참조 :
https://github.com/WeareSoft/tech-interview
- 프로세스(Process) 란
사전적 의미: 컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램
메모리에 올라와 실행되고 있는 프로그램의 인스턴스(독립적인 개체)
운영체제로부터 시스템 자원을 할당받는 작업의 단위
즉, 동적인 개념으로는 실행된 프로그램을 의미한다.
할당받는 시스템 자원의 예
CPU 시간
운영되기 위해 필요한 주소 공간
Code, Data, Stack, Heap의 구조로 되어 있는 독립된 메모리 영역
특징
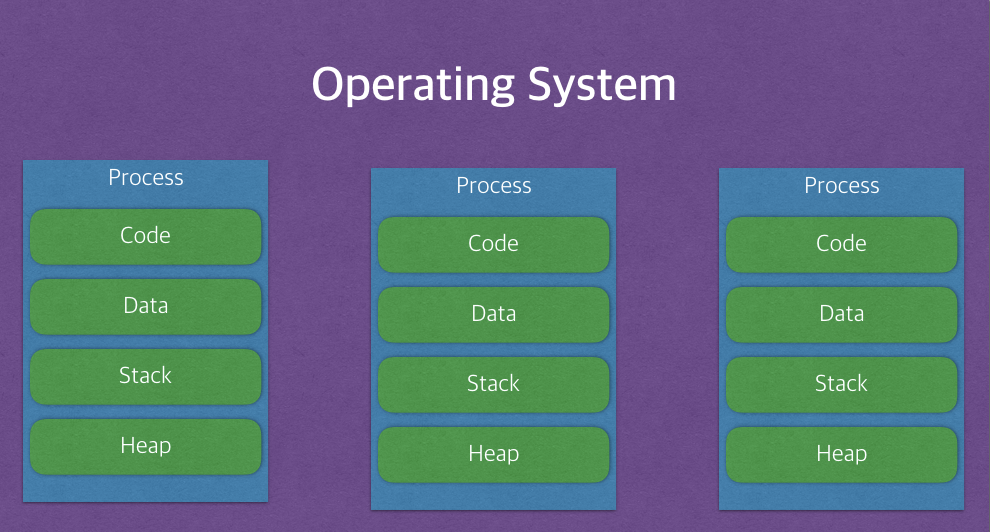
프로세스는 각각 독립된 메모리 영역(Code, Data, Stack, Heap의 구조)을 할당받는다.
기본적으로 프로세스당 최소 1개의 스레드(메인 스레드)를 가지고 있다.
각 프로세스는 별도의 주소 공간에서 실행되며, 한 프로세스는 다른 프로세스의 변수나 자료구조에 접근할 수 없다.
* 한 프로세스가 다른 프로세스의 자원에 접근하려면 프로세스 간의 통신(IPC, inter-process communication)을 사용해야 한다. (Ex. 파이프, 파일, 소켓 등을 이용한 통신 방법 이용)
- 스레드(Thread) 란
사전적 의미: 프로세스 내에서 실행되는 여러 흐름의 단위
프로세스의 특정한 수행 경로
프로세스가 할당받은 자원을 이용하는 실행의 단위
특징
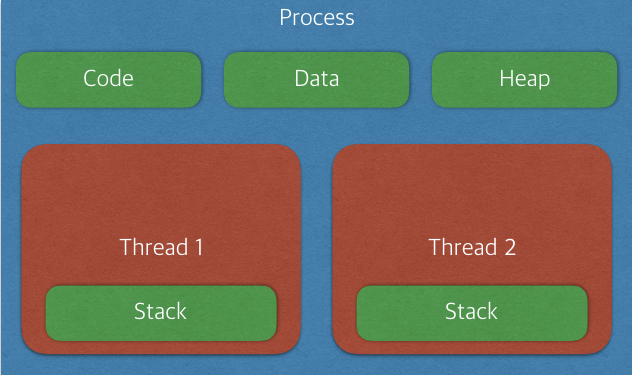
스레드는 프로세스 내에서 각각 Stack만 따로 할당받고 Code, Data, Heap 영역은 공유한다.
