📝 1. 서론
SSAPI 서비스는 아프리카/치지직의 채팅/후원 데이터를 실시간으로 수집하여 개발자분들이 콘텐츠를 쉽게 개발할 수 있도록 돕는 API 서비스입니다.
많은 개발자분들의 사랑으로 매달 트래픽이 늘고 있는데요,
최근 들어 피크 시간대 기준 초당 2~3천 개의 트래픽이 들어오고 있는 상황이었습니다.
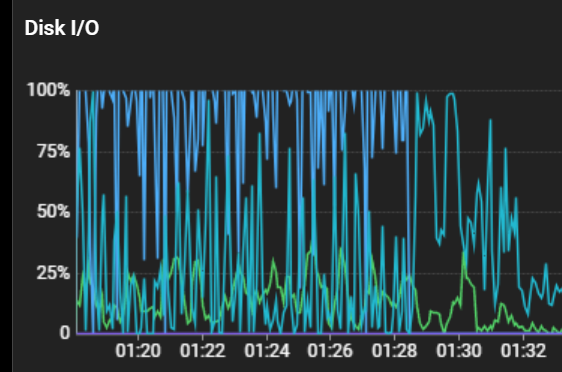
사용자분이 많이 늘면서 피크가 아닐 때에도 디스크의 I/O는 평상시에도 25~100%를 왔다 갔다 했었고
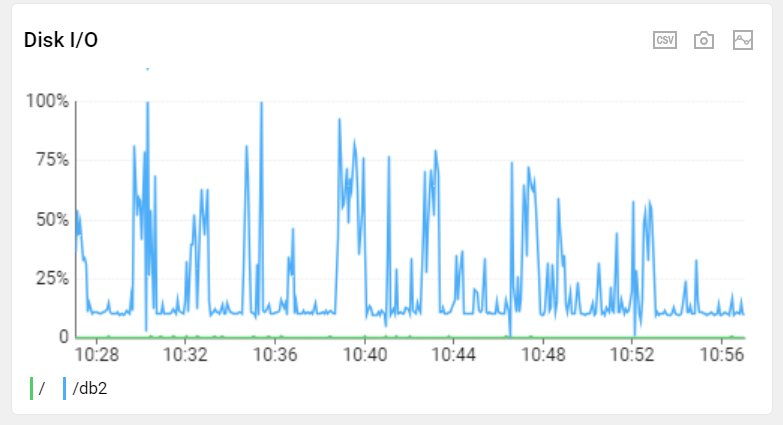
그리고 피크 시간이 되면...
네... 대안이 필요할때가 되었습니다...
🤔 2. 디스크를 뭘 쓰길래...
SSAPI는 iwinv를 사용하며, 디스크 역시 iwinv에서 제공하는 SSD 블록을 사용합니다.
상품 상세 설명 페이지에서 IOPS에 대한 상세 스펙이 나오진 않지만, 고객센터를 통해 확인해본 바로는 최대 10K IOPS 정도를 지원한다고 안내받았습니다.
물리 SSD와 비교하면 성능이 높은 편은 아니지만 10K IOPS 자체가 낮은 성능은 아니기 때문에 최적화에 난감함을 느끼고 있었습니다.

❓ 3. 왜 IOPS를 많이 쓰죠?
SSAPI에서 초당 3~4천 개의 트래픽에 대한 아주 디테일한 디버깅 로그를 수집하고 있으며, 이 데이터를 MongoDB에 임시 저장해 두었다가 개발자분들이 폴링 방식으로 데이터를 제공받을 수 있도록 합니다.
MongoDB의 경우 인덱스 개수에 따라 쓰기가 중복되는데, 이러한 인덱스와 파일 로그 시스템 등으로 설계 당시에도 피크 기준 6~8K 정도의 IOPS를 사용하고 있었습니다.
때문에 서버에 기본 마운트되는 SSD 블록 이외에 DB 전용 블록을 하나 더 사용하여 트래픽을 안정적으로 분산해왔습니다.
🌀 4. 첫 번째 시도
첫 번째 시도는 역시 가장 원초적인 수집하는 데이터 양 자체를 줄이는 것입니다. SSAPI에서 채팅과 후원 데이터는 소켓을 통해 데이터를 수집 후 파싱하여 사용합니다.
이때 파싱에 대한 정책을 설정하지 않아 분류되지 않는 데이터(Unkown Data) 또한 수집하고 있었습니다.
이는 향후에라도 해당 데이터의 패턴을 분석하여 추가적인 데이터 제공이 가능하도록 활용하기 위해서입니다.
