
📍 Intro
- 항해99 실전프로젝트를 6주간 진행하면서 검색 및 필터 기능에 대해 성능 개선을 진행했다.
- 처음에 1주일이라는 기간을 잡았는데 사실상 2주라는 시간이 할애되었고 핵심 기능인 만큼 시간이 걸리더라도 목표를 달성하는 것에 초점을 맞췄다.
❓ 검색 성능 개선 "왜" 했어?
- KISSmetrics에 따르면 고객의 47%가 2초 이내의 시간에 로딩이 되는 웹 페이지를 원하고 있으며, 40%는 로딩이 3초 이상 걸리는 페이지를 바로 떠난다고 한다.
- 👉🏻 비즈니스적인 관점에서 이탈률 40%는 매우 치명적이다. 그렇기 때문에 검색 성능 개선의 필요성을 느꼈다.

📑 진행 단계
- 진행단계는 모두 7단계다.
- Index 생성, Cross Join 제거, 불필요한 Join이 발생하지 않도록 분기 처리해 Count Query 개선, No Offset 방식 적용, Covering Index 생성, Full-Text Index 생성 및 Match() Against() 사용, 검색 로징 변경이다.
- 그 중에서 No Offset 방식과 Full-Text Index는 적용하지 않았는데 그 이유도 아래에 설명하겠다.
1. Index 생성
- 적용 계기
- 기존 쿼리 실행 시 Order By 부분에서 많은 시간이 소요되는 것을 알 수 있었다. 그래서 Index를 적용하기로 했다.
- 인덱스 항목
- 리뷰수(Default 정렬값)
- 👉🏻 실제 쇼핑몰의 경우 변동이 많은 값이므로 인덱스로 설정하지 않는 것이 좋지만 현재 Mucosa 프로젝트의 경우 리뷰수 변동이 없으므로 인덱스로 설정하기로 결정했다.
- 가격(고가순, 저가순)
- 리뷰수(Default 정렬값)
- 결과 분석
- 개선된 부분
- 대부분의 첫 페이지 로딩이 개선되었으며 최대 2880%까지 개선되었다.
- 추가 개선이 필요한 부분
- 일부 항목의 경우 Count Query에 성능 저하 발생했다.
- 개선된 부분
2. Cross Join 제거
- 적용 계기
- Querydsl로 작성한 쿼리가 Cross Join을 발생시키고 있다는 것을 알게 되었다.
- 👉🏻 Cross Join 대신 Inner Join이 발생하도록 코드를 수정했다.
- Cross Join 제거 방법
- Cross Join이 발생하는 Brand 테이블을 Inner Join이 발생하도록 쿼리 수정했다.

- Cross Join이 발생하는 Brand 테이블을 Inner Join이 발생하도록 쿼리 수정했다.
- 결과 분석
- 개선된 부분
- 키워드 검색 부분의 경우 기존에 발생하던 Cross Join이 Inner Join으로 변경되면서 최대 232%까지 개선되었다.
- 추가 개선이 필요한 부분
- 단순 메인페이지 로딩의 경우 Join을 강제하면서 Count Query에 성능 저하가 발생
- 개선된 부분
3. 불필요한 Join이 발생하지 않도록 분기 처리해 Count Query 개선
- 적용 계기
- Inner Join을 명시적 처리하면서 Brand 테이블 필요하지 않은 Count Query에서도 Join이 발생하여 성능이 떨어진 사실을 발견했다.
- 불필요한 Join이 발생하지 않도록 분기 처리했다.
