
Netwhat
Netwhat 기출문제를 풀기 위한 네트워크 개념 잡기
IP address
1. Network란?
네트워크는 Net + Work 의 합성어로 두 대 이상의 컴퓨터가 논리적 또는 물리적으로 그물망처럼 연결되어 통신이 가능한 상태를 말한다.
네트워크의 종류 :
- PAN (Personal Area Network)
- LAN (Local Area Network)
- MAN (Metropolitan Area Network)
- WAN (Wide Area Network)
- VAN (Value Added Network)
- ISDN (Integrated Services Digital Network)
2. IP (Internet Protocol) address란?
컴퓨터 네트워크에서 장치들이 서로를 인식하고 통신을 하기 위해 사용하는 특수한 주소이다. 네트워크에 연결된 장치가 라우터이든 일반 서버이든, 모든 기계는 이 특수한 주소를 가지고 있어야 한다. 네트워크 상에서 통신을 하기 위해서는 몇 가지 통신규약 (protocol)을 따라야 한다. IP 주소는 network ID 부분과 host ID 부분으로 구성되어 있으며 하나의 네트워크 안에서 network 영역이 같아야 하고 host 영역은 서로 달라야 통신이 가능하다.
IPv4 (IP version 4) :
오늘날 일반적으로 사용하는 IP 주소이다. 32bit로 구성되어 있으며 4개의 10진수를 .으로 구분하여 0.0.0.0 ~ 255.255.255.255의 범위를 갖는다. 중간의 일부 번호들은 특별한 용도를 위해 사용된다. 이를테면 127.0.0.1은 로컬 호스트 자기 자신을 가리킨다.
IPv6 (IP version 6) :
IP 주소의 부족 현상을 해결하기 위한 차세대 IP 주소 체계이다. IPv4의 주소 공간을 확장한 것으로 128bit 체계의 16진수로 표기하며 4개의 16진수를 콜론(:)으로 구분한다.
3. IP 주소 클래스
IP 주소에는 클래스라는 개념이 있고 이 개념을 알아야 어디까지가 네트워크 영역이고 호스트 영역인지 알 수 있다. 즉, 클래스는 하나의 IP 주소에서 네트워크 영역과 호스트 영역을 나누는 방법이자, 약속이다.
클래스 별 범위 :
| 클래스 | 고정 비트 | 범위 |
|---|---|---|
| A | 0 | 0.0.0.0 ~ 127.255.255.255 |
| B | 10 | 128.0.0.0 ~ 191.255.255.255 |
| C | 110 | 192.0.0.0 ~ 223.255.255.255 |
| D (멀티캐스트) | 1110 | 224.0.0.0 ~ 239.255.255.255 |
| E (예약됨) | 1111 | 240.0.0.0 ~ 255.255.255.255 |
클래스 A :
IP 주소를 2진수로 표기했을 때 맨 앞자리 수가 항상 0이며 하나의 네트워크가 가질 수 있는 호스트 수가 가장 많은 클래스이다. 주로 국가나 대형 네트워크에서 사용한다.
클래스 A의 네트워크 주소는 10진수로 1.0.0.0 ~ 127.0.0.0의 범위를 갖기 때문에 1 ~ 127으로 시작하는 IP 주소는 클래스 A라고 보면 된다.
호스트 주소의 갯수는 0.0.0 (2진수로 모두가 0인 경우) 은 네트워크 주소로 사용되고 255.255.255 (2진수로 모두가 1인경우) 은 브로드캐스트 주소로 사용되기 때문에 이 2가지 주소를 제외한 ((2^24) - 2) 개 이다.
클래스 B :
IP 주소를 2진수로 표기했을 때 맨 앞자리 수가 항상 10이어야 한다. 주로 중대형 네트워크에서 사용한다.
네트워크 주소 범위는 10xx xxxx. xxxx xxxx 에서 x들이 가질 수 있는 경우의 수, 2^14 개 이다.
호스트 주소 범위는 xxxx xxxx. xxxx. xxxx 에서 x들이 가질 수 있는 경우의 수, `((2^16) - 2) 개 이다.
클래스 C :
IP주소를 2진수로 표기했을 때 맨 앞자리 수가 항상 110이어야 한다. 주로 소형 네트워크에서 사용한다.
네트워크 주소 범위는 110x xxxx. xxxx xxxx. xxxx xxxx 에서 x들이 가질 수 있는 경우의 수, 2^21 개 이다.
호스트 주소 범위는 xxxx xxxx 에서 x들이 가질 수 있는 경우의 수, ((2^8) - 2) 개 이다.

Netmask & Subnetmask
1. Netmask
네트워크 주소 부분의 비트를 모두 1로 치환한 것으로 IP 주소와 AND연산을 하게되면 네트워크 주소를 얻을 수 있다.

2. Subnet
IP 주소의 공간 낭비 문제를 해결하기 위해 서브넷이라는 개념을 이용한다. 하나의 네트워크를 쪼개 만든 네트워크로써 즉, 하나의 네트워크는 여러 서브넷으로 나뉠 수 있다. 서브넷으로 나눠서 관리하는 이유는 보안, 관리, 속도, 성능 면에서 이점이 있기 때문이다.
