
자바를 좀 공부 해봤다면 누구나 자바 바이트 코드가 JRE 위에서 동작한다는 것을 알것이다. JRE에서 가장 중요한 요소는 자바 바이트코드를 해석하고 실행하는 JVM(Java Virtual Machine)이다. JRE는 자바 API와 JVM으로 구성되며, JVM의 역할은 자바 애플리케이션을 클래스 로더(Class Loader)를 통해 읽어 들여서 자바 API와 함께 실행하는 것이다.
저도 어느정도 JVM이 어떤 역할을 하는지는 알지만 따로 정리해두지 않으면 시간의 지남에 따라 기억도 가물해지고 이 참에 한번 정리하려고 한다.
가상머신
가상 머신(Vritual Machine)은 여러가지로 정의할 수 있겠지만, 프로그램을 실행하기 위해서 물리적인 컴퓨터와 유사한 머신을 소프트웨어로 구사한 것이라고 생각하면 된다. 지금은 비록 빛이 바래진 목표긴 하나 자바는 원래 WORA(Write Once Run Anywhere)를 구현하기 위한 물리적인 머신과 별개의 가상 머신을 기반으로 동작하도록 설계하였다. 그래서 자바 바이트코드(byte code)를 어디서든 실행하고자 JVM이 설치된다는 가정하에 모든 하드웨어에 자바 실행코드를 따로 변경하지 않고도 실행 및 동작하게 한 것이다.
JVM (Java Virtual Machine)
JVM은 자바 바이트 코드를 실행하기 위한 가상 머신이다.
우선, 자바 소스 작성부터 그 소스코드가 어떻게 변환되고 실행되는지 전반적인 실행과정을 보자면!
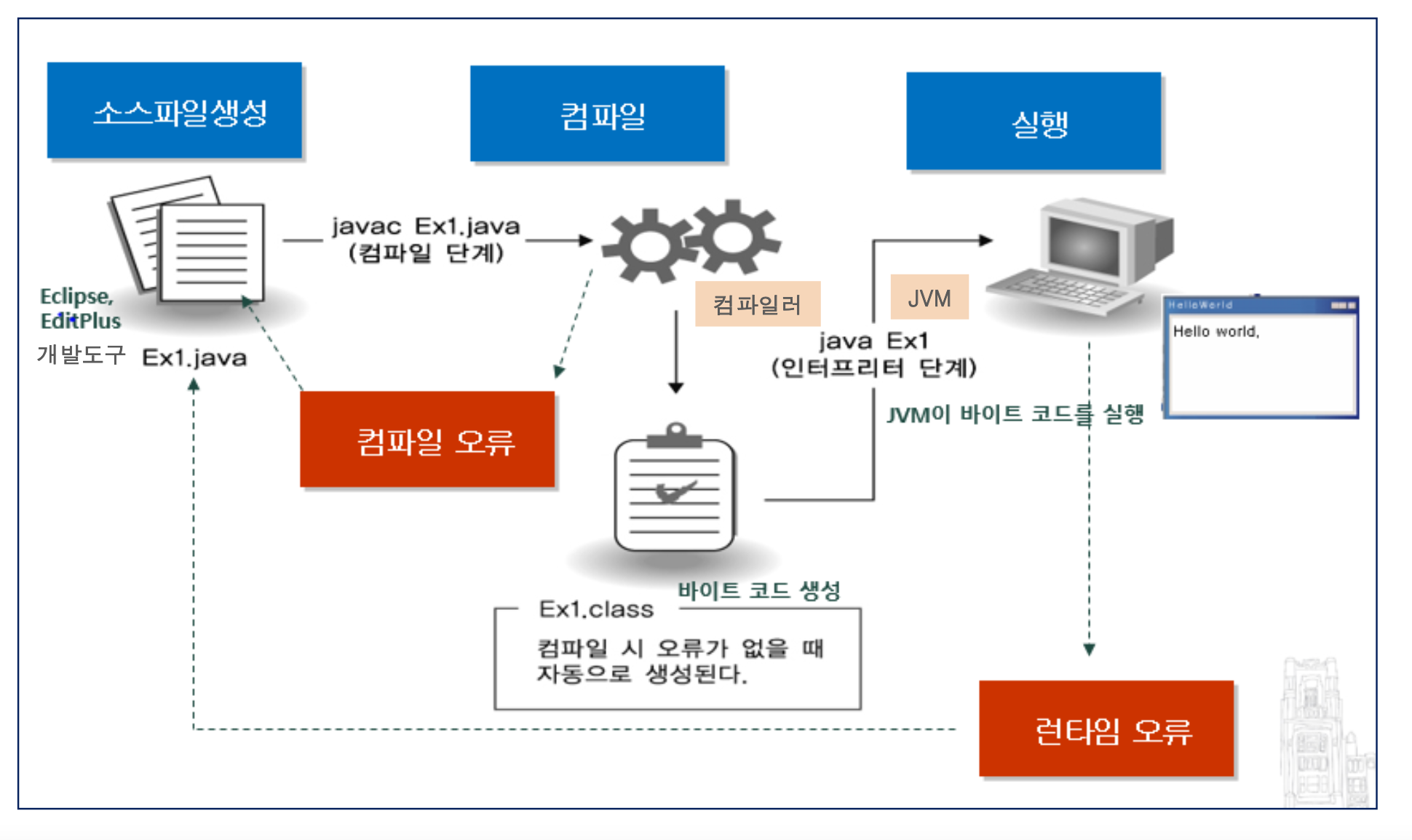
1.eclipse나 intelliJ 같은 통합개발환경툴(IDE) 곳에서 (꼭 여기서 작성안해도된다. 메모장도 가능) 자바어로 코드를 작성한다. (여기까지는 .java) 파일이다.
2.작성된 코드(.java)를 javac(= 자바 컴파일)에 넘겨주면서 컴파일을 한다. 그러면 바이트 코드(byte code)로 변환된다. 즉, .class 파일이 생겨난다. (참고로 바이트 코드로 된 class 파일은 JVM이 설치된 어느 OS에서도 실행이 가능하다. 이식성이 좋다고도 말한다!)
(바이트 코드의 모습)
3.컴파일 오류가 없을 시 .class 파일이 생기는데, 이 클래스 파일을 인터프리터 단계인 JVM이 드디어 바이트코드를 실행한다.
이렇게 JVM은 JDK에 포함된 소프트웨어이며 바이트 코드(byte)코드를 완전한 기계어로 번역하는 역할을 한다.
자바 프로그램은 완전한 기계어가 아닌 바이트 코드 파일(.class)로 구성되는데 이 클래스 파일을 JVM이
기계어로 번역하고 실행한다.
CPU가 이해할 수 있는 언어가 바이너리 코드라면 바이트 코드는 가상 머신(JVM)이 이해할 수 언어이다.

JVM의 특징
- 스택 기반의 가상 머신 : 대표적인 컴퓨터 아키텍처인 intel x86 아키텍처나 ARM 아키텍처와 같은 하드웨어가 레지스터 기반으로 동작하는 데 비해 JVM은 스택 기반으로 동작한다.
- 심볼릭 레퍼런스 : 기본 자료형(primitive data type)을 제외한 모든 타입(클래스와 인터페이스)을 명시적인 메모리 주소 기반의 레퍼런스가 아니라 심볼릭 레퍼런스를 통해 참조한다.
- Garbage Collection : 가비지 컬렉션은 클래스 인스턴스는 사용자 코드에 의해 명시적으로 힙 메모리에 생성되고 가비지 컬렉션에 의해 자동적으로 삭제된다.
