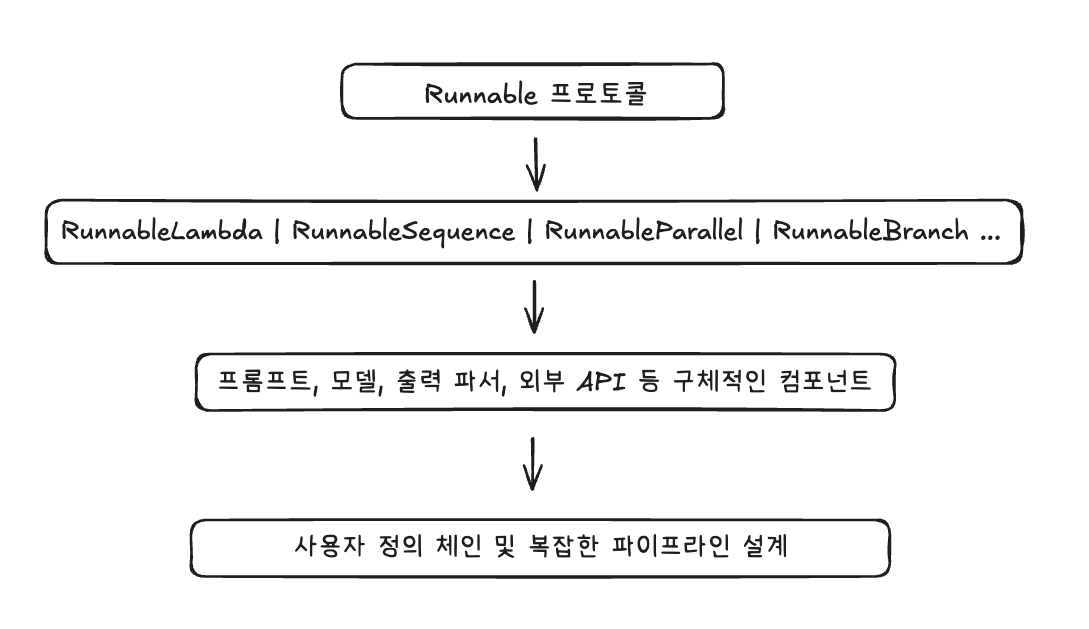
지난 글에서 LCEL이 뭔지, 그리고 왜 중요한지 개념적으로 정리해보았습니다. 간단히 복습하면 LCEL은 위 그림처럼 Runnable 단위를 쌓아올려서 최종적으로 체인이나 파이프라인을 만드는 구조입니다.
이번 포스팅에서는 이 구조를 실제 코드로 구현해보며 RAG 파이프라인 안에서 검색, 채팅, 메모리, 비동기 실행까지 직접 확인해보겠습니다.
실습 목표
이번 실습의 목표는 LCEL의 다양한 실행 방식과 블록들을 직접 체험하는 것입니다.
구체적으로는 다음을 확인해볼 것입니다.
1. 검색 모드: 벡터DB에서 관련 문서 찾기
2. 채팅 모드(Streaming): 답변을 토큰 단위로 스트리밍 출력
3. 메모리 적용: RunnableWithMessageHistory를 활용하여 대화 맥락 유지
4. 배치 처리: 여러 질문을 한 번에 처리하는 batch/abatch 실행
5. 비동기 실행: ainvoke/astream으로 동시에 요청 처리
정리하면 "검색 → 답변 → 맥락 유지 → 병렬/비동기 처리라는 흐름을 하나의 파이프라인에서 확인하는 것"이 핵심 목표입니다.
코드 구조 요약
이번 실습 코드는 기능별로 모듈을 나누어 구성했습니다.