3. Subnetmask
IPv4의 서브넷마스크는 IP 주소와 같이 32비트의 2진수의 형태로 되어 있지만 IP 주소와 달리 클래스 개념이 없고 앞에서부터 순차적으로 1씩 증가한다. 형태가 같은 이유는 IP 주소와 서브넷마스크를 AND연산하기 위해서이다. 서브넷마스크는 네트워크 영역과 호스트 부분을 구분해주는 역할을 한다.
IP를 클래스로 나눈다는 것은, 결국 서브넷마스크를 사용한다는 것과 같은 말이다. 예를 들어 C클래스를 그대로 사용한다는 것은 C클래스 네트워크를 쪼개지 않고 그대로 하나의 네트워크에 할당할 수 있는 ((2^8) - 2) 개의 호스트 ID를 사용하겠다는 뜻이고 이때는 255.255.255.0이 기본 서브넷마스크가 된다. 즉, 별개의 서브넷마스크를 생성하지 않아도 기본적으로 적용되어 있는 것이 기본 서브넷마스크이고, 기본 서브넷마스크로 쪼개진 네트워크 주소를 서브넷 네트워크라고 한다.
IP 클래스별 기본 서브넷마스크 :
| 클래스 | IP 주소 범위 | 서브넷 마스크 |
|---|---|---|
| A | 1.0.0.0 ~ 127.255.255.255 | 255.0.0.0 |
| B | 128.0.0.0 ~ 191.255.255.255 | 255.255.0.0 |
| C | 192.0.0.0 ~ 223.255.255.255 | 255.255.255.0 |
기본 서브넷마스크의 형태를 보면, 네트워크 부분의 비트만 1로 치환한 형태이다. 기본 서브넷마스크는 넷마스크라고도 할 수 있는 것이다.
요즘에는 뚜렷하게 넷마스크와 서브넷마스크를 구분하지 않는다. 왜냐하면 CIDR 이후(현재) 서브넷마스크만 쓰기 때문이다.
4. Network / Broadcast 주소
네트워크 주소
하나의 네트워크를 통칭하기 위한 주소로 해당 네트워크의 첫번째 IP 주소이다. 계산 방법은 IP 주소와 서브넷마스크의 AND연산을 하면 된다.
브로드캐스트 주소
특정 네트워크에 속하는 모든 호스트들이 갖게 되는 주소로 해당 네트워크에 속하는 모든 IP 주소 가운데 맨 마지막 IP 주소이다. 네트워크에 있는 클라이언트 모두에게 데이터를 보내기 위해 존재한다. 계산 방법은 서브넷마스크의 0인 부분을 1로 바꾸면 된다.
참고 : 보통 라우터 주소는 네트워크 주소와 브로드캐스트 주소, 이 둘을 제외한 호스트 범위 중 가장 앞의 주소일 가능성이 높다.
5. Subnetting
IP 주소 낭비를 막기위해 원본 네트워크를 서브넷마스크를 이용하여 여러 개의 서브넷 네트워크로 나누는 작업이다. IP를 사용하는 네트워크 장치들의 수에 따라 효율적으로 사용할 수 있도록 하는 것이다.
예시로 클래스 A의 IP 주소 1.1.1.1의 기본 서브넷마스크 255.0.0.0을 클래스 B의 서브넷마스크 255.255.0.0으로 변경해보자. 변경된 서브넷마스크로 AND연산을 하게되면 네트워크 ID가 1.0.0.0에서 1.1.0.0으로 확장된다. 반대로 호스트의 범위는 기존의 0.0.0.0 ~ 0.255.255.255 (약 16,777,216개) 에서 0.0.0.0 ~ 0.0.255.255 (약 65,534개)로 훨씬 적어졌음을 알 수 있다.
다른 예시 :

참고 : 도메인 네임(DOMAIN NAME)
- 사용자들이 쉽게 인식하고 사용할 수 있도록 숫자로 표기된 IP 주소를 문자 형태로 표시하는 인터넷 주소
예 : www(호스트).sample(기관명).co(소속기관 종류).kr(소속국가)- DNS : 도메인 네임을 IP 주소로 변경해주는 작업 수행
Subnetting 특징
-
서브네팅을 통해 네트워크 ID가 확장되므로 인해 할당될 수 있는 네트워크의 수가 늘어난다. 하지만 네트워크가 분리됨으로 서로가 통신하기 위해서는 라우터를 통해서만 가능하다. 물론 같은 네트워크에 속해 있는 호스트들은 라우터를 거치지 않고 통신이 가능하다.
-
특정 몇 군데의 호스트에서 너무 많은 트래픽을 발생시켜서 속도를 저하시키는 문제를 해결할 수 있다. 이는 서브네팅을 통하여 네트워크가 분리되기 때문에 브로드캐스트 도메인의 크기가 줄어들게 되므로 가능한 일이다. (브로드캐스트 주소가 다양해짐)
참고 : 서브넷의 브로드캐스트 주소란?
