
자료구조와 알고리즘은 그냥 암기하고 외우는 것이 아니라, 실제 써먹을 수 있도록 제대로 이해해야 합니다.
하지만, 이제 막 코딩을 시작한 사람에게는 필요없습니다. 그럼 언제 필요할까요? 난 코딩은 다 돌아가는데 너무 느릴 때! 어디를 최적화해야 하는지! 효율적으로 더 빠르게 돌아가기 위해서 필요합니다.
간단히 말하면 코드를 최적화 하는 것입니다! (클린 코드라고도 하죠.)
알고리즘 :
알고리즘은 여러개의 지시사항이라고 볼 수 있습니다. 어떠한 목표를 달성하기 위해 컴퓨터가 수행해야 하는 것들이죠. 일상 생활에서도 찾아볼 수 있습니다. 예를 들어, 아침에 일어나서 침구류를 정리하고, 샤워를 하고, 밥을 먹고, 출근을 하죠. 이런 것들도 모두 알고리즘이라고 할 수 있습니다! 이러한 많은 것들이 목적을 달성하기 위한 여러개의 행동들로 이루어져 있고, 이를 통해 최적의 결과를 산출해내는 것이죠.
ex) 최단 경로 찾기, 이미지 압축 방법, 암호화 하는 방법 등이 모두 알고리즘입니다!
자료 구조 :
데이터는 마치 오일같습니다. 어디서에든 데이터를 필요로 하죠. 결국 데이터 구조는 많은 데이터들을 정리하는 것입니다. 어떻게 정리하냐에 따라서 속도에 영향을 주기 때문입니다. 즉, 어떤 데이터 구조를 사용하냐에 따라서 서비스가 빨라지거나 느려집니다.
- 정렬(sort), 탐색(search), 삽입(insert), etc...
결국 어떠한 작업에 따라서 어떠한 데이터 구조를 언제, 어떻게 쓰는지 아는 것이 해당 프로그램이나 어플의 속도를 결정하게 됩니다. 어떨 때는 array 대신 linked lists를 써야 하는것처럼 말이죠.
따라서 기본적인 4가지 오퍼레이션 상황에 맞춰서 각각의 데이터 구조에 대한 이해도가 있어야 합니다.
1. 검색(search)
2. 읽기(read)
3. 삽입(insert)
4. 삭제(delete)
이 4가지 상황을 염두하고 데이터 구조를 보면 어떠한 상황에 어떤 데이터 구조를 써야할 지 알 수 있습니다. 여기서 어떤 데이터 구조를 선택하느냐에 따라서 갈리게 되는거죠.
시간복잡도(Time Complexity) :
데이터 구조의 연산이나 알고리즘이 얼마나 빠르고 느린지 측정하는 방법입니다. 이것을 실제 시간을 측정하는 것이 아니라 얼마나 많은 단계가 있는가로 측정합니다. 물론 단계가 적을 수록 더 좋다고 할 수 있습니다.
Arrays :
먼저 배열을 알아보기 전에 메모리 관점에서 배열이 어떻게 보이는지 생각해볼 필요가 있습니다.
메모리는 휘발성 메모리, 비휘발성 메모리 2가지 종류가 있습니다.
Non volatile memory : 껐다 켜도 없어지지 않는 하드 드라이브
Volatile memory : 컴퓨터를 끄면 RAM에 올라가 있는 데이터가 사라지는 것으로 프로그램이 돌아가고 변수를 활용할 때, 이것들은 모두 RAM에 저장이 됩니다.
배열은 같은 타입의 데이터를 연속된 공간에 나열시키고, 각 데이터에게 번호표를 줘서 어디에 저장했는지 쉽게 알 수 있게 한 타입입니다. (공백X)
배열을 설정할 때는 컴퓨터에게 얼마나 배열이 긴 지를 설명해줘야 합니다. 그러면 RAM의 그에 따른 크기만큼 공간을 미리 예약/할당 해주는 것이죠. 하지만 파이썬 같은 몇 가지 언어들은 시스템에서 자동으로 할당해 줍니다.