lcel_pipeline/
├── config.py # 설정 및 상수
├── models.py # 데이터 모델(KeywordSection 등)
├── document_processor.py # 문서 로드 & 섹션/청크 분리
├── vector_store_manager.py # 벡터스토어 구축 및 로드
├── rag_chain_builder.py # LCEL 기반 RAG 체인
├── chat_history_manager.py # 대화 히스토리 관리 (RunnableWithMessageHistory)
├── main.py # RAGApplication (검색/채팅/비동기/배치 실행)
│
├── run.py # 기본 실행 스크립트
├── interactive_chat.py # CLI 대화형 실행
│
├── finance-keywords.txt # 금융 키워드 데이터
├── nlp-keywords.txt # NLP 키워드 데이터
└── faiss_keywords/ # 실행 시 생성되는 벡터스토어 디렉토리
1. 핵심 모듈
- config.py: 모델명, 경로, 검색 파라미터 등 공통 설정
- models.py: 데이터 모델 정의 (KeywordSection 등)
- document_processor.py: 문서 로드 및 섹션/청크 분리
- vector_store_manager.py: 임베딩 생성 & 벡터스토어(FAISS) 관리
- rag_chain_builder.py: LCEL 기반 RAG 체인 (Branch, Memory, Stream 포함)
- chat_history_manager.py: 대화 히스토리 관리 (RunnableWithMessageHistory)
- main.py: RAGApplication 클래스 → 검색, 채팅, 비동기, 배치 실행 총괄
2. 실행 스크립트
- run.py: 기본 실행 스크립트
- interactive_chat.py: CLI 기반 대화형 실행 (검색/채팅 모드 선택)
3. 데이터 파일
- finance-keywords.txt: 금융 키워드 데이터
- nlp-keywords.txt: NLP 키워드 데이터
- faiss_keywords/: 실행 시 자동 생성되는 벡터스토어 디렉토리
- index.faiss / index.pkl
데이터 플로우
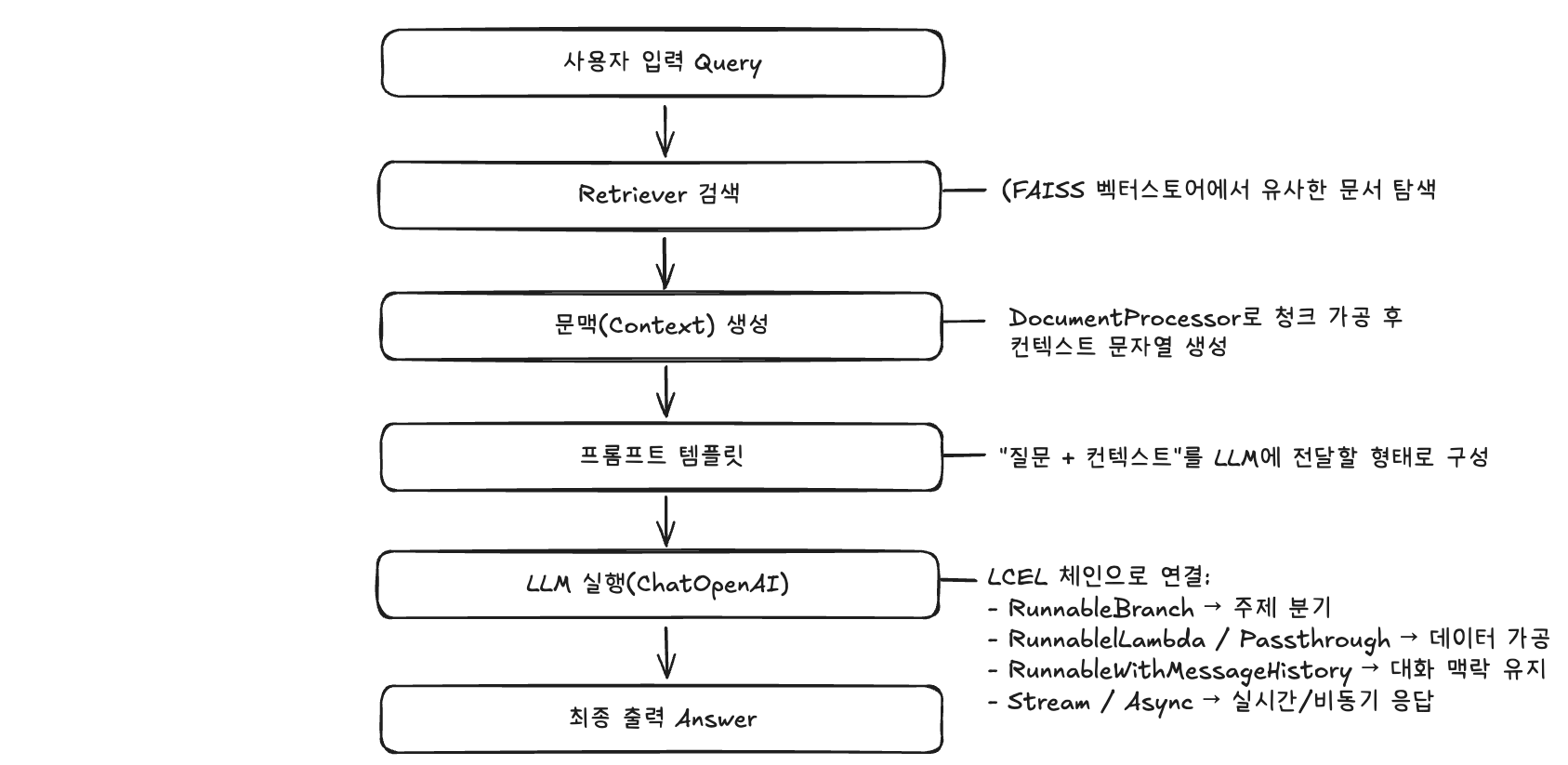
파이프라인 구축
앱 초기화
아래 함수 하나로 문서 로드 → 청크 분할 → 벡터스토어 구축(FAISS) → retriever 생성 → RAG체인 연결 → 메모리까지 한 번에 준비됩니다.
즉, 질문을 던지면 바로 검색과 답변이 가능하도록 RAG 파이프라인 전체를 세팅하는 단계입니다.
def initialize(self) -> None:
print("문서를 로드하는 중...")
docs = DocumentProcessor.load_documents(FILES)
