
정규 표현식(Regular Expression)
문자열에서 특정 문자 조합을 찾기 위한 패턴이다.
정규식 만들기

- 정규 표현식 리터럴: 슬래시로 패턴을 감싸 작성
// 리터럴 방식
const regex = /abc/;정규 표현식 리터럴은 스크립트를 불러올 때 컴파일되므로, 바뀔 일이 없는 패턴의 경우 리터럴을 사용하면 성능이 향상될 수 있다.
RegExp객체의 생성자 호출
// 생성자 방식
const regex = new RegExp("abc");
const regex = new RegExp(/abc/);생성자 함수를 사용하면 정규 표현식이 런타임에 컴파일된다.
바뀔 수 있는 패턴이나, 사용자 입력 등 외부 출처에서 가져오는 패턴의 경우 사용하는 것이 좋다.
정규식 메서드
| 메서드 | 의미 |
|---|---|
| 문자열.match(/정규표현식/) | 문자열에서 정규표현식에 매칭되는 항목을 반환 |
| 문자열.matchAll(/정규표현식/) | 문자열에서 정규표현식에 매칭되는 모든 항목을 반환 |
| 문자열.replace(/정규표현식/, 대체문자열) | 정규표현식에 매칭되는 항목을 대체문자열로 변환 |
| 문자열.split(정규표현식) | 문자열을 정규표현식에 매칭되는 항목으로 쪼개 배열로 반환 |
| 정규표현식.test(문자열) | 문자열이 정규표현식과 매칭되면 true, 아니면 false 반환 |
| 정규표현식.exec(문자열) | match와 유사, 첫번째 매칭 결과만 반환 |
| 문자열.search(/정규표현식/) | 문자열에서 정규표현식에 일치하는 부분을 탐색하여 인덱스를 반환 |
| 문자열.replaceAll(/정규표현식/, 대체문자열) | 정규표현식에 매칭되는 모든 항목을 대체 문자열로 변환 |
문자열 내부에 패턴과 일치하는 부분이 존재하는지 여부만 확인하고자 한다면,
test() 나 search() 메서드를 사용하는 것이 좋다.
더 느리더라도 일치에 관한 추가 정보가 필요하다면 exec() 나 match() 메서드를 사용하면 된다.
이는 일치하는 부분이 존재하면, 일치에 관한 데이터를 포함한 배열을 반환한다.
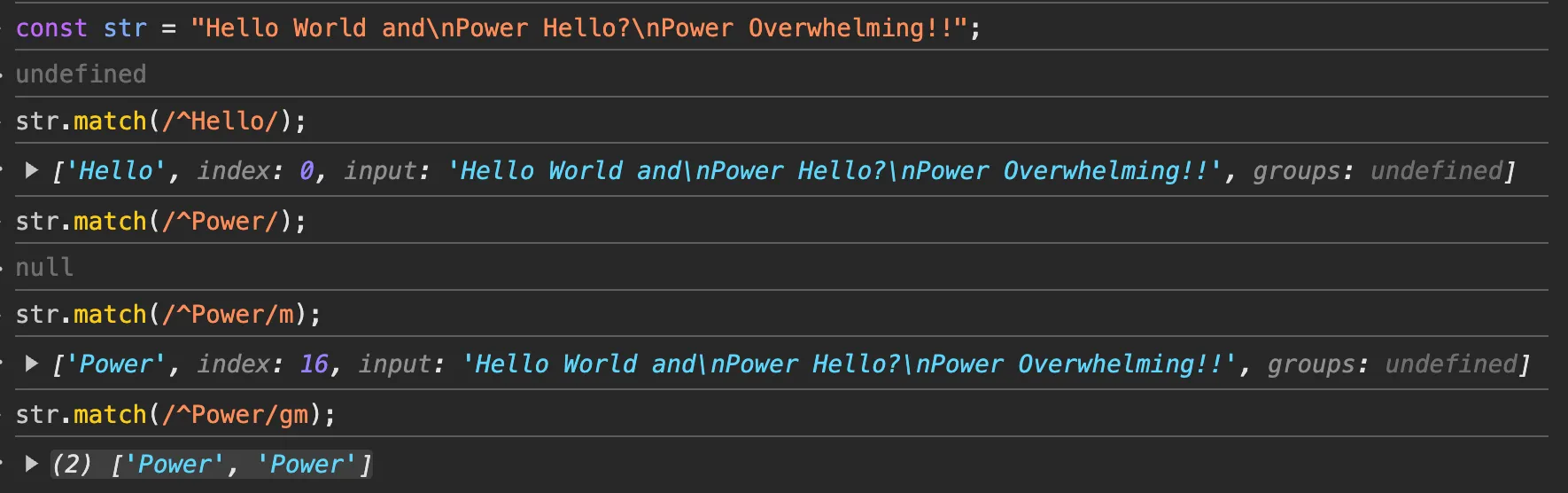
match와exec의 차이
정규식 플래그
