
SELECT
- 테이블에서 데이터를 조회
문법
SELECT 컬럼1, 컬럼2
[FROM 테이블명]
[GROUP BY 컬럼명]
[ORDER BY 컬럼명 [ASC | DESC]
[LIMIT offset, 조회 할 행의 수] // offset 시작 점
[WHERE 대상컬럼=대상컬럼값]예제
SELECT * FROM student; // student 전체 조회
SELECT name, birthday FROM student; // student 테이블에서 name과 birthday를 조회
SELECT * FROM student WHERE sex='male' AND sex='female'; // student 테이블에서 sex가 'male'이고 'female'인 전체 데이터 조회
SELECT * FROM student WHERE sex='male' LIMIT 2, 1; // student 테이블에서 sex가 'male'인 데이터를 2번째 부터 1개를 조회GROUP BY
- 특정 컬럼을 기준으로 데이터 그룹핑
문법
SELECT * FROM 테이블명 GROUP BY 그룹핑 할 기준 컬럼명예제
SELECT sex FROM student group by sex; // student 테이블에서 어떤 성별로 구성이 되어 있는 지 추출
SELECT sex, sum(distance), avg(distance) FROM student GROUP BY sex; // 각 성별의 거리의 총합과 평균을 추출ORDER BY
- 지정된 칼럼을 기준으로 행을 정렬
문법
SELECT 컬럼명 FROM 테이블명 ORDER BY 정렬의 기준으로 사용할 컬럼 [ASC | DESC]예제
SELECT * FROM student ORDER BY distance DESC, address ASC;
// student 테이블에서 distance 기준으로 내림차순 정렬 후 동일한 distance 내에서 address를 기준으로 올림차순 정렬index
- 조회할 때 원하는 행을 빠르게 찾을 수 있게 준비해 둔 데이터
- 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료 구조
인덱스란? - 망나니개발자
종류
- primary : 중복되지 않는 유일한 키
- normal : 중복을 허용하는 인덱스
- unique : 중복을 허용하지 않는 유일한 키
- foreign : 다른 테이블과 관계성을 부여하는 키
- full text : 자연어 검색, myisam에서만 지원
primary key
- 테이블 전체를 통틀어 중복되지 않는 값을 지정해야 함
- WHERE문을 이용해서 데이터 조회 시 가장 빠르게 조회 가능
- 테이블 마다 딱 하나의 primary key를 가질 수 있다
CREATE TABLE `student` (
`id` tinyint(4) NOT NULL AUTO_INCREMENT,
...중략
PRIMIARY KEY (`id`) // 컬럼명이 id임 컬럼을 primary로 지정
...) ENGINE=MyISAM AUTO_INCREMENT=9 DEFAULT CHARSET=utf8unique key
- 테이블 전체를 통틀ㄹ어서 중복되지 않는 값을 지정
- 빠르게 데이터 조회 가능
- 여러 개의 unique key 지정 가능
CREATE TABLE `student` (
`id` tinyint(4) NOT NULL AUTO_INCREMENT,
...중략
UNIQUE KEY `idx_number` (`number) USING BTREE,
// `idx_number : unique key 이름 정의
// (`number`) : unique key 대상
...) ENGINE=MyISAM AUTO_INCREMENT=9 DEFAULT CHARSET=utf8normal key
- 중복 허용
- primary, unique보다 느림
- 여러 개의 키를 지정
CREATE TABLE `student` (
`id` tinyint(4) NOT NULL AUTO_INCREMENT,
...중략
KEY `idx_department` (`department`), // department 를 idx_department로 키 지정
