1. JDBC, SQL MAPPER, ORM(JPA) == 어떻게 데이터베이스에 데이터를 저장할 것인가 == 어떻게 영속성 구현할 것인가
- DB마다 연결방법, SQL, 응답 방법 등이 전부 다름.
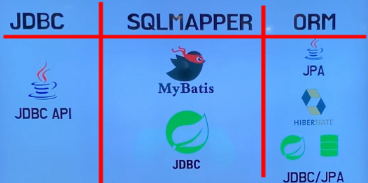
- JDBC API == java database connectivity == 일반적인 디비 접근 기술
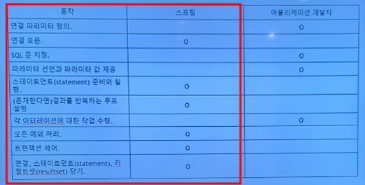
- java 진영의 DB 연결 표준 인터페이스 →드라이버 매니저를 통해 DB 종류에 맞춰 작동되도록.
- 드라이버 매니저 → 연결 → statement → resultset
- ⇒ 중복 코드가 많다, 커넥션 관리 계속해야한다(close 자원), sql 다뤄야 한다.

- SQL MAPPER , 스프링의 JDBC
- 이전의 불편한 점(중복코드)을 많이 추상화 시킴 (jdbc template)
- 마이바티스 ,
- 자바 코드와 SQL을 분리하자 → 쿼리를 java xml로 분리 (관심사의 분리)
- 동적쿼리 가능

- ORM == object relational mapping → JPA 인터페이스 생성, 하이버네이트 구현체 == 객체와 RDB 패러다임불일치 해소
- 패러다임불일치 (연관관계(객체참조), 상속..)

- 객체의 상속, 정보은닉, 추상화, 다형성 등으로 복잡한 세상을 추상화하자. 하는데 디비에는 이런게 없네? 게다가 물리적으로는 데이터 숨기는데 성공했을지몰라도, 논리적으로는 강한 의존관계를가진다(양쪽수정)
- SQL vs 메소드
- 아직도 SQL의 존적인 개발하네? 엔티티 값 추가되면 SQL 문 수정해야되네 ? → 메소드
- 상속
- 직접 SQL 쓴다면 부모와 자식에 대한 쿼리 각각 날려줘야함. → JPA가 알아서 관리해줌
- 동일성 이 깨지는문제
- AVA는 동일성, 동등성 비교하지만, 트랜잭션 내에서 하나의 객체는 같은 주소를 가짐. 동일하게 취급돼서 DB와의 싱크 맞춰줌
- 연관관계
- 데이터중심으로 코드짬(연관관계를 id) → 연관있는 객체들간 객체참조
- 자바에서 관계가진 엔티티 멤버변수로 객체넣어도 테이블 매핑코드 JPA가 만들어줌. DB 외래키
- 객체그래프 탐색시 sql은 join에 대한 연관 데이터 보장안되지만, JPA 쓰면 보장.
- 스프링 데이터의 JPA에는 엔티티 매니저 복잡하니까 한단계 더추상화 해서 레포지토리 사용, 내부에 있음.
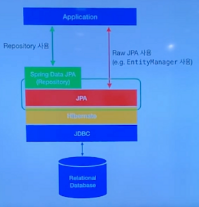
- spring data JDBC == simple , 엔티티 매니저 감추자