- 서브넷의 브로드캐스트 주소는 255보다 훨씬 작은 수를 가질 수 있게 된다. 한 브로드캐스트 주소를 너무 많은 호스트가 갖는 걸 방지할 수 있기 때문에 트래픽 문제를 해결할 수 있는 것이다.
Subnetting 계산
서브넷마스크는 2진수로 표기했을 때 네트워크 ID 부분은 1이 연속적으로 있어야하고, 호스트 ID 부분은 0이 연속적으로 있어야 한다. 즉, 중간에 1이나 0이 섞이면서 나열될 수 없다. 이로 인해 서브넷마스크가 네트워크 ID를 확장하면서 1비트씩 확보하게 되면 네트워크 할당 가능 수가 2배로 증가하고 반대로 호스트 할당 가능 수가 2배로 줄어들게 된다.
서브넷마스크에서 호스트 영역의 범위 구하기 :
- 최솟값 : 서브넷마스크의 호스트 영역 전부 0이 되는 값 (네트워크 주소)
- 최댓값 : 서브넷마스크의 호스트 영역 전부 1이 되는 값 (브로드캐스트 주소)
- 범위 : 최솟값 ~ 최댓값 (네트워크 주소와 브로드캐스트 주소 제외하기!)
194.139.10.7/25라는 IP를 서브네팅 하는 예시 :
| 서브네팅 | IP 주소 | 할당 객체 |
|---|---|---|
| 194.139.10.0/25 | 194.139.10.0 | 네트워크 주소 |
| 194.139.10.1 ~ 194.139.10.126 | 호스트 IP | |
| 194.139.10.127 | 브로드캐스트 주소 | |
| 194.139.10.128/25 | 194.139.10.128 | 네트워크 주소 |
| 194.139.10.129 ~ 194.139.10.254 | 호스트 IP | |
| 194.139.10.255 | 브로드캐스트 주소 |
6. CIDR
CIDR(Classless Inter-Domain Routing)은 클래스로만 구분된 네트워크의 한계를 극복하기 위한 수단으로 개발되었다. 기존의 클래스만을 이용하면 서브넷마스크는 8자리 단위로만 끊기게 되어 낭비되는 것이 많은 반면 CIDR을 이용하면 네트워크 ID로 사용하는 범위를 자유롭게 표기할 수 있게 되어 네트워크를 조금 더 세부적인 단위로 쪼갤 수 있다. 서브넷과 CIDR은 결국 네트워크를 자른다는 의미는 같지만 CIDR은 특수한 표기법을 따른다.
예시 :
192.168.0.1 (주소)
255.255.255.0 (서브넷마스크)
이런 서브넷마스크를 갖는 주소는 CIDR로 표기하면
192.168.0.1/24 가 된다.
/ 뒤에 적힌 숫자는 몇 개의 비트가 네트워크 ID로서 유효한지를 의미한다. 기존의 클래스로만 구분한다면 뒤에 따라오는 숫자는 8, 16, 24정도였겠지만 CIDR에서는 17,25 등으로로 표기할 수 있다.
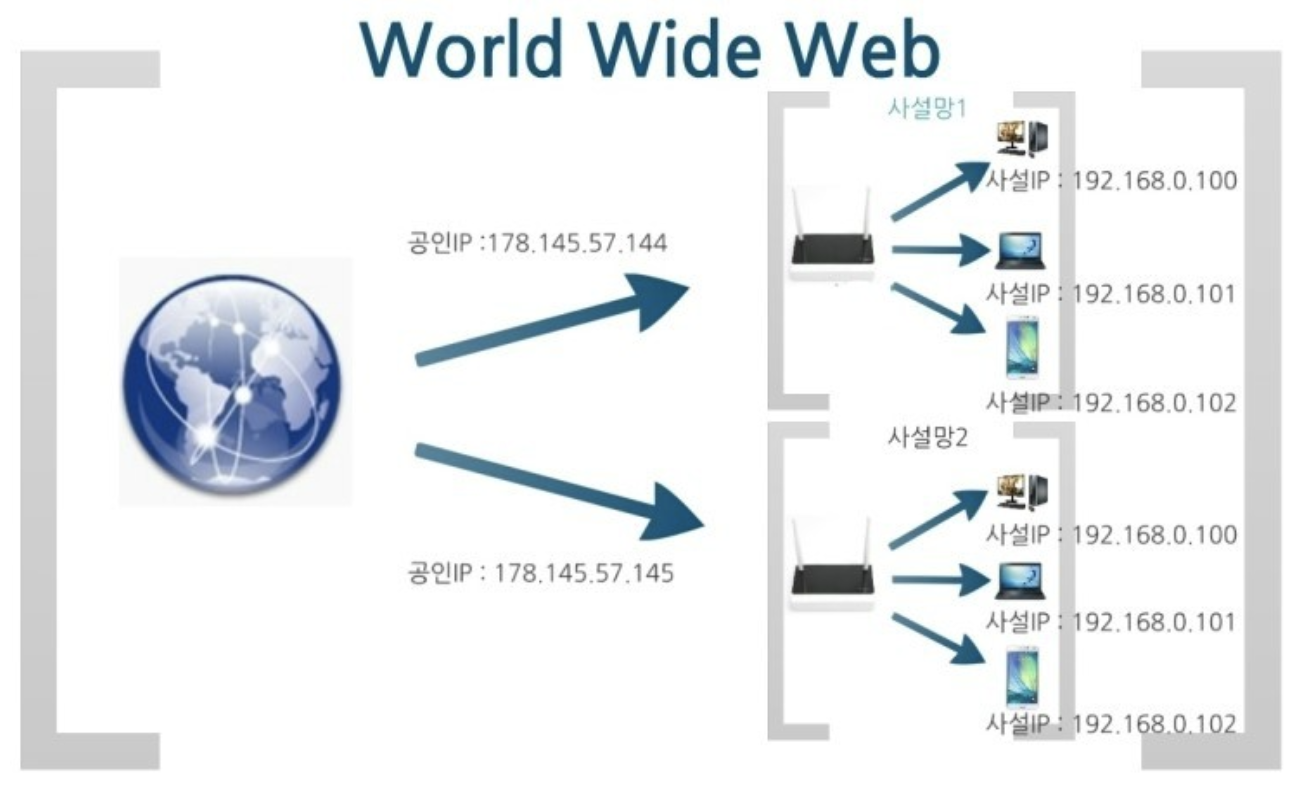
공인(Public) & 사설(Private) IP
1. 공인 IP
인터넷 사용자의 로컬 네트워크를 식별하기 위해 ISP(인터넷 서비스 공급자)가 제공하는 IP주소이다. 공용 IP주소라고도 불리며 외부에 공개되어 있는 IP 주소이다.