- 기본 자료형으르 명확하게 정의하여 플랫폼 독립성 보장 : C/C++등 전통적인 언어는 플랫폼에 따라 int 형 크기가 변한다. JVM은 기본 자료형을 명확하게 정의하여 호환성을 유지하고 플랫폼의 독립성을 보장한다.
- 네트워크 바이트 오더(network byte order) : 자바 클래스 파일은 네트워크 바이트 오더를 사용한다. 인텔 x86 아키텍처가 사용하는 리틀 엔디안이나, RISC 계열 아키텍처가 주로 사용하는 빅 엔디안 사이에서 플랫폼 독립성을 유지하려면 고정된 바이트 오더를 유지해야하므로 네트워크 전송 시에 사용하는 바이트 오더인 네트워크 바이트 오더를 사용한다. 네트워크 바이트 오더는 빅 엔디안이다.
자바는 썬 마이크로시스템스가 개발했지만, JVM 명세(The Java Virtual Machine Specification)을 따르기만 하면 어떤 벤더든 JVM을 개발하여 제공 가능하다. 따라서 대표적인 오라클 핫스팟 JVM 외에도 IBM JVM을 비롯한 다양한 JVM이 존재한다. 안드로이드 스마트폰에 기본탑재된 Dalvik VM은 JVM이긴 하지만 JVM 명세를 따르지 않는다. 스택 머신인 다른 JVM과 달리 Dalvik VM은 레지스터 머신이며, 따라서 독자적인 툴을 사용하여 자바 byte code를 Dalvik VM용의 레지스터 기반 명령어 코드로 변환한다.
자바 바이트코드
WORA를 구현하기 위해 JVM은 사용자 언어인 자바와 기계어 사이의 중간 언어는 자바 바이트 코드를 사용한다. 이 자바 바이트 코드가 자바 코드를 배포하는 가장 작은 단위이다.
자바 바이트코드에 대해 설명하기 전, 한 가지 실제 예를 설명한다. 실제로 개발 과정에서 발생한것을 변경 및 요약한것이다.
현상
원래 잘 동작하던 애플리케이션이 라이브러리 업데이트 이후로 다음과 같은 NoSuchMethodError 오류를 내고 동작하지 않는다
Exception in thread "main" java.lang.NoSuchMethodError: com.nhn.user.UserAdmin.addUser(Ljava/lang/String;)V
at com.nhn.service.UserService.add(UserService.java:14)
at com.nhn.service.UserService.main(UserService.java:19)
애플리케이션 코드는 변경하지 않았으며 다음과 같다.
// UserService.java
…
public void add(String userName) {
admin.addUser(userName);
}업데이트된 라이브러리 소스코드와 원래 소스코드는 다음과 같다.
// UserAdmin.java - 업데이트된 소스코드
…
public User addUser(String userName) {
User user = new User(userName);
User prevUser = userMap.put(userName, user);
return prevUser;
}
// UserAdmin.java - 원래 소스코드
…
public void addUser(String userName) {
User user = new User(userName);
userMap.put(userName, user);
}즉, 반환값이 없던 addUser() method가 User 클래스 인스턴스를 반환하는 메서드로 변경되었다.
그러나, 애플리케이션 코드는 addUser() method의 return 값을 사용하지 않으므로 변경하지 않았다.
보기에는 com.nhn.user.UserAdmin.addUser() 메서드는 여전히 존재하는거 같은데...
왜? NoSuchMethodError가 발생할까?
원인
애플리케이션 코드를 새로운 라이브러리로 다시 컴파일하지 않았기 때문이다. 즉, 애플리케이션 코드는 우리가 보기에 반환값고 무관하게 메서드를 호출하고 있는거 같지만, 실제로 컴파일된 클래스 파일은 반환값까지 지정된 메서드를 지칭한다.
이는 다음 오류 메시지를 보면 확실히 알 수 있다.
java.lang.NoSuchMethodError: com.nhn.user.UserAdmin.addUser(Ljava/lang/String;)V
NoSuchMethodError는 "com.nhn.user.UserAdmin.addUser(Ljava/lang/String;)V"라는 메서드를 찾지 못해서 생긴 에러이다. 여기서 포인트는 "Ljava/lang/Stirng;"과 마지막 "V"이다. 자바 바이트코드의 표현에서 "L;"은 클래스 인스턴스이다. 즉 addUser() 메서드는 java/lang/String 객체 하나를 파라미터로 받는 메서드이다. 이 사례의 라이브러리에서는 파라미터가 변경되지 않았으므로 이 파라미터는 정상이다. 위 메세지의 마지막 "V"는 메서드의 반환값을 나타낸다. 자바 바이트코드 표현에서 "V"는 반환값이 없음을 의미한다. 즉, 위 오류 메시지는 java.lang.String 객체 1개를 파라미터로 받고 반환값이 없는 com.nhn.user.UserAdmin.addUser()라는 메서드를 찾지 못했다는 의미이다.
애플리케이션 코드는 이전 라이브러리로 컴파일되었으므로, "V"를 반환하는 메서드를 호출하도록 class 파일에 기록되어 있지만, 새로 변경된 라이브러리에서 "V"를 반환하는 메서드는 없어지고, "Lcom/nhn/user/User;"를 반환하는 메서드가 추가되었기 때문에 NoSuchMethodError가 발생한 것이다.
참고
오류 자체는 새로운 라이브러리를 다시 컴파일 하지 않았기 때문에 발생한 것이지만, 이 사례는 라이브러리 제공자의 잘못이 더 크다고 할수 있다. public으로 공개된 메서드의 반환값이 없다가 User 클래스 인스턴스를 반환하도록 변경된것이므로, 이것은 명백한 메서드 시그니처 변경이다. 즉, 라이브러리 하위 호환성이 깨진것으로 라이브러리 제공자는 메서드가 변경되었다는 것을 반드시 사용자에게 알려줬어야 한다.
다시 자바 바이트코드 자체 이야기로
JVM을 이야기 할때는 자바 바이트 코드를 빼놓을수 없다. JVM은 자바 바이트 코드로 실행하는 실행기이다. 자바 컴파일러는 C/C++ 등의 컴파일러처럼 고수준 언어를 기계어, 즉 직접적인 CPU가 이해하는 명령을 변환하는 것이 아니라, 개발자가 이해하는 자바 언어를 JVM이 이해하는 자바 바이트 코드를 변환하는 것이다. 따라서 자바 바이트 코드는 플랫폼에 의존적인 코드가 없기 때문에 같은 프로파일의 JRE가 설치된 장비라면 CPU나 OS가 다르더라도 실행할 수 있고(윈도우 PC에서 개발하여 컴파일한 .class 파일을 리눅스 OS에서도 그대로 실행 가능하다.) 컴파일 결과물 크기가 소스코드의 크기와 크게 다르지 않으므로 네트워크로 전송하여 실행하기도 쉽다.
클래스 파일(.class) 자체는 바이너리 파일이므로 사람이 이해하기 쉽지 않다. 이 점을 보완하기 위해 JVM 벤더들은 javap라는 역어셈블러(disassembler)를 제공한다. javap를 이용한 결과물을 흔히 자바 어셈블리라고 부른다. 앞 사례에서 애플리케이션 코드 UserService.add()메서드를 javap-c 옵션으로 역어셈블한 결과물은 다음과 같다.
javap를 사용하는 방법은
command line에
javap 입력 후
javap <옵션> <클래스 파일 명>
옵션은 terminal에 javap를 입력하면 알려준다.