if not docs:
raise ValueError("문서를 찾지 못했거나 섹션이 비어 있습니다.")
print("문서를 청크로 분할하는 중...")
split_docs = DocumentProcessor.split_long_docs(docs)
print("벡터 스토어를 구축하는 중...")
vs = VectorStoreManager.build_and_save_vectorstore(split_docs)
self.retriever = vs.as_retriever(search_kwargs={"k": DEFAULT_RETRIEVER_K})
print("RAG 체인을 구축하는 중...")
rag_chain = RAGChainBuilder.make_rag_chain(self.retriever)
self.chain_with_history = RunnableWithMessageHistory(
rag_chain,
self.history_manager.get_session_history,
input_messages_key="query",
history_messages_key="history",
)
print("초기화 완료!")코드 상세 설명
1. 문서 로드
def initialize(self) -> None:
print("문서를 로드하는 중...")
docs = DocumentProcessor.load_documents(FILES)
if not docs:
raise ValueError("문서를 찾지 못했거나 섹션이 비어 있습니다.")텍스트 파일(finance-keywords.txt, nlp-keywords.txt)을 읽어 Document객체로 변환합니다. 만약 파일이 비어있다면 에러를 발생시켜 초기화가 멈추게합니다.
2. 청크 분할
print("문서를 청크로 분할하는 중...")
split_docs = DocumentProcessor.split_long_docs(docs)이 단계에서는 문서를 그대로 쓰지 않고 길이가 너무 긴 섹션은 자동으로 잘라냅니다.
실제로는 DocumentProcessor.split_long_docs() 안에서 RecursiveCharacterTextSplitter라는 유틸을 써서, 일정한 크기(chunk_size=800) 단위로 청크를 나누고, 겹치는 부분(chunk_overlap=120)도 남겨둡니다. 이렇게 해야 LLM이 문맥을 놓치지 않고 검색 정확도가 올라갑니다.
아래는 split_long_docs 함수를 정의한 부분입니다.
# document_processor.py
@staticmethod
def split_long_docs(docs: List[Document], chunk_size: int = DEFAULT_CHUNK_SIZE,
chunk_overlap: int = DEFAULT_CHUNK_OVERLAP) -> List[Document]:
"""긴 문서들을 청크로 분할합니다.
