
검색 알고리즘
- 배열 검색
1) 선형 검색 : 무작위로 늘어놓은 데이터 모임에서 검색을 수행한다.
2) 이진 검색 : 일정한 규칙으로 늘어놓은 데이터 모임에서 아주 빠른 검색을 수행한다.
3) 해시법 : 추가, 삭제가 자주 일어나는 데이터 모임에서 아주 빠른 검색을 수행한다.- 체인법 : 같은 해시 값의 데이터를 선형 리스트로 연결하는 방법
- 오픈 주소법 : 데이터를 위한 해시 값이 충돌할 때 재해시하는 방법
- 선형 리스트 검색
- 이진 검색 트리
- 검색만 한다면 검색에 사용할 알고리즘은 계산시간이 짧은 것을 선택하면 된다.
- 데이터 추가, 삭제 등의 작업을 자주하는 경우라면 검색 이외의 작업에 소요되는 비용을 종합적으로 평가하여 알고리즘을 선택해야 한다.
- 이 장에서는 선형 검색과 이진 검색을 다룬다.
선형 검색
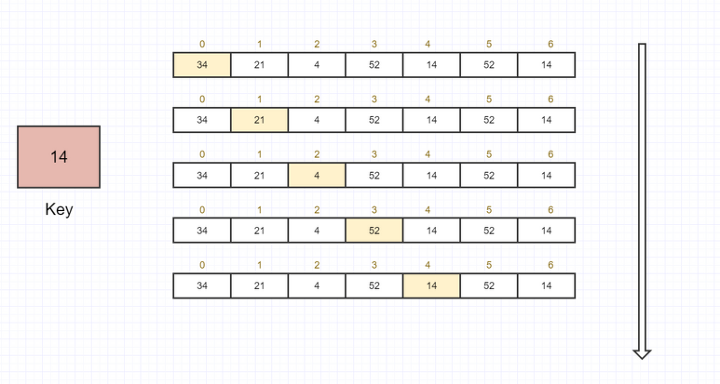
- 요소가 직선 모양으로 늘어선 배열에서의 검색은 원하는 키 값을 갖는 요소를 만날 때 까지 맨 앞부터 순서대로 요소를 검색하면 된다. 이것이 선형 검색이다.
핵심
- 검색할 값을 발견하지 못하고 배열의 끝을 지나간 경우 알고리즘을 종료한다.
- 검색할 값과 같은 요소를 발견한 경우 알고리즘을 종료한다.
- 검색할 값을 배열의 끝에 덧붙이면 2번만으로 알고리즘을 작성할 수 있다. 또한 비용이 절반으로 줄어든다. 이를 보초법이라고 한다.
int x = 검색할 배열;
int n = 배열 길이;
int key = 검색할 값;
int answer = 0; // 결과값
// 여기까지 공통 요소
int i = 0;
while(true) {
if (i == 0)
answer = -1;
break;
}
else (a[i] == key)
answer = i
break;
}
i++;
}
// 보초법을 사용하면 다음처럼 된다.
a[n] = key;
while(true){
if (a[i] == key) // if문 하나 사라짐 -> 비용 절반으로 감소
break;
i++;
}
answer = i == n ? -1 : i;이진 검색

- 요소가 오름차수 또는 내림차순으로 '정렬된' 배열에서 검색하는 알고리즘이다.
핵심
- 배열이 정렬되어 있어야한다.
- 검색할 값이 중앙에 있는 값보다 크다면 오른쪽 절반을, 중앙에 있는 값보다 작다면 왼쪽 절반을 보는 과정을 반복한다.
- a[pc]와 key가 일치하는 경우 알고리즘 종료
- 검색 범위가 더 이상 없는 경우 알고리즘 종료
int x = 검색할 배열;
int n = 배열 길이;
int key = 검색할 값;
int answer = 0; // 결과값
int pl = 0; // 검색 범위의 첫 인덱스
int pr = n - 1; // 검색 범위의 끝 인덱스
answer = -1;
do {
int pc = (pl + pr) / 2 // 중앙요소의 인덱스
if (a[pc] == key) {
answer = pc;
break;
}
else if (a[pc] < key) {
pl = pc + 1;
else
pr = pc - 1;
} while(pl <= pr);복잡도
- 시간 복잡도 : 실행에 필요한 시간을 평가한 것
- 공간 복잡도 : 기억 영역과 파일 공간이 얼마나 필요한 것을 평가한 것
- 두 복잡도의 균형이 중요하다.
- 선형 검색의 시간 복잡도 : O(n)
- 이진 검색의 시간 복잡도 : O(log n)
Arrays.binarySearch에 의한 이진 검색
- Java는 배열에서 이진 검색을 하는 메서드를 표준 라이브러리로 제공한다.
- 모든 자료형 배열에서 사용 가능하다.
static int binarySearch(Object[] a, Object key)
- 자연 정렬이라는 방법으로 요소의 대소관계를 판단한다.
- java.util.Arrays를 import한 후 Arrays.binarySearch(배열, 검색값);으로 사용하면 된다.
- 검색에 성공하면 반환값은 검색값의 인덱스이다.
- 검색에 실패하면 삽입 포인트를 x라고 할 때 - x - 1을 반환한다. 삽입 포인트는 검색값보다 큰 요소 중 첫번째 요소의 인덱스이다. ex) [1, 2, 3, 5, 6]에서 Key가 4일 때 삽입 포인트는 3이므로 -4를 반환한다.
- 배열의 모든 요소가 검색값보다 작으면 배열의 길이가 삽입 포인트가 된다.
static <T> int binarySearch(T[] a, T key, Comparator<? super T> c)
- 자연 순서가 아닌 순서로 줄지어 있는 배열에서 검색하거나, 자연 순서를 논리적으로 갖지 않는 클래스 배열에서 검색할 때 사용한다.
- 정렬되어 있지만 추가적인 정렬 정보가 필요할 때 사용하면 되는 것으로 보인다. 그리고
Comparator<? super T\> c가 그 역할을 한다. <? extends T>는 클래스 T의 서브 클래스를 전달받는다는 의미이고,<? super T\>는 클래스 T의 슈퍼블래스를 전달받는다는 의미이다.
class X {
public static final Comparator<T> COMPARATOR = new Comp();
private static class Comp implements Comparator<T> {
public int compare(T d1, Td2) {
// d1이 d2보다 크면 양의 값 반환
// d1이 d2보다 작으면 음의 값 반환
// d1이 d2와 같으면 0 반환
}
}
}- 정렬 정보를 위처럼 클래스로 선언한 후 Arrays.binarySearch(배열, 검색할 값, X.COMPARATOR)로 호출하면 된다.

do for me