라우팅
라우터의 핵심 기능은 패킷이 이동할 최적의 경로를 설정한 뒤 해당 경로로 패킷을 이동시키는 것이다.
이를 라우팅이라고 한다.
일반적으로 가정 환경에서는 공유기가 라우터의 역할을 대신한다.
사실 공유기는 라우터 기능뿐만 아니라 NAT, DHCP 서버 기능, 보안을 위한 방화벽 기능 등 다양한 장치의 기능이 함축된 네트워크 장비라고 볼 수 있다.
라우팅이 뭘까요?
라우터가 패킷이 이동할 최적의 경로를 설정한 뒤 해당 경로로 패킷을 이동시키는 것을 라우팅 이라고 합니다.
라우팅에는 정적 라우팅과 동적 라우팅으로 나뉠 수 있습니다.
홉
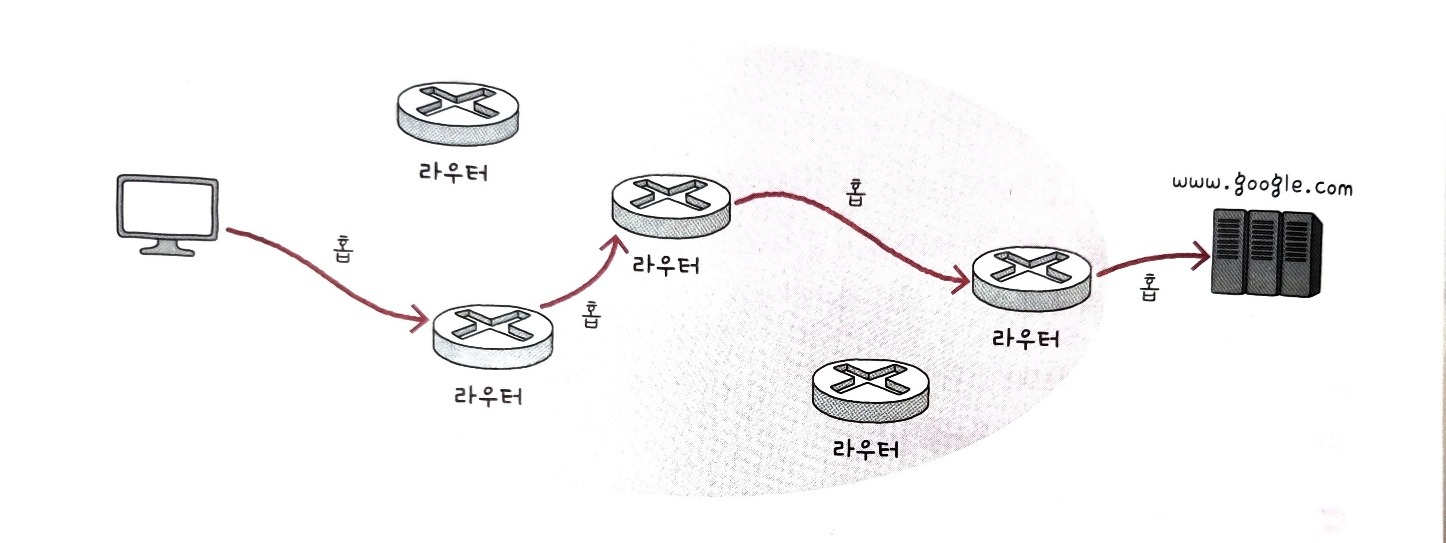
라우팅 도중 패킷이 호스트와 라우터 간에, 혹은 라우터와 라우터 간에 이동하는 하나의 과정을 홉이라고 부른다.
즉, 패킷은 '여러 홉을 거쳐' 라우팅될 수 있는 것이며, 여러 홉을 거쳐 다른 네트워크 내의 호스트로 이동할 수 있다.
라우팅 테이블
라우팅의 핵심은 라우터가 저장하고 관리하는 라우팅 테이블이다.
라우터는 라우팅 테이블을 참고하여 수신지까지의 도달 경로를 판단한다.
라우팅 테이블은 특정 수신지까지 도달하기 위한 정보를 저장하는 표이며, 핵심 정보로는 수신지 IP 주소, 서브넷 마스크, 다음 홉이 있다.
