https://leetcode.com/problems/word-ladder-ii/
📕 문제 설명
시작 단어를 끝 단어로 만들 수 있는 최소 길이의 transformation sequence 모두 반환하기
(주어진 단어리스트에서 transformation sequence를 찾으며, 없는 경우 빈 리스트 반환)
- Input
시작 단어, 끝 단어, 단어 리스트 - Output
최소 길이의 모든 transformation sequence 리스트
예제
시도 1.
우선 한 글자 차이나는 것 저장하고 있는 딕셔너리 만들고 bfs로 큐에 path 넣으면서 endWord 보면 min count 설정하고 끝내는 식으로 작성.
시간 초과
public class Solution {
public IList<IList<string>> FindLadders(string beginWord, string endWord, IList<string> wordList) {
List<IList<string>> answerList = new List<IList<string>>();
Dictionary<string, List<string>> singleLetterDiffDict = new Dictionary<string, List<string>>();
List<string> allWordsList = wordList.ToList();
if (!wordList.Contains(beginWord))
{
allWordsList.Add(beginWord);
}
foreach(string word in allWordsList)
{
singleLetterDiffDict[word] = new List<string>();
}
// 한글자 차이나는 단어들 모은 dict 만들기
for (int i = 0; i < allWordsList.Count - 1; i++)
{
string currentWord = allWordsList[i];
for (int j = i + 1; j < allWordsList.Count; j++)
{
string tempWord = allWordsList[j];
int cnt = 0;
for (int k = 0; k < currentWord.Length; k++)
{
if (currentWord[k] != tempWord[k]) cnt++;
}
if (cnt == 1)
{
singleLetterDiffDict[currentWord].Add(tempWord);
singleLetterDiffDict[tempWord].Add(currentWord);
}
}
}
Queue<List<string>> queue = new Queue<List<string>>();
int minCnt = 501;
queue.Enqueue(new List<string>() {beginWord});
while(queue.Count != 0)
{
List<string> currentList = queue.Dequeue();
if (currentList.Count >= minCnt) break; // endWord 도달시 종료
foreach(string tempWord in singleLetterDiffDict[currentList[currentList.Count - 1]]) // 한글자 차이나는 단어들로 리스트 붙여나가기
{
if (currentList.Contains(tempWord)) continue;
List<string> tempList = currentList.ToList();
tempList.Add(tempWord);
if (tempWord == endWord)
{
minCnt = tempList.Count;
answerList.Add(tempList);
}
queue.Enqueue(tempList);
}
}
return answerList;
}
}시도 2.
시간 초과 (32까지는 통과됨)
위의 풀이에서 list로 contains하는 부분에서 시간 많이 걸리는 것 같아서 Dictionary로 visited 관리
public class Solution {
public IList<IList<string>> FindLadders(string beginWord, string endWord, IList<string> wordList) {
List<IList<string>> answerList = new List<IList<string>>();
Dictionary<string, List<string>> singleLetterDiffDict = new Dictionary<string, List<string>>();
Dictionary<string, bool> visited = new Dictionary<string, bool>();
List<string> allWordsList = wordList.ToList();
if (!wordList.Contains(beginWord))
{
allWordsList.Add(beginWord);
}
foreach(string word in allWordsList)
{
singleLetterDiffDict[word] = new List<string>();
visited[word] = false;
}
// 한글자 차이나는 단어들 모은 dict 만들기
for (int i = 0; i < allWordsList.Count - 1; i++)
{
string currentWord = allWordsList[i];
for (int j = i + 1; j < allWordsList.Count; j++)
{
string tempWord = allWordsList[j];
int cnt = 0;
for (int k = 0; k < currentWord.Length; k++)
{
if (currentWord[k] != tempWord[k]) cnt++;
}
if (cnt == 1)
{
singleLetterDiffDict[currentWord].Add(tempWord);
singleLetterDiffDict[tempWord].Add(currentWord);
}
}
}
Queue<List<string>> queue = new Queue<List<string>>();
int minCnt = 501;
queue.Enqueue(new List<string>() {beginWord});
visited[beginWord] = true;
while(queue.Count != 0)
{
Queue<List<string>> nextQueue = new Queue<List<string>>();
List<string> tempVisited = new List<string>();
while(queue.Count != 0)
{
List<string> currentList = queue.Dequeue();
if (currentList.Count > minCnt) break; // endWord 도달시 종료
foreach(string tempWord in singleLetterDiffDict[currentList[currentList.Count - 1]]) // 한글자 차이나는 단어들로 리스트 붙여나가기
{
if (visited[tempWord]) continue;
List<string> tempList = currentList.ToList();
tempList.Add(tempWord);
if (tempWord == endWord && (minCnt == 501 || tempList.Count == minCnt))
{
minCnt = tempList.Count;
answerList.Add(tempList);
}
nextQueue.Enqueue(tempList);
tempVisited.Add(tempWord);
}
}
foreach(string s in tempVisited)
{
visited[s] = true;
}
queue = nextQueue;
}
return answerList;
}
}시도 3.