Args:
docs: 분할할 Document 객체들의 리스트
chunk_size: 청크 크기
chunk_overlap: 청크 간 겹치는 부분의 크기
Returns:
분할된 Document 객체들의 리스트
"""
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=TEXT_SPLITTER_SEPARATORS,
)
return splitter.split_documents(docs)3. 벡터스토어 구축
print("벡터 스토어를 구축하는 중...")
vs = VectorStoreManager.build_and_save_vectorstore(split_docs)
self.retriever = vs.as_retriever(search_kwargs={"k": DEFAULT_RETRIEVER_K})이 단계에서는 잘라낸 문서 청크들을 벡터(숫자 표현)로 변환한 후, 이를 FAISS라는 벡터 데이터베이스에 저장합니다. 이 과정을 거쳐야 나중에 질문이 들어왔을 때, 관련성이 높은 문서들을 빠르게 찾아올 수 있습니다.
실제로는 VectorStoreManager.build_and_save_vectorstore()함수 안에서 다음 과정을 수행합니다.
# vector_store_manager.py
@staticmethod
def build_and_save_vectorstore(docs: List[Document], save_dir: Path = Path("./faiss_keywords")) -> FAISS:
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = FAISS.from_documents(documents=docs, embedding=embeddings)
save_dir.mkdir(parents=True, exist_ok=True)
vectorstore.save_local(str(save_dir))
return vectorstore- 임베딩: OpenAI의 "text-embedding-3-small"모델을 사용해 각 문서를 벡터로 변환합니다.
- FAISS 저장: 변환된 벡터들을 FAISS에 저장하고, 로컬 디렉토리(faiss_keywords/)에도 파일(index.faiss, indel.pkl)로 남깁니다.
- retriever 변환: 마지막으로
vs.as_retriever(k=DEFAULT_RETRIEVER_K)를 통해 검색 인터페이스로 바꿉니다. 이제 사용자가 질문을 던지면, retriever가 FAISS에서 관련 문서 k개를 뽑아 RAG 체인에 넘깁니다.
4. RAG 체인 구축
print("RAG 체인을 구축하는 중...")
rag_chain = RAGChainBuilder.make_rag_chain(self.retriever)이 단계에서는 검색기(retriever)를 받아서 RAG 파이프라인을 구성합니다. RAGChainBuilder.make_rag_chain()내부에서는 프롬프트 템플릿을 정의하고, LLM(ChatOpenAI)을 연결한 뒤, 검색 결과(retriever)에서 가져온 문서를 프롬프트에 포함시킵니다. 이렇게하면 "질문 → 관련 문서 검색 → 문맥을 붙여서 답변 생성"의 RAG 흐름이 완성됩니다.
5. 메모리 적용
self.chain_with_history = RunnableWithMessageHistory(
rag_chain,
self.history_manager.get_session_history,
input_messages_key="query",
history_messages_key="history",
)마지막 단계에서는 체인에 대화 히스토리(메모리)를 붙입니다.
RunnableWithMessageHistory로 감싸면, 동일한 세션(session_id) 안에서는 이전 대화 내용이 자동으로 프롬프트에 포함됩니다.input_messages_key="query": 사용자가 입력한 질문history_messages_key="history": 저장된 대화 히스토리
검색 모드
LLM을 붙이기 전에, 검색이 제대로 되는지 먼저 확인하는 모드입니다. 이 단계에서는 키워드를 입력하면, 관련 문서 섹션의 출처(source)와 제목(section_title)만 출력됩니다.
RAG를 튜닝할 때 첫번째 체크포인트입니다. 검색이 잘 안될 경우 답변 품질이 떨어지기 때문에 반드시 확인해야합니다.
def run_search(self, query: str) -> None:
items = self.retriever.invoke(query)
print("\n[Search Results]")
for d in items:
print("-", d.metadata.get("source"), d.metadata.get("section_title"))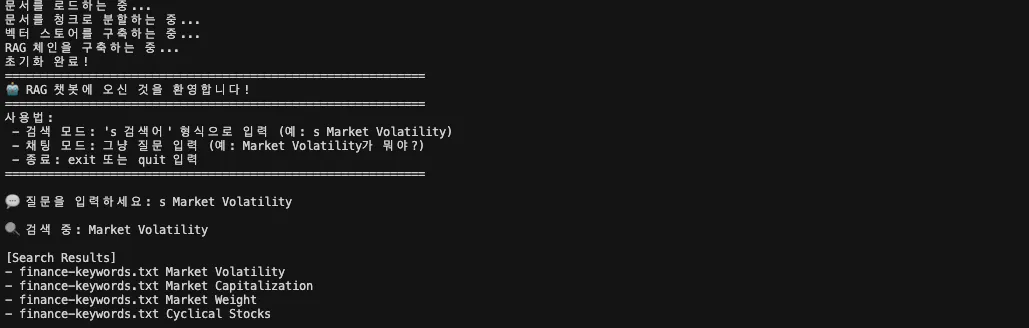
채팅 모드(동기 스트리밍)
채팅모드에서는 stream()을 사용해 답변이 토큰 단위로 출력됩니다. 기다리지 않고 첫 토큰부터 바로 보여주기때문에 실시간 채팅 환경을 제공합니다.