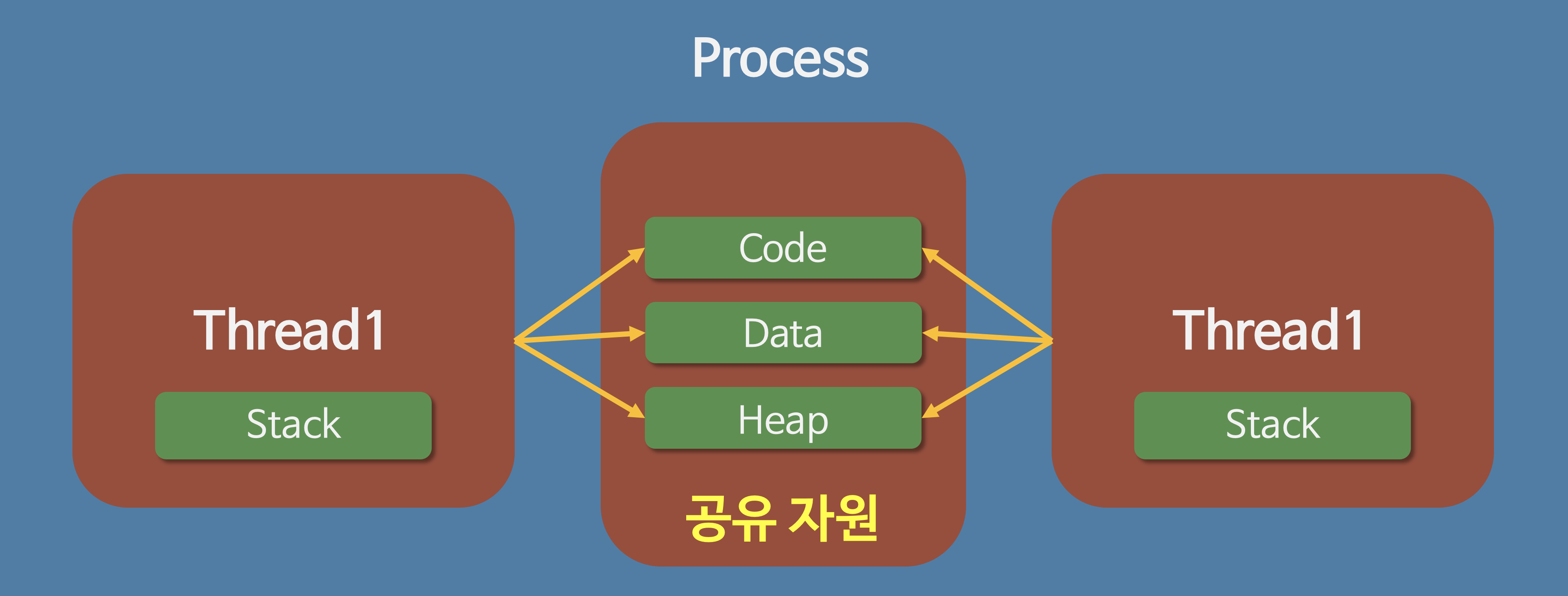
스레드는 한 프로세스 내에서 동작되는 여러 실행의 흐름으로, 프로세스 내의 주소 공간이나 자원들(힙 공간 등)을 같은 프로세스 내에 스레드끼리 공유하면서 실행된다.
같은 프로세스 안에 있는 여러 스레드들은 같은 힙 공간을 공유한다. 반면에 프로세스는 다른 프로세스의 메모리에 직접 접근할 수 없다.
각각의 스레드는 별도의 레지스터와 스택을 갖고 있지만, 힙 메모리는 서로 읽고 쓸 수 있다.
* 한 스레드가 프로세스 자원을 변경하면, 다른 이웃 스레드(sibling thread)도 그 변경 결과를 즉시 볼 수 있다. - 자바 스레드(Java Thread) 란
- 일반 스레드와 거의 차이가 없으며, JVM가 운영체제의 역할을 한다.