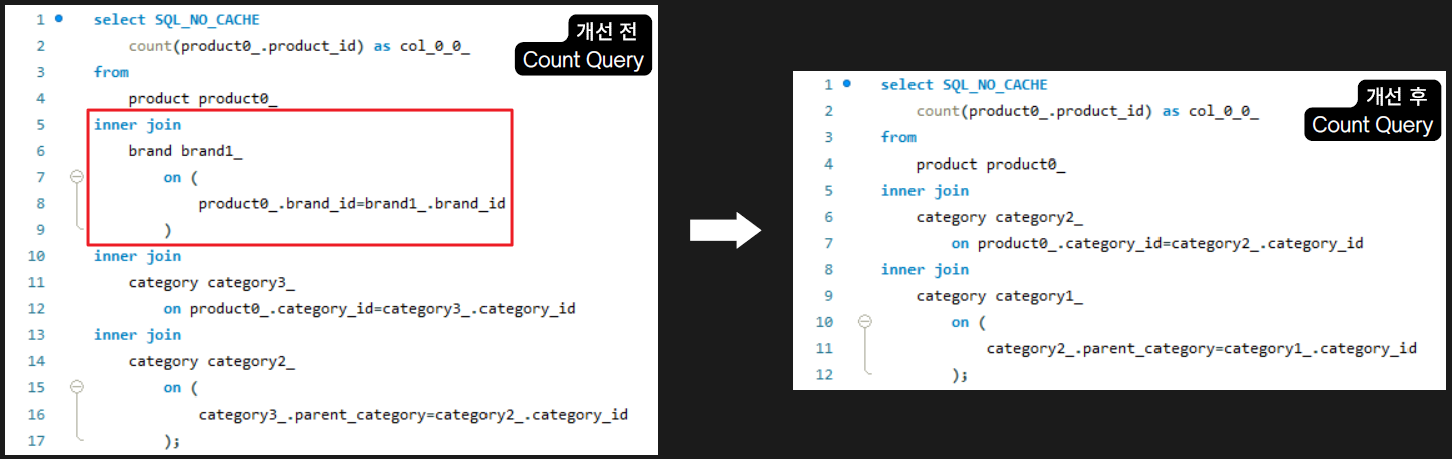
- 결과 분석
- 개선된 부분
- Inner Join을 강제하면서 발생했던 count query 성능 저하에 대해서는 최대 1127%까지 개선되었다.
- 추가 개선이 필요한 부분
- 마지막 페이지에 대한 Query 속도는 여전히 느렸다.
- 개선된 부분
4. No Offset 방식 적용
- 적용 계기
- 페이징 처리 시 Offset이 성능 저하를 발생한다는 사실을 알게 되었다.
- 👉🏻 No Offset 방식 적용하기로 했다.
- Offset이 성능 저하를 발생시키는 이유
- Offset을 사용하게 되면 Offset + Limit만큼의 데이터를 읽은 후 Offset만큼의 데이터를 버린다.
- 👉🏻 마지막 페이지로 갈수록 읽어야하는 데이터 수가 비약적으로 증가한다.
- No Offset 방식을 적용하지 않은 이유
- No Offset 방식의 경우 Offset 사용 대신 where절에 조회 시작 부분을 판단하도록 한다.
👉🏻 하지만 MUCOSA의 경우 Where절에 사용될 조회 시작 부분을 판단하도록 하는 기준 key가 중복이 가능한 값(리뷰수, 가격)이기 때문에 No Offset 방식을 적용할 수 없다고 판단했다. - No Offset 방식의 경우 페이징버튼이 아닌 ‘more(더보기)’ 버튼을 사용해야 한다.
👉🏻 순차적 페이지 이동만 가능한데 MUCOSA의 경우 전체 상품 수가 100만개이므로 페이지 이동이 자유로운 페이징 버튼을 사용하는 것이 좋을 것으로 판단했다.
- No Offset 방식의 경우 Offset 사용 대신 where절에 조회 시작 부분을 판단하도록 한다.
5. Covering Index 생성
- 적용 계기
- No Offset 방식을 적용할 수 없는 상황에서 성능을 개선하기 위해 Full Scan이 발생하는 Product 테이블 개션의 필요성을 알게 되었다.
- 👉🏻 Covering Index를 통해 'where, order by, offset ~ limit'를 인덱스 검색으로 빠르게 처리하고 걸러진 데이터를 통해서만 데이터 블록에 접근하기 때문에 성능 개선이 가능하다고 판단했다.
- Querydsl에서의 Covering Index 적용
- Querydsl의 경우 from절의 서브쿼리를 지원하지 않는다.