이렇게 하면 컴퓨터는 얼마나 길지, 어디서 시작할지 알고 있게 됩니다. 이걸 알고있기 때문에 배열의 처리 속도가 빠른 것입니다!
- Reading :
말 그대로 배열을 어떻게 읽을 지 결정하는 것입니다. 중요한 점은 배열은 0부터 인덱싱!!
즉, 위치만 알면 배열의 데이터에 접속할 수 있습니다.
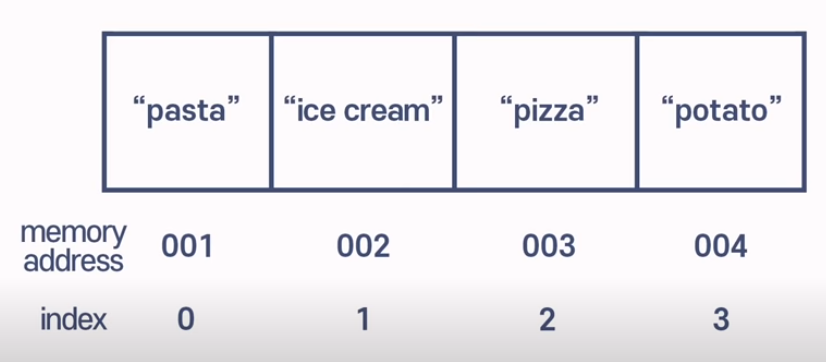 만약 아이스크림을 먹고 싶으면 컴퓨터에게 1번 인덱스의 값을 달라고 하면 되는 것이죠.
만약 아이스크림을 먹고 싶으면 컴퓨터에게 1번 인덱스의 값을 달라고 하면 되는 것이죠.
- Reading :
따라서 배열에서 Reading(읽어내는 것)하는 것은 매우 빠릅니다. 앞에서 말한 것처럼 컴퓨터는 배열이 어디서 시작하는지를 알고 있기 때문이죠!
많은 자료를 읽어내야 한다면 배열이 최고입니다. 인덱스에서 요소를 읽어내는 속도는 동일하기 때문에 배열이 얼마나 긴지랑은 관계가 없습니다. 배열에 몇개가 있던 스텝은 동일합니다!
- Searching
이건 읽기와 다르게 시간이 조금 걸립니다. 데이터를 읽을 때는 그냥 값을 얻으면 됐었지만, 검색에서는 해당 값이 어디에 있는지 모르기 때문입니다. 불행하게도 모두 하나하나 다 뒤져야 합니다.
- Searching

메모리는 마치 데이터를 넣은 박스입니다. 그렇지만 이 박스들은 열려있지 않기 때문에 직접 열어야 합니다. 랜덤 엑세스가 있어서 박스를 쉽게 접근할 수 있는데 박스 안의 값은 모르는 상황입니다. 따라서, 하나 하나 열어서 맞는지 체크하는 과정을 해야합니다. 알다시피 그냥 읽는 것보다 시간이 많이 걸립니다.
만약 찾는 값이 첫번째 인덱스에 있다면, 순식간에 찾고 끝납니다. 그러나 보통의 시나리오의 경우에는 중간에 있을 확률이 높습니다. 최악의 경우는 맨 마지막에 있는 것입니다. 아니면 아예 값이 없거나;;
이런 방식을 선형 탐색(Linear searching)이라고 합니다. 순서대로 0부터 끝까지 차례차례 찾는 것이죠. 이것보다 빠른 탐색 방법도 있긴 한데 일단은 배열안에서 탐색, 검색은 그닥 빠르지 않다 정도로만 알고 있으면 될거 같습니다.
- Insert(Add, Write)
삽입에는 3가지 시나리오가 있습니다. 먼저 값이 들어갈 공간을 확인하고, 공간이 있다면 "어디에" 추가해야 하는지가 가장 큰 이슈입니다.
