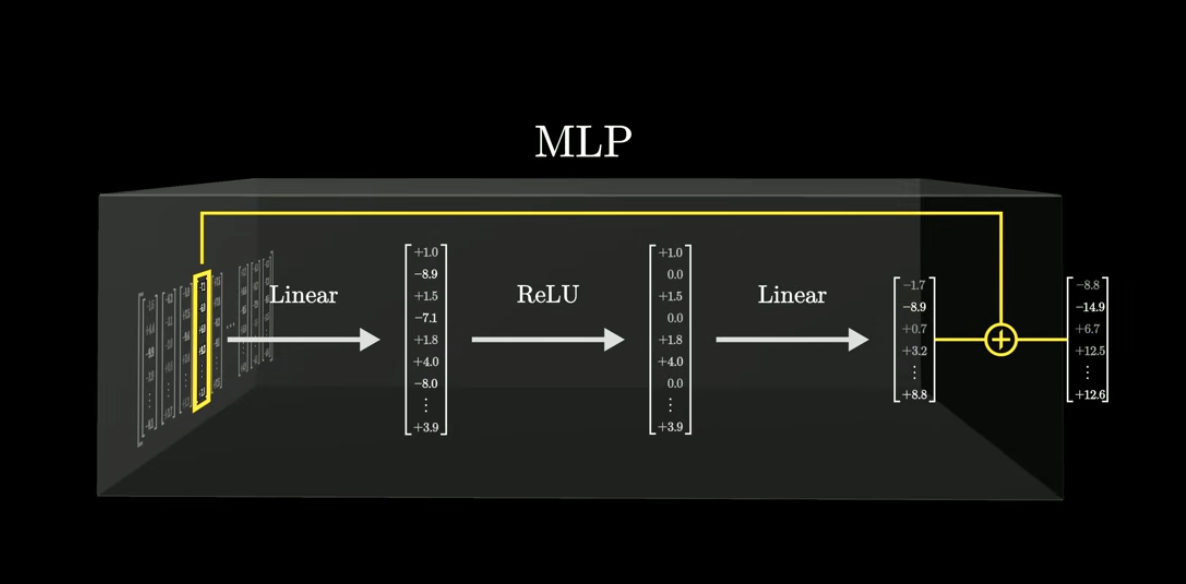
MLP의 역할은?
- 각 벡터의 값들을 미리 정한 연산 순서대로 계산해줌
- 최종적인 결과 벡터를 얻게 됨
- 이 결과 벡터는 처음 input으로 넣은 벡터와 더해져서 다음 레이어로 넘어가게 됨
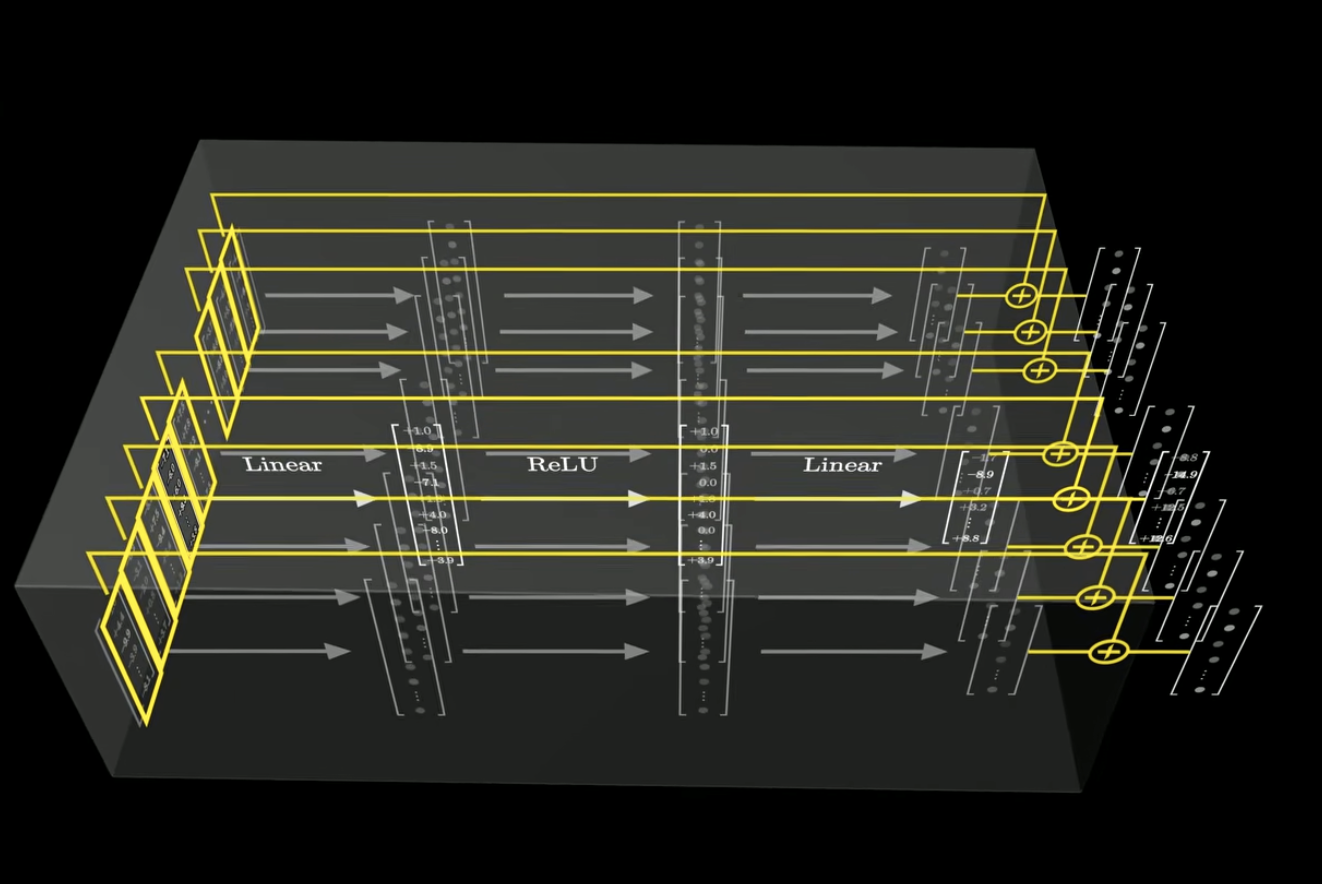
이 과정을 모든 벡터에 대해 똑같이 수행, 병렬적 적용 (독립적 연산)
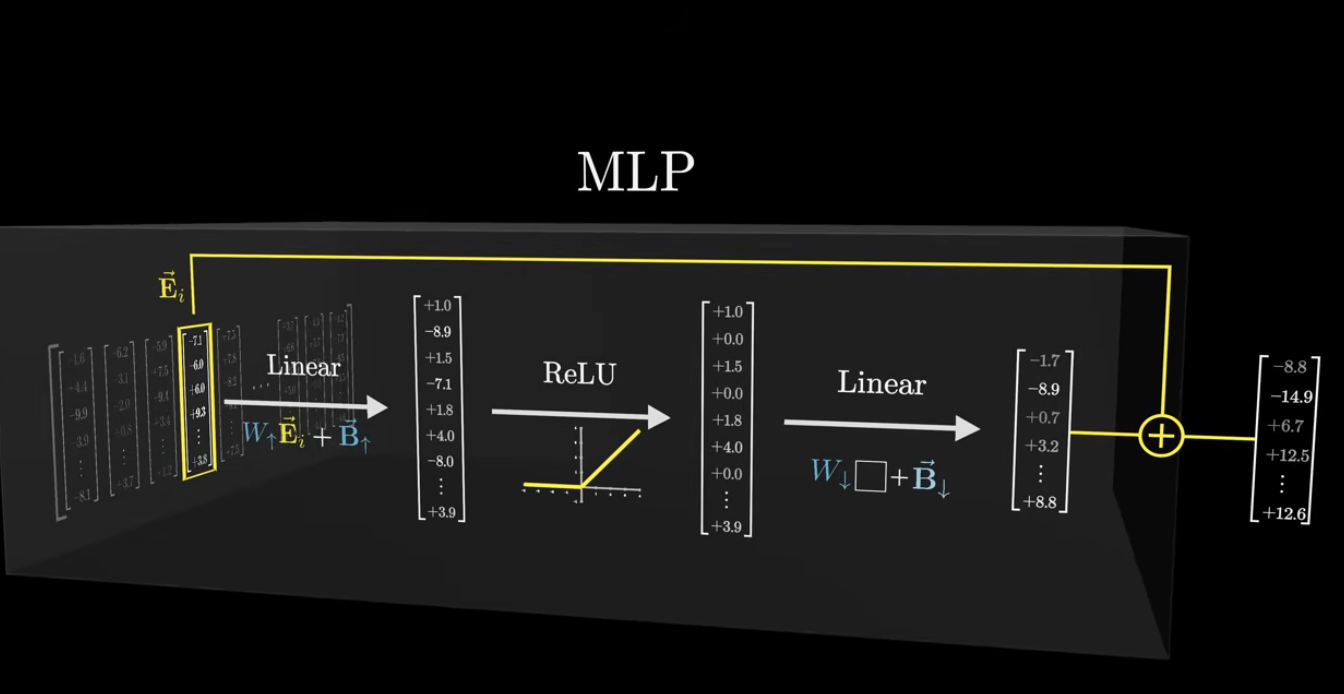
1. 첫 번째 선형 계층 (First Linear Layer)
- 구조 :
- 역할 : 입력 벡터의 차원( 또는 )을 확장(Expansion)
- 트랜스포머의 오리지널 논문("Attention Is All You Need")에서는 입력 차원 를 4배 확장하여 차원으로 만듬 - 목적 : 고차원 공간으로 매핑함으로써 모델이 더 복잡한 특징(feature)과 비선형적 관계를 학습할 수 있는 능력을 부여합니다.
2. 활성화 함수 (ReLU Activation)
- 구조:
- 역할: 비선형성(Non-linearity)을 도입
- 목적: 선형 변환만으로는 복잡한 데이터 패턴을 학습할 수 없기 때문에, ReLU(Rectified Linear Unit) 함수를 통해 모델에 비선형성을 추가하여 표현력을 극대화
3. 두 번째 선형 계층 (Second Linear Layer)
- 구조:
- 역할: 확장된 차원()을 다시 원래의 차원()으로 축소(Projection)
- 목적: 확장된 특징을 압축 -> 변환된 정보를 다음 서브 레이어나 최종 출력 계층으로 전달하기 위해 차원을 일치시킴

뇽안