- 공인 IP는 전 세계에서 유일한 IP 주소를 갖는다.
- 공인 IP 주소가 외부에 공개되어 있기에 인터넷에 연결된 다른 PC로부터의 접근이 가능하다. 따라서 공인 IP 주소를 사용하는 경우 방화벽 등의 보안 프로그램을 설치할 필요가 있다.
2. 사설 IP
일반 가정이나 회사 내 등에 할당된 네트워크의 IP 주소이며, 로컬 IP, 가상 IP라고도 한다. IPv4의 주소 부족으로 인해 서브넷팅된 IP이기 때문에 라우터에 의해 로컬 네트워크 상의 PC나 장치에 할당된다.
사설 IP 주소 대역 :
| 클래스 | 범위 |
|---|---|
| A | 10.0.0.0 ~ 10.255.255.255 |
| B | 172.16.0.0 ~ 172.31.255.255 |
| C | 192.168.0.0 ~ 192.168.255.255 |
3. 공인 IP와 사설 IP의 차이점
공인 IP 주소는 어떠한 네트워크가 갖는 고유한 주소이고 사설 IP 주소는 하나의 네트워크 안에서 주어지는 상대적인 주소이다. 비유로 예를 들자면, 집 주소로 xx시 xx구 xx로 xx동 xx호는 어디서 보든 한 곳을 가리키는 공인 주소이지만, 단순히 101호, 302호 같은 형태의 주소는 어떤 건물인지, 어떤 구인지 등에 따라 상대적이다. 이것이 사설 IPv4라고 볼 수 있다.
이런 개념의 탄생 배경은 IPv4가 할당할 수 있는 네트워크 수가 고갈되고 있고, 지금은 과거와 비교해 무수히 많은 기기가 인터넷에 접근해야 하기 때문이다. 그래서 많은 부분을 각설하고 모두가 익숙한 와이파이의 개념으로 풀어보자면 공인 IP는 라우터의 주소, 사설 IP는 그 라우터에 연결된 각각의 기기의 주소이다. 이렇게 하면, 우리 집에는 하나의 네트워크만이 연결되지만, 그 안에는 많은 기기가 고유한 주소를 가진 채로 그 네트워크를 통해 다른 네트워크와 소통할 수 있는 것이다. 단, 다른 집의 다른 네트워크와 컴퓨터가 내 컴퓨터와 동일한 사설 IP를 가질 수 있다. 물론 그 두 컴퓨터의 공인 IP는 각자 라우터가 받아오는 네트워크의 주소이기 때문에 다르다.
| 공인 IP (Public IP) | 사설 IP (Private IP) | |
|---|---|---|
| 할당 주체 | ISP (인터넷 서비스 공급자) | 라우터 (공유기) |
| 할당 대상 | 개인 또는 회사의 서버 (라우터) | 개인 또는 회사의 기기 |
| 고유성 | 인터넷 상에서 유일한 주소 | 하나의 네트워크 안에서 유일 |
| 공개 여부 | 내/외부 접근 가능 | 외부 접근 불가능 |
참고 : 사설 IP 주소만으로는 인터넷에 직접 연결할 수 없다. 라우터를 통해 1개의 공인(Public) IP만 할당하고, 라우터에 연결된 개인 PC는 사설(Private) IP를 각각 할당 받아 인터넷에 접속할 수 있게 된다.
