이번 글은 Entity Structure Within and Throughout: Modeling Mention Dependencies for Document-Level Relation Extraction(AAAI '21) 논문 리뷰입니다. KAIST DAVIAN 연구실의 최민석님께서 발표하신 랩세미나를 정리한 글임을 밝힙니다.
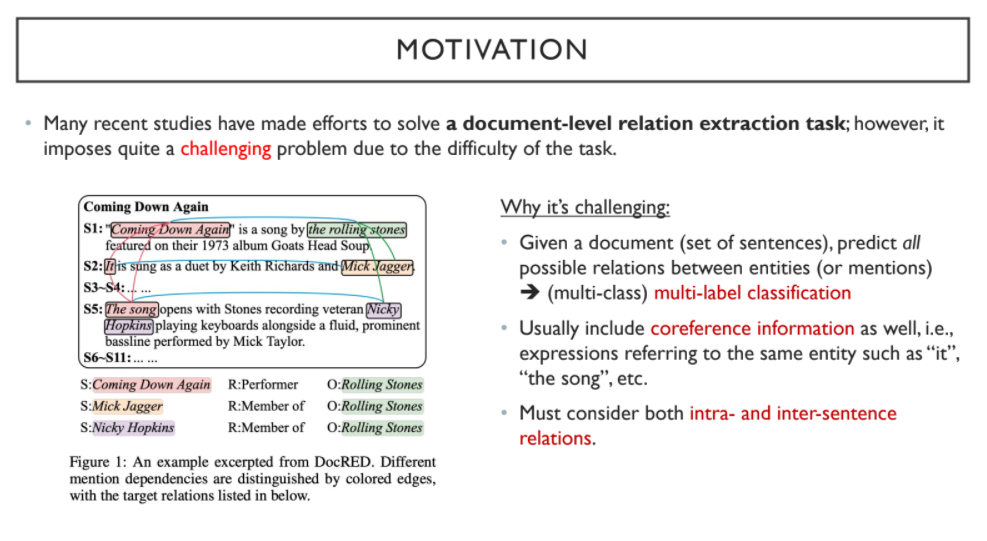
'Document-level Relation Extraction Task'가 어려운 이유는,
1) 문서 전체 내의 모든 Entity 간에 잠재적으로 생성 가능한 Relation을 모두 고려해야 하기 때문에
2) Coreference Information을 고려해야 하기 때문에 (e.g. the song -> it)
즉, 문장 내 혹은 문장 간의 수많은 관계들을 고려해야 하기 때문이다.

주요 Entity Structure는 다음과 같다.
1) Intra + coref: 동일한 문장 내에서의 동일한 entity
2) Intra + relate: 동일한 문장 내에서의 관계 있는 entity
3) Inter + coref: 동일하지 않은 문장에서의 동일한 entity
4) Inter + relate: 동일하지 않은 문장에서의 관계 있는 entity
5) IntraNE: 동일한 문장 내에서의 a, the 와 같은 단어
6) NA: 동일하지 않은 문장에서의 a, the 와 같은 단어, 중요하지 않다고 판단
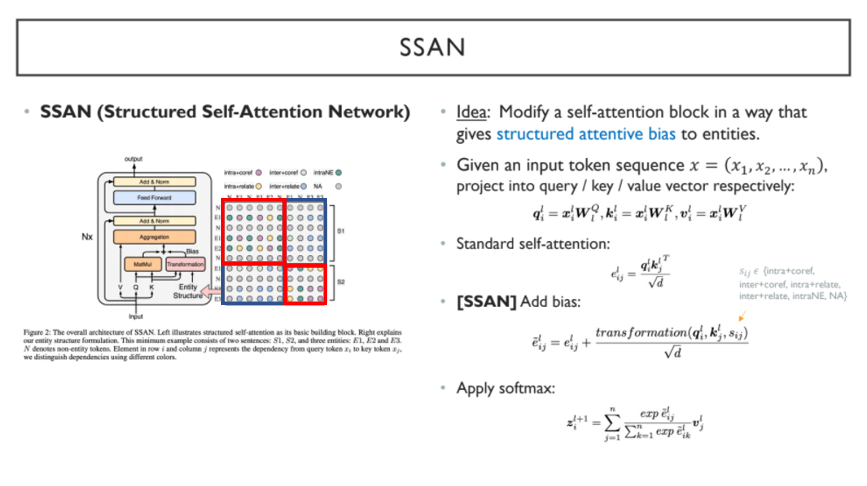
Structured Self-Attention Network(SSAN) 구조의 가장 큰 특징은 entity structure와 연결되는 Transformation 부분(Biasterm)이다. Entity structure는 one hot vector 형식으로 생성되고, 빨간색 박스는 intra 부분을 고려하며 파란색 박스는 inter 부분을 고려한다. 기존의 standard self-attention에 entity structure에 따른 transformation을 pairwise하게 더해주는 방식이다.