정규식 플래그는 고급 검색을 위한 전역 옵션을 설정하도록 지원하는 기능이다.
| Flag | 의미 | 설명 |
|---|---|---|
| i | Ignore Case | 대소문자를 구별하지 않고 검색 |
| g | Global | 문자열 내의 모든 패턴 검색 |
| m | Multi Line | 문자열이 행이 바뀌더라도 검색 |
| s | 개행 문자가 . 과 일치 | |
| u | unicode | 유니코드 전체 지원 |
| y | sticky | 문자 내 특정 위치에서 검색하는 ‘sticky’ 모드 활성화 |
const flags = 'i';
cosnt regex = new RegExp('hello', flags);
const regex1 = /apple/i;
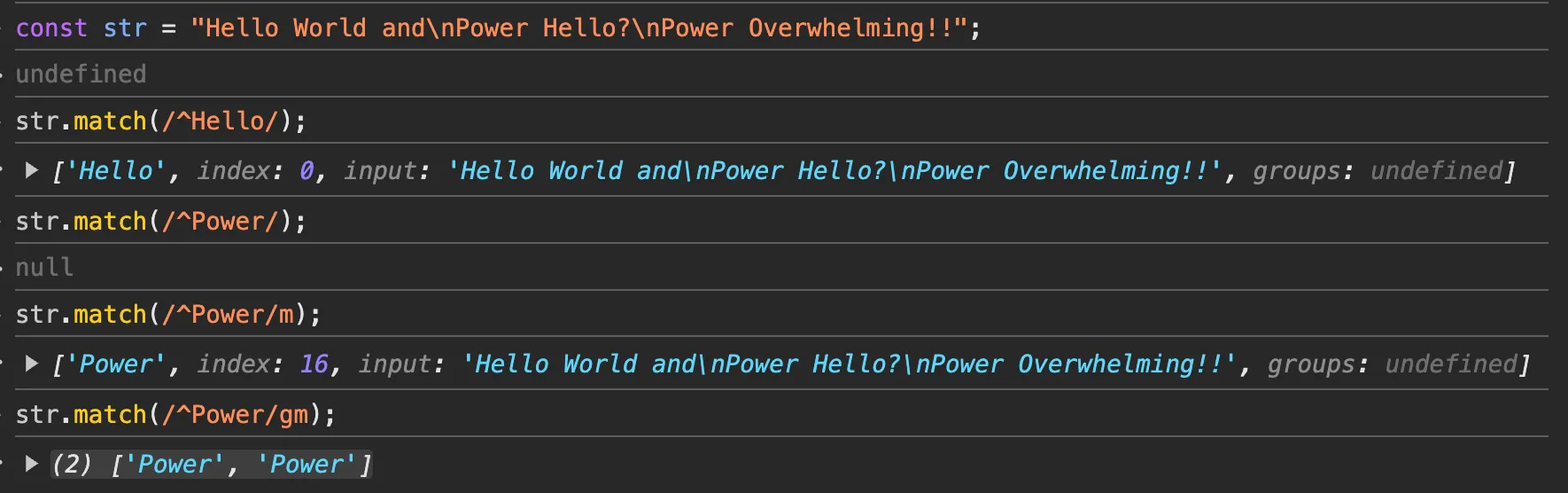
const regex2 = /apple/gm;m: 줄바꿈 검색
입력 시작(^) 앵커나 입력 종료($) 앵커는 전체 문자열이 아닌 각 줄 별로 대응되게 만들어졌기 때문에, 여러 줄을 검색해야 한다면 m 플래그를 사용
정규식 기호 모음
| 패턴 | 의미 |
|---|---|
| a-zA-Z | 영어알파벳(-으로 범위 지정) |
| ㄱ-ㅎ가-힣 | 한글 문자(-으로 범위 지정) |
| 0-9 | 숫자(-으로 범위 지정) |
| . | 모든 문자열. 단, 줄바꿈 포함 x |
| \d | 숫자 |
| \D | 숫자가 아닌 것 |
| \w | 밑줄 문자를 포함한 영숫자 문자 [A-Za-z0-9_]와 동일 |
| \W | \w가 아닌 것 |
| \s | 공백 |
| \S | 공백이 아닌 것 |
| \특수기호 | 특수기호 * \^ $ ! \? … 등 |
| \b | 63개 문자(영문, 숫자, _)가 아닌 나머지 문자에 일치하는 경계 |
| \B | 63개 문자에 일치하는 경계 |
| \x | 16진수 문자에 일치 /\x61/은 a에 일치 |
| \0 | 8진수 문자에 일치 /\141/은 a에 일치 |
| \u | 유니코드 문자에 일치 /\u0061/은 a에 일치 |
| \c | 제어 문자에 일치 |
| \n | 줄 바꿈 문자에 일치 |
| \r | 캐리지 리턴(CR) 문자에 일치 |
| \t | 탭 문자에 일치 |
\0패턴