public void add(java.lang.String);
Code:
0: aload_0
1: getfield #15; //Field admin:Lcom/nhn/user/UserAdmin;
4: aload_1
5: invokevirtual #23; //Method com/nhn/user/UserAdmin.addUser:(Ljava/lang/String;)V
8: return 이 결과물에서 addUser() 메서드를 호출하는 부분은 "5:invokevirtual #23;"이다. 이는 23번 인덱스에 해당하는 메서드를 호출하라는 의미이며, 23번 인덱스의 메서드를 javap 프로그램이 친절하게 //Method com/nhn/user/UserAdmin.addUser: 이런식으로 주석으로 달아주었다.
invokevirtual은 자바 바이트코드에서 메서드를 호출하는 가장 기본적인 명령어의 OpCode(operation code)이다. 참고로, 자바 바이트코드에서 메서드를 호출하는 명령어 OpCode는 invokeinterface, invokespecial, invokestatic, invokevirtual의 4가지가 있으며 각각의 의미는 다음과 같다.
- invokeinterface : 인터페이스 메서드 호출
- invokespecial : 생성자, private 메서드, 슈퍼 클래스의 메서드 호출
- invokestatic : static 메서드 호출
- invokevirtual : 인스턴스 메서드 호출
자바 바이트 코드의 명령어는 OpCode와 피연산자 Operand로 분리할 수 있으며, invokevirtual 같은 OpCode는 2바이트의 피연산자가 필요하다.
위의 애플리케이션 코드를 업데이트된 라이브러리로 다시 complie 하여 다시 역어셈블하면 다음과 같은 결과를 얻을 수 있다.
public void add(java.lang.String);
Code:
0: aload_0
1: getfield #15; //Field admin:Lcom/nhn/user/UserAdmin;
4: aload_1
5: invokevirtual #23; //Method com/nhn/user/UserAdmin.addUser:(Ljava/lang/String;)Lcom/nhn/user/User;
8: pop
9: return 23번째 해당하는 메서드가 "Lcom/nhn/user/User;"를 반환하는 메서드로 변환된것을 알 수 있다.
위의 역어셈블 결과물에서 코드 앞의 숫자는 무슨 숫자를 의미할까? 바로 바이트 번호이다. JVM이 실행하는 코드를 굳이 바이트 코드라고 하는 이유가 바로 이것일 것이다.
즉, 위의 aload_0, getfield, invokevirtual 같은 바이트 코드 명령어는 1바이트의 바이트 번호로 표현된다.(1바이트는 8비트이므로 헥사로 표현되면 0x??가 된다.) aload_0 = 0x2a, getfield = 0xb6, invokevirtual = 0xb6 등이다. OpCode는 총 2^8임으로 256개라는 점을 알 수 있다.
aload_0, aload_1 와 같은 OpCode는 피연산자가 필요하지 않다. 따라서 aload_0 바로 다음 바이트가 명령어의 OpCode가 된다. 그러나 getfield, invokevirtual은 2바이트의 피연산자가 필요하다. 따라서 첫 번째 바이트에 있는 getfield의 다음 명령어는 2바이트를 건너뛴 네번째 바이트에 기록된다. 위 바이트 코드를 Hex Editor로 보면 다음과 같다.
2a b4 00 0f 2b b6 00 17 57 b1 자바 바이트코드에서 클래스 인스턴스는 "L;" void는 "V"로 표시되는 것처럼 다른 타입들도 고유의 표현이 있다. 이 표현을 정리하자면 다음고 같다.
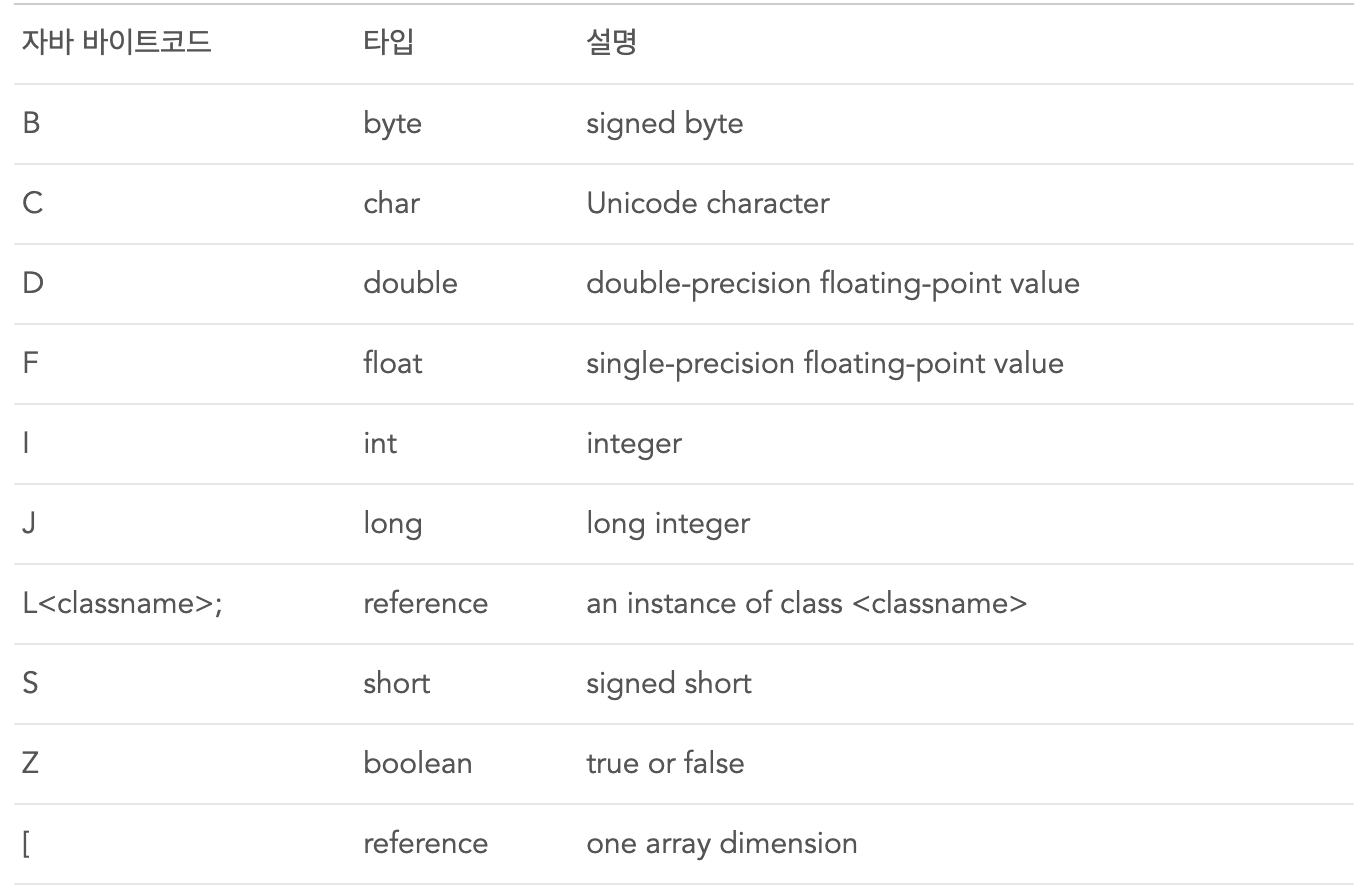
그럼 바이트 코드 표현을 적용할 수 있다.
자바 코드인 double d[][][]; 를 [[[D로 바이트코드로 표현이 가능하다.
Object mymethod(int l, double d, Thread t) 를 (IDLjava/lang/Thread;)Ljava/lang/Object;로 바이트 코드로 표현이 된다.
더 자세한 내용은 "The Java Virtual Machine Specification, Second Edition"의 "4.3 Descriptors" 절을 참고한다. 또한, 다양한 자바 바이트코드의 명령어들은 "The Java Virtual Machine Specification, Second Edition"의 "6. The Java Virtual Machine Instruction Set" 장을 참고한다.