def run_chat(self, query: str, session_id: str = DEFAULT_SESSION_ID) -> None:
print("\n[Answer Streaming]")
print("=" * 50)
response_chunks = []
for chunk in self.chain_with_history.stream(
{"query": query},
config={"configurable": {"session_id": session_id}}
):
print(chunk, end="", flush=True)
response_chunks.append(chunk)
print("\n" + "=" * 50)
if not response_chunks:
print("❌ 응답을 생성할 수 없습니다.")
else:
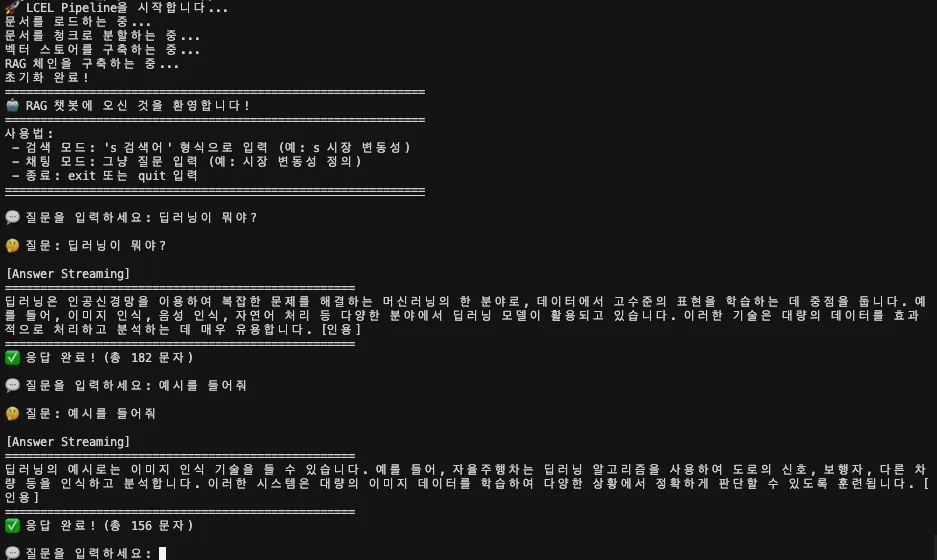
print(f"✅ 응답 완료! (총 {len(''.join(response_chunks))} 문자)")예를 들어, "딥러닝이 뭐야?"라고 물으면 한 글자씩 쌓이면서 답변이 완성됩니다.

코드 추가 설명
1. 함수 진입
def run_chat(self, query: str, session_id: str = DEFAULT_SESSION_ID) -> None:인자로 query(사용자 질문)와 session_id(대화 세션 ID)를 받습니다. 세션 ID는 RunnableWithMessageHistory와 연결되어 있어서, 같은 세션 안에서는 대화 히스토리가 이어집니다. (여기서 히스토리 관리는 chat_history_manager.py의 get_session_history()함수가 담당합니다.)
2. 스트리밍 출력 준비
response_chunks = []
for chunk in self.chain_with_history.stream(
{"query": query},
config={"configurable": {"session_id": session_id}}
):핵심은 self.chain_with_history.stream(...)입니다. self.chain_with_history는 initialize() 단계에서 만들어지는데, 사실은 이렇게 구성돼 있어요.
self.chain_with_history = RunnableWithMessageHistory(
rag_chain, # ← rag_chain은 rag_chain_builder.py에서 생성
self.history_manager.get_session_history,
input_messages_key="query",
history_messages_key="history",
)즉 self.chain_with_history = RAG 체인 + 메모리입니다.