...) ENGINE=MyISAM AUTO_INCREMENT=9 DEFAULT CHARSET=utf8Full text
- mysql의 기본설정이 4로 되어 있기 때문에 최소 4글자 이상을 입력하거나 이 값을 조정해야 함
- mysql은 전문 검색 엔진이 아니므로 한글 검색이 잘 안된다
- 스토리지 엔진 중에서 myisam에서만 사용 가능
SELECT introduction, MATCH(introduction) AGIAINST('영문과에') FROM student MATCH (introduction) AGAINST('영문과에');중복 키
- 하나의 키에 여러 개의 컬럼을 포함
- 인덱스의 한 형태가 아닌 스타일
CREATE TABLE `student` (
`id` tinyint(4) NOT NULL AUTO_INCREMENT,
...중략
KEY `idx_department_name` (`department`,`address`), // department, address 를 idx_department_name로 키 지정
...) ENGINE=MyISAM AUTO_INCREMENT=9 DEFAULT CHARSET=utf8인덱스의 정의 방법
- 검색이 빈번하게 발생하는 경우와 같이 자주 조회되는 컬럼에 적용
- 조회 시 오랜 시간을 소모하는 컬럼에 적용
- url데이터 처럼 데이터가 긴 경우 인덱스를 사용하지 않는다
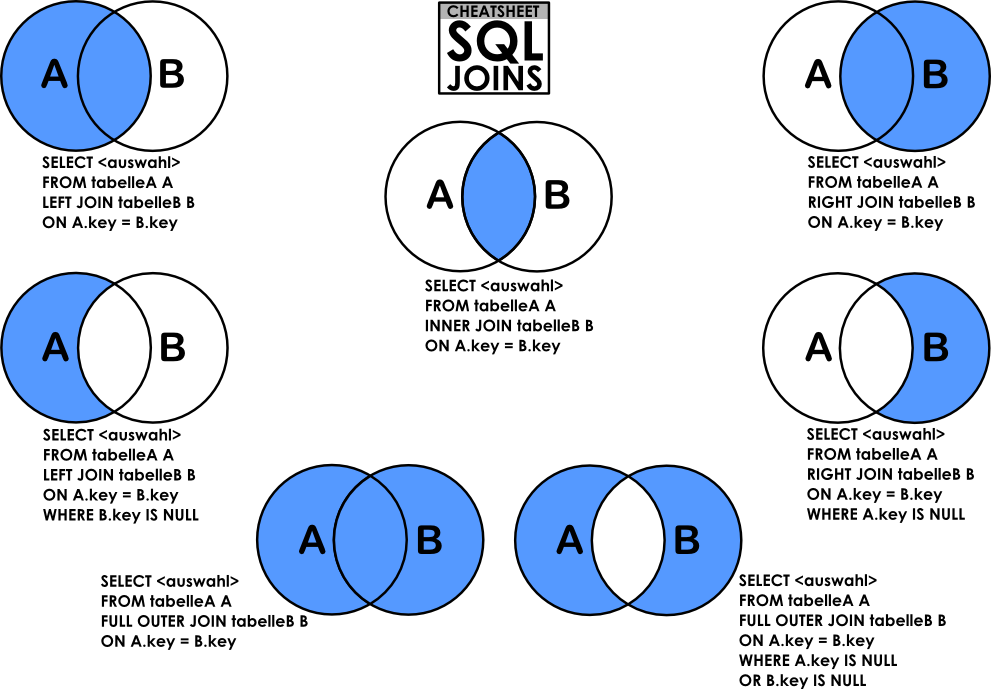
Join
- 테이블간의 관계성에 따라서 복수의 테이블을 결합하여 하나의 테이블인 것처럼 결과를 출력
- 데이터의 규모가 커지면서 하나의 테이블로 정보를 수용하기 어려워지면 테이블을 분할하여 테이블 간의 관계성 부여
Join의 종류
OUTER JOIN
- 매칭되는 컬럼이 없어도 결과를 반환
- 매칭되는 컬럼이 없는 경우 NULL로 표시
- LEFT JOIN과 RIGHT JOIN이 있다
INNER JOIN
- 매칭되는 컬럼에 대해서만 결과를 반환
예제
// student table 생성
CREATE TABLE `student` (
`id` tinyint(4) NOT NULL,
`name` char(4) NOT NULL,
`sex` enum('남자','여자') NOT NULL,
`location_id` tinyint(4) NOT NULL,
`birthday` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;// location table 생성
CREATE TABLE `location` (
`id` tinyint UNSIGNED NOT NULL AUTO_INCREMENT ,
`name` varchar(20) NOT NULL ,
`distance` tinyint UNSIGNED NOT NULL ,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;;SELECT s.name, s.location_id, l.name AS address, l.distance FROM student AS s LEFT JOIN AS l ON s.location_id = l.id;설명
- student AS s :
- [tableName] AS [t] 형태로 사용
- student 테이블의 alias는 s
- s.name = student.name / s.location_id = student.location_id
- query를 간결하게 짜기 위해 사용
- LEFT JOIN
- [table name1] LEFT JOIN [table name2]
- table name1 에 table name2의 데이터를 join
- ON
- join 할 경우 조건 부여
- ON s.location_id = l.id
: student의 location_id는 location의 id와 같다
: s.location_id의 column값에 해당하는 location 테이블의 column을 결과에 붙여서 출력
join의 종류에 따른 결과

늦깎이 프론트 개발자