클래스 파일 포맷
자바의 클래스 파일 포맷을 설명하기 전에 다시 자바 웹 애플리케이션에서 흔한 사례를 하나 보고 가자
현상
Tomcat에서 JSP를 작성하여 실행하니 실행되지 않고 다음과 같은 오류가 발생하였다.
Servlet.service() for servlet jsp threw exception org.apache.jasper.JasperException: Unable to compile class for JSP Generated servlet error:
The code of method _jspService(HttpServletRequest, HttpServletResponse) is exceeding the 65535 bytes limit" 원인
위 같은 오류 메시지는 웹 어플리케이션 서버별로 조금씩 다르지만, 65535바이트 제한 이라는 메시지이다. 이 65535 바이트 제한은 한 메서드의 크기가 65535바이트를 넘을 수 없다는 JVM 명세 자체의 제한이다.
왜 이러한 명세 제한이 생겼는지 좀 더 깊게 들어가보자.
자바 바이트 코드에서 일반적으로 사용하는 bransh/jump 명령은 "goto"와 "jsr" 두가지 이다.
goto [branchbyte1] [branchbyte2]
jsr [branchbyte1] [branchbyte2] 이들은 모두 2바이트의 signed branch offset을 피연사자로 받으므로 최대 65535번 인덱스까지 이동할 수 있다. 그러나, 자바 바이트코드는 좀 더 여유 있는 branch를 지원하기 위해 4바이트의 signed branch offset을 받는 "goto_w"와 "jsr_w"를 이미 준비하고 있다.
goto_w [branchbyte1] [branchbyte2] [branchbyte3] [branchbyte4]
jsr_w [branchbyte1] [branchbyte2] [branchbyte3] [branchbyte4] 즉, 이들을 이용하면 65535 이상의 인덱스로도 branch 가능하다. 자바 메서드의 65535 바이트 제한을 넘을 수 있을거같다. 하지만 자바 클래스 파일 포맷의 다른 여러가지 제한 때문에 여전히 자바 메서드는 655535 바이트를 넘길 수가 없다. 다른 제한을 알아보기 위해 클래스 파일 포멧을 간단히 설명하겠다.
자바 .class 파일의 큰 골격은 다음과 같다.
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}위 내용은 "The Java Virtual Machine Specification, Second Edition"의 "4.1. The ClassFile Structure"에서 가져온 것이다.
앞에서 역어셈블한 UserService.class 파일의 첫 16바이트를 Hex Editor로 살펴보면 다음과 같다.
ca fe ba be 00 00 00 32 00 28 07 00 02 01 00 1b 이 값과 함께 클래스 파일 포맷을 간단히 살펴보자.
-
magic : 클래스 파일의 첫 4바이트는 magic number이다. 이는 자바 클래스 파일을 구별하기 위해 미리 지정해둔 값이며, 위의 Hex Editor 갑셍서 볼수 있듯이 항상 OxCAFEBABE이다. 즉, 어떤 파일의 첫 4바이트가 0xCAFEBABE라면 이는 자바 클래스파일이라고 일단 추측가능하다.
-
minor_version, major_version : 다음 4바이트는 클래스 버전을 나타낸다. UserService.class 파일은 0x00000032이므로, 클래스 버전은 50.0이다. 16진수인 32를 10진수로 나타내면 50이기 때문이다. JDK 1.6으로 컴파일한 클래스 파일 버전은 50.0, JDK 1.5로 컴파일한 클래스 파일 버전은 49.0이다. 이처럼 JVM은 자신의 버전보다 하위 버전에서 컴파일된 클래스 파일에 대해서는 하위 호환성을 유지해야한다. 반면에 하위 버전의 JVM에서 상위 버전의 클래스를 실행하면 java.lang.UnsupportedClassVersionError가 발생한다.
-
constant_pool_count, constant_pool[] : 버전 다음으로는 클래스 파일의 상수 풀(constant pool)정보를 기술한다. 뒤에서 설명할 런타임 상수 풀(Runtime Constant Pool) 영역에 들어갈 정보가 바로 여기에 있다. JVM은 클래스 파일을 로드하면서 이 constant_pool 정보를 메서드 영역의 런타임 상수 풀에 넣는다. UserService.class 파일의 constant_pool_count는 0x0028이므로 constant_pool에 40-1, 즉 39개의 인덱스를 가진것을 알 수 있다.
-
access_flags: 주로 클래스의 modifier 정보, 즉 public, final, abstract나 인터페이스 여부를 나타내는 플래그이다.
-
this_class, super_class: 각각 this, super에 해당하는 클래스들에 대한 constant_pool 내의 인덱스이다.
-
interfaces_count, interfaces[]: 클래스가 구현한 인터페이스의 개수와 각 인터페이스에 대한 constant_pool 내의 인덱스이다.
-
fields_count, fields[]: 클래스의 필드 개수와 필드 정보이다. 필드 정보에는 필드 이름, 타입 정보, modifier, constant_pool에서의 인덱스 등이 포함된다.
-
methods_count, methods[]: 클래스의 메서드 개수와 메서드 정보이다. 메서드 정보는 메서드 이름, 파라미터 타입과 개수, 반환 타입, modifier, constant_pool에서의 인덱스와 함께 메서드 자체의 실행 코드, 예외 정보 등의 내용도 포함한다.
-
attributes_count, attributes[]: attribute_info 구조체는 다양한 속성을 갖고 있다. field_info나 method_info에서도 attribute_info를 사용한다.
이렇게 javap 프로그램은 이 클래스의 파일 포맷도 사용자가 간략하게 해석하여 읽을 수 있게 보여준다. "javap-verbose"옵션을 사용하여 UserService.class를 분석하면 다음과 같은 애요이 출력된다.