4. 고정 IP & 유동 IP
고정 IP는 컴퓨터에 고정적으로 부여된 IP로 한번 부여되면 IP를 반납하기 전까지는 다른 장비에 부여할 수 없는 IP 주소를 말한다.
유동 IP는 장비에 고정적으로 IP를 부여하지 않고 컴퓨터를 사용할 때 남아 있는 IP 중에서 돌아가면서 부여한는 IP이다.
인터넷 상에서 서버를 운영하고자 할 때는 공인 IP를 고정 IP로 부여해야 한다. 즉, 공인 IP를 부여받지 못 한다면 다른 사람이 내 서버에 접속할 수 없고, 고정 IP를 부여하지 않으면 내 서버가 아닌 다른 사람의 서버로 접속이 될 수도 있기 때문이다.
반면에 우리가 집에서 사용하는 인터넷 서비스 업체는 각 가정마다 공인 IP를 유동 IP로 부여하고, 공유기 내부에서는 사설 IP를 유동 IP로 부여하는 것이 일반적이다.
OSI 7계층
네트워크는 워낙 방대하고 복잡한 과정을 거치기 때문에 하나의 규정 아래 모든 과정을 욱여넣는 것이 아니라 역할에 따른 여러 계층으로 나누어 정리한다. 이렇게 하면 통신 중 문제가 발생할 때 문제가 일어나는 부분만을 살펴보면 되니 유용하다.
계층을 나누어 정리한 모델 중 하나인 OSI는 서로 다른 시스템 간의 원활한 네트워크를 위해 1997년 ISO에서 제안한 통신 규약이다. 네트워크 통신 과정을 7개의 계층으로 구분해 시스템의 복잡도를 최소화 한다.
1. 물리 계층
- 물리적 매체를 통한 전송 (하드웨어 전송)
- 프로토콜 : RS-232C, X.21, V.21, Modem, Cable, Fiber
- 장비 : 허브, 리피터
- PDU : 비트 (Bit)
참고 : PDU란?
- PDU는 Process Data Unit의 약자로 각 계층에서 전송되는 단위이다. 네트워크 통산과정을 깊게 이해하기 위해서는 왜 각각의 계층의 PDU가 다른지와 각각의 역할에 대해 알고 있어야 한다.
2. 데이터링크 계층
- 네트워크 기기들 사이의 데이터 전송
- 시스템 간 오류 없이 데이터 전송을 위해 패킷을 프레임으로 구성하여 물리계층으로 전송
- 3계층에서 정보를 받아 주소와 제어정보를 헤어와 테일에 추가
- 프로토콜 : HDLC, LAPB, PAPD, 이더넷, MAC, ATM, LAN, Wifi
- 장비 : 브릿지, 스위치
- PDU : 프레임 (Frame)
3. 네트워크 계층
- 기기에서 데이터그램이 가는 경로 설정
- 최적의 경로를 선택하여 패킷을 목적지까지 전송
- 데이터는 패킷 단위로 분할되어 전송 후 다시 합쳐짐
- 프로토콜 : IP, X.25, ICMP
- 장비 : 라우터, L3 스위치
- PDU : 패킷 (Packet)
4. 전송 계층
- 시스템 종단 간(발신지 to 목적지) 에러 관리
- 패킷의 전송이 유효한지 확인
- 전송에 실패한 패킷을 다시 보내는 것과 같은 신뢰성있는 통신을 보장
- 헤드에는 세그먼트 포함
- 전송 데이터의 다중화, 집중화, 주소 지정, 오류 및 흐름 제어
- 프로토콜 : TCP, UDP, ARP, RTP
- 장비 : 게이트웨이, L4 스위치
- PDU : 세그먼트 (segment)
5. 세션 계층
- 통신 시스템 간 상호작용, 동기화, 프로세스 간 동기 제어기능 수행
- 포트 번호를 기반으로 연결
- 동시 송수신 방식(duplex), 반이중 방식(half-duplex), 전이중 방식(Full Duplex)의 통신과 함께, 체크 포인팅과 유휴, 종료, 다시 시작 과정 등을 수행
- TCP/IP 세션을 만들고 없애는 책임을 짐
- 메시지 (message) 전송
- 프로토콜 : NetBIOS, SSH, TLS
6. 표현 계층
- 세션 계층에서 받은 데이터를 응용 계층에 적합한 형태로 변환
- 인코딩, 암호화, 압축, 코드 변환, 구문 검색 기능 수행
- 예 : EBCDIC로 인코딩된 문서 파일을 ASCII로 인코딩된 파일로 변환
- 메시지 (message) 전송
- 프로토콜 : JPG, MPEG, SMB, AFP
7. 응용 계층
- 사용자와 바로 연결되어 있음
- 사용자가 네트워크에 접근할 수 있도록 인터페이스와 서비스 제공
- 사용자로부터 정보를 입력받아 하위 계층으로 전달하고 하위 계층에서 전송한 데이터를 사용자에게 전달
- 파일 전송, DB, 메일 전송 등의 응용 서비스를 네트워크에 연결해주는 역할
- 메시지 (message) 전송
- 프로토콜 : DHCP, DNS, FTP, HTTP, HTTPS, SMTP, SSH, Telnet
TCP/IP
TCP/IP는 패킷 통신 방식의 인터넷 프로토콜인 IP(인터넷 프로토콜)와 전송 조절 프로토콜인 TCP(전송 제어 프로토콜)로 이루어져 있다. IP는 패킷 전달 여부를 보증하지 않고, 패킷을 보낸 순서와 받는 순서가 다를 수 있다. TCP는 IP 위에서 동작하는 프로토콜로, 데이터의 전달을 보증하고 보낸 순서대로 받게 해준다. 즉, 데이터의 정확성 확인은 TCP가, 패킷을 목적지까지 전송하는 일은 IP가 담당한다.
