🏆 퀵정렬이란?
평균적으로 매우 빠른 수행 속도를 자랑하는 정렬 방법입니다.
-
전체리스트를 2개의 부분 리스트로
분할하고, 각가의 부분 리스트를 다시퀵정렬하는 전형적인분할정복법을 사용. -
피벗을 설정하고피벗을 기준으로 좌우에 작은값, 큰값을 놓는 방법을 반복합니다. -
시간복잡도 : O(nlogn)
⭐️ 분활정복법이란?
문제를 조금씩 나눠가면서 문제를 푼 다음 마지막에 합쳐서 문제를 해결
🛠️ 퀵정렬 방식
- 피벗선택
- Low, High 지정 후 교환
- 피벗과 High값을 교환
- 왼쪽, 오른쪽에 있는 리스트에 1~4의 과정반복
*이 방식은 왼쪽을 피벗으로 선택하여하는 퀵정렬입니다.
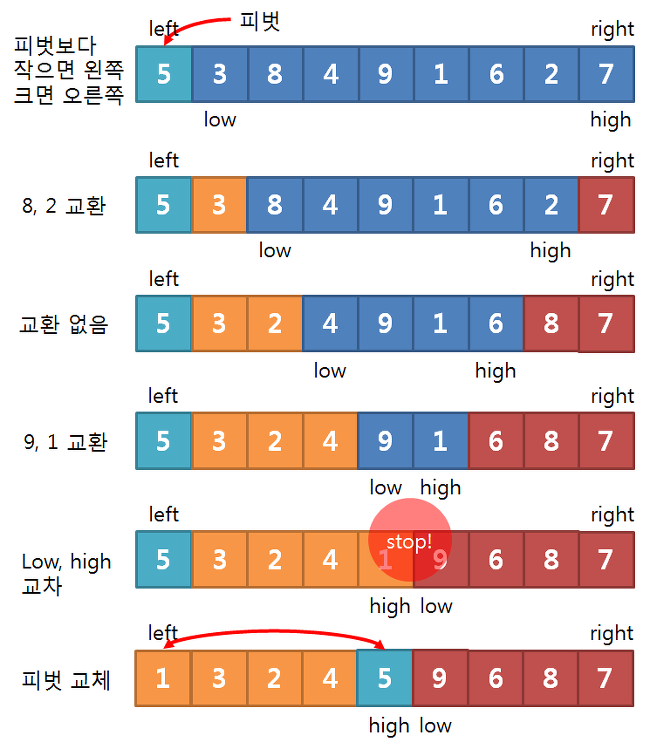
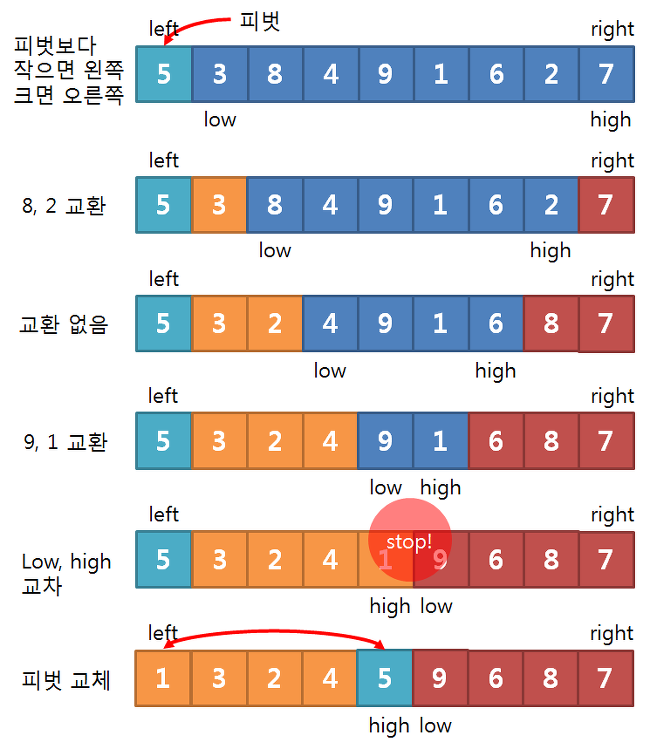
피벗선택

피벗과 low, high값들을 지정해줍니다.
피벗은 제일 첫번째 요소로 지정해줍니다.
초기의 low는 피벗보다 + 1
초기의 high는 right와 같이 합니다.