이외에도 라우팅 테이블에 명시되는 대표적인 정보는 네트워크 인터페이스와 메트릭이 있다.
라우터끼리 최단 경로에 대한 정보를 교환하여 테이블을 갱신한다.
수신지 IP 주소와 서브넷 마스크: 최종적으로 패킷을 전달할 대상을 의미한다.다음 홉: 최종 수신지까지 가기 위해 다음으로 거쳐야 할 호스트의 IP 주소나 인터페이스를 의미한다.
게이트웨이라고 명시되기도 한다.네트워크 인터페이스: 패킷을 내보낼 통로이다.메트릭: 해당 경로로 이동하는 데 드는 비용을 의미한다.
라우팅 테이블에 없는 경로로 패킷을 전송해야 할 때도 있다.
이 경우 기본적으로 패킷을 내보낼 경로를 설정하여 해당 경로로 패킷을 내보낼 수 있으며, 이 기본 경로를 디폴트 라우트라고 한다.
디폴트 라우트는 모든 IP 주소를 의미하는 0.0.0.0/0로 명시한다.
기본 게이트웨이는 호스트가 속한 네트워크 외부로 나아가기 위한 첫 번째 경로이고, 여기서 기본 게이트웨이로 나아가기 위한 경로가 디폴트 라우트인 셈이다.
네트워크 내부 호스트 A가 네트워크 외부 호스트 B에게 패킷을 전달해야 한다고 할 때, A의 라우팅 테이블에 B에 이르는 경로가 따로 없다고 하자.
A는 우선 패킷을 기본 게이트웨이에 전달해야 한다.
이를 위해 A는 라우터 주소인 기본 게이트웨이를 디폴트 라우트로 삼는다.
그럼 A는 라우팅 테이블에 따로 수신지 경로가 등록되어 있지 않은 패킷들은 기본적으로 라우터(디폴트 라우트-기본 게이트웨이)에게 전달하게 된다.
라우터에 대해 설명해주세요.
라우터는 네트워크 계층에서 동작하는 네트워크 장비입니다.
라우터는 IP 주소를 통해 IP 패킷을 서로 다른 네트워크로 전송합니다.
패킷의 최적의 경로를 결정하는 것을 라우팅이라고 하며 라우팅 테이블을 참조해서 패킷을 전송하는 것을 포워딩이라고 합니다.
L3 스위치에 대해 설명해주세요.
L3 스위치는 네트워크 계층에서 동작하는 네트워크 장비입니다.
L3 스위치는 라우터에 L2 스위치가 추가된 장비입니다.
MAC 주소 테이블과 라우팅 테이블을 조합한 정보를 FPGA라는 하드웨어에 기록하여 고속으로 패킷 전송을 할 수 있습니다.
SDN
software-defined networking
네트워크 리소스를 최적화하고 변화하는 비즈니스 요구, 애플리케이션 및 트래픽에 신속하게 네트워크를 채택하는 데 도움이 되는 네트워크 가상화 및 컨테이너화에 대한 접근 방식
라우팅 알고리즘
- 라우터별 제어
라우팅 알고리즘들이 모두 라우터 각각에서 동작하는 경우를 말한다. - 논리적 중앙 집중형 제어
논리적 중앙 집중형 컨트롤러가 포워딩 테이블을 작성하고 이를 모든 개별 라우터가 사용할 수 있도록 배포한 경우를 나타낸다.
라우터별 제어와 달리 논리적 중앙 집중형 제어는 서로 직접 상호작용하지 않으며 포워딩 테이블을 계산하는 데도 적극적으로 참여하지 않는다.
이것이 라우터별 제어와 논리적 중앙 집중형 제어의 주요 차이점이다.
라우팅 알고리즘을 분류하는 방법
- 중앙 집중형 라우팅 알고리즘
- 네트워크 전체에 대한 완전한 정보를 가지고 출발지와 목적지 사이의 최소 비용 경로를 계산한다.
- 전체 상태 정보를 갖는 알고리즘을
링크 상태 알고리즘이라고 한다.