정규식 검색 기준 패턴
| 기호 | 의미 |
|---|---|
| ? | 없거나 최대 한개 /apple?/ |
| * | 없거나 여러개 /apple*/ |
| + | 최소 한개 /apple+/ |
| *? | 최대 한개 |
| +? | 최소 한개 |
| {n} | n개 |
| {Min,} | 최소 Min개 이상 |
| {Min, Max} | 최소 Min개 이상, 최대 Max개 이하 |
정규식 그룹 패턴
| 기호 | 의미 |
|---|---|
| () | 그룹화 및 캡쳐 |
| (?:패턴) | 그룹화 (캡쳐x) |
| (?=) | 앞쪽 일치 /ab(?=c)/ |
| (?!) | 부정 앞쪽 일치 /ab(?!)c/ |
| (?≤) | 뒤쪽 일치 /(?≤ab)c/ |
| (?<!) | 부정 뒤쪽 일치 /(?<!ab)c/ |
정규식 그룹화

ko+ 는 o 만 +를 적용시킨다.
그룹화 ()를 사용하면 원하던 ko 에 대한 문자를 검색하게 된다.

배열을 보면 결과에 ko 가 포함된다.
이는 캡쳐 기능에 의한 것이다.
정규식 캡처 기능

- 먼저,
ko를 그룹화하여 캡처한다. - 캡처된 표현식은 당장 사용되지 않으며, 그룹화된
ko를 패턴 +로 1회 이상 연속으로 반복되는 문자로 검색한다. - 이후 캡처했던 표현식
ko가 검색된다.
캡처하지 않는 그룹화 (?:)
그룹화의 캡처 기능 때문에 원치않는 결과값을 얻게 되는데, 이를 막기 위해선 캡쳐 비활성화 기능 ?:을 사용한다.

우테코 정규 표현식 적용
프리코스 1주차 과제에서 정규 표현식을 사용해야 했다.
사용자가 //구분자\n 형태로 작성한 커스텀 구분자를 추출하여 이를 기준으로 수를 더하는 것이었다.
ex) *"//;\n;//-\n2;3-4"*
여기에 나는 간단한 정규식을 사용하여 구분자를 추출하였다.
const regex = /\/\/(.)\\n/;\/\/은//을 의미한다.(.)은 임의의 한 문자를 의미한다.\\n은\n을 의미한다.
match 를 사용하여 정규식에 해당하는 문자열이 있는지 체크하고, 해당 문자를 추출한다.
그리고 replace 를 사용하여 해당 문자열을 제거한다.
정규식 검사 사이트
정규식을 작성한 후 올바르게 작성했는지 모르겠을 때 예제를 통해 검사할 수 있는 사이트이다.
참고