Compiled from "UserService.java"
public class com.nhn.service.UserService extends java.lang.Object
SourceFile: "UserService.java"
minor version: 0
major version: 50
Constant pool:
const #1 = class #2; // com/nhn/service/UserService
const #2 = Asciz com/nhn/service/UserService;
const #3 = class #4; // java/lang/Object
const #4 = Asciz java/lang/Object;
const #5 = Asciz admin;
const #6 = Asciz Lcom/nhn/user/UserAdmin;;
// … 중략 - constant pool 내용 계속 …
{
// … 중략 - 메서드 정보 …
public void add(java.lang.String);
Code:
Stack=2, Locals=2, Args_size=2
0: aload_0
1: getfield #15; //Field admin:Lcom/nhn/user/UserAdmin;
4: aload_1
5: invokevirtual #23; //Method com/nhn/user/UserAdmin.addUser:(Ljava/lang/String;)Lcom/nhn/user/User;
8: pop
9: return
LineNumberTable:
line 14: 0
line 15: 9
LocalVariableTable:
Start Length Slot Name Signature
0 10 0 this Lcom/nhn/service/UserService;
0 10 1 userName Ljava/lang/String;
// … 후략 - 다른 메서드 정보 …
}JVM 구조
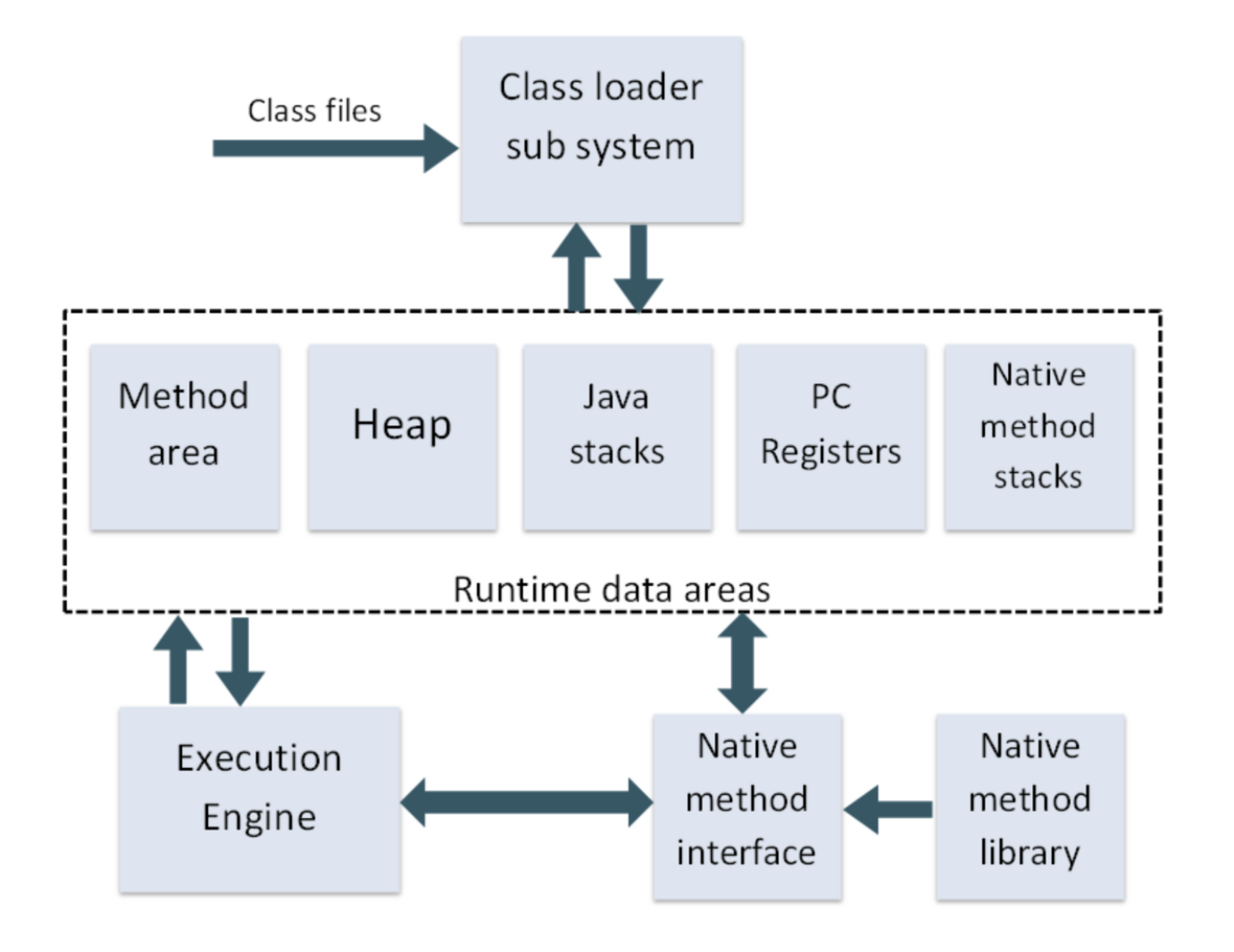
JVM은 크게 3가지로 구분한다.
- Class Loader
- Runtime Data Area
- Execution Engine
클래스 로더(Class Loader)가 컴파일된 자바 바이트코드를 런타임 데이터 영역(Runtime Data Area)에 로드하고, 실행 엔진(Execution Engine)이 자바 바이트코드를 실행한다.
Class Loader

자바는 컴파일 타임에서 아니라 동적 로드인 런타임에서 클래스를 처음 참조할 때 해당 클래스를 로드하고 링크하는 특징이 있다. 이 동적 로드를 담당하는 부분이 JVM의 class loader 이다. 자바 클래스 로더의 특징은 다음과 같다.
-
게층 구조 : 클래스 로더끼리 parents-child 관계를 이루어 계층구조를 생성한다. 최상위 클래스 로더는 부트스트랩 클래스 로더(Bootstrap Class Loader)이다.
-
위임 모델 : 계층 구조를 바탕으로 클래스 로더끼리 로드를 위임하는 구조로 동작한다. 클래스를 로드할 때 먼저 상위 클래스 로더를 확인하여 상위 클래스 로더에 있다면 해당 클래스를 사용하고, 없다면 로드를 요청 받은 클래스 로더가 클래스를 로드한다.
-
가시성(visibility) 제한 : 하위 클래스 로더는 상위 클래스 로더의 클래스를 찾을수 있지만 상위 클래스는 하위 클래스 로더를 찾을 수 없다.
-
언로드(unload) 불가 : 클래스 로더는 클래스를 로드할 수 있고 언로드는 할 수가 없다. 언로드 대신 현재 클래스 로더를 삭제하고 아예 새로운 클래스 로더를 생성하는 방법을 사용할수는 있다.
각 클래스 로더는 로드된 클래스들을 보관하는 namespace를 갖는다. 클래스를 로드할 때 이미 로드된 클래스인지 확인하기 위해 namespace에 보관된 FQCN(Fully Qualified Class Name)을 기준으로 클래스를 찾는다. 비록 FQCN이 같더라도 namespace가 다르면, 즉 다른 클래스가 로드한 클래스면 다른 클래스로 간주한다.
다음 그림은 Class Loader 위임 model을 나타냈다.

클래스 로더가 클래스 로드를 요청받으면, 클래스 로더 캐시, 상위 클래스 로더, 자기 자신의 순서로 해당 클래스가 있는지 확인한다. 즉, 이전에 로드된 클래스인지 클래스 로더 캐시를 확인하고, 없으면 상위 클래스 로더를 거슬러 올라가면서 확인한다. 부트스트랩 클래스 로더까지 확인해도 없으면 요청 받은 클래스 로더가 파일 시슽렘에서 해당 클래스를 찾는다.
-
부트스트랩 클래스 로더 : JVM을 가동할 때 생성되며, Object 클래스를 비롯하여 자바 API들을 로드한다. 다른 클래스 로더와 달리 자바가 아니라 네이티브 코드로 구현되어 있다.
-
익스텐션 클래스 로더(Extension Class Loader) : 기본 자바 API를 제외한 확장 클래스들을 로드한다. 다양한 보안 확장 기능 등을 여기에 로드하게 된다.
-
시스템 클래스 로더(System Class Loader) : 부트스트랩 클래스 로더와 익스텐션 로더가 JVM 자체의 구성요소를 로드하는 것이라면, 시스템 클래스 로더는 애플리케이션의 클래스를 로드한다고 할 수 있다. 사용자가 지정한 $CLASSPATH 내의 클래스를 로드한다.
-
사용자 정의 클래스 로더(User-Defined Class Loader) : 애플리케이션 사용자가 직접 코드 상에서 생성해서 사용하는 클래스 로더이다.
웹 어플리케이션 서버(WAS)와 같은 프레임워크는 웹 어플리케이션들, enterprise 애플리케이션들이 서로 독립적으로 동작하기 위해 사용자 정의 클래스 로더를 사용한다. 즉, 클래스 로더의 위임 모델을 통해 애플리케이션의 독립성을 보장하는 것이다. 이와 같은 WAS 클래스 로더 구조는 WAS 벤더마다 조금씩 다른 형태의 계층 구조를 사용하고 있다.
클래스 로더가 아직 로드되지 않는 클래스를 찾으면 다음 그림과 같은 과정을 거쳐 클래스를 로드하고 링크하고 초기화한다.

각 단계를 간단히 설명하면 다음과 같다.
-
로드(Loading) : 클래스를 파일에서 가져와서 JVM의 메모리에 로드한다.