- 분산 라우팅 알고리즘
- 최소 비용 경로의 계산이 라우터들에 의해 반복적이고 분산된 방식으로 수행된다.
- 어떤 노드도 모든 링크의 비용에 대한 완전한 정보를 갖고 있지는 않다.
- 대신, 각 노드는 자신에게 직접 연결된 링크에 대한 비용 정보만을 가지고 시작한다.
- 이후 반복된 계산과 이웃 노드와의 정보 교환을 통해 노드는 점차적으로 목적지 또는 목적지 집합까지의 최소 비용 경로를 계산한다.
분산 라우팅 알고리즘은
거리 벡터 알고리즘이라고 부르는데, 이는 각 노드가 네트워크 내 다른 모든 노드까지 비용의 추정값을 벡터 형태로 유지하기 때문이다.
- 정적 라우팅 알고리즘
- 동적 라우팅 알고리즘
- 부하에 민감한 알고리즘
현재 혼잡한 링크에 높은 비용을 부과한다면, 라우팅 알고리즘은 혼잡한 링크를 우회하는 경로를 택하는 경향을 보일 것이다.
링크 상태 라우팅 알고리즘
링크 상태 알고리즘은 각 노드가 자신과 직접 연결된 링크의 식별자와 비용 정보를 담은 링크 상태 패킷을 네트워크상의 다른 모든 노드로 브로드캐스트하게 함으로써 가능하다.
노드들의 브로드캐스트를 통해 모든 노드는 네트워크에 대한 동일하고 완벽한 관점을 갖게 된다.
각 노드는 이제 LS 알고리즘(링크 상태 알고리즘)을 이용해 다른 노드와 똑같은 최소 비용 경로 집합을 계산할 수 있다.
링크 상태 알고리즘은 최악의 경우 O(n^2)의 복잡성을 갖는다.
거리 벡터 라우팅 알고리즘
링크 상태 알고리즘이 네트워크 전체 정보를 이용하는 알고리즘인 반면에, 거리 벡터 알고리즘은 반복적으로 비동기적이며 분산적이다.
각 노드는 하나 이상의 직접 연결된 이웃으로부터 정보를 받고, 계산을 수행하며, 계산된 결과를 다시 그 이웃드에게 배포한다는 점에서 분산적이다.
이웃끼리 더 이상 정보를 교환하지 않을 때까지 프로세스가 지속된다는 점에서 반복적이다.
LS 알고리즘은 다익스트라 알고리즘을 수행하기 전에 각 노드가 네트워크에 대한 전체 지도를 먼저 얻어야 한다는 면에서 중앙 집중형 알고리즘이다.
DV 알고리즘은 분산적이고 그러한 전체 정보를 사용하지 않는다.
하나의 노드가 갖는 정보는 단지 자신에게 직접 연결된 이웃으로의 링크 비용와 그 이웃들로부터 수신하는 정보뿐이다.
각 노드는 이웃으로부터의 갱신을 기다리고, 업데이트를 수신하면 새로 거리 벡터를 계산하고, 이 새로운 거리 벡터를 이웃들에게 배포한다.
노드 x가 이웃 w에게서 새로운 거리 벡터를 수신하면, x는 w의 거리 벡터를 저장하고, 벨만-포드 식을 사용하여 자신의 거리 벡터를 갱신한다.
Dx(y) = min{c(x, v) + Dv(y)}갱신을 계속하다보면, 실제 최소 비용 경로의 비용으로 수렴하게 된다.
링크 비용 변경과 링크 고장
링크 비용이 감소할 때는 최소 비용을 계산하는 과정으로 인해 정상적으로 포워딩 테이블이 갱신된다.
하지만 링크 비용이 증가할 때 최소 비용을 계산하게 되면 라우팅 루프 문제가 발생하게 된다.
이러한 문제를 무한 계수 문제(count-to-infinity problem) 이라고 한다.
이는 링크 비용이 증가했더라도 다른 라우터에선 최소 비용을 계산할 때 증가한 비용이 최소가 되지 않기에 적용하지 않게 되어 발생하는 것이다.
이러한 문제는 포이즌 리버스 라는 방법을 사용해 방지할 수 있다.