- RAG 체인은 rag_chain_builder.py의
make_rag_chain()에서 생성 - 메모리는 chat_history_manager.py의
get_session_history()로 관리 stream()메서드는 답변을 한 번에 기다리지 않고, 토큰 단위로 잘라서 실시간으로 전달해줍니다.
3. 출력 처리
print(chunk, end="", flush=True)
response_chunks.append(chunk)각 토큰(chunk)을 바로 출력(print)하면서, 동시에 리스트에 저장합니다. flush=True옵션 덕분에 터미널에 바로 찍히고, 버퍼에 쌓이지 않습니다. 이렇게 모아둔 response_chunks는 마지막에 답변 전체를 합칠 때 사용됩니다.
4. 최종 결과 출력
if not response_chunks:
print("❌ 응답을 생성할 수 없습니다.")
else:
print(f"✅ 응답 완료! (총 {len(''.join(response_chunks))} 문자)")만약 스트리밍 도중 아무 토큰도 못 받으면 에러 메시지를 출력합니다. 정상적으로 답변이 생성되면 토큰을 전부 합쳐서 길이(문자 수)를 계산해 보여줍니다.
메모리 적용
(별도 함수는 없고, 위 run_chat/run_chatasync에서 session_id로 동작합니다.)
for chunk in self.chain_with_history.stream(
{"query": query},
config={"configurable": {"session_id": session_id}}
):
...같은 세션(session_id)에서는 이전 대화를 기억합니다. 예를 들어, 먼저 "딥러닝이 뭐야?"라고 물은 뒤에 "예시를 들어줘"라고 하면 모델이 앞 대화의 맥락을 기억하고 이어서 대답합니다. 이것은 RunnableWithMessageHistory덕분에 가능한 기능입니다.
session_id는 사실상 “방 번호” 같은 역할을 합니다. 같은 방에서는 이전 대화가 그대로 이어지고, 새로운 session_id로 실행하면 완전히 새로운 대화 세션이 시작됩니다.
배치 처리
def run_batch(self, queries, session_id: str = DEFAULT_SESSION_ID):
print("\n[Batch Processing]")
results = self.chain_with_history.batch(
[{"query": q} for q in queries],
config={"configurable": {"session_id": session_id}}
)
for idx, (q, res) in enumerate(zip(queries, results)):
print(f"\n[Query {idx+1}] {q}\n[Answer]")
print(res)batch()를 사용하면 여러 질문을 한 번에 처리할 수 있습니다. 예를 들어, ["시장 변동성 정의", "NLP 토큰화", "딥러닝이 뭐야?"]를 입력하면 각각의 답변이 순서대로 출력됩니다. 그리고 내부적으로 LCEL은 병렬 최적화를 지원하기 때문에, 순차 실행보다 빠르게 결과를 얻을 수 있습니다. 출력도 [Query 1], [Query 2]처럼 깔끔하게 정리돼 나오기 때문에 부하 테스트나 대량 요청 시 매우 유용합니다.