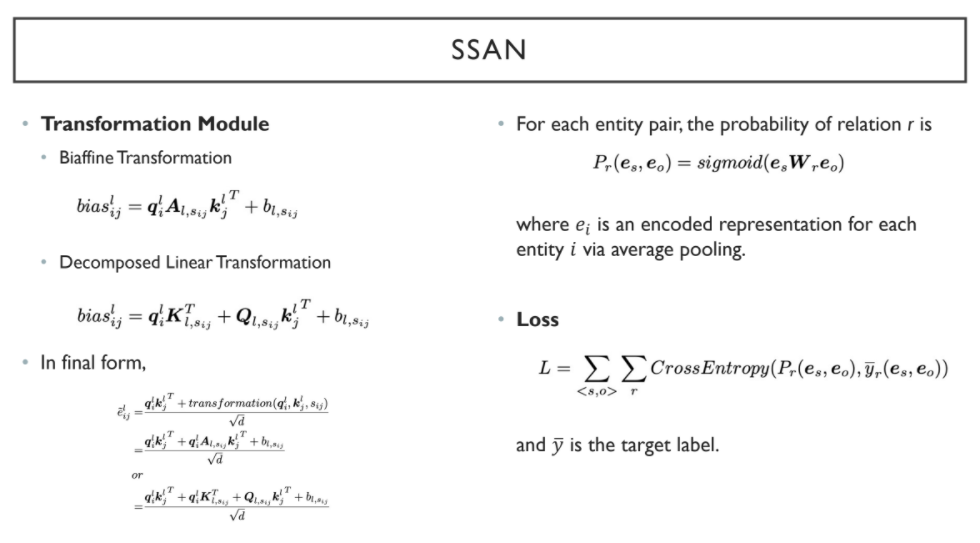
Transformation module은 Biaffine Transformation 이거나 Decomposed Linear Transformation 으로 구성된다. Biaffine transforamtion은 query와 key가 공유되는 반면, decomposed linear transformation은 query와 key가 공유되지 않는다.
동일한 의미를 갖는 여러 entity(e.g. the song -> it)는 average pooling을 통해 fixed-sized dimension의 entity representation를 생성한다. 각 entity representation pair에 대해 bilinear tranformation을 수행하고, sigmoid function에 의해 특정 relation에 확률로 근사하게 된다.
즉, 각 entity representation pair에 대하여 relation 개수만큼의 확률이 도출된다.
이후 prediction label과 target label 간의 cross entropy loss의 합을 구하게 된다.