- 자바에는 프로세스가 존재하지 않고 스레드만 존재하며, 자바 스레드는 JVM에 의해 스케줄되는 실행 단위 코드 블록이다.
- 자바에서 스레드 스케줄링은 전적으로 JVM에 의해 이루어진다.
- 아래와 같은 스레드와 관련된 많은 정보들도 JVM이 관리한다.
- 스레드가 몇 개 존재하는지
- 스레드로 실행되는 프로그램 코드의 메모리 위치는 어디인지
- 스레드의 상태는 무엇인지
- 스레드 우선순위는 얼마인지
- 즉, 개발자는 자바 스레드로 작동할 스레드 코드를 작성하고, 스레드 코드가 생명을 가지고 실행을 시작하도록 JVM에 요청하는 일 뿐이다.
멀티 프로세스 대신 멀티 스레드를 사용하는 이유
- 쉽게 설명하면, 프로그램을 여러 개 키는 것보다 하나의 프로그램 안에서 여러 작업을 해결하는 것이다.
- 자원의 효율성 증대
- 멀티 프로세스로 실행되는 작업을 멀티 스레드로 실행할 경우, 프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어들어 자원을 효율적으로 관리할 수 있다.
- 프로세스 간의 Context Switching시 단순히 CPU 레지스터 교체 뿐만 아니라 RAM과 CPU 사이의 캐시 메모리에 대한 데이터까지 초기화되므로 오버헤드가 크기 때문
- 스레드는 프로세스 내의 메모리를 공유하기 때문에 독립적인 프로세스와 달리 스레드 간 데이터를 주고 받는 것이 간단해지고 시스템 자원 소모가 줄어들게 된다.
- 멀티 프로세스로 실행되는 작업을 멀티 스레드로 실행할 경우, 프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어들어 자원을 효율적으로 관리할 수 있다.
- 처리 비용 감소 및 응답 시간 단축
- 또한 프로세스 간의 통신(IPC)보다 스레드 간의 통신의 비용이 적으므로 작업들 간의 통신의 부담이 줄어든다.
- 스레드는 Stack 영역을 제외한 모든 메모리를 공유하기 때문
- 프로세스 간의 전환 속도보다 스레드 간의 전환 속도가 빠르다.
- Context Switching시 스레드는 Stack 영역만 처리하기 때문
- 또한 프로세스 간의 통신(IPC)보다 스레드 간의 통신의 비용이 적으므로 작업들 간의 통신의 부담이 줄어든다.
- 주의할 점!
- 동기화 문제
- 스레드 간의 자원 공유는 전역 변수(데이터 세그먼트)를 이용하므로 함께 상용할 때 충돌이 발생할 수 있다.
뮤텍스와 세마포어의 차이
- 뮤텍스(Mutex)
- 공유된 자원의 데이터를 여러 스레드가 접근하는 것을 막는 것
- 상호배제라고도 하며, Critical Section을 가진 스레드의 Running time이 서로 겹치지 않도록 각각 단독으로 실행하게 하는 기술이다.
- 다중 프로세스들의 공유 리소스에 대한 접근을 조율하기 위해 synchronized 또는 lock을 사용한다.
- 즉, 뮤텍스 객체를 두 스레드가 동시에 사용할 수 없다.
- 세마포어(Semaphore)
- 공유된 자원의 데이터를 여러 프로세스가 접근하는 것을 막는 것
- 리소스 상태를 나타내는 간단한 카운터로 생각할 수 있다.
- 운영체제 또는 커널의 한 지정된 저장장치 내의 값이다.
- 일반적으로 비교적 긴 시간을 확보하는 리소스에 대해 이용한다.
- 유닉스 시스템 프로그래밍에서 세마포어는 운영체제의 리소스를 경쟁적으로 사용하는 다중 프로세스에서 행동을 조정하거나 또는 동기화 시키는 기술이다.
- 공유 리소스에 접근할 수 있는 프로세스의 최대 허용치만큼 동시에 사용자가 접근하여 사용할 수 있다.
- 각 프로세스는 세마포어 값은 확인하고 변경할 수 있다.