실행 방법
# ====== 1. 프로젝트 디렉토리 진입 ======
cd lcel_pipeline
python
# ====== 2. 파이썬 REPL에서 실행 ======
import asyncio
from main import RAGApplication
app = RAGApplication()
app.initialize()
# 비동기 실행
asyncio.run(app.run_chat_async("딥러닝이 뭐야?"))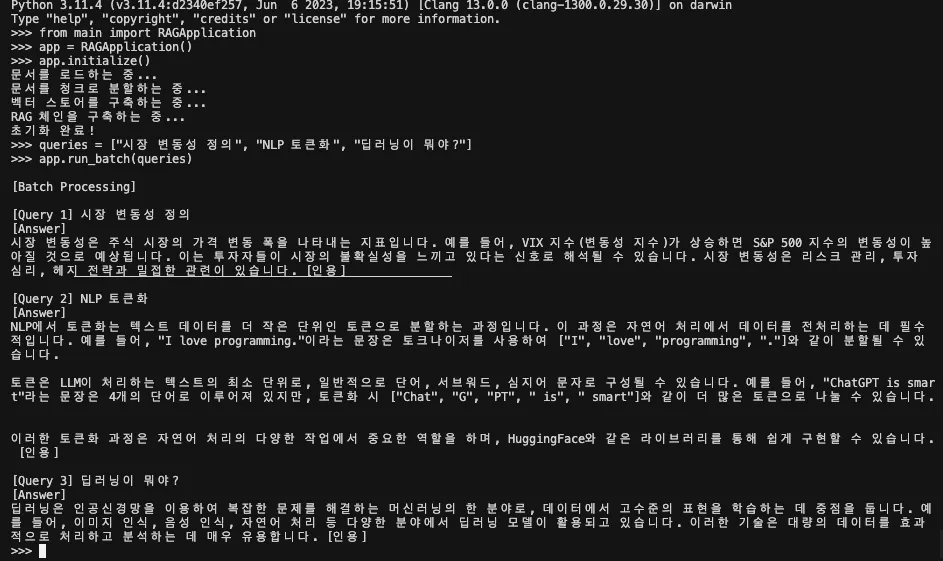
비동기 스트리밍
async def run_chat_async(self, query: str, session_id: str = DEFAULT_SESSION_ID) -> str:
print(f"\n[Async Answer Streaming] 질문: {query}")
print("=" * 50)
response = ""
async for chunk in self.chain_with_history.astream(
{"query": query},
config={"configurable": {"session_id": session_id}}
):
print(chunk, end="", flush=True)
response += chunk
print("\n" + "=" * 50)
return responseastream()은 stream()의 비동기 버전입니다. 차이점은 “여러 요청을 동시에 처리할 수 있느냐”에 있습니다.
예를 들어, 동기 stream()은 한 사용자의 요청을 처리하는 동안 다른 요청은 대기해야 하지만, astream()은 동시에 여러 사용자의 질문을 받아 각각 독립적으로 스트리밍 답변을 보낼 수 있습니다.
서버 환경에서 동시 접속자가 많은 경우, 이 비동기 방식이 필수적입니다.
실행 방법
# ====== 1. 프로젝트 디렉토리 진입 ======
cd lcel_pipeline
python
# ====== 2. 파이썬 REPL에서 실행 ======
from main import RAGApplication
app = RAGApplication()
app.initialize()
queries = ["시장 변동성 정의", "NLP 토큰화", "딥러닝이 뭐야?"]
app.run_batch(queries)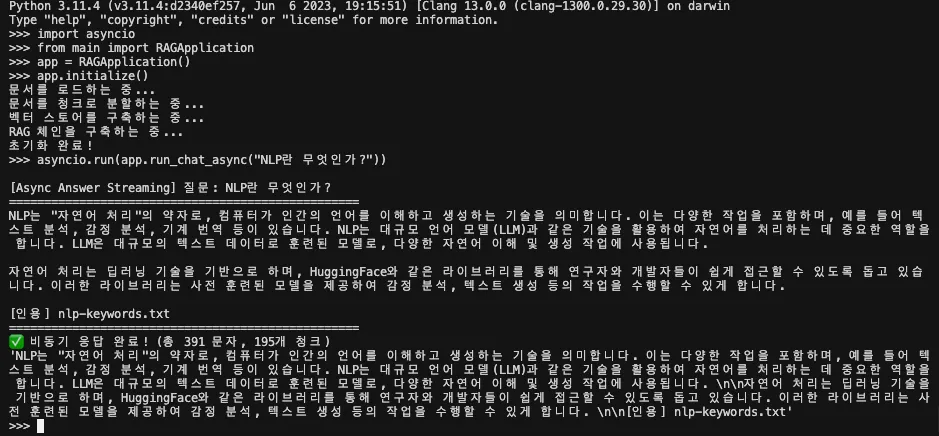
마무리
이번 실습에서는 LCEL의 다양한 실행 방식(stream, astream, batch, branch, memory)을 실제 코드에 적용해보면서 RAG 파이프라인을 확장해보았습니다.
검색만 검증할 수 있는 검증 모드, 토큰 단위로 답변을 보여주는 스트리밍, 맥락을 이어가는 메모리, 여러 질문을 동시에 처리하는 배치, 서버 환경에서 유용한 비동기 처리까지 동시에 확인할 수 있었습니다.
처음에는 복잡해보였지만, 결국 LCEL은 각 단계를 Runnable블록으로 나누고 파이프(|)로 연결한다라는 단순한 원리에 기반하는 것을 깨달았습니다.
참고자료