- Insert(Add, Write)
- 최고의 시나리오는 값을 맨 끝에 추가하는 경우입니다. 배열의 시작점에서 맨 끝으로 옮기면 되기 때문입니다.
- 그저 그런 시나리오는 값이 중간에 들어가야 하는 경우입니다. 뒤쪽의 배열들을 하나하나 뒤쪽으로 옮겨줘야 합니다.
- 최악의 시나리오는... 놀랍게도 맨 앞에 들어가야 하는 경우입니다. 앞에서 말한 것처럼 비집고 들어갈 수 없기 때문에 값을 끝에서 부터 뒤로 밀어줘야 합니다! 만약 배열의 크기가 크다면...ㅠㅠ
번외로 안좋은 경우가 한 가지 더 있는데 그건 바로 공간이 이미 다 찬 경우입니다. 알다시피 배열은 정해진 길이가 있고, 만들 때 해당 공간을 미리 할당하게 되어 있습니다. 따라서 이전 배열을 그대로 복사하고 새로운 값을 추가해야 합니다. 딱 봐도 시간이 오래걸리겠죠?
- Delete
삭제는 Insert와 비슷합니다. 배열을 이리저리 움직여야 하기 때문이죠.
- Delete
- 배열의 마지막 요소를 삭제하고 싶다면 그냥 마지막 배열로 이동해서 삭제하면 됩니다.
- 보통의 시나리오에서는 중간 값을 삭제하는 경우가 대부분 입니다. 삭제 할 때는 바로 삭제하면 되는데 삭제된 곳이 빈공간으로 남아있기 때문에 뒤쪽에 있는 값들을 다시 앞쪽으로 땡겨줘야 합니다.

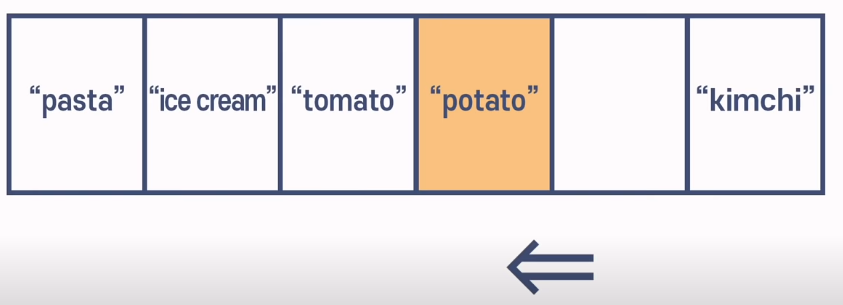
- 최악의 시나리오는 삭제할 값이 맨 앞에 있는 것입니다. 삭제하고 남은 공간을 메꾸기 위해 뒤쪽의 모든 값들을 앞으로 떙겨와야 합니다.
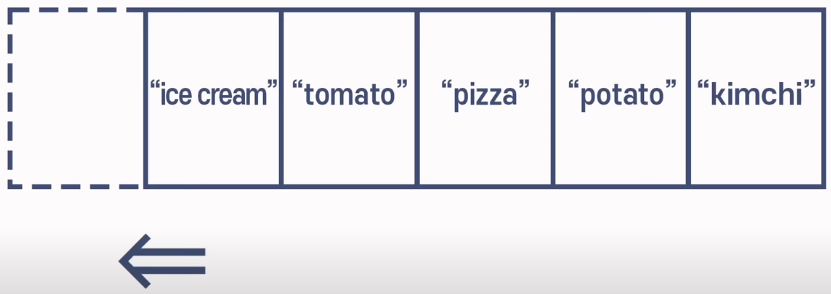
즉, 배열은 데이터를 읽을 때는 정말 빠릅니다. 하지만 검색하고 추가하고 삭제해야 할 때는 느려집니다. 배열에서 추가하고 삭제하고 싶은 상황이라면 배열의 맨 끝에서 작업하는 것이 가장 좋은 방법입니다.