사용 중이지 않는 자원의 경우 그 프로세스가 즉시 자원을 사용할 수 있다.
이미 다른 프로세스에 의해 사용 중이라는 사실을 알게 되면 재시도하기 전에 일정 시간을 기다려야 한다.- 세마포어를 사용하는 프로세스는 그 값을 확인하고, 자원을 사용하는 동안에는 그 값을 변경함으로써 다른 세마포어 사용자들이 기다리도록 해야한다.
- 세마포어는 이진수 (0 또는 1)를 사용하거나, 또는 추가적인 값을 가질 수도 있다.
- 차이
- 가장 큰 차이점은 관리하는 동기화 대상의 개수
- Mutex는 동기화 대상이 오직 하나뿐일 때, Semaphore는 동기화 대상이 하나 이상일 때 사용한다.
- Semaphore는 Mutex가 될 수 있지만 Mutex는 Semaphore가 될 수 없다.
- Mutex는 상태가 0, 1 두 개 뿐인 binary Semaphore
- Semaphore는 소유할 수 없는 반면, Mutex는 소유가 가능하며 소유주가 이에 대한 책임을 가진다.
- Mutex 의 경우 상태가 두개 뿐인 lock 이므로 lock 을 가질 수 있다.
- Mutex의 경우 Mutex를 소유하고 있는 스레드가 이 Mutex를 해제할 수 있다. 하지만 Semaphore의 경우 이러한 Semaphore를 소유하지 않는 스레드가 Semaphore를 해제할 수 있다.
- Semaphore는 시스템 범위에 걸쳐있고 파일시스템상의 파일 형태로 존재하는 반면 Mutex는 프로세스 범위를 가지며 프로세스가 종료될 때 자동으로 Clean up 된다.
- 가장 큰 차이점은 관리하는 동기화 대상의 개수
동기와 비동기
이 개념은 OS에서 뿐만 아니라 여러가지 분야에서도 쓰인다.
- 동기(Synchronous)란?'동기' 라고하면 다수의 개채들이 동일(일정)한 무언가를 가지는 것. 또는 무언가가 동일(일정)하게 되는 것.
- 그 무언가는 상태가 될 수 있고 행위가 될 수 있고, 시간,속도, 주기, 출현 등이 될 수 있다.
- 여기서 말하는 '동기'는 두개의 프로세스가 데이터를 주고 받을 때, 주고 받는 순서(또는 시간)가 일정하다는 것을 뜻한다. (너 한번, 나 한번)
- 비동기(Asynchronous)란?
- '동기'가 아닌 것.
- 동기식, 동기적이다.
- 어떤 작업을 요청했을 때 그 작업이 종료될 때까지 기다린 후 다음 작업을 수행한다.
- 데이터를 주고받는 '순서'가 중요할때 사용된다.
- 요청한 작업만 처리하면 되기 때문에 전체적인 수행 속도는 빠를 수 있다. (일만 하면 된다)
- 한 작업에 대한 시간이 길어질 경우, 전체 응답이 지연될 수 있다.
- 어떤 작업을 요청했을 때 그 작업이 종료될 때까지 기다린 후 다음 작업을 수행한다.
- 비동기식, 비동기적이다.
- 어떤 작업을 요청했을 때 그 작업이 종료될 때까지 기다리지 않고(작업을 위임하고), 다음 작업을 수행한다. 요청했던 작업이 끝나면 결과를 받고, 그에 따른 추가 작업이 있다면 수행한다.
- 요청 순서에 상관없이, 동시에 다수의 작업을 처리할 수 있다.
- 작업이 끝날 때 따로 이벤트를 감지하고 결과를 받아 그에 따른 추가 작업을 해줘야하기 때문에, 비교적 느릴 수 있다.
- I/O 작업이 잦고, 빠른 응답속도를 요구하는 프로그램에 적합하다.
- 어떤 작업을 요청했을 때 그 작업이 종료될 때까지 기다리지 않고(작업을 위임하고), 다음 작업을 수행한다. 요청했던 작업이 끝나면 결과를 받고, 그에 따른 추가 작업이 있다면 수행한다.