-
검증(Verifying) : 읽어 들인 클래스가 자바 언어 명세(Java Language Specification) 및 JVM 명세에 명시된 대로 잘 구성되어 있는지 검사한다. 클래스 로드의 전 과정중에 가장 까다로운 검사를 수행하는 과정으로 가장 복잡하고 시간이 많이 걸린다. JVM TCK의 테스트 케이스 중에서 가장 많은 부분이 잘못된 클래스를 로드하여 정상적으로 검증 오류를 발생시키는지 test하는 부분이다.
-
준비(Preparing) : 클래스가 필요로하는 메모리를 할당하고, 클래스에서 정의된 필드, 메서드, 인터페이스들을 나타내는 데이터 구조를 준비한다.
-
분석(Resolving) : 클래스의 상수 풀 내 모든 simbolic reference를 direct reference로 변경한다.
-
초기화(Initializing) : 클래스 변수들을 적절한 값으로 초기화한다. 즉, static initalizer들을 수행하고, static field들을 설정된 값으로 초기화한다.
Runtime Data Area

런타임 데이터 영역은 JVM이라는 프로그램이 운영체제 위에서 실행되면서 할당받은 메모리 영역이다. 런타임 데이터 영역은 6개의 영역으로 나눌 수 있다. 이 중에 PC Register, JVM Stack, Native Method Stack은 스레드마다 하나씩 생성되며 Heap, Method Area, Runtime Constant Pool은 모든 스레드가 공유하여 사용한다.
예전에 게시한 메모리 구조를 미리 읽고 참고하면 조금 도움 될 수 있다.
메모리 영역: 코드, 데이터, 힙, 스택 대해 (Feat. 스레드)
-
PC Register : PC(Program Counter) Register는 각 스레드마다 하나씩 존재하여 스레드가 시작될 때마다 생성된다. PC Register는 현재 수행중인 JVM 명령의 주소를 갖는다.
-
JVM Stack : JVM Stack은 각 스레드마다 하나씩 존재하며 스레드가 시작될 때 생성된다. 스택 프레임(Stack Frame)이라는 구조체를 저장하는 스택으로 JVM은 오직 JVM 스택에서 스택 프레임을 추가하고 push와 pop동작만 수행한다. 예외 발생 시 printStackTrace()등의 메서드로 보여주는 Stack Trace의 각 라인은 하나의 스택 프레임을 표현한다.
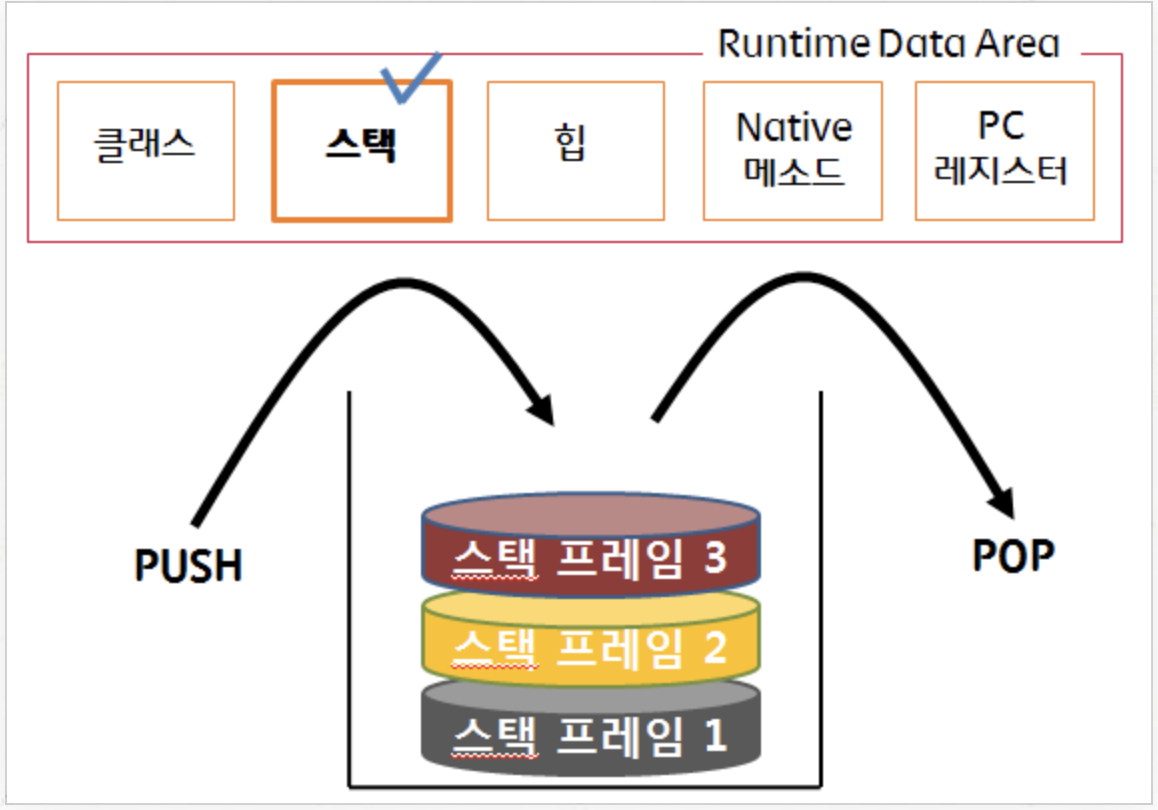
-
Stack Frame : JVM 내에 메서드가 수행될 때마다 하나의 스택 프레임이 생성되어 해당 스레드의 JVM 스택에 추가되고 메서드가 종료되면 스택 프레임이 제거된다. 각 스택 프레임은 지역 변수 배열이 추가되고, 메서드가 종료되면 스택 프레임이 제거가 된다. 각 스택 프레임은 지역 변수 배열(Local Variable Array), 피연산자 스택(Operand Stack), 현재 실행중인 메서드가 속한 클래스의 런타임 상수 풀에 대한 레퍼런스를 갖는다. 지역 변수 배열, 피연산자 스택의 크기는 컴파일시에 결정되므로 스택 프레임 크기도 메서드에 따라 크기가 고정된다.
-
Local Variable Array : 0부터 시작하는 index를 가진 배열이다. 0은 메서드가 속한 클래스 인스턴스의 this 레퍼런스이고, 1부터는 메서드에 전달된 파라미터들이 저장되며, 메서드 파라미터 이후에는 메서드의 지역변수들이 저장된다.
-
Operand Stack : 메서드의 실제 작업 공간이다. 각 메서드는 피연산자 스택과 지역변수 배열 사이에서 데이터를 교환하고, 다른 메서드 호출 결과를 push 또는 pop 한다. 피연산자 스택 공간이 얼마 나 필요한지는 컴파일 시점에서 결정한다.
-
Native Method Stack : 자바 외의 언어로 작성된 네이티브 코드를 위한 스택이다. 즉, JNI(Java Native Interface)를 통해 호출하는 C/C++ 등의 코드를 수행하기 위한 Stack이며, 언어에 맞게 C Stack 이나 C++ Stack이 생성된다.
-
Method Area : 메서드 영역은 모든 스레드가 공유하는 영역으로 JVM이 시작될 때 생성된다. JVM이 읽어 들인 각각의 클래스와 인터페이스에 대한 런타임 상수 풀, 필드와 메서드 정보, Static 변수, 메서드의 바이트 코드등을 보관한다. 흔히 Permanent Area 또는 Permanent Generation(PermGen)이라고 불린다. 메서드 영역에 대한 GC는 JVM 벤더의 선택 사항이다.