TCP/IP는 오늘날 인터넷에서 가장 많이 사용되는 표준 프로토콜이다. HTTP, FTP, SMTP 등 TCP를 기반으로 한 많은 수의 애플리케이션 프로토콜들이 IP 위에서 동작하기 때문에, 묶어서 TCP/IP로 부르기도 한다.
TCP
- 데이터의 전송 방법을 결정하는 프로토콜
- OSI 7계층 중
전송 계층에 해당하며 신뢰성 있는 연결형 서비스를 제공 - 패킷의 다중화, 순서 제어, 오류 제어, 흐름 제어 기능을 제공
IP
- 인터넷 상에서 각 호스트의 주소를 결정하는 프로토콜
- OSI 7계층 중
네트워크 계층에 해당하며 데이터그램 기반으로 하는 비연결성 서비스를 제공 - 패킷의 분해/조립, 주소 지정, 경로 선택 기능을 제공
TCP/IP 4계층
1. 네트워크 인터페이스
- 데이터를 전송하는 전송매체를 결정하고 신호 레벨, 전기 신호의 제어 기능 담당
2. 인터넷 계층
- 네트워크 상의 경로 설정과 주소를 지정
- IP 프로토콜 - 상위 계층으로부터 받은 데이터를 패킷 단위로 목적지에 정확히 전송
- ARP, IGMP 프로토콜 - 올바른 데이터 전송을 유도하는 역할
- RARP 프로토콜 - 초기 IP 설정 수행
3. 전송 계층
- 상위 계층 데이터의 신뢰성 있는 전송을 수행
- IP에 의해 전달되는 패킷의 오류를 검사하고 재전송 요구 등의 제어를 담당
4. 응용 계층
- TCP/IP 프로토콜을 사용하여 서비스 할 수 있는 응용 프로그램들을 제공
OSI 7계층과 TCP/IP 4계층 :
| OSI 7계층 | TCP/IP 4계층 | TCP/IP의 프로토콜 |
| 응용 계층 표현 계층 세션 계층 | 응용 계층 | FTP, TFTP, DNS, Telnet, SMTP, SNMP |
| 전송 계층 | 전송 계층 | TCP, UDP |
| 네트워크 계층 | 인터넷 계층 | IP, ARP, RARP, ICMP |
| 데이터링크 계층 물리 계층 | 네트워크 계층 | Network interface |
TCP와 UDP
TCP와 UDP는 모두 패킷을 한 컴퓨터에서 다른 컴퓨터로 전달해주는 IP 프로토콜을 기반으로 구현되어 있지만, 서로 다른 특징을 가지고 있다.
TCP는 데이터 송신 방향이 양방향이지만 UDP는 일방적이기 때문에 신뢰성이 요구되는 애플리케이션에서는 TCP를 사용하고 간단한 데이터를 빠른 속도로 전송하고자 하는 애플리케이션에서는 UDP를 사용한다.
1. TCP (Transmission Control Protocol)
- 데이터 전송 전 신뢰성 있는 데이터 전송을 위해 송수신 간의 세션을 연결 (연결형 서비스)
- 강력한 에러 제어 기능(검출/정정)이 있어서 회선이 불안한 상태에서도 정확한 데이터 전송 가능
- 흐름 제어를 위해 슬라이딩 윈도 방식 이용 (오버플로우 방지)
- 패킷의 순차 번호와 CRC를 이용하여 신뢰성 있는 통신을 수행
- TCP 프로토콜을 이용한 서비스 : FTP, Telnet, HTTP, SMTP, POP 등
2. UDP (User Datagram Protocol)
- 데이터 전송 전 연결 설정 작업을 하지 않음 (Connection-less protocol)
- 데이터 전송속도의 향상을 꾀하기 위해 흐름 제어, 오류 정정 기능 없음
- 빠른 수행속도를 필요로 하는 응용 프로그램과 멀티미디어 데이터 실시간 전송에 적합
- 신뢰성이 낮은 데이터 전송과 짧은 데이터 고속 전송에 유리
- 데이터 전송 단위는 블록
- 송신 측에서 무조건 송신만을 수행하는 프로토콜
- 전송 중 패킷이 사라지면 수신 측에서 패킷이 사라렸는지 여부를 알 수 없음
- UDP 프로토콜을 이용한 서비스 : DHCP, SNMP, TFTP, BOOTP 등
TCP vs UDP :
| TCP | UDP |
|---|---|
| 연결지향성 프로토콜 | 비 연결지향성 프로토콜 |
| byte 스트림을 통한 연결 | message 스트림을 통한 연결 |
| 혼잡제어, 흐름제어 O | 혼잡제어, 흐름제어 X |
| 에러 체크를하고 복구 또한 시도 | 에러 체크를 하지만 문제가 있는 패킷은 버림 |
| 순서 보장, 상대적으로 느림 | 순서 보장되지 않음, 상대적으로 빠름 |
| 신뢰성있는 데이터 전송(안정적) | 데이터 전송 보장 X |
| TCP 패킷 : Segment | UDP 패킷 : Datagram |
| 일 대 일(Unicast) 통신 | 일 대 일, 일 대 다(Broadcast), 다 대 다(Multicast) 통신 |
| HTTP, Email, 파일전송 등에서 사용 | DNS, Broadcasting 등에서 사용 |
DHCP & DNS
1. DHCP
Dynamic Host Configuration Protocol(동적 호스트 설정 프로토콜)의 준말로 해당 호스트에게 IP주소, 서브넷마스크, 기본 게이트웨이 IP주소, DNS서버 IP주소를 자동으로 일정 시간 할당해주는 인터넷 프로토콜이다.