Low High 지정
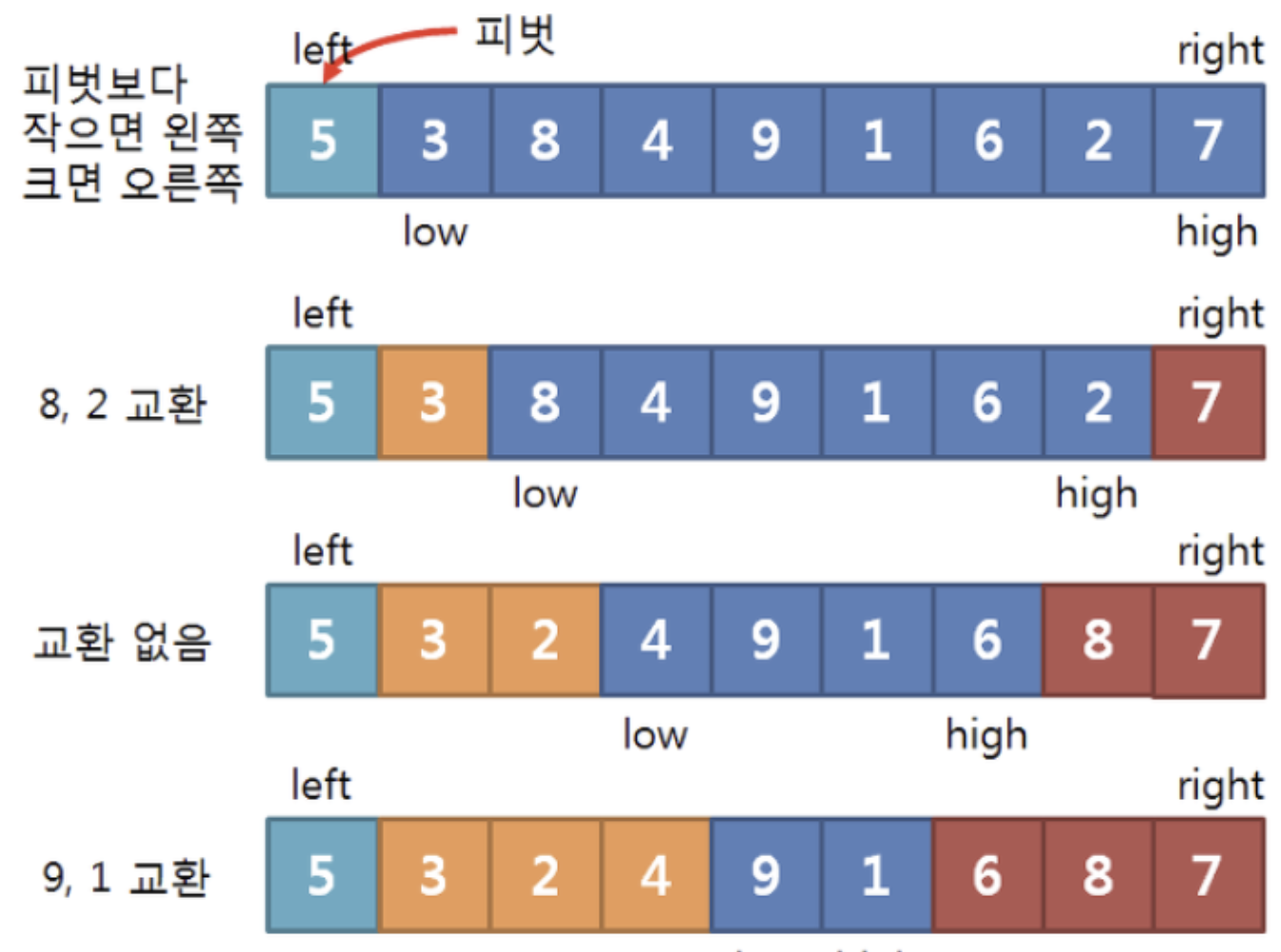
왼쪽에 피벗보다 작은값, 오른쪽에는 피벗보다 큰값으로 넣기위해서
low는 피벗보다 작은값이라면 +1을 해주며 옮깁니다.
high는 피벗보다 큰값이라면 -1을 해주며 옮깁니다.
만약 low가 피벗보다 큰값을만나면 멈추고 high도 피벗보다 작은값을만나면 멈춥니다.
멈춘둘은 값을 교환해줍니다.