-
Rumtime Constant Pool : 클래스 파일 포맷에서 constant_pool 테이블에 해당하는 영역이다. 메서드 영역에 포함되는 영역이지만, JVM 동작에서 가장 핵심적인 역할을 수행하는 곳이기 때문에 JVM 명세에서도 중요하게 기술한다. 각 클래스와 인터페이스의 상수 뿐만 아니라, 메서드와 필드에 대한 모든 reference를 담고 있는 테이블이다. 즉, 어떤 메서드나 필드를 참조할 때 JVM은 런타임 상수 풀을 통해 해당 메서드나 필드의 실제 메모리상 주소를 찾아내서 참조한다.
-
Heap : 인스턴스 또는 객체를 저장하는 공간으로 GC의 대상이다. JVM 성능 등의 이슈에서 가장 많이 언급되는 공간이다. 힙 구성 방식이나 가비지 컬렉션 방법등은 JVM 벤더의 재량이다.
다시 앞에서 살펴본 역어셈블(javap)된 바이트코드로 되돌아 가보자
public void add(java.lang.String);
Code:
0: aload_0
1: getfield #15; //Field admin:Lcom/nhn/user/UserAdmin;
4: aload_1
5: invokevirtual #23; //Method com/nhn/user/UserAdmin.addUser:(Ljava/lang/String;)Lcom/nhn/user/User;
8: pop
9: return
이렇게 역어셈블된 코드와 가끔 우리가 접할 수 있는 x86 아키텍처의 어셈블리 코드를 비교해보면, 비록 Opcode(피연산자)라는 형식은 유사해보이지만, 피연산자에 레지스터 이름이나 메모리 주소나 offset을 쓰지 않는 다는 차이점을 확인할 수 있다. 앞에서 설명했듯이 JVM은 스택을 사용하므로 레지스터를 사용하는 x86 아키텍쳐와 다르게 레지스터를 사용하지 않고 또한 자체적으로 메모리를 관리하므로 실제 메로리 주소 대신 15,23같은 인덱스 번호를 사용하는 것이다. 이 15, 23은 현재 클래스(여기서는 UserService 클래스)가 가지는 상수 풀의 인덱스이다. 즉, JVM은 각 클래스마다 상수 풀을 생성하며, 실제 대상의 레퍼런스를 보관하고 있다.
위의 역어셈블된 코드의 각 줄을 간단히 번역하면 다음고 같다.
- aload_0: 지역 변수 배열의 0번 인덱스 내용을 피연산자 스택에 추가한다. 지역 변수 배열의 0번 인덱스는 언제나 this, 즉 현재 클래스 인스턴스에 대한 레퍼런스이다.
- getfield #15: 현재 클래스 상수 풀에서 15번 인덱스 내용을 피연산자 스택에 추가한다. 즉, UserAdmin admin 필드가 추가된다. admin 필드는 클래스 인스턴스이므로 레퍼런스가 추가된다.
- aload_1: 지역 변수 배열의 1번 인덱스 내용을 피연산자 스택에 추가한다. 지역 변수 배열의 1번 인덱스부터는 메서드 파라미터이다. 즉, add()를 호출하면서 전달한 String userName의 레퍼런스가 추가된다.
- invokevirtual #23: 현재 클래스 상수 풀에서 23번 인덱스 내용에 해당하는 메서드를 호출한다. 이때 앞서 getfield로 추가한 레퍼런스와 aload_1로 추가한 파라미터를 모두 꺼내서 호출하는 메서드에 전달한다. 메서드 호출이 완료되면 그 반환값을 피연산자 스택에 추가한다.
- pop: invokevirtual로 호출한 결과 반환값이 피연산자 스택에 들어가 있으므로 스택에서 꺼낸다. 예전 라이브러리로 컴파일한 코드에서는 이 부분이 없음을 확인할 수 있다. 즉, 예전 라이브러리에서는 반환값이 없으므로 반환값을 스택에서 꺼낼 필요가 없었다.
- return: 메서드를 완료한다.
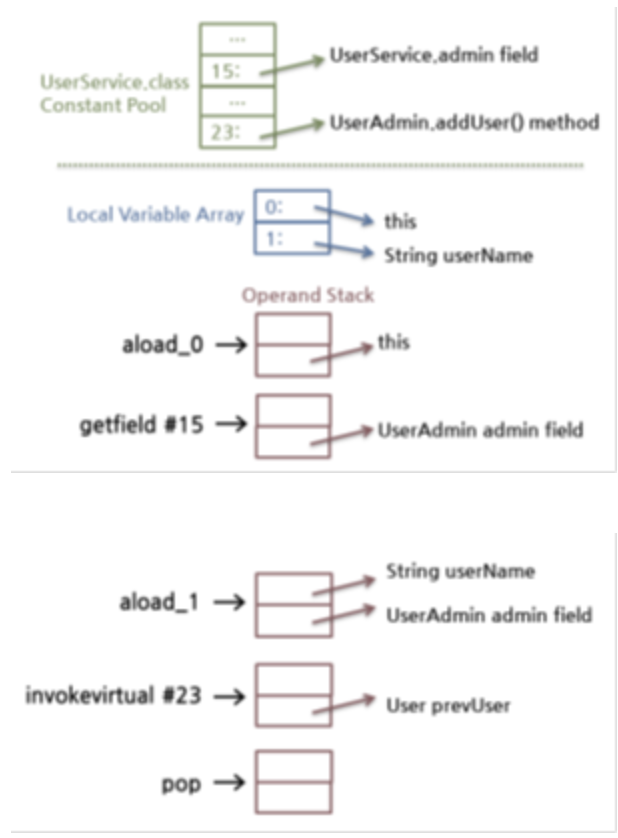
참고로 이 메서드에서는 지역 변수 배열이 변경되지 않았으므로 위 그림은 피연산자 스택 변경만 표시했다. 그러나 대부분의 경우 지역 변수 배열도 함께 변경된다. 지역 변수 배열과 피연산자 스택 간의 데이터 전달은 수많은 load(aload, iload 등) 및 store(asotre, istore 등) 명령어로 이뤄진다.
이 그림에서는 런타임 상수 풀과 JVM 스택의 내용만 간략하게 확인했다. 실제 동작에서는 각각의 클래스 인스턴스들이 힙에 할당되고, User, UserAdmin, UserService, String 등의 클래스 정보가 메서드 영역에 보관될 것이다.
Execution Engine
클래스 로더를 통해 JVM 내의 런타임 데이터 영역에 배치된 바이트코드는 실행 엔진에 의해 실행된다. 실행 엔진은 자바 바이트코드를 명령어 단위로 끊어 읽어 실행된다. CPU가 기계 명령어를 하나씩 실행하는 것과 비슷하다. 바이트코드는 각 명령어는 1byte짜리 OpCode와 추가 피연산자로 이루어져 있으며, 실행 엔진은 하나의 OpCode를 가져와서 피연산자와 함께 작업을 수행한 다음, 다음 OpCode를 수행하는 식으로 동작한다.
그런데 자바 바이트 코드는 기꼐어가 바로 수행할 수 있는 언어보다는 비교적 인간이 보기 편한 현앹로 기술된 것이다. 그래서 Execution Engine은 이와 같은 바이트코드를 실제로 JVM 내부에서 기계가 실행할 수 있는 형태로 변경하며, 그 방식은 2가지가 있다.
-
인터프리터 : 바이트코드 명령어를 하나씩 읽어서 해석하고 실행한다. 하나씩 해석하고 실행하기 때문에 바이트코드 하나하나의 해석은 빠른데 인터프리팅 결과의 실행은 느리다는 단점을 가지고 있다. 흔히 얘기하는 인터프리터 언어의 단점을 가지는 것이다. 즉, 바이트코드라는 언어는 기본적으로 '인터프리터 방식'으로 동작한다.