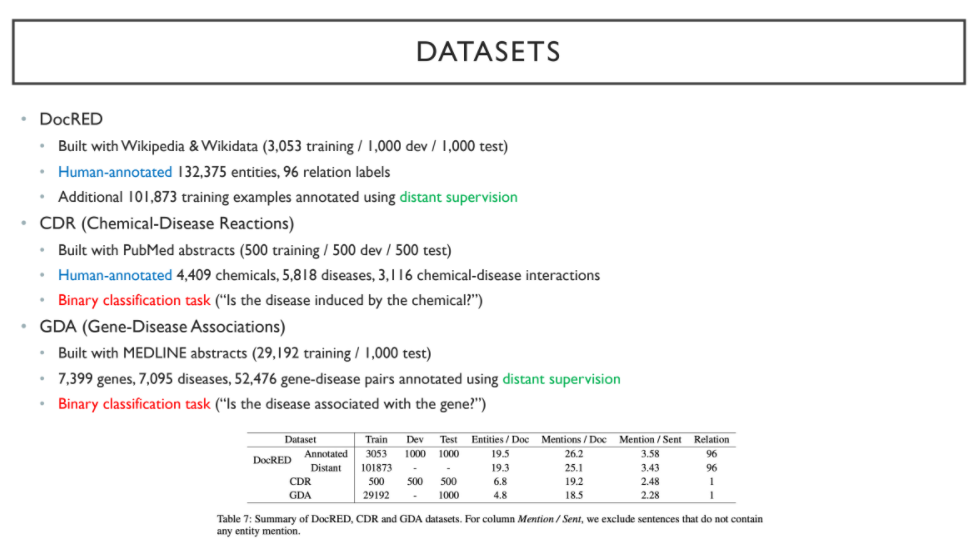
다음은 dataset에 대한 설명이다.
1) DocRED: human-annotated Wikipedia & Wikidata dataset
2) CDR: human-annotated PubMed abstract dataset
only binary classification(disease-chemical)
3) GDA: MEDLINE abstract dataset
only binary classification(disease-gene)
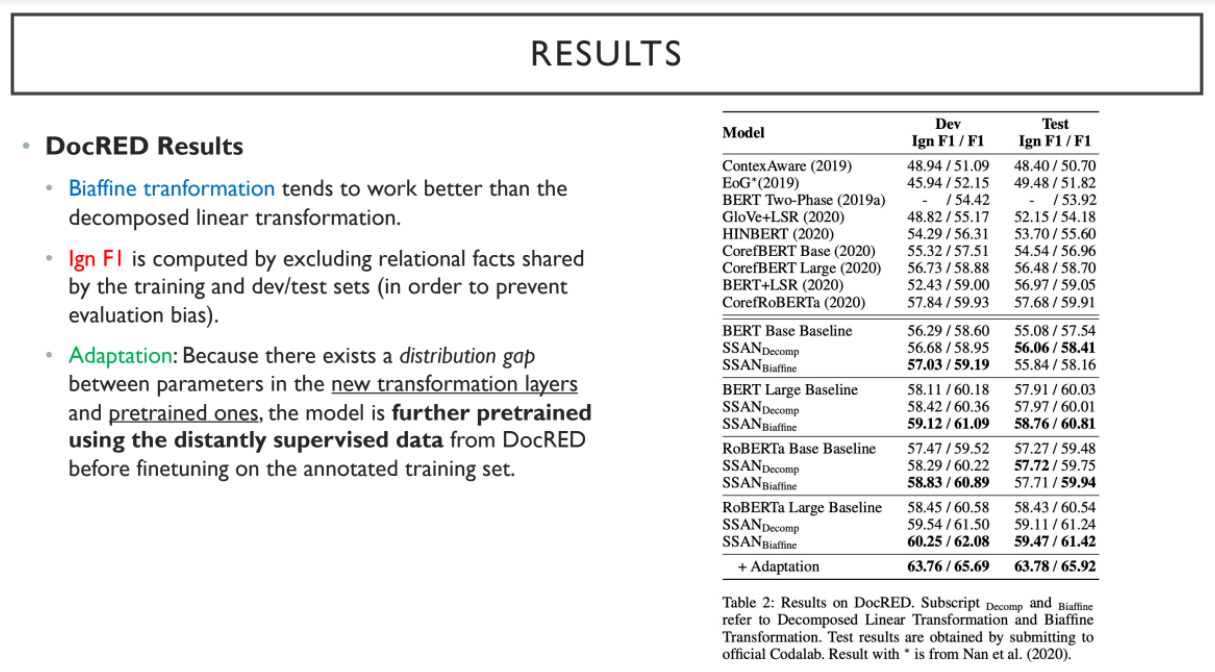
결론은 다음과 같다.