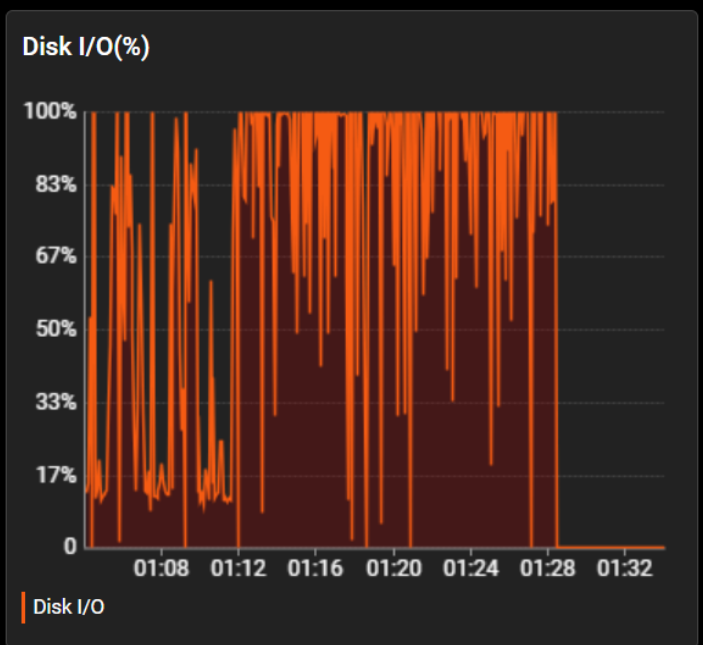
이러한 데이터는 초당 500~1000개 정도 수신되었는데, 이 데이터를 포기함으로써 며칠간은 안정적인 서비스 운영이 가능하게 되었습니다.
5. 😔 하지만 오래가지 않았죠...
사용자가 더 늘면서 첫 번째 시도에도 불구하고 서론에 언급했던 트래픽이 들어오게 되었습니다.
이제 단일 SSD 블록의 최대 스펙인 10K 이상의 성능이 필요한 상황이 되었습니다.
6. 🤔 대안을 고민해보자 (실패)
떠오르는 대안은 크게 세 가지였습니다.
1. 물리적으로 블록의 성능을 높이자
아쉽게도, 현재 사용하고 있는 클라우드 서비스에서 블록에 클래스가 여러 개 있진 않아 현재 사용하고 있는 블록이 최고 사양의 블록이라는 점에서 이 부분은 불가했습니다.
2. MongoDB를 샤딩하여 서버를 분산하자
이 방식이 가장 일반적이면서 가장 많이 사용되는 방식이었지만, 관리 지점이 많아지는 것이 다소 부담스럽기도 하였고 분산 서버 중 일부 서버에 장애가 발생할 경우 복구가 어려워 보이는 점, 그리고 서버를 여러 개 사용하는 것에 대한 비용 부담 등이 작용하여 이 부분은 포기하게 되었습니다.
3. 물리 서버를 쓰고 RAID를 직접 구성할까?
물리 서버나 베어메탈 서버를 사용하게 되면 SSD의 사양이나 RAID 구성을 자유롭게 커스터마이징할 수 있습니다. 다만, 데이터 보호를 위해서는 RAID 10 구성을 직접 해야 하는 점과 디스크 장애 시 서버 장애로 이어질 수 있다는 점이 불편했습니다.
7. 🚀 블록은 RAID 구성 할 수 없나?
🛑 잠시만요!
소개하고 있는 RAID 방식은 물리적 RAID 구성이 아닌 소프트웨어 RAID 방식입니다!
드 물리적인 방식에 비해 성능 등의 단점이 있습니다
RAID를 구성할 때 저는 기존에 RAID 컨트롤러 카드를 통해서 물리적으로 RAID를 구성하는 것만 알았는데, 최근 알게 된 내용으로, 논리적으로도 RAID 구성이 가능하다는 것을 알게 되었습니다.
우분투에서 mdadm과 같은 소프트웨어를 사용해서 논리적으로 RAID 구성이 가능하다는 것을 알게 되었고 이 방법을 채택하기로 했습니다!
그야말로 가장 우려했던 부분이 모두 해결 가능했거든요!
1. 서버 분산을 통해 관리 지점을 늘리고 싶지 않다
기존 사용하던 서버에서 블록과 mdadm만 셋팅하면 되니 관리 지점이 늘지 않음
2. 데이터 손상과 디스크 손상을 걱정하고 싶지 않다
블록은 디스크의 관리를 클라우드 측에서 여러 번의 복제를 통해 알아서 관리해주므로 이러한 걱정을 할 필요가 없었습니다.