- 👉🏻 커버링 인덱스를 활용하여 조회 대상의 PK를 조회하는 부분과 해당 PK로 필요한 컬럼 항목들을 조회하는 부분을 나누어 구현

- 결과 분석
- 개선된 부분
- 마지막 페이지 속도가 최대 236%까지 개선되었다.
- 추가 개선이 필요한 부분
- 첫페이지에 대해 목표했던 2초 이내의 결과는 달성하지 못했다.
- 키워드 검색에 대한 성능 개선이 다른 항목들에 비해 많이 되지 않았다.
- 개선된 부분
6. Full-Text Index 생성 및 Match()-Against()
- 적용 계기
- 마지막 페이지 부분이 개선되었으나 처음 목표했던 2초 이내는 달성하지 못함. 그래서 엘라스틱서치 적용도 고려했지만 엘라스틱서치의 역인덱싱 방식과 같은 원리로 동작하는 MySQL의 Full-Text 인덱스를 알게 되었다.
- 👉🏻 굳이 엘라스틱 서치를 이용할 필요 없이 Full-Text Index를 적용하고 Match()-Against() 쿼리문을 사용했다.
- Full-Text Index 방식을 적용하지 않은 이유
- Full-Text 인덱스를 적용하여 실제 테스트를 해 본 결과 성능 개선이 되지 않았다.
- 👉🏻 MUCOSA의 경우 검색 시 Join이 많이 발생하기 때문이라고 판단했다.
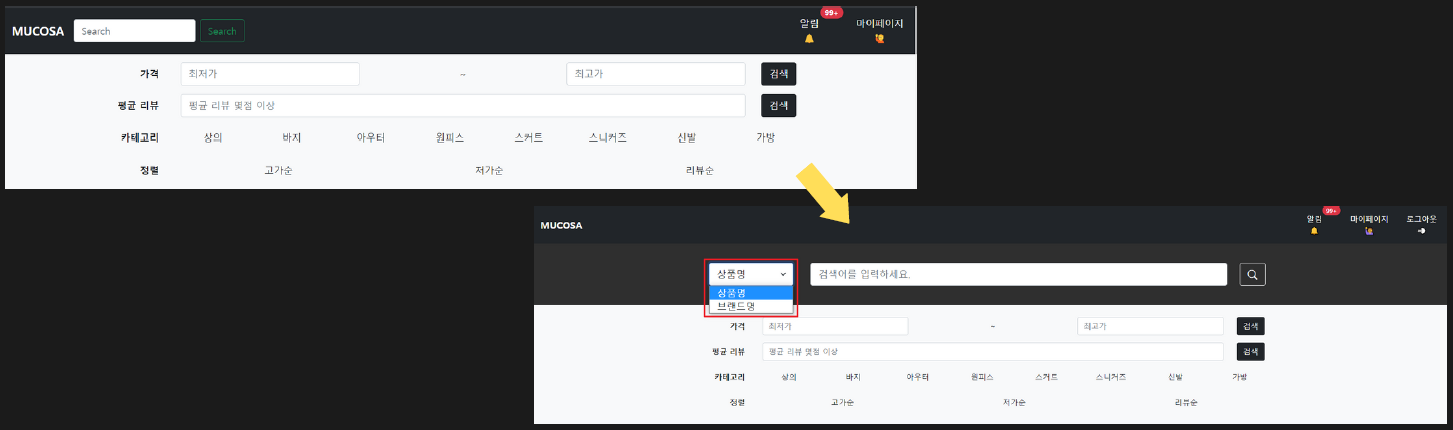
7. 검색 로직 변경
- 적용 계기
- Full-Text Index 방식을 시도하면서 Join에 의해 성능 저하가 많이 된다는 것을 인지했다.
- 👉🏻 상품명과 브랜드명을 동시에 검색할 수 있는 로직상 더 이상 Join을 줄일 수 없어 Search Type을 지정해 검색하는 로직을 반영하여 Join을 줄이고자 했다.
- 결과 분석
- 개선된 부분
- 검색 기능 성능이 최대 308%까지 개선되었다.
- 👉🏻 첫페이지의 경우 상품명 검색, 브랜드명 검색 모두 1초 이내로 목표 달성했다.