다른 풀이 참고했는데 다른 언어에서는 통과되는 bfs + dfs 풀이이다. bfs로 min_depth랑 adjacent list 찾은 다음 dfs로 adjacent list 타고가면서 path 저장하는 방식이다.
(똑같이 시간 초과 난다ㅠㅠ C#에서 안되는건지 C#으로 구현하다가 어디서 더 잡아먹는식으로 적은건가..)
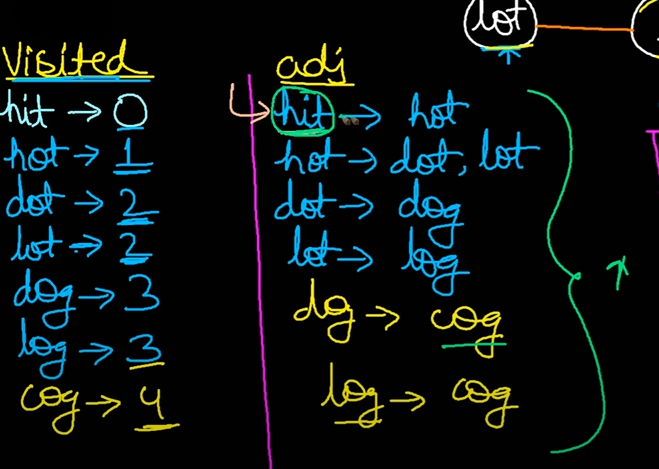
시간 초과 동일 (32번째)
public class Solution {
List<IList<string>> answerList = new List<IList<string>>();
public IList<IList<string>> FindLadders(string beginWord, string endWord, IList<string> wordList) {
Dictionary<string, HashSet<string>> singleLetterDiffDict = new Dictionary<string, HashSet<string>>();
Dictionary<string, int> visited = new Dictionary<string, int>();
foreach(string word in wordList)
{
visited[word] = 501;
singleLetterDiffDict[word] = new HashSet<string>();
}
visited[beginWord] = 0;
singleLetterDiffDict[beginWord] = new HashSet<string>();
Queue<string> queue = new Queue<string>();
queue.Enqueue(beginWord);
// BFS -> 최단 거리 찾기 + 1 글자 차이나는 것 저장
while (queue.Count != 0)
{
string s = queue.Dequeue();
for (int i = 0; i < s.Length; i++)
{
var charArr = s.ToCharArray();
for (char c = 'a'; c <= 'z'; c++)
{
if (s[i] == c) continue;
charArr[i] = c;
string nextWord = new string(charArr);
if (visited.TryGetValue(nextWord, out int cnt)) // wordList에 존재하는 단어인지 확인
{
// 존재하는데 visited 안되어 있으면 parent depth에 + 1해주기
if (cnt == 501)
{
visited[nextWord] = visited[s] + 1;
queue.Enqueue(nextWord);
singleLetterDiffDict[s].Add(nextWord);
}
else if (visited[nextWord] == visited[s] + 1)
{
singleLetterDiffDict[s].Add(nextWord);
}
}
}
}
}
List<string> path = new List<string>();
DFS(beginWord, endWord, singleLetterDiffDict, path);
return answerList;
}
private void DFS(string begin, string end, Dictionary<string, HashSet<string>> dict, List<string> path)
{
path.Add(begin);
if (begin == end)
{
answerList.Add(path.ToList());
return;
}
foreach(string s in dict[begin])
{
DFS(s, end, dict, path);
path.Remove(s);
}
}
}(그렇게 완전히 통과되는 케이스를 아직 찾지 못했다고..)
풀이
결과

하나씩 심어 나가는 개발 농장🥕 (블로그 이전중)