피벗과 High 교환
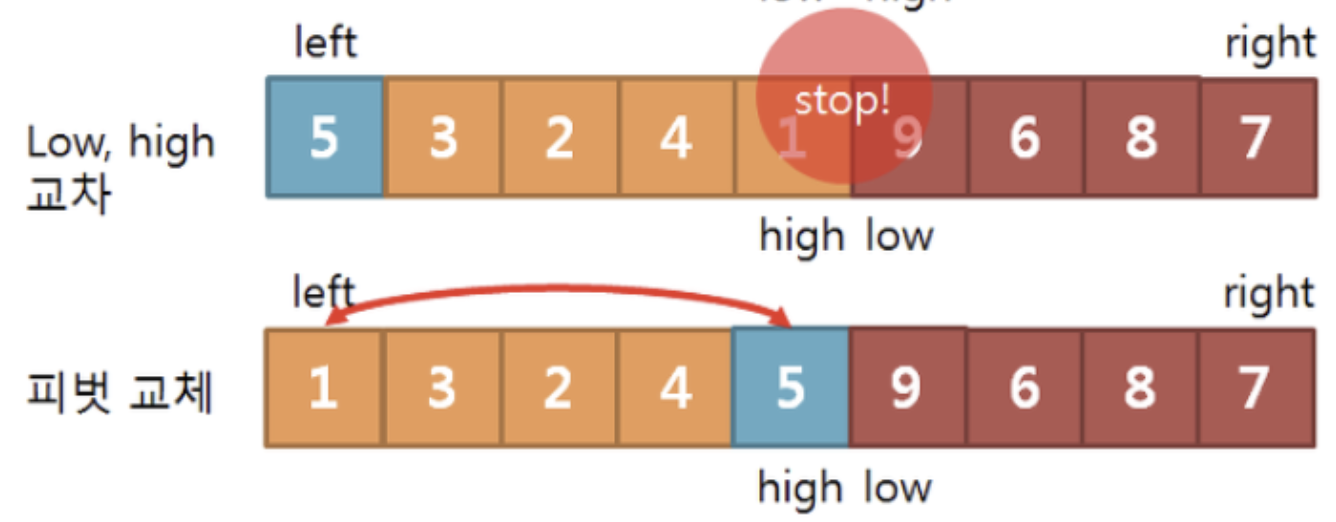
위의 작업을 반복하면 그림과 같이 low > high 의 상황이 생깁니다.
이때 high의 값과 피벗의 값을 교환해줍니다.
그렇게 된다면 피벗의 왼쪽에는 피벗보다 작은값들이,
피벗의 오른쪽에는 피벗보다 큰 값들이 있을것입니다.
반복
피벗보다 작은쪽에 있는 값들로 위의 과정을 반복하고
피벗보다 큰쪽에 있는 값들로 위의 과정을 반복합니다.
반복했을때 마지막에는 정렬됩니다.
코드
#include <stdio.h>
#define swap(x,y,t) ((t)=(x), (x)=(y), (y)=(t))
int partition(int list[], int left,int right)
{
int pivot,temp,low,high;
low = left;
high= right+1;
pivot=list[left];
do
{
do
{
low++;
}while(list[low]<pivot && low<=right);
do
{
high--;
}while(list[high]>pivot);
if(low<high)
{
swap(list[low],list[high],temp);
}
}while(low<high);
swap(list[left],list[high],temp);
return high;
}
void quicksort(int list[], int left,int right)
{
if(left<right)
{
int q=partition(list, left, right);
quicksort(list,left,q-1);
quicksort(list,q+1,right);
}
}
int main()
{
int list[6]={10,2,20,7,50,1};
quicksort(list,0,5);
for(int i=0; i<6; i++)
{
printf("%d ",list[i]);
}
return 0;
}퀵정렬의 장단점
🙆♂️ 장점
-
정렬된 상태가 아닌 이상 시간복잡도가 O(nlogn)이라서 속도가 매우 빠릅니다.
-
추가 메모리를 거의 사용하지 않기에 대규모 데이터를 다룰 때 메모리 사용량이 상대적으로 적습니다.
🙅♂️ 단점
-
특정 조건(정렬된 상태) 하에 성능이 급격하게 떨어진다. (O(n2))
-
퀵 정렬은 재귀적으로 구현되기 때문에, 배열이 매우 클 경우 스택 오버플로우가 발생할 수 있습니다.
마무리

근데 킹갓 파이썬에서는 딸깍 몇번으로 퀵정렬 할 수 있습니다...네...감사합니다