- 👉🏻 브랜드명 검색의 경우 마지막페이지까지 1초 이내로 목표 달성했다.
- 개선된 부분
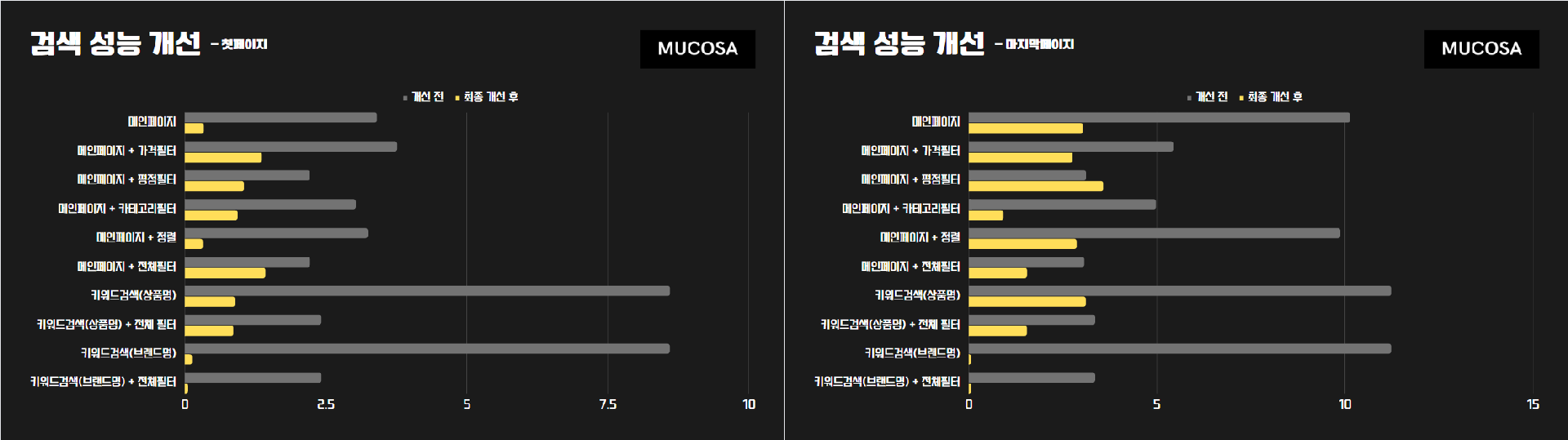
테스트 결과
- 자세한 테스트 결과는 아래 구글 Docs에 저장했다.
- 테스트의 정확성을 높이기 위해 No Cache를 적용했고 10번씩 쿼리를 실행해서 평균값을 냈다.
- https://docs.google.com/spreadsheets/d/1TI6gnlM-oUQtTpSN-fTS1uW9YMFFbqm6MCS30mMAXBU/edit?usp=sharing
회고
- 실전 프로젝트를 하기 전에는 이러한 대량의 데이터 환경에서의 성능을 고려하지 않았다. 채용공고를 들여다보니 대용량 트래픽에서의 경험을 중요시하다는 것을 알 수 있어서 이번 프로젝트에서도 중요하게 다뤘다.
- 검색 성능 개선을 하면서 다른 서비스에서는 어떻게 진행하는지 살펴봤다. 확실히 무한스크롤을 통해 로딩하는 서비스가 많았다. 가장 인상적이었던 서비스는 네이버 쇼핑이다. 정말 대량의 데이터가 있었는데 MUCOSA처럼 페이징을 사용했다. 차이점은 1페이지 20개씩~80개씩 보여주는데 1페이지 안에서는 무한스크롤로 되고 무거운 이미지 데이터들은 따로 불러오는듯 했다.
- 아직 백엔드 개발자로써 갈길이 멀다고 생각한다. 그리고 공부를 하면 할수록 CS전공 지식이 많이 필요하구나 뼈저리게 느끼게 되었다. 그래서 비록 비전공자이지만 틈틈이 CS전공 지식을 쌓아야겠다고 생각했다.

어떠한 가치를 창출할 수 있을까를 고민하는 개발자. 주로 Spring으로 개발해요.