DHCP는 애초에 어떤 IP주소를 특정 웹사이트의 이름에 할당해줄지를 결정하는 프토콜이다. 웹사이트를 만들 때 IP주소를 고정할 것 같지만, 실제 IP주소의 할당은 생각보다 훨씬 '동적'이다. 하나하나 주소를 다 고정시키기엔 손도 많이 가고, 주소 고갈의 문제가 있다.
그래서 고안한 방법이, 현재 사용 중이지 않거나 대여 기간이 끝난 IP주소는 또 다른 곳에 할당을 해주는 것이다. 이렇게 DNS가 전달받은 이름을 IP주소와 매치시키기 전에 애초에 할당을 해주는 과정과 관계된 것이 DHCP이다. DHCP 서버와 연동만 되어 있다면 이런 일련의 과정이 모두 자동화될 수 있는 것이 장점이다.
DHCP를 통한 IP 주소 할당은 임대(Lease)라는 개념을 가지고 있는데 이는 DHCP 서버가 IP 주소를 영구적으로 단말에 할당하는 것이 아니고 임대기간(IP Lease Time)을 명시하여 그 기간 동안만 단말이 IP 주소를 사용하도록 하는 것이다. 단말은 임대기간 이후에도 계속 해당 IP 주소를 사용하고자 한다면 IP 주소 임대기간 갱신(IP Address Renewal)을 DHCP 서버에 요청해야 하고 또한 단말은 임대 받은 IP 주소가 더 이상 필요치 않게 되면 IP 주소 반납 절차(IP Address Release)를 수행하게 된다.
즉, 유동 IP를 할당한다 == DHCP서버로부터 IP를 DHCP서버에서 설정해놓은 사용시간만큼 임대해온다.
DHCP는 UDP 프로토콜을 기반으로 작동한다. UDP의 특징은 단말 간 연결을 수립하지 않는다. 그리고 신뢰성을 보장하지 않는다. 이 두가지 특성으로 UDP는 TCP보다 성능이 좋다. 호스트가 시작됐을 때 DHCP 서버를 알지 못하기 때문에 서브넷 상의 모든 노드로 브로드캐스팅 해야한다. 때문에 성능이 좋아햐 하고 연결 대상을 모르기 때문에 UDP를 사용한다.
1. DNS
Domain Name Server의 준말로 도메인 네임과 IP 주소의 대응 관계를 데이터베이스로 구축해 사용하는 인터넷 프로토콜이다.
클라이언트에게 DNS를 제공하는 것은 DHCP 서버의 책임이다. DNS는 브라우징을 단순화하는 매우 특별한 목적을 수행하는 인터넷 상의 또 다른 컴퓨터라고 볼 수 있다.
네트워크의 각 컴퓨터에는 고유한 IP 주소가 있고, 이는 인터넷에서도 마찬가지이다. 인터넷에 연결된 모든 네트워크 또는 컴퓨터 서버에도 고유한 주소가 있다. 우리가 자주 방문하는 사이트의 각 IP 주소를 매번 기억하는 것은 사실 불가능한 일에 가깝다. 그래서 우리는 도메인 이름(www.으로 시작하는 주소)을 사용하는데, 사용자가 문자로 입력한 주소(https://...)를 숫자 형태인 IP 주소(125.xxx.xxx.xxx)로 변환해주는 일을 바로 DNS가 수행하는 것이다.
라우팅
1. 라우터와 라우팅
라우터는 OSI 7계층에서 네트워크 계층에 포함되는 기기로써 둘 혹은 그 이상의 네트워크와 네트워크 간 데이터 전송을 위해 최적 경로를 설정해주며 데이터를 해당 경로를 따라 한 통신망에서 다른 통신망으로 통신할 수 있도록 도와주는 인터넷 접속 장비이다. 즉, 네트워크를 통해 정보를 주고 받을 때 데이터에 담긴 수신처의 주소를 읽고 가장 적절한 통신통로를 이용해 다른 통신망으로 전송하는 장치로, 전화국의 교환기와 비슷한 개념이다. 라우터가 패킷을 전송하는 장비라면 라우팅은 그 패킷을 보낼 경로를 선택하는 과정이다.