-
JIT(Just-In-Time) 컴파일러 : 인터프리터의 단점을 보완하기 위해 도임된 것으로 JIT 컴파일러이다. 인터프리터 방식으로 실행하다가 적절한 시점에 바이트코드 전체를 컴파일하여 네이티브 코드로 변경하고, 이후에는 해당 메서드를 더이상 인터프리팅하지 않고 네이티브 코드로 직접 실행하는 것이다. 네이티브 코드를 실행하는 것이 하나씩 인터프리팅하는 것보다 빠르고, 네티티브 코드는 캐시에 보관하기 때문에 한 번 컴파일 된 코드는 계속 빠르게 수행되게 한다.
JIT 컴파일러가 컴파일하는 과정은 바이트코드를 하나씩 인터프리팅하는 것보다 훨씬 오래 걸린다. 그래서 만약 한번만 실행되는 코드일 경우에는 굳이 컴파일 하지 않고 인터프리팅 방식으로 하는것이 유리하다. JIT 컴파일러를 사용하는 JVM들은 내부적으로 해당 메서드가 얼마나 자주 수행되는지 체크하고, 일정 정도를 넘었을 때만 컴파일을 수행한다.
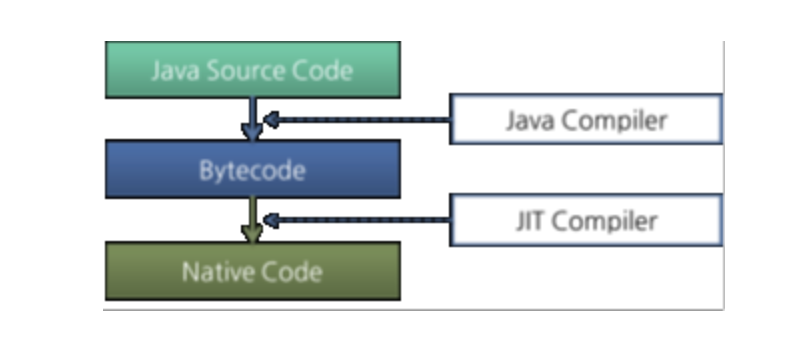
실행 엔진이 어떻게 동작하는지 JVM 명세에 규정되지 않고 있다. 따라서 JVM 벤더들은 다양한 기법으로 실행 엔진을 향상시키고 다양한 방식의 JIT 컴파일러를 도입하고 있다.
대부분 JIT 컴파일러는 다음과 같은 형태로 동작한다.
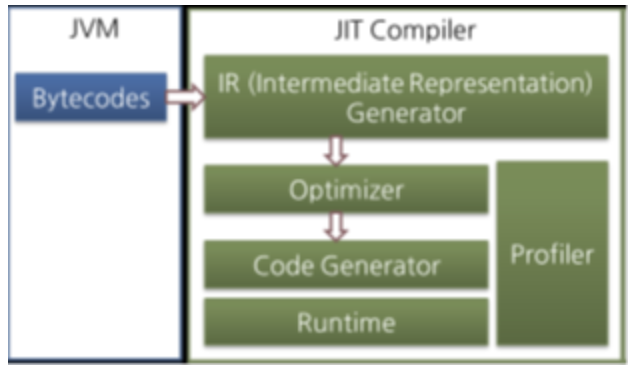
JIT 컴파일러는 바이트코드를 일단 중간 단계의 표현인 IR(Intermediate Representation)로 변환하여 최적화를 수행하고 그 다음에 네이티브 코드를 생성한다.
Oracle Hotspot VM은 핫스팟 컴파일러라고 불리는 JIT 컴파일러를 사용한다. 핫스팟이라고 불리는 이유는 내부적으로 프로파일링을 통해 가장 컴파일이 필요한 부분, 즉 '핫스팟'을 찾아낸 다음, 이 핫스팟을 native code로 컴파일하기 때문이다. 핫스팟 VM은 한번 컴파일된 바이트코드라도 해당 메서드가 더 이상 자주 불리지 않는다면 cache에서 native code를 덜어내고 다시 인터프리터 방식으로 동작한다. 핫스팟 VM은 서버 VM과 클라이언트 VM으로 나뉘어져있고, 각각 다른 JIT 컴파일러를 사용한다.
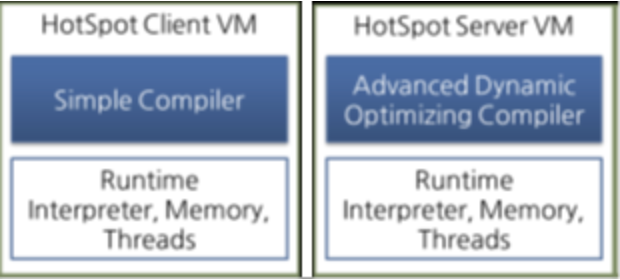
클라이언트 VM과 서버 VM은 각각 오라클 핫스팟 VM을 실행할 때 입력하는 -client, -server 옵션으로 실행된다. 클라이언트 VM과 서버 VM은 동일한 런타임을 사용하지만, 위 그림과 같이 다른 JIT 컴파일러를 사용한다. 서버 VM에서 사용하는 Advanced Dynamic Optimizing Compiler가 더 복잡하고 다양한 성능 최적화 기법을 사용하고 있다.
IBM JVM은 JIT 컴파일러뿐만 아니라 IBM JDK 6부터 AOT(Ahead-Of-Time) 컴파일러라는 기능을 도입했다. 이는 한번 컴파일된 네이티브 코드를 여러 JVM이 공유 캐시를 통해 공유해서 사용하는 것을 의미한다. 즉, AOT 컴파일러를 통해 이미 컴파일된 코드는 다른 JVM에서도 컴파일하지 않고 사용할 수 있게 하는 것이다. 또한, 아예 AOT 컴파일러를 이용하여 JXE(Java EXecutable)라는 파일 포맷으로 프리컴파일(pre-compile)된 코드를 작성하여 빠르게 실행하는 방법도 제공하고 있다.
자바 성능 개선의 많은 부분은 바로 이 실행 엔진을 개선하여 이뤄지고 있다. JIT 컴파일러는 물론 다양한 최적화 기법을 도입하여 JVM의 성능은 계속해서 향상되고 있다. 초창기 JVM과 지금의 JVM은 이 실행 엔진에서 큰 차이가 있다.
오라클 핫스팟 VM은 1.3부터 핫스팟 컴파일러를 내장하기 시작하였고, 안드로이드 Dalvik VM은 안드로이드 2.2부터 JIT 컴파일러를 도입하였다.
The Java Virtual Machine Specification, Java SE 7 Edition
지난 2011년 7월 28일 오라클은 Jave SE 7을 발표하면서 JVM 명세도 자바 SE 7 버전으로 업데이트하여 발표하였다. 1999년 "The Java Virtual Machine Specification, Second Edition"을 발표한 이후 무려 12년 만에 개선판을 내놓은 것이다. 이 개선판은 12년 간 누적된 여러 변화와 수정 사항을 포함하고 있으며, 명세에 대해 더 명확하게 기술하고 있다. 또한 자바 SE 7과 함께 발표된 "The Java Language Specification, Java SE 7 Edition"의 내용도 반영하고 있다. 주된 변화를 간단히 요약하면 다음과 같다.
- 자바 SE 5.0부터 도입된 Generics, 가변 인자 메서드 지원
- 자바 SE 6부터 변화된 바이트코드 검증 프로세스 기술
- 동적 타입 언어 지원을 위해 invokedynamic 명령어 및 관련 클래스 파일 포맷 추가
- 자바 언어 자체의 개념에 대한 내용을 삭제하고, 자바 언어 명세에서 찾도록 유도
- 자바 Thread와 Lock에 대한 내용을 삭제하고, 자바 언어 명세로 내용을 넘김
참고
Java Performance Fundamental-김한도
Oracle-java Documentation
D2-JVM Internal