포이즌 리버스는 한 라우터가 경로 설정을 갱신하게 되면 중간 경유지 라우터에겐 목적지까지의 비용이 무한대라고 알려 최소 비용을 다시 계산하게 하는 것이다.
하지만 이러한 포이즌 리버스 방법도 모든 무한 계수 문제를 해결할 수는 없다.
직접 이웃한 2개의 노드가 아닌 3개 이상의 노드를 포함한 루프는 이 방법으로 해결할 수 없다.
링크 상태 알고리즘 vs 거리 벡터 라우팅 알고리즘
- 메시지 복잡성
링크 상태 알고리즘에서 각 노드는 네트워크 내 각 링크 비용을 알아야 하며, 링크 비용이 변할 때마다 새로운 링크 비용이 모든 노드에게 전달되어야 한다.
거리 벡터 알고리즘에서는 매 반복마다 직접 연결된 이웃끼리 메시지를 교환한다.
링크 비용이 변하고, 이 새로운 링크 비용이 이 링크에 연결된 어떤 노드의 최소 비용 경로에 변화를 준 경우에만 DV 알고리즘은 수정된 링크 비용을 전파한다. - 수렴 속도
링크 상태 알고리즘은 브로드캐스트를 해야하므로 O(n^2) 알고리즘이며, 거리 벡터 알고리즘은 라우팅 루프로 인한 무한 계수 문제가 발생할 수 있다. - 견고성
만약 라우터가 고장나거나 오동작하거나 파손된다면 어떤 일이 발생할까?
링크 상태 알고리즘에서 경로 계산은 자신의 테이블을 만들기 위한 자신의 포워딩 테이블만 계산하기 때문에 경로 계산이 분산 수행되어 어느 정도의 견고성을 제공한다.
거리 벡터 알고리즘은 잘못된 최소 비용 경로를 일부 혹은 모든 목적지에 알릴 수 있다.
각 반복마다 한 노드의 거리 벡터 계산이 이웃에게 전달되고, 다음 반복에서 이웃의 이웃에게 간접적으로 전달된다.
이런 측면에서 거리벡터 알고리즘을 사용하는 네트워크에서 한 노드의 잘못된 계산은 전체로 확산될 수 있다.
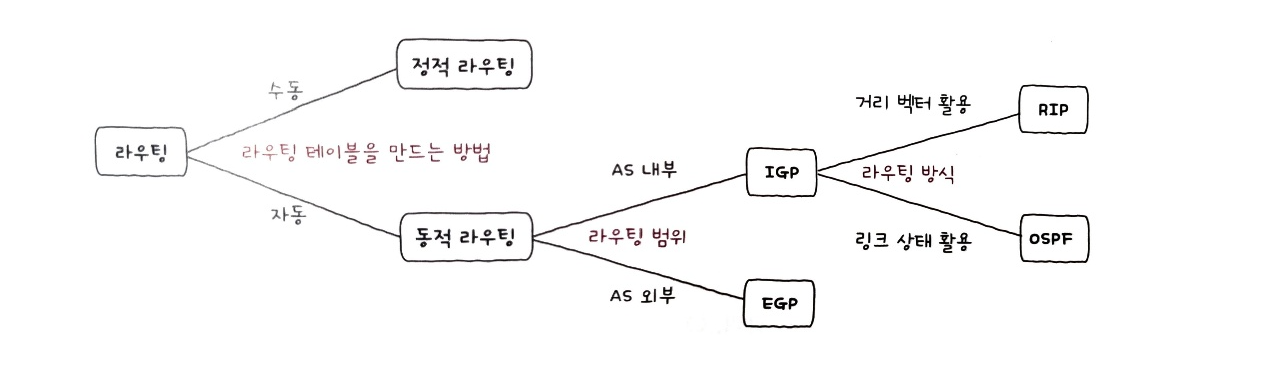
정적 라우팅과 동적 라우팅
라우팅 테이블을 만드는 방법은 정적 라우팅, 동적 라우팅 두 가지 방법이 있다.
이는 IP 주소를 할당하는 방법인 정적 할당, 동적 할당과 유사하다.
정적 라우팅
정적 라우팅은 사용자가 수동으로 직접 채워 넣은 라우팅 테이블의 항목을 토대로 라우팅되는 방식이다.