2. 라우터의 동작 원리
라우터는 패킷의 전송경로를 결정하기 위해 랜테이블, 네트워크테이블, 라우팅테이블을 사용한다. 이 3가지 테이블을 관리함으로써 다른 네트워크에 연결된 모든 장치들의 주소를 인식하고 이것을 바탕으로 패킷의 전송경로를 결정한다.
- 같은 네트워크에 있는 장치로부터 패킷을 보내면 라우터에서는 먼저 랜테이블 검사를 한다. 이곳에서는 패킷의 목적지가 같은 네트워크에 있는지 아니면 다른 네트워크에 있는지 확인한다.
- 네트워크테이블을 검사하여 패킷을 전달한 네트워크 주소를 찾아낸다.
- 라우팅테이블을 검색하여 가장 적합한 경로를 찾아내서 패킷을 보낸다.
- 랜테이블 : 라우터에 연결되어 있는 랜 세그먼트 내 장치의 주소를 관리하고 있으며 필터링 작업에 사용된다.
- 네트워크테이블 : 네트워크 상의 모든 라우터의 주소를 보관하여 패킷의 수신지 라우터를 식별하는데 사용된다.
- 라우팅테이블 : 개개의 라우터에 구축되어 있으며 각 경로에 대한 정보를 유지하고 있어서 세그먼트로 전송되는 패킷의 경로를 결정하는데 사용된다.
이 3가지 테이블은 라우터가 패킷을 전송함에 있어서 최선의 경로를 선택하게 되고 회선의 장애나 라우터의 장애시 우회 경로를 선택해서 패킷 Routing loop를 방지하기 위해 사용된다.
3. 라우터의 목적지 학습 방법
-
Connected (연결)
자신과 물리적으로 직접 연결되어있는 장비의 IP 주소를 자동으로 알아온다. 이때 IP는 네트워크 주소로 라우팅 테이블에 저장된다. -
Static (정적)
관리자가 직접 라우팅 경로를 선택해서 보내는 설정
-장점 : 관리자가 테이터가 전송될 경로를 직접 설정하므로 경로관리에 가장 효율적이다.
-단점 : 네트워크 변화에 대한 대처가 느리다. -
Dynamic (동적)
각 라우터들이 갖고 있는 정보를 서로에게 공유하여 라우팅 테이블에 저장한다. 주시적으로 최적경로를 계산하여 라우팅 테이블의 정보를 유지하는 방식이다.
-장점 : 네트워크 변화에 대한 대처가 빠르다.
-단점 : 주기적으로 경로를 계산해야하므로 리소스 소비량(CPU사용량)이 많아진다. -
Redistribution (재분배)
정보 교환이 이루어지지 않는 장비끼리 관리자가 강제로 교환하는 방식
게이트웨이
게이트웨이(gateway)는 '관문'이나 '출입구'라는 의미로 다양한 분야에서 일반적으로 사용되는 용어다. 컴퓨터 네트워크에서의 게이트웨이는 현재 사용자가 위치한 네트워크(정확히는 세그먼트-segment)에서 다른 네트워크(인터넷 등)로 이동하기 위해 반드시 거쳐야 하는 거점을 의미한다. 자동차 고속도로로 진입하기 위해 통과하는 톨게이트와 유사한 개념이다.
두 컴퓨터(노드-node라고도 함)가 네트워크 상에서 서로 연결되려면 동일한 통신 프로토콜(통신 규약)을 사용해야 한다. 따라서 프로토콜이 다른 네트워크 상의 컴퓨터와 통신하려면 두 프로토콜을 적절히 변환해 주는 변환기가 필요한데, 게이트웨이가 바로 이러한 변환기 역할을 한다. 한국인과 미국인 사이에 원활한 의사소통을 위해 통역사를 두는 것과 동일하다.
게이트웨이는 일반적으로 하드웨어 형태로 제공되며, 내부적으로 복잡한 원리로 작동하지만 외형은 생각보다 간단하다. 흔히 보는 네트워크 허브나 스위치 등과 비슷하게 생겼다. 또한 기능이나 용도, 적용 범위 등에 따라 손바닥만한 제품부터 소형 냉장고만한 제품까지 크기도 다양하다.
게이트웨이는 또한 라우터와 동일한 개념으로 이해할 수 있다. 라우터는 네트워크 장비의 일종으로, 패킷(네트워크 전송 데이터의 최소 단위)을 다른 네트워크 보내주는 역할을 한다. 이와 함께 최적의 네트워크 경로를 찾아주는 역할도 함께 수행한다. 이렇듯 라우터도 서로 다른 네트워크를 연결한다는 부분에서 게이트웨이와 상통한다(다만 게이트웨이는 라우터보다 포괄적인 개념이다).
참고 사이트 :
