Apache Hudi(Hadoop Upserts Deletes Incrementals)
Apache Hudi는 HDFS 또는Cloud Storage 기반으로 대량의 분석데이터를 저장하고, 관리할수 있는 스토리지이다.
Apache Hudi는 스트림을 통해서 실시간 데이터를 가져올수도 있고, 전통적인 batch 프로세싱으로 데이터를 저장할 수도 있다.
기존 HDFS은 RDBMS와는 다르게 적재되어있는 데이터를 업데이트해서 사용하는데 적합하지 않다. 이러한 불편함을 Apache Hudi가 해소해줄 수 있을 것 같다.
동작 방식
데이터를 디렉토리 구조로 파티셔닝하여 지정된 basepath에 저장. (Hive 테이블과 유사)
레코드들이 여러개의 파티션내에 여러개의 parquet 파일로 분산되어 저장된다.
데이터에 변경이 발생하면 변경사항이 반영된 새로운 parquet 파일을 생성하며 파일에 timestamp를 기록해둔다.
(delta가 아니라 매번 전체 내용을 가지는 파일을 생성한다)
파티션의 데이터가 변경될 때마다 parquet 파일 개수가 늘어나게 되고,
데이터 조회 시 timestamp를 이용해서 가장 최근의 파일 혹은 특정 시점의 파일을 선택해서 최신/이전 데이터를 가져온다.
테이블 종류
CopyOnWrite , MergeOnRead 2가지 종류로 분류된다.
간단한게 데이터 변경이 적고, 조회가많은 성격을 가진 테이블에 경우 CopyOnWrite를 사용하는게 유리하고, 데이터 변경이 잦고, 조회가 적은 테이블 성격을 가진 테이블은 MergeOnRead를 사용하는게 좋다.
CopyOnWrite
- 기본 유형으로 데이터 commit할 때마다 그 시점에 변경 사항 처리
- commit 마다 새로운 버전의 파일을 계속해서 생성하는 방식
- 데이터가 자주 변경되지 않지만 조회가 많은 경우 유리
- 열지향 파일 형태(Parquet)로 데이터 저장
Copy On Write 동작 방식
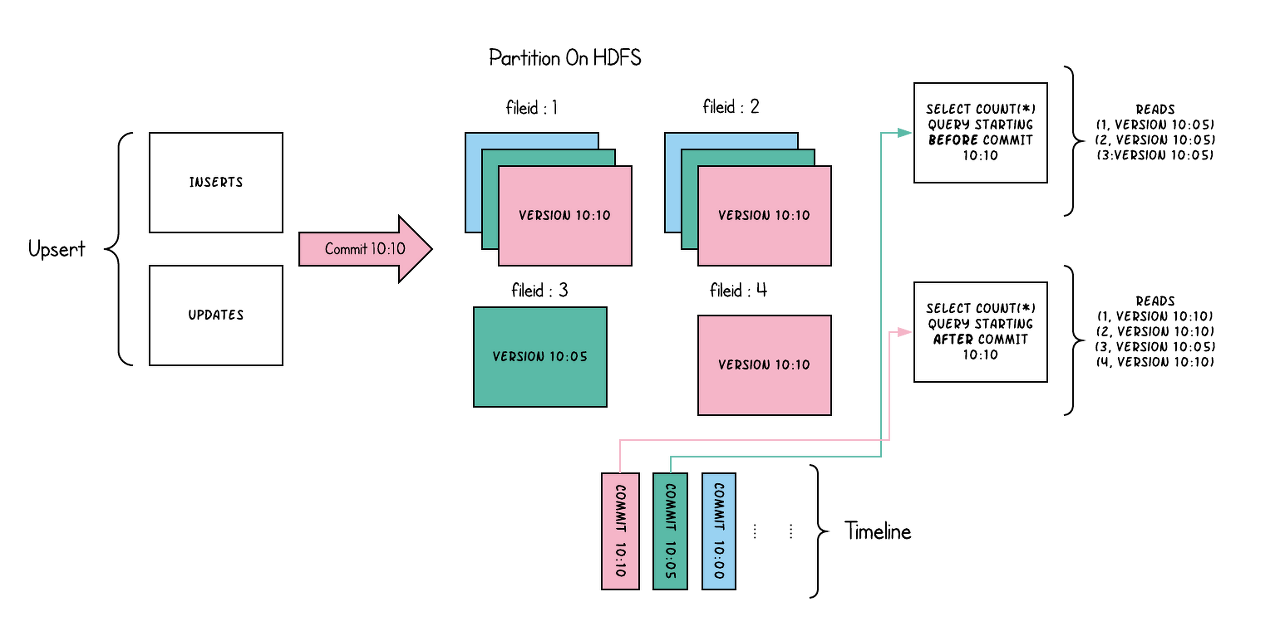
한 파티션 내에 데이터가 4개 파일(fileid 1, 2, 3, 4)로 나뉘어 저장되어있다.
한 파티션 내의 데이터가 무조건 하나의 파일로 되어있지 않아서 index를 통해서 변경 레코드가 속한 파일을 찾아 그 파일만 새로 파일을 생성하는 방식인 것 같다. (파티션 내 파일 갯수는 데이터 크기와 옵션 값을 통해 결정되는 것 같다)
여기서 10:10 이라고 되어있는 것은 10시 10분을 의미한다.
10:10 커밋 이전의 데이터를 조회한다면 file 1의 10:05 데이터, file2의 10:05 데이터, file3의 10:05 데이터를 조회하게 된다.
(file4는 10:10 이전 데이터가 없으므로 스킵)
10:10 커밋 이후의 데이터를 조회한다면 file 1의 10:10 데이터, file2의 10:10 데이터, file3의 10:05 데이터, file4의 10:10의 데이터를 조회하게 된다.
(file3은 10:05 이후 변하지 않았기 때문에 10:10 이후에도 10:05 시점 데이터와 같다)
MergeOnRead
- commit 시는 delta 로그에만 기록하고 조회 시 변경 사항을 merge하여 보여준다. (신규 parquet 파일이 새로 생성 X)
- 데이터 변경이 잦고, 조회가 적은 성경 테이블에 유리
- Parquet 파일(데이터)과 Avro 파일(delta 로그) 조합으로 데이터 저장
- 변경사항을 반영한 parquet 파일을 새로 생성하는 작업은 compaction이라고 하며, 주기(Default : 1시간), commit 개수(Default : 5개)에 따라 비동기로 처리된다.
쿼리 종류
Snapshot query
특정 시점의 스냅샷 데이터 조회 (최신 데이터도 조회 가능함)
Incremental query
특정 기간 동안 추가/수정된 데이터 조회 (그 기간 내 최신 내용으로 조회됨)
Read Optimized query
Merge On Read 방식에서 사용되며, Snapshot query와 유사하지만 아직 compaction되지 않은 데이터는 제외하고 조회하여 성능을 높인다
Hive, Spark SQL, PrestoDB, Impala 등을 이용해서도 데이터를 읽을 수 있는데
읽기 위해서는 쿼리 엔진이 Hudi 포맷을 처리할 수 있도록 Hudi 라이브러리를 제공해야 한다 (jar 파일 제공됨)
참조 : https://sheerheart.tistory.com/entry/Apache-Hudi-%EC%86%8C%EA%B0%9C-HDFS-upsertdelete