동적 라우팅
네트워크의 규모가 커지고 관리해야 할 라우터가 늘어나면 정적 라우팅만으로는 관리가 버겁다.
또한, 패킷이 라우팅되는 경로상에 문제가 발생한 데다가 또 다른 경로로 우회하여 전송할 수 있음에도 불구하고 라우터는 문제가 발생한 경로로 패킷을 전송할 수밖에 없다.
이때 사용되는 방식이 동적 라우팅이다.
동적 라우팅은 자동으로 라우팅 테이블 항목을 만들고, 네트워크 경로상에 문제가 발생했을 때 이를 우회할 수 있게 경로가 자동으로 갱신되기도 한다.
라우팅 프로토콜
동적 라우팅은 특정 수신지까지 도달하기 위한 최적의 경로를 찾아 라우팅 테이블에 추가하려 노력한다.
이를 위해 라우터끼리 자신의 정보를 교환하는데, 이 때 사용되는 프로토콜이 라우팅 프로토콜이다.
라우팅 알고리즘
- Link State Algorithm: 모든 라우터들의 정보를 가지고 있다.
- Distance Vector Algorithm: 자신과 이웃한 라우터의 정보만 가지고 있다.
라우팅 프로토콜
라우팅 프로토콜은 라우터끼리 자신들의 정보를 교환하며 패킷이 이동할 최적의 경로를 찾기 위한 프로토콜이다.
- 내부 라우팅(IGP): 같은 AS 내부의 라우팅 정보를 교환하는 프로토콜
- 외부 라우팅(EGP): 다른 AS 간의 라우팅 정보를 교환하는 프로토콜
AS
망식별 번호, 각각의 자율시스템을 식별하기 위한 인터넷 상의 고유 번호
하나의 그룹/기관/회사 같이 동일한 라우팅 정책으로 하나의 관리자에 의해 운영되는 네트워크
AS들 사이의 포워딩은 돈이나 정책들이 얽혀있다.
AS들 사이의 Peering을 통해 트래픽을 운반해준다.
AS들 사이의 트래픽을 다루는 것은 BGP를 통해서 이루어진다.
Distance Vector
분산 라우팅 알고리즘
라우터는 목적지까지의 모든 경로를 자신의 라우팅 테이블 안에 저장하는 것이 아니라 목적지까지의 거리 (Hop Count 등)와 그 목적지까지 가려면 어떤 인접 라우터(Neighbor Router)를 거쳐서 가야 하는지 방향만을 저장한다.
인접 라우터들과 주기적으로 라우팅 테이블을 교환해서 자신의 정보에 변화가 생기지 않았는지를 확인하고 관리한다.
[ 장점 ]
- 메모리 절약(한 라우터가 모든 라우팅 정보를 가지고 있을 필요가 없기 때문
- 라우팅의 구성 자체가 간단
[ 단점 ]
-
트래픽 낭비(라우팅 테이블에 아무런 변화가 없더라도 정해진 시간마다 한 번씩 라우팅 테이블의 업데이트가 일어나기 때문)
-
Convergence Time이 느리다.
느린 Convergence Time 때문에 RIP의 경우 최대 홉 카운트가 15를 넘지 못한다.
Convergence Time
라우팅 테이블에 생겨난 변화를 모든 라우터가 알 때까지 걸리는 시간
종류: RIP
Link State Algorithm
중앙 집중형 라우팅 알고리즘
한 라우터가 목적지까지의 모든 경로 정보를 다 알고 있다.
[ 장점 ]
- Convergence Time이 짧다. (라우터가 모든 경로를 알고 있기 때문)
- 라우팅 테이블 교환이 자주 발생하지 않는다.
- 트래픽 절약(교환이 일어나는 경우에도 테이블에 변화가 있는 것만을 교환)
[ 단점 ]
- 메모리 소모가 크다.(라우터가 모든 라우팅 정보를 관리해야 하기 때문)
- 라우터 CPU의 부담이 큼(SPF 계산 등 여러 계산을 해야 하기 때문)
종류: OSPF(Open Shortest Path First)
IGP
RIP
Routing Information Protocol은 최소 Hop Count를 파악하여 라우팅하는 프로토콜이다.