🎉 8. 해결 완료
현재 최대 10K의 IOPS를 지원하는 SSD 블록 2개를 RAID 0로 구성하여 최대 20K 정도를 사용할 수 있도록 DB 스토리지를 구성한 상태입니다.
현재 사용하고 있는 서비스에서 iwinv는 한 서버에 최대 3개의 SSD 블록 마운트를 지원하기 때문에, 이론상 최대 30K까지 이러한 방식으로 디스크의 성능을 높일 수 있을 것으로 기대하고 있습니다.
글에서 따로 설명하진 않았지만, 디버깅용 로그 역시 오류가 날 경우 그 원인을 더 자세히 분석할 수 있게 하기 위해 더 세세한 로그를 수집하게 되면서 1K 정도의 IOPS를 유발하였기 때문에, 이 역시 별도의 SATA*4 RAID 블록을 통해 해결했습니다! (디버깅용 로그는 수백 기가 정도로 용량이 매우 커 SSD 블록으로 처리하기엔 비용 이슈가 있었기 때문이죠...)
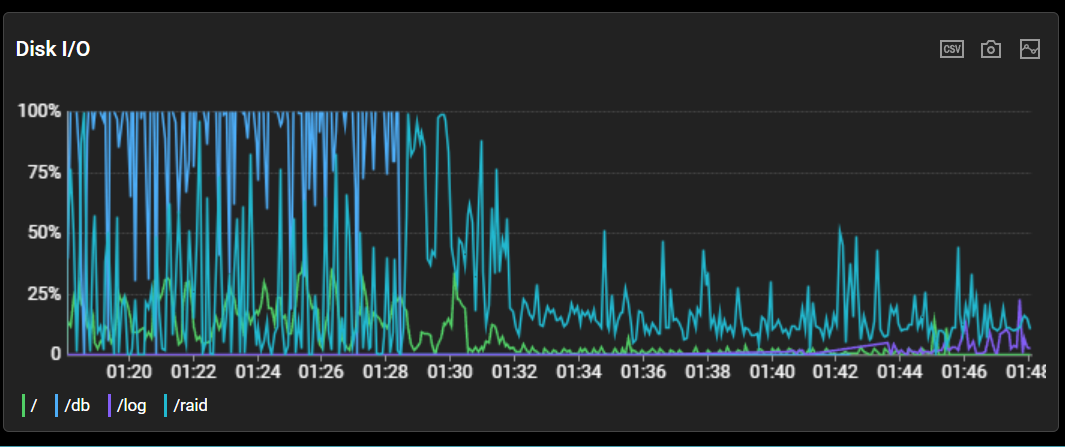
개선 후 디스크의 사용량은 최대 50% 이하로 줄어 안정적인 트래픽을 보여주고 있습니다.
🛠️ 9. 물론 해결해야 할 문제는 아직 있습니다.
가장 큰 문제는 역시 비용입니다.
서버를 분산하는 것에 비해 저렴한 것은 맞지만, SSD 블록은 매우 비쌉니다.
간단한 예로, 2개의 100GB SSD 블록을 합쳐 RAID 0로 구성하는 경우 월 3.2만 원이라는 금액이 발생하게 됩니다.
개인정보 보호를 위해 채팅과 후원 데이터는 약 3일 간격으로 자동 삭제되고 있지만, 운영 DB의 경우 그렇지 않습니다.
향후 운영 DB의 용량이 늘게 될 경우 이러한 블록 비용은 꽤나 부담스러운 수준이 될 것 같습니다.
만약 나중에 운영 DB의 용량이 너무 늘어나거나 30K 이상의 IOPS가 필요하게 될 경우, 결국 어쩔 수 없이 서버를 분산하거나 운영 DB와 채팅/후원 DB를 분리하거나 MongoDB가 아닌 다른 DB를 사용하는 등의 고민이 필요해질 것 같습니다.
물론, 현재는 문제가 되지 않기 때문에 아직 수정 계획은 없습니다.

해당 API에 대해 궁금하신 점이 있으신 분은 디스코드 채널이나 @hutsak로 DM 주시길 바랍니다
긴 글 읽어주셔서 감사합니다.
🆕 10. 24년 08월 07일 후기
앞서 글에서 소개한것 처럼, 역시 더 큰 사양의 RAID가 필요하게 되어 조금 비싸긴 하지만 SSD 블록을 RAID 10 구성하여 제공해주는 전용 서비스 (MAX IO 서버)를 사용하고 있습니다!
SSD 용량의 증설이 불가능하고 용량도 적다는게 단점이긴 하지만 IO 성능은