1) Biaffine transformation이 decomposed linear transformation에 비해 성능이 잘 나온다.
2) Ign F1: evaluation bias를 피하기 위해 train과 dev/test에서 공유된 relation은 제외하고 평가한 지표
3) Adaptaion: Pretrained transformation과 new transformation 간의 distribution gap이 있다고 판단하여, 새로운 transformation에 pretraining과 fine tuning을 진행함
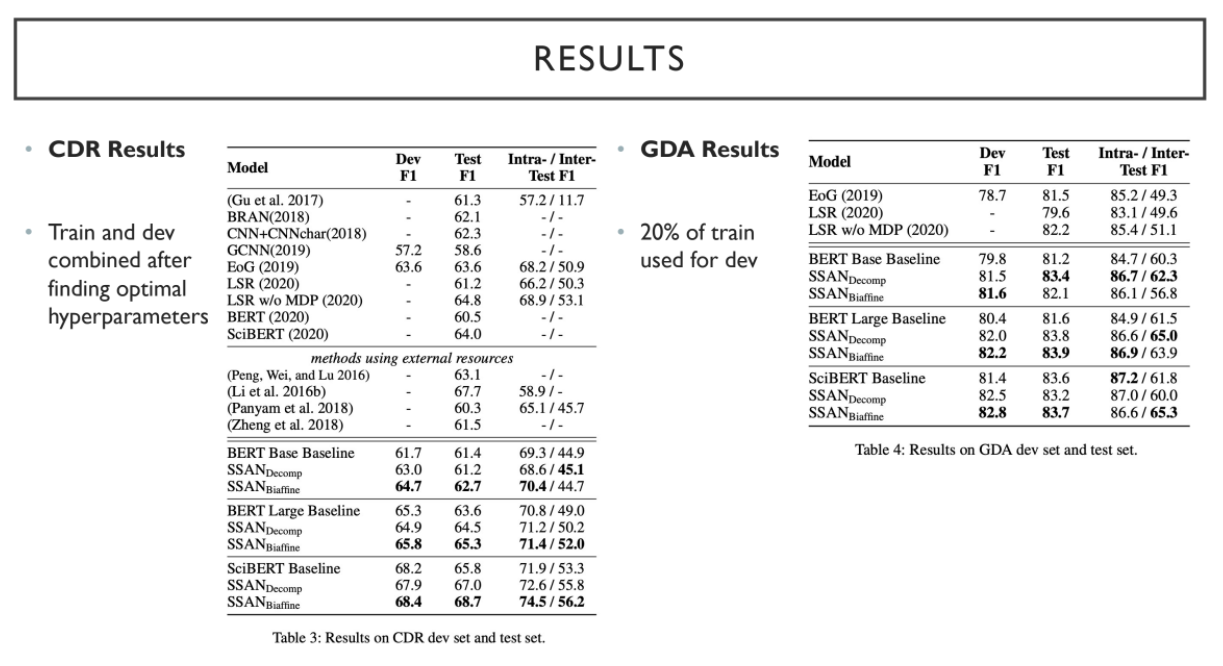
CDR의 경우 train과 dev dataset을 합치고, GDA의 경우 20%의 train을 dev dataset으로 사용한다.

결론은 Structuring Attention Computation이 document-level relation extraction에 효과가 있다는 점이다.
추후 entity structure formulation을 다양하게 진행해볼 수 있을 것으로도 기대된다.