Distance vector(거리+방향) 다이나믹 라우팅 프로토콜이다.
RIP 프로토콜은 최단 거리, 즉 라우팅되는 홉 카운트가 가장 적은 경로로 라우팅하는 프로토콜로, 라우팅 테이블에 인접 라우터 정보를 저장하여 경로를 결정한다.
최대 홉 카운트는 15로, 거리가 짧기 때문에 내부용(IGP)로 많이 이용하는 프로토콜이다.
직접 연결되어 있는 라우터는 홉으로 계산하지 않고, 30초 주기로 Default Routing을 업데이트하여 인접 라우터로 정보를 전송한다.
또한, 4~6개까지 로드밸런싱이 가능하다는 특징이 있다.
주로 UDP 세그먼트에 캡슐화되어 사용된다.
RIP은 단순 홉을 카운트하여 경로를 결정하기 때문에 경로의 네트워크 속도는 판단하지 않는다.
때문에 비효율적인 경로로 전달할 가능성이 있다.
또한 Distance Vector 알고리즘으로 네트워크 변화에 대처하는 시간이 느리다는 단점이 있다.
OSPF
Open Shortest Path First 최단 경로 우선 프로토콜이다.
최소 시간 경로를 최적 라우팅 경로로 결정하는 것이다.
가장 대표적인 링크 상태 프로토콜로, SPF(최단 거리 우선 알고리즘)을 통해 라우팅 테이블을 생성한다.
주로 내부 게이트웨이 프로토콜(IGP)로 대규모 기업망에서 사용된다. 특히 Area라는 개념을 사용하여 전체 네트워크를 작은 영역으로 나눠 효율적으로 관리하는 방식을 택한다.
각 Area는 Back Bone Area에 연결되어 있으며 RIP가 30초마다 update되어 정보를 전송시켜주는 반면에 OSPF는 링크 상태에 변화가 있을 시 즉각적으로 Flodding을 해주기 때문에 컨버전스 타임이 매우 빠르다.
링크 상태 정보를 플러딩하고 다익스트라 최소 비용 경로 알고리즘을 사용하는 링크 상태 알고리즘으로, OSPF를 이용하여 각 라우터는 전체 AS에 대한 토폴로지 지도(그래프)를 얻는다.
OSPF의 자율시스템은 계층적인 영역으로 구성될 수 있다.
각 영역은 자신의 OSPF 링크 상태 라우팅 알고리즘을 수행하는데, 한 영역 내의 라우터는 같은 영역 내의 라우터들에게만 링크 상태를 브로드캐스트한다.
각 영역 내에서 하나 혹은 그 이상의 영역 경계 라우터가 영역 외부로의 패킷 라우팅을 책임진다.
AS 내 영역 간 라우팅을 위해서는 먼저 영역 경계 라우터로 패킷을 라우팅하고(영역 내 라우팅), 백본을 통과하여 목적지 영역의 영역 경계 라우터로 라우팅한 후 목적지로 라우팅한다.
BGP
Border Gateway Protocol은 AS와 AS간 사용되는 라우팅 프로토콜이다.
정해진 정책에 의해 최적 라우팅 경로를 수립하며, 분산 라우팅 알고리즘(거리 벡터)을 사용해 다른 IGP보다 컨버전스는 느리지만, 대용량의 라우팅 정보를 교환할 수 있는 프로토콜이다.
AS간 라우팅 프로토콜은 여러 AS간의 협력이 수반되므로 통신하는 AS들은 같은 AS 간 라우팅 프로토콜을 수행해야만 한다.
AS 내부에선 최단거리로 이동하지만, AS 간의 이동은 정책적인 부분을 따르며 이동하기 때문에, 최단 거리로 이동하지는 않는다.
라우팅 프로토콜에 대해 설명해주세요.
라우팅 프로토콜은 라우터끼리 자신들의 정보를 교환하며 패킷이 이동할 최적의 경로를 찾기 위한 프로토콜입니다.
내부 라우팅과 외부 라우팅으로 나눌 수 있습니다.
NEXT. IP 한